
Important Characteristics of Data
이전까지는 attribute에 초점을 맞춰서 알아보았다면, 이번에는 data 자체에 초점을 맞춰보고자 한다.
1. Dimensionality(# of attributes)
개의 object와 개의 attribute를 가지는 data가 있다고 해보자. 이러한 경우 data table이 로 만들어지게 될 것이고 하나의 row 를 택한다고 했을 때, 이 object를 설명하기 위해서는 개의 attribute value가 필요할 것이다. 따라서 attribute의 숫자의 경우 data의 dimensionality를 정의하게 된다. 보통 이것은 가장 흔한 문제이다. 고차원의 data의 경우 많고 많은 문제거리를 가져오게 된다. 하나의 object를 설명하기 위해서는 수백개 혹은 수백만개의 서로 다른 attribute를 생각해내야하는 경우도 존재한다. 이것이 의미하는 것은 해당 object가 매우 복잡하다는 것을 말하는 것이다. 가장 대표적인 예시가 아마 사람의 DNA일 것이다. 정말 복잡하게 구성되어 있는 DNA를 통해서 해당 사람을 설명할 수 있는 것이다.
그렇다고 할지라도 고차원의 data가 존재해도 괜찮은 경우는 그만큼의 많은 object가 존재할 때이다. 예를 들어 미지수가 2개이고 방정식이 2개라면 미지수를 구할 수가 있다. 하지만 미지수가 3개인데 방정식이 2개뿐인 경우라면 미지수를 구하는데 어려움이 생긴다. 그래서 만약 어떠한 dataset을 가지고 있다고 할 때 반드시 attribute의 개수를 확인해야 한다. Data의 차원은 sample의 수보다 작아야 하고, 이러한 경우에만 machine learning 문제를 해결해나갈 수 있다. 만약 data의 차원이 sample의 수보다 훨씬 큰 경우에는 이를 "large p small n" 문제라고 한다. 물론 이러한 문제를 쉽게 만들어서 해결하는 방법들이 존재하지만, 고차원의 경우는 항상 어떠한 문제를 만들어내기 마련이다.
2. Sparsity
Sparsity라는 것은 무수히 많은 0이 존재하는 경우를 말한다. 다시 위와 같은 data table이 있다고 했을 때, 아마도 90%의 element가 0의 값을 가지는 경우를 생각해보자. 이러한 경우에 data를 보았을 때 이 data가 실질적으로 설명하는 바는 무엇일까? 사실 0보다 0이 아닌 element가 많은 경우가 훨씬 더 유용하게 사용될 것이다. 즉, 존재성의 중요함이 필요하다는 것이다.
3. Resolution
Data에서 특정한 pattern은 scale에 의존할지도 모른다. 예를 들어, 우리가 물병의 전체를 보고 있을 때 한눈에 해당하는 물체가 물병인지 알 수 있을 것이다. 하지만 물병의 일부분만이 보인다고 했을 때는 해당 물체가 물병인지 아닌지 확신할 수가 없다. 그래서 특정 pattern은 scale에 의존적일 수 밖에 없는 것이다. 우리가 보고 있는 scale에 따라서 data의 특정 pattern을 찾을 수도 있지만 찾지 못할 수도 있다.
4. Size
만약 attribute의 개수가 너무나도 많아지면 컴퓨터가 이를 다루는데 어려움이 존재하게 된다. 컴퓨터에서 알고리즘을 동작시킬 때 중요한 computational issue가 발생할 수도 있는 것이다.
Data의 이러한 characteristic들을 종합해 봤을 때 data를 다루는 경우에 attribute의 개수에 비해서 충분히 많은 object의 개수가 있는지, 충분히 많은 정보가 있는지, 충분히 적당한 해상도에 측정이 되었는지, data가 내 컴퓨터에 사용될만큼 적절한 크기인지 등 이러한 질문들이 data를 다루기 전에 가장 먼저 확인해야하는 내용들이다.
Types of Datasets
Data를 표현하는 방식에도 다양한 방식이 존재한다.
1. Record
- Data Matrix : 그 중에서 data matrix의 경우 우리가 지금까지 object와 attribute를 설명할 때 사용하던 dataset의 type 중 하나이다. Data matrix에서 row는 object를, column은 attribute를 설명하고 있다.
- Document Data : 보통 가공되지 않은 data들이 document 형식으로 존재하곤 한다.
- Transaction Data : 여기서 item들은 보통 순서를 가지게 된다.
2. Graph : Graph의 경우 수많은 variable을 가지게 되는데, 이들이 서로 연결되어 있게 된다. 특히, 연결이 임의로 형성이 된다는 점이 graph의 특징이다.
- World Wide Web
- Molecular Structures
3. Ordered
- Spatial Data
- Temporal Data
- Sequential Data
- Genetic Sequence Data
여기서 중요한 부분은 이렇게 다양한 형태로 data가 존재할 수 있는데, 이때 각 data type마다 적용해야 하는 data mining 기법이 다르다는 것이다. 그러면 지금부터 하나씩 자세하게 살펴보도록 할 것이다.
1. Record Data
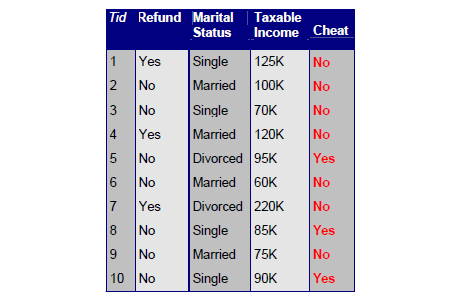 위와 같은 record data의 경우 우리에게 매우 친숙한 data type일 것이다. 위의 예시는 세금과 연말 정산에 관련된 dataset인데, 아마도 여기서 가장 중요한 정보는 cheat이라는 attribute일 것이다. 이러한 정보들을 바탕으로 예측하고자 하는 것이 바로 cheat의 유무일 것이기 때문이다. Data mining을 통해서 cheat이라는 column에 어떠한 값들이 채워질지 예측하게 될 것이다.
위와 같은 record data의 경우 우리에게 매우 친숙한 data type일 것이다. 위의 예시는 세금과 연말 정산에 관련된 dataset인데, 아마도 여기서 가장 중요한 정보는 cheat이라는 attribute일 것이다. 이러한 정보들을 바탕으로 예측하고자 하는 것이 바로 cheat의 유무일 것이기 때문이다. Data mining을 통해서 cheat이라는 column에 어떠한 값들이 채워질지 예측하게 될 것이다.
1.1. Data Matrix
 만약 모든 것들이 숫자로 되어져 있다면, 이는 record data 중에서도 data matrix가 될 것이다. matrix라고 한다면 개의 object와 개의 attribute를 표현한 것이다.
만약 모든 것들이 숫자로 되어져 있다면, 이는 record data 중에서도 data matrix가 될 것이다. matrix라고 한다면 개의 object와 개의 attribute를 표현한 것이다.
1.2. Document Data
예를 들어 2개의 다른 document가 있다고 해보자. 그리고 우리가 각 document를 data로 표현하고자 하는데, 기존의 data matrix의 경우처럼 각 object는 attribute의 관점으로 설명할 수 있을 것이다. 그래서 핵심 attribute를 정의해서 각 attribute가 document를 설명할 수 있도록 만들어야 한다.
사람들은 흔히 term vector로서 document를 사용하게 된다. 우리는 각 document를 vector 형식으로 설명하고자 하는 것이다. 그리고 각 vector에서 element가 하는 일을 각각의 term을 표현하는데 사용된다. 여기서 각 term은 vector의 component 혹은 attribute에 해당하게 된다.
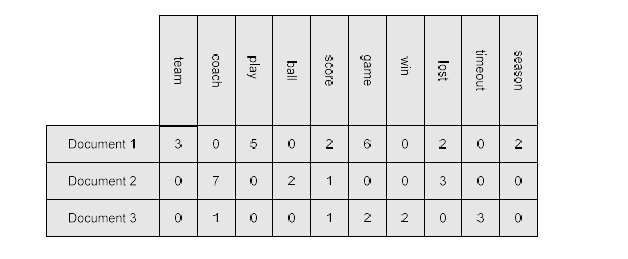 예를 들어, 각 document가 위와 같은 attribute를 포함하고 있다고 했을 때 각 element가 설명하고자 하는 것은 얼마나 해당 단어가 등장했는지이다. 이러한 방식이 document를 term vector로서 흔히 사용하는 방식인 것이다. 즉, 각 component의 값은 document에서 해당하는 term이 얼마나 등장했는지를 나타내게 된다.
예를 들어, 각 document가 위와 같은 attribute를 포함하고 있다고 했을 때 각 element가 설명하고자 하는 것은 얼마나 해당 단어가 등장했는지이다. 이러한 방식이 document를 term vector로서 흔히 사용하는 방식인 것이다. 즉, 각 component의 값은 document에서 해당하는 term이 얼마나 등장했는지를 나타내게 된다.
스포츠와 관련된 단어의 빈도수를 설명하고 있지만, 실질적으로 하고자 하는 것은 서로 다른 document를 비교하고자 하는 것이다.
1.3. Transaction Data
 Transaction data의 경우 매우 특별한 형태의 data이다. 여기서 각 transaction은 item들의 set 형태로 존재하며 위와 같은 예시를 보면 고객이 한 번의 쇼핑 여행에서 구매한 제품 set은 transaction를 구성하고, 개별 구매 제품은 item에 해당하게 된다. 결국에 우리는 위와 같은 data를 table로 보게되면 각 제품을 구매했는지 하지 않았는지 설명할 수 있는 것이고, 이는 term vector와 유사하다고 볼 수 있다.
Transaction data의 경우 매우 특별한 형태의 data이다. 여기서 각 transaction은 item들의 set 형태로 존재하며 위와 같은 예시를 보면 고객이 한 번의 쇼핑 여행에서 구매한 제품 set은 transaction를 구성하고, 개별 구매 제품은 item에 해당하게 된다. 결국에 우리는 위와 같은 data를 table로 보게되면 각 제품을 구매했는지 하지 않았는지 설명할 수 있는 것이고, 이는 term vector와 유사하다고 볼 수 있다.
이전에도 이야기했듯이 정말로 중요한 핵심은 이러한 matrix에서 0이 아닌 value들의 존재성이다. 위의 document data를 보면 매우 많은 0이 존재하는 것을 알 수 있다. 그래서 여기서 0이 아닌 value들이 의미를 가지게 되는 것이다. Document data에서는 document를 비교하기 위해서 0이 아닌 value들을 참고하게 되는 셈이다.
2. Graph Data
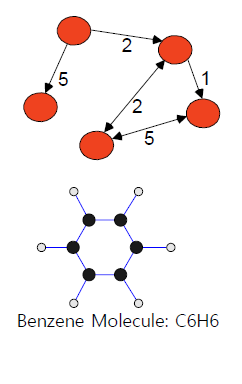 Graph data는 node와 edge로 되어 있는 data type으로, node들은 edge를 통해서 연결되어 있다. 여기서 edge에는 방향성이 존재할 수도 있고 아닐 수도 있는 것이다. 이러한 형태의 data는 매우 흔하지만 사용하는데는 어려움이 존재한다. Graph data가 사용되는 예시로는 generic graph, molecule, webpage, social network, brain network 등이 있다.
Graph data는 node와 edge로 되어 있는 data type으로, node들은 edge를 통해서 연결되어 있다. 여기서 edge에는 방향성이 존재할 수도 있고 아닐 수도 있는 것이다. 이러한 형태의 data는 매우 흔하지만 사용하는데는 어려움이 존재한다. Graph data가 사용되는 예시로는 generic graph, molecule, webpage, social network, brain network 등이 있다.
3. Ordered Data
3.1. Sequences of Transactions / Genomic Sequence Data
Ordered data에서 중요한 것은 순서이며, transaction data에 순서가 존재하는 확장된 버전이 대표적인 예시 중 하나이다.
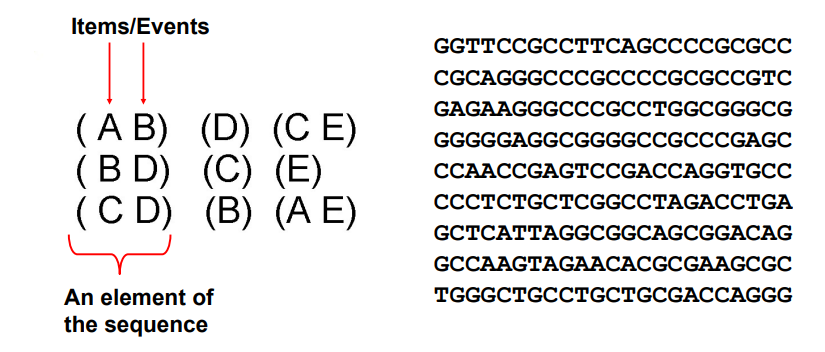 위와 같이 item들의 순서가 존재하기에 (A B)와 (B A)는 서로 다른 item에 해당하게 된다. 때로는 이러한 순서가 중요한 의미를 가지기도 하며, 이러한 예시로는 genomic sequence data가 있다. 여기에는 G, T, C, A가 특정한 순서로 존재하게 되는데, 이는 pattern을 형성하게 된다. 이러한 순서는 특정 질병과 연관지을 수도 있고, 사람의 특징을 설명할 수도 있다.
위와 같이 item들의 순서가 존재하기에 (A B)와 (B A)는 서로 다른 item에 해당하게 된다. 때로는 이러한 순서가 중요한 의미를 가지기도 하며, 이러한 예시로는 genomic sequence data가 있다. 여기에는 G, T, C, A가 특정한 순서로 존재하게 되는데, 이는 pattern을 형성하게 된다. 이러한 순서는 특정 질병과 연관지을 수도 있고, 사람의 특징을 설명할 수도 있다.
3.2. Saptio-Temporal Data
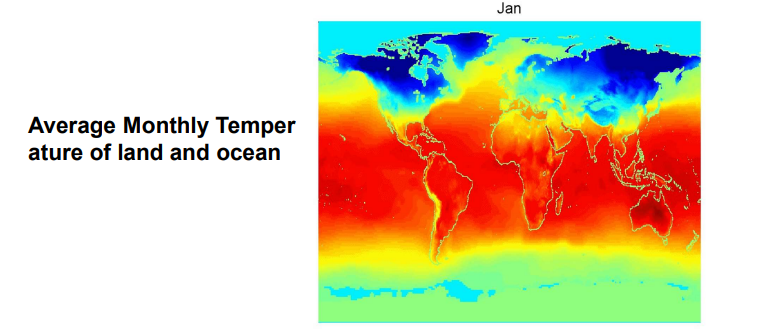 Spatio-temporal data는 이름에서부터 알다시피 space와 time이 결합되어 사용하는 data이다. 위의 예시는 시간의 흐름에 따라 변화하는 월평균 기온을 보여주는 것인데, space는 2차원으로 지구상의 위치를 알려주고 있으며 time으로는 한달마다 변화하고 있다.
Spatio-temporal data는 이름에서부터 알다시피 space와 time이 결합되어 사용하는 data이다. 위의 예시는 시간의 흐름에 따라 변화하는 월평균 기온을 보여주는 것인데, space는 2차원으로 지구상의 위치를 알려주고 있으며 time으로는 한달마다 변화하고 있다.
Data Quality
- Poor data quality negatively affect many data processing efforts
Data를 얻고자 할 때 sensor를 이용해서 수집을 하기도 하고, 가령 선생님이 같은 교실에 있는 학생들에게 속삭이며 말을 할 때 선생님과 거리가 먼 학생들의 경우 다르게 들릴 수도 있을 것이다. 즉, 자연적으로 data를 온전히 받아들이지 못하는 경우가 많으며 대부분은 data의 quality가 떨어지는 현상이 발생한다. Data quality에 따라 이후의 영향력의 차이는 굉장히 크기 때문에 data quality는 고려해야하는 부분 중 하나이다.
- Data mining example : a classification model for detecting for detecting people who are loan risks is built using poor data
신용도가 높은 몇몇 지원자들은 대출을 거절당하고, 더 많은 대출이 채무 불이행 개인들에게 주어진다. 이러한 경우에 문제는 은행의 경우 파산의 위험이 존재한다. 여기서 data의 quality가 정말로 중요하게 작용한다.
그렇다면 어떠한 종류의 data quality 문제가 존재하는 것일까? data에 대해서 어떻게 문제를 발견할 수 있을까? 우리가 이 문제들에 대해서 무엇을 할 수 있을까? 이러한 질문들에 대한 답을 알아보기 위해서 먼저 data quality 문제의 예시들을 알아보도록 하자.
- Noise and outliers : 하나의 outlier가 우리의 prediction model에 굉장한 타격을 입힐 수 있다.
- Wrong data : 보통 이러한 data는 사람의 실수나 sensor의 문제로부터 만들어지게 된다.
- Fake data : 이는 사람의 의도로 만들어져 대중들에게 영향력을 행사할 수 있다.
- Missing values
- Duplicate data : 사람의 경우 문제가 되지 않지만 컴퓨터의 경우에는 연산하는데 있어서 큰 문제를 야기할 수 있다.
지금부터는 하나씩 자세하게 이러한 문제들에 대해서 알아보도록 하자.
1. Noise
Data에서 주목하고 싶은 pattern을 object라고 했을 때, 우리는 이러한 object를 찾기를 원하며 noise의 경우에는 불필요한 object에 해당하게 된다. 우리는 data로부터 특정 pattern을 얻기를 원하는데 원하지 않는 object인 noise가 존재할 수 있으며, 사실 이러한 object를 분리시키는 기법들도 많이 존재한다. 그리고 obejct를 설명하기 위한 attribute에 대해서 noise는 원래 value의 수정을 의미한다. True value가 있다고 가정해보자. 여기에 noise가 추가가 된다면 원래 value와는 다른 결과를 만들어 낼 것이다. 우리가 흔히 sensor를 통해서 측정되는 결과는 true value와 noise가 더해진 형태일 것이다.
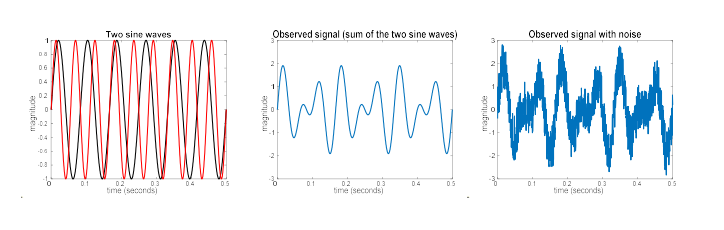 위와 같이 진폭은 같고 진동수가 다른 2개의 sine wave가 있다고 했을 때 이를 합치게 되었을 때 가운데와 같은 결과가 나온다고 하고 이를 true pattern이라고 해보자. 우리는 이러한 결과를 보려고 시도할 것이다. 그러나 실제로는 우측과 같이 noise가 존재하는 결과를 얻게 될 것이다. 그래서 우리는 어떻게든 우측의 결과로부터 가운데의 이상적인 결과를 얻으려고 할 것이다.
위와 같이 진폭은 같고 진동수가 다른 2개의 sine wave가 있다고 했을 때 이를 합치게 되었을 때 가운데와 같은 결과가 나온다고 하고 이를 true pattern이라고 해보자. 우리는 이러한 결과를 보려고 시도할 것이다. 그러나 실제로는 우측과 같이 noise가 존재하는 결과를 얻게 될 것이다. 그래서 우리는 어떻게든 우측의 결과로부터 가운데의 이상적인 결과를 얻으려고 할 것이다.
2. Outliers
Outlier는 data set의 다른 대부분의 data object와 상당히 다른 특성을 가진 data object이다. 그렇다면 우리는 어떻게 outlier의 존재에 대해서 알 수 있을까? 대표적인 기술로 clustering을 통해서 outlier를 찾아낼 수가 있다.
 Data object를 point라고 할 수 있는 이유는 data가 vector로 표현될 수 있기 때문이다. 즉, data object를 vector space에 놓을 수 있다는 의미이다. 그래서 vector space에서 point로 표현이 되는 것은 data object에 해당하게 된다. 그렇기 때문에 cluster로 형성이 되는 것은 특정한 pattern을 제시할 수 있는 것이다. 위의 예시는 4개의 cluster와 3개의 point를 보여주고 있으며, 3개의 point는 어떠한 cluster에도 속하지 않아서 이를 outlier라고 부를 수 있는 것이다. Outlier는 data analysis를 방해하는 noise로 볼 수도 있고, 특정한 pattern을 찾아내는데 방해되는 존재로 간주되기도 한다. 그리고 현실에서는 안전과 관련된 많은 문제들에서 outlier를 찾아내는 것은 매우 중요하다.
Data object를 point라고 할 수 있는 이유는 data가 vector로 표현될 수 있기 때문이다. 즉, data object를 vector space에 놓을 수 있다는 의미이다. 그래서 vector space에서 point로 표현이 되는 것은 data object에 해당하게 된다. 그렇기 때문에 cluster로 형성이 되는 것은 특정한 pattern을 제시할 수 있는 것이다. 위의 예시는 4개의 cluster와 3개의 point를 보여주고 있으며, 3개의 point는 어떠한 cluster에도 속하지 않아서 이를 outlier라고 부를 수 있는 것이다. Outlier는 data analysis를 방해하는 noise로 볼 수도 있고, 특정한 pattern을 찾아내는데 방해되는 존재로 간주되기도 한다. 그리고 현실에서는 안전과 관련된 많은 문제들에서 outlier를 찾아내는 것은 매우 중요하다.
3. Missing Values
Data matrix에서 모든 공간이 특정 value로 채워진게 아니게 되면 비어져 있는 공간의 경우 missing value가 존재하게 된다. 현실적으로 완벽하게 data matrix를 채우는 경우는 흔치 않기에 대부분 missing value 문제에 직면하게 된다. Missing value의 원인으로는 정보가 수집되지 않거나 특정 attribute가 모든 case에 적용되지 않기 때문이다. 사람들은 개인정보를 제공해주는 사례가 줄어들게 되고, 연간 소득과 같은 경우는 어린 아이에게는 해당하지 않는다.
그렇다면 이러한 missing value를 다루기 위해서는 어떻게 해야할까? 극단적인 해결 방안으로 data object를 없애버리면 된다. 아니면 missing value가 있는 공간에 특정 값을 추정해서 채워 넣을 수도 있다. 특히 시간과 관련있는 기온이나 인구 조사 결과와 같은 경우에는 어느정도 추정이 가능하게 된다. 아니면 추천하지는 않지만 data analysis 동안 missing value를 무시하는 방안도 있다.
- Eliminate data objects or variables
- Estimate missing values
- Ignore the missing value during analysis
4. Duplicate Data
Data set에는 중복되거나 거의 서로 중복되는 data object가 포함될 수 있습니다. 이는 주로 다른 종류(heterogeneous)들로 이루어진 source의 data를 병합할 때 주요 문제가 된다. 예시로는 동일한 사람이 사용하는 여러개의 이메일 주소가 이에 해당한다. 내가 주로 사용하는 학교 이메일 계정을 A라는 database에 제공하고, 개인적으로 사용하는 이메일 계정을 B라는 database에 제공했을 때 이를 합치려고 하면 서로 다른 이메일이지만 동일한 사람의 것이라서 문제가 된다.
이러한 duplicate data 문제를 해결하는데 있어서 data cleaning이라는 process 기술이 사용된다. 하지만 이러한 기술의 경우 data를 지우는데 많은 비용을 소모하게 된다.
