Logistic regression의 optimization problem은 안타깝게도 closed form solution이 존재하지 않는다. 그래서 gradient descent 방식을 사용해서 이 문제를 해결해야 한다.
How to Optimization?
다시 logistic regression이 풀고자 하는 optimization problem을 보면 다음과 같다. 다음의 loss function을 최소로 만드는 parameter w를 찾는 것이 logistic regression의 목표이다.
wargmin=:L(w) or Ln=1∑Nlog (1+exp(−ynwTxn))
이때, gradient descent를 진행하기 위해서는 parameter w에 관한 gradient를 계산해야 한다.
Gradient:
∇wL(w)=n=1∑N1+exp(−ynwTxn)−ynexp(−ynwTxn)
그리고는 loss function을 감소시키기 위해서는 gardient의 negative 방향을 향해서 반복적으로 parameter를 업데이트 시켜줘야 한다.
Gradient Descent:
wt+1←wt−α∇wL(w)∣w=wt
관습적으로 optimization problem에서 minimization을 하고자 한다면 L을 loss function이라고 할 것이며, 반대로 maximization을 하고자 한다면 L을 objective function이라고 할 것이다.
Alternative Form
Logistic regression의 성질을 이용해서 만약 binary classifier를 가정하게 된다면 data point의 label은 보통 0이나 1이 될 것이다. 그렇게 되면 우리가 풀고자 하는 식은 더 간단해질 것이고, 먼저 yn∈{0,1}에 대해서 likelihood는 다음과 같이 정의할 수 있다.
우리가 원하는 것은 위의 objective function을 최대로 만드는 것이기 때문에 gradient ascent algorithm을 통해서 다음과 같이 parameter를 업데이트 해줘야 한다.
wnew=wold+η(∂w∂L)
이때 각 업데이트 과정에서는 다음과 같이 gradient를 구할 수 있다.
∂w∂L=n=1∑N[yn−σ(wTxn)]xn
이 계산을 결론내기 위해서는 logistic regression의 성질 중 하나를 사용해서 쉽게 계산이 가능하고, 따라서 우리는 gradient ascent update rule을 다음과 같이 정리할 수 있다.
wnew=wold+ηn=1∑N[yn−σ((wold)Txn)]xn
Detailed Calculation of Gradient
생략했던 gradient의 계산을 다음과 같이 할 수 있다. Binary classification에 대한 log-likelihood를 parameter w에 대해서 미분해서 정리하는 과정이다.
파란점으로 표시가 된 data point들은 class -1을 가지고 있고, 검은점으로 표시가 된 data point들은 class 1을 가지고 있다. 그러면 이제 logistic regression을 이들을 분류하기 위해서 위와 같이 빨간선으로 존재하게 된다. 그러면 확률을 0.5를 기준으로 class를 분류한다고 했을 때 decision boundary가 0에서 만들어져서 나름 classification을 잘한 결과가 된다.
이번에는 class 1에 다른 data point들이 추가 된 경우를 보면은 원래 linear regression이었다면 많은 error를 발생시켰겠지만 logistic regression은 여전히 잘 동작하는 것을 볼 수 있다. Linear model이었다면 확률이 0.5에 대해서 decision boundary가 좀 더 우측으로 생성되어 class 1인 data point 일부를 잘못 분류하는 error를 만들게 될 것이다.
Newton's Method: Second-Order Optimization
이렇게 logistic regression이 gradient-based optimization의 대표적인 방법인 gradient descent 혹은 ascent로 해결할 수 있다는 것을 알아보았다. Logistic regression은 linear model과는 다르게 간단한 data들에 대해서도 robust 함을 확인할 수 있었다. 이번에 살펴 볼 Newton method도 logistic regression의 문제를 해결하는 방안 중 하나이다. 이는 loss function 혹은 objective function의 second-order derivative를 구해서 풀고자하는 방식이다. Newton method로부터 유명한 algorithm 중 하나인 iterative re-weighted least square(IRLS) method에 대해서 알아볼 것이다.
Hessian Matrix
Newton method를 이해하기 위해서 먼저 Hessian matrix에 대한 이해가 필요하다. Hessian matrix는 그저 여러 variable을 고려하는 second-order derivative를 표현하기 위한 수단이다. 먼저 second derivative는 만약 f(x)가 미분이 가능하다면 다음과 같이 계산이 된다.
∂xi∂xj∂2f(x)at (i,j)
그러면 이제 Hessian matrix H는 위와 같은 second derivative의 결과를 coordinate마다 계산을 해서 각각을 element로 하는 symmetric matrix를 다음과 같이 만들 수 있다.
이렇게 D 차원의 variable x를 가질 때, 모든 second derivative의 결과를 하나의 matrix로 표현이 가능해졌다.
Newton's Method
First-order gradient descent는 first-order Taylor exression을 사용한 loss function의 근사치이다. 어떠한 함수가 있다면 임의의 지점에서의 gradient를 계산해서 모든 함수들을 근사시키게 된다. 함수에서 특정 지점의 기울기는 loss function의 gradient 값과 같을 것이다. 이를 기반으로 GD에서는 원하는 지점을 찾아가기 위해서 gradient를 기반으로 이동하게 된다.
반면, Newton's method의 기본 아이디어는 Hessian을 통해서 second-order Taylor expansion을 사용한 objective function을 근사시키는 것이다. Objective function J(w)의 second-order Taylor expansion은 현재의 위치인 w(k)에서 다음과 같이 구할 수 있다.
where ∇2J(w(k)) is the Hessian of J(w) evaluated at w=w(k)
이렇게 second derivative까지 사용하게 되면 더욱 정교한 근사가 가능해지고 이로 인해서 fast convergence가 가능해져 더욱 빠르게 수렴할 수 있게 된다. 구체적으로 Newton's method가 하고자 하는 것은 second-order Taylor expansion이 주어졌을 때 이를 최대로 만들기 위해서 stationary point를 찾으려고 하는 것이다. 그래서 second-order Taylor expansion의 derivative를 구하고 0으로 두면 다음과 같은 결과를 얻을 수가 있다.
dwdJ2(w)=J(w(k))+∇2J(w(k))w−∇2J(w(k))w(k)=0
그러면 다음과 같이 optimal w를 얻을 수 있게 된다.
w=w(k)−[∇2J(w(k))]−1∇J(w(k))
이로부터 Newton's method가 하고자 하는 것은 다음과 같은 업데이트 rule을 만드는 것이다.
w(k+1)=w(k)−[∇2J(w(k))]−1∇J(w(k))
여기서 Hessian matrix의 inversion가 존재하는 이유는 Hessian matrix가 symmetric matrix이기 때문이다. 이제 Newton's method를 그래프를 통해서 이해를 해보고자 한다.
우리는 f(x)를 감소시키고 싶은 것이고, Newton's method는 이 function을 파란선인 second-order Taylor expansion을 통해 근사시키려고 하는 것이다. 파란선의 함수를 최소로 만들어주는 xk+dk에서의 검은점을 찾기 위해서 근사시킬 것이다. 찾은 후에는 빨간선에서 해당 지점으로 이동해 다시 파란선을 만들고 다시 이를 최소로 만들어주는 지점을 찾아서 빨간선에서 근사시킬 것이다. 그렇게 하면 convex의 경우 xk에서 파란선의 영향을 받아서 계속해서 원하는 지점을 찾아 이동하게 될 것이다.
Newton's method는 local minima와 local maxima issue가 존재하지만, 일단 convex 혹은 concave function이라는 것이 확인이 되면 Newton's method는 정확하게 원하는 지점을 찾을 수 있을 것이다. Non-conves나 non-concave function의 경우에는 보장할 수는 없다.
Detailed Calculation of Hessian
IRLS는 단지 logistic regression을 위한 Newton's method이다. 그래서 먼저 Hessian을 계산해보면 다음과 같을 것이다.
∇2L=∂w∂[∇L]T
=∂w∂[n=1∑N(yn−y^n)xnT]
=−n=1∑Ny^n(1−y^n)xnxnT
이제 objective function J(w)를 다음과 같이 negative log-likelihood를 이용해서 나타낼 수 있다.
따라서 gradient와 Hessian을 계산하면 다음과 같다. 그리고 Hessian이 positive definite라는 것은 쉽게 확인할 수 있을 것이다.
gradient: −n=1∑N(yn−y^n)xn
Hessian: n=1∑Ny^n(1−y^n)xnxnT
IRLS
이제 Hessian 혹은 logistic regression이 주어지면, Newtons' method는 다음과 같이 업데이트가 될 것이다.
Δw=−inverse of Hessian[n=1∑Ny^n(1−y^n)xnxnT]−1gradient[−n=1∑N(yn−y^n)xn]
IRLS가 하고자 하는 것은 결국 다음과 같이 수렴할 때까지 반복하는 update algorithm이다.
Δw=(XSXT)−1XSb
where S=⎣⎢⎢⎡y^1(1−y^1)⋮0…⋱…0⋮y^N(1−y^N)⎦⎥⎥⎤,b=⎣⎢⎢⎢⎡y^1(1−y^1y1−y^1⋮y^N(1−y^Ny1−y^N⎦⎥⎥⎥⎤
Alternatively
wk+1=wk+(XSkXT)−1XSkbK
X는 data point matrix이고, S와 b는 위와 같이 정의할 수 있다. 다음은 IRLS algorithm의 psuedo-code이다. 여기서 관심있게 볼 내용은 Newton's method 덕분에 hyper-parameter가 존재하지 않는다는 것이다. IRLS는 convergence를 보장한다는 것도 중요하다.
Multiclass Logistic Regression
우리는 지금까지 binary class에 대한 logsitic regression만을 살펴보았는데, 이를 일반화시키면 더 많은 class를 분류하는 것도 가능하다. 이러한 경우에는 다음과 같이 해당 data point가 어떠한 class에 속하는지에 대한 확률을 사용하게 된다.
p(yn=k∣xn)=∑j=1Kexp(exp(wkTxn))exp(wkTxn)
그러면 log-likelihood는 data point간에 independence를 고려해서 다음과 같이 objective function을 나타낼 수 있다.

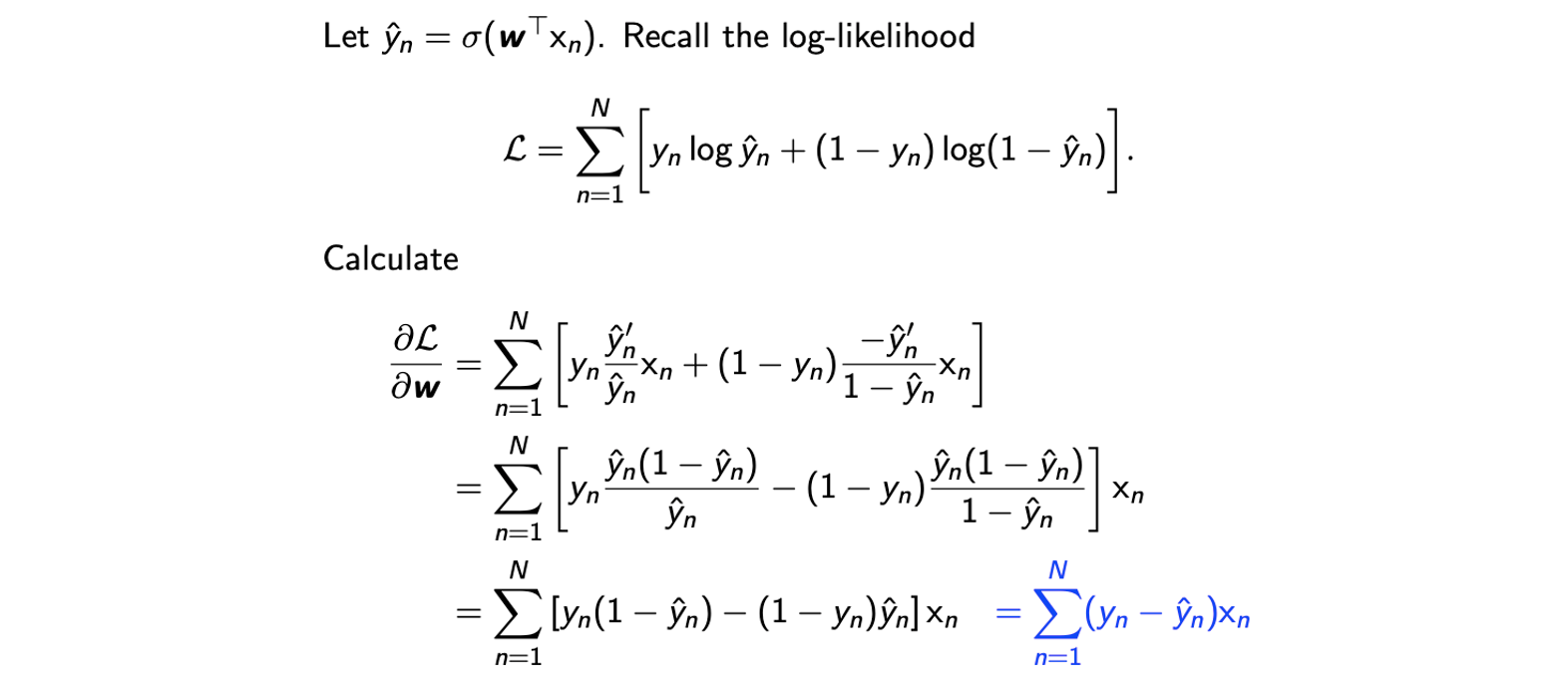 Binary classification에 대한 log-likelihood를 parameter 에 대해서 미분해서 정리하는 과정이다.
Binary classification에 대한 log-likelihood를 parameter 에 대해서 미분해서 정리하는 과정이다.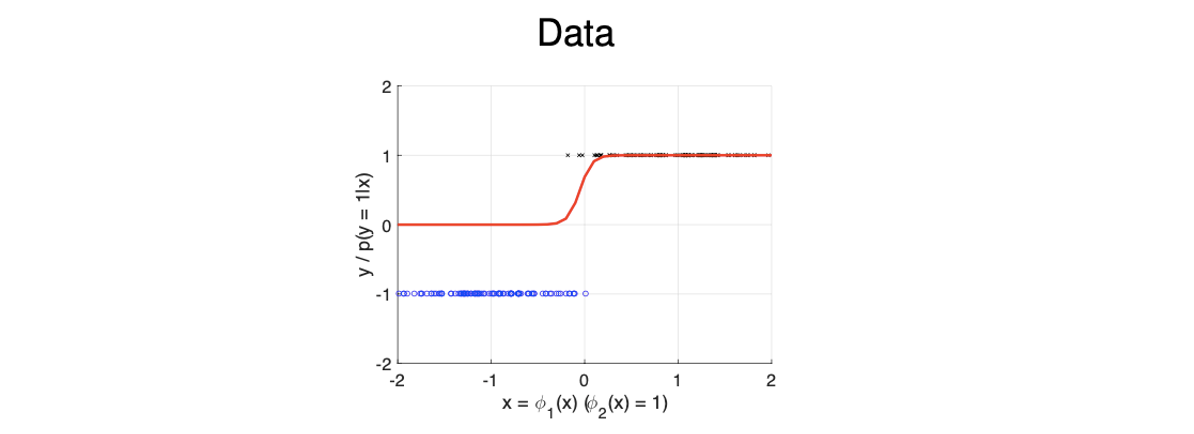 파란점으로 표시가 된 data point들은 class -1을 가지고 있고, 검은점으로 표시가 된 data point들은 class 1을 가지고 있다. 그러면 이제 logistic regression을 이들을 분류하기 위해서 위와 같이 빨간선으로 존재하게 된다. 그러면 확률을 0.5를 기준으로 class를 분류한다고 했을 때 decision boundary가 0에서 만들어져서 나름 classification을 잘한 결과가 된다.
파란점으로 표시가 된 data point들은 class -1을 가지고 있고, 검은점으로 표시가 된 data point들은 class 1을 가지고 있다. 그러면 이제 logistic regression을 이들을 분류하기 위해서 위와 같이 빨간선으로 존재하게 된다. 그러면 확률을 0.5를 기준으로 class를 분류한다고 했을 때 decision boundary가 0에서 만들어져서 나름 classification을 잘한 결과가 된다.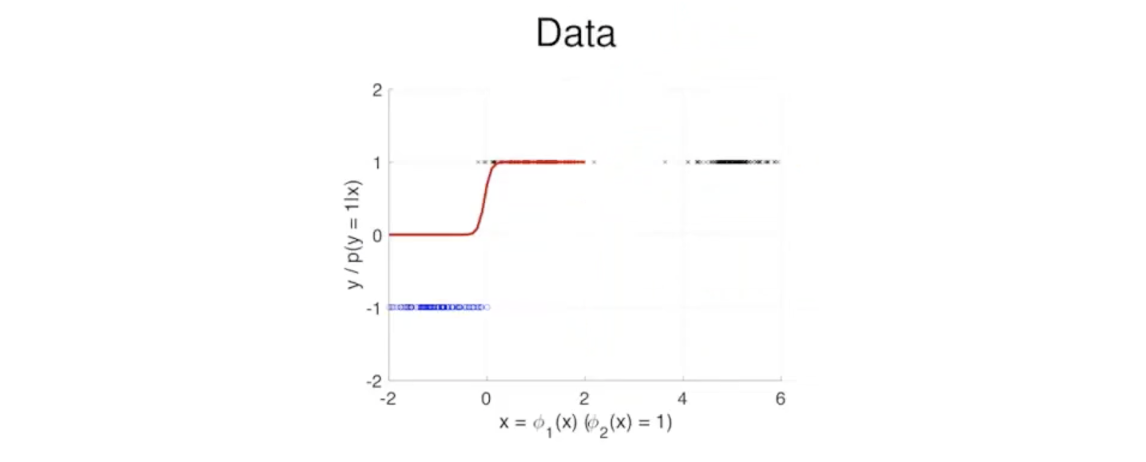 이번에는 class 1에 다른 data point들이 추가 된 경우를 보면은 원래 linear regression이었다면 많은 error를 발생시켰겠지만 logistic regression은 여전히 잘 동작하는 것을 볼 수 있다. Linear model이었다면 확률이 0.5에 대해서 decision boundary가 좀 더 우측으로 생성되어 class 1인 data point 일부를 잘못 분류하는 error를 만들게 될 것이다.
이번에는 class 1에 다른 data point들이 추가 된 경우를 보면은 원래 linear regression이었다면 많은 error를 발생시켰겠지만 logistic regression은 여전히 잘 동작하는 것을 볼 수 있다. Linear model이었다면 확률이 0.5에 대해서 decision boundary가 좀 더 우측으로 생성되어 class 1인 data point 일부를 잘못 분류하는 error를 만들게 될 것이다. 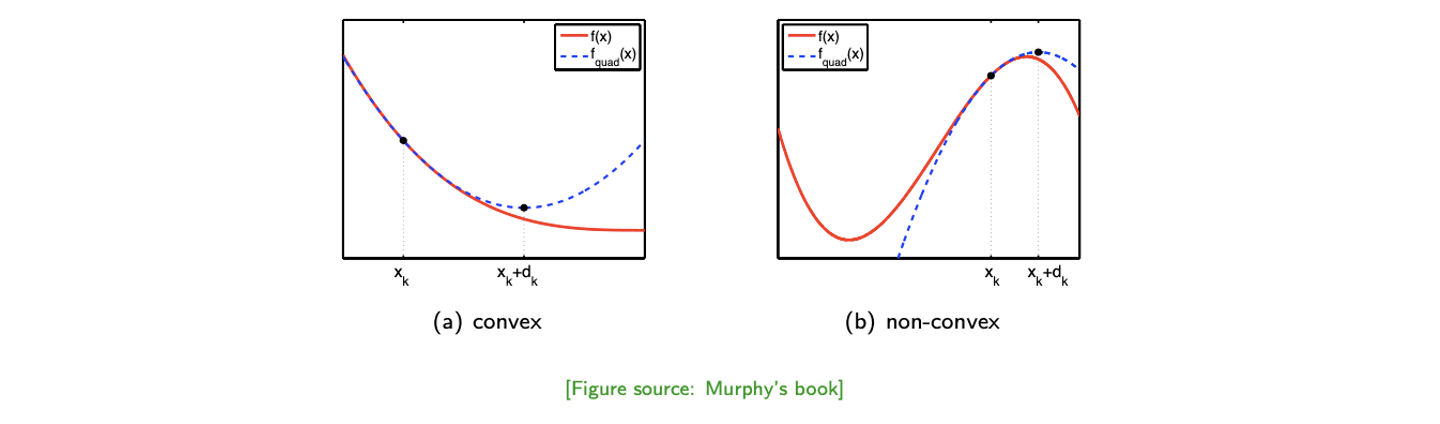 우리는 를 감소시키고 싶은 것이고, Newton's method는 이 function을 파란선인 second-order Taylor expansion을 통해 근사시키려고 하는 것이다. 파란선의 함수를 최소로 만들어주는 에서의 검은점을 찾기 위해서 근사시킬 것이다. 찾은 후에는 빨간선에서 해당 지점으로 이동해 다시 파란선을 만들고 다시 이를 최소로 만들어주는 지점을 찾아서 빨간선에서 근사시킬 것이다. 그렇게 하면 convex의 경우 에서 파란선의 영향을 받아서 계속해서 원하는 지점을 찾아 이동하게 될 것이다.
우리는 를 감소시키고 싶은 것이고, Newton's method는 이 function을 파란선인 second-order Taylor expansion을 통해 근사시키려고 하는 것이다. 파란선의 함수를 최소로 만들어주는 에서의 검은점을 찾기 위해서 근사시킬 것이다. 찾은 후에는 빨간선에서 해당 지점으로 이동해 다시 파란선을 만들고 다시 이를 최소로 만들어주는 지점을 찾아서 빨간선에서 근사시킬 것이다. 그렇게 하면 convex의 경우 에서 파란선의 영향을 받아서 계속해서 원하는 지점을 찾아 이동하게 될 것이다.  여기서 관심있게 볼 내용은 Newton's method 덕분에 hyper-parameter가 존재하지 않는다는 것이다. IRLS는 convergence를 보장한다는 것도 중요하다.
여기서 관심있게 볼 내용은 Newton's method 덕분에 hyper-parameter가 존재하지 않는다는 것이다. IRLS는 convergence를 보장한다는 것도 중요하다.