
Data augmentation
인공지능 모델을 학습시킬 때 쉽게 성능을 향상시킬 수 있는 data augmentation 기법에 대해서 알아볼 것이다.
Learning representation from a dataset
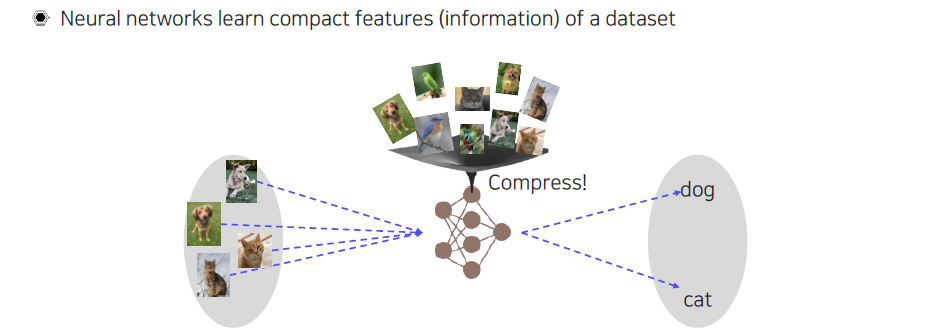 기본적으로 machine learning 모델들을 사용하는 이유는 이세상에 존재하는 모든 data를 활용할 수 없기 때문에 적절히 압축시켜 기존의 knowledge를 잘 활용해서 새로운 data가 들어왔을 때 이 data가 무엇인지 분석할 수 있다. Data를 굉장히 compact한 형태로 만들어 정보를 압축해서 가질 수 있다.
기본적으로 machine learning 모델들을 사용하는 이유는 이세상에 존재하는 모든 data를 활용할 수 없기 때문에 적절히 압축시켜 기존의 knowledge를 잘 활용해서 새로운 data가 들어왔을 때 이 data가 무엇인지 분석할 수 있다. Data를 굉장히 compact한 형태로 만들어 정보를 압축해서 가질 수 있다.
Dataset is (almost) always biased
 여기서 문제는 machine learning을 학습할 때 사용하는 dataset은 이세상 모든 data를 반영하는 real data가 아니라 한쪽으로 bias 되어있을 것이다. 예를 들어 우리가 영상을 취득할 때 카메라를 이용할텐데, 아무렇게나 찍는 것이 아니라 괜찮게 나오는 구도를 찾아서 촬영하도록 사람들에게 bias가 되어있을 것이다. 즉, 어떠한 구도를 찍는지에 대한 개개인의 선호도가 존재할 것이다. 어떠한 강물을 찍는다고 했을 때 강물만을 찍는다기 보다는 하늘과 풀숲과 강물이 함께 나오는 구도를 찾아서 찍고자 할 것이다. 이렇게 많은 사진들을 모아서 평균을 내보니까 중간과 같이 가운데에는 숲이 있고 위는 하늘이 나오면서 아래에는 강물이 비치는 쪽으로 편향되어 있음을 확인할 수 있었다. 이러한 구도를 사람들이 선호하는 순간 이로부터 취득된 dataset은 real data를 잘 반영하는 그러한 dataset이 아니라, 사람들의 선호도가 반영된 변형된 dataset이라는 것이다.
여기서 문제는 machine learning을 학습할 때 사용하는 dataset은 이세상 모든 data를 반영하는 real data가 아니라 한쪽으로 bias 되어있을 것이다. 예를 들어 우리가 영상을 취득할 때 카메라를 이용할텐데, 아무렇게나 찍는 것이 아니라 괜찮게 나오는 구도를 찾아서 촬영하도록 사람들에게 bias가 되어있을 것이다. 즉, 어떠한 구도를 찍는지에 대한 개개인의 선호도가 존재할 것이다. 어떠한 강물을 찍는다고 했을 때 강물만을 찍는다기 보다는 하늘과 풀숲과 강물이 함께 나오는 구도를 찾아서 찍고자 할 것이다. 이렇게 많은 사진들을 모아서 평균을 내보니까 중간과 같이 가운데에는 숲이 있고 위는 하늘이 나오면서 아래에는 강물이 비치는 쪽으로 편향되어 있음을 확인할 수 있었다. 이러한 구도를 사람들이 선호하는 순간 이로부터 취득된 dataset은 real data를 잘 반영하는 그러한 dataset이 아니라, 사람들의 선호도가 반영된 변형된 dataset이라는 것이다.
The training dataset is sparse samples of real data
 Data가 편향된 문제뿐 아니라 data가 가질 수 있는 embedding space에서 real data가 가질 수 있는 영역에서 실제로 우리가 가지고 학습할 수 있는 data는 굉장히 희소한 data들이다. 예를 들어, 우측과 같이 real data가 굉장히 밀집된 분포를 가지고 있다고 했을 때, 이세상 모든 data를 위와 같은 분포로 취득할 수 있다고 하더라도 실제로 우리가 학습에 사용하는 data는 이 중에서 굉장히 sampling된 sparse한 data만을 이용해서 학습할 것이다. 그래서 굉장히 local한 data만을 이용해서 학습할 수 있다는 한계점이 존재한다.
Data가 편향된 문제뿐 아니라 data가 가질 수 있는 embedding space에서 real data가 가질 수 있는 영역에서 실제로 우리가 가지고 학습할 수 있는 data는 굉장히 희소한 data들이다. 예를 들어, 우측과 같이 real data가 굉장히 밀집된 분포를 가지고 있다고 했을 때, 이세상 모든 data를 위와 같은 분포로 취득할 수 있다고 하더라도 실제로 우리가 학습에 사용하는 data는 이 중에서 굉장히 sampling된 sparse한 data만을 이용해서 학습할 것이다. 그래서 굉장히 local한 data만을 이용해서 학습할 수 있다는 한계점이 존재한다.
The training dataset and real data always have gaps
 그렇기 때문에 training data와 real data 사이에는 항상 gap이 존재한다. 우리가 항상 training data를 믿고 사용하는 것 자체가 real data를 분석하는데 최적의 조건을 만족하지 못하고 있다는 것이다. 예를 들어, 학습에 사용하는 training data가 정상적인 밝기의 image나 어두운 image로만 구성되어 있다고 가정해보자. 그리고 만약 testing을 진행한다고 했을 때 정상적인 밝기가 아니라 굉장히 밝은 image가 input으로 주어진다고 해보자. 이러한 경우에 training 시킨 모델이 이러한 image를 한번도 본 적이 없기 때문에 혼선을 발생시켜서 성능이 떨어지거나 예측불가능한 결과를 만들 것이다. 이러한 dataset 자체가 전체적인 것을 커버하지 못하기 때문에 이부분에 대해서 신중하게 접근할 필요가 생기는 것이다.
그렇기 때문에 training data와 real data 사이에는 항상 gap이 존재한다. 우리가 항상 training data를 믿고 사용하는 것 자체가 real data를 분석하는데 최적의 조건을 만족하지 못하고 있다는 것이다. 예를 들어, 학습에 사용하는 training data가 정상적인 밝기의 image나 어두운 image로만 구성되어 있다고 가정해보자. 그리고 만약 testing을 진행한다고 했을 때 정상적인 밝기가 아니라 굉장히 밝은 image가 input으로 주어진다고 해보자. 이러한 경우에 training 시킨 모델이 이러한 image를 한번도 본 적이 없기 때문에 혼선을 발생시켜서 성능이 떨어지거나 예측불가능한 결과를 만들 것이다. 이러한 dataset 자체가 전체적인 것을 커버하지 못하기 때문에 이부분에 대해서 신중하게 접근할 필요가 생기는 것이다.
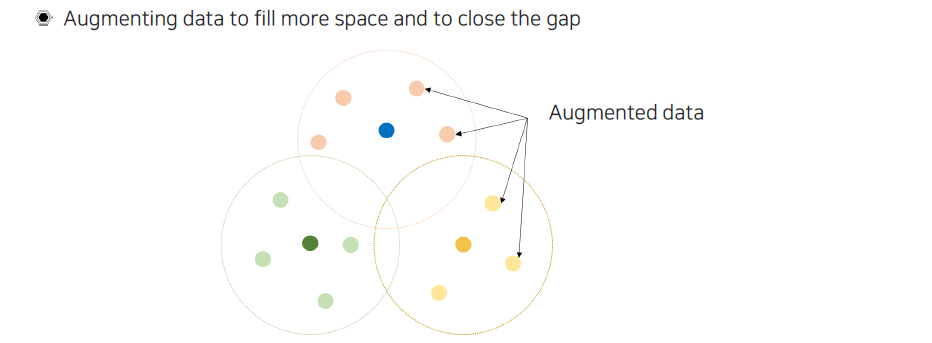 이러한 문제를 해결하지는 못해도 완화시킬 수 있는 방법이 바로 augmentation 기법이다. Data augmentation이라는 것은 sample space에서 실제로 가지고 있는 sample이 적다고 하더라도 주변의 빈 공간들을 채워서 real data에 조금이라도 근접할 수 있도록 만들어주는 과정이다. 지금부터는 이렇게 augmented data를 만드는 방법에는 어떠한 것들이 있는지 알아볼 것이다.
이러한 문제를 해결하지는 못해도 완화시킬 수 있는 방법이 바로 augmentation 기법이다. Data augmentation이라는 것은 sample space에서 실제로 가지고 있는 sample이 적다고 하더라도 주변의 빈 공간들을 채워서 real data에 조금이라도 근접할 수 있도록 만들어주는 과정이다. 지금부터는 이렇게 augmented data를 만드는 방법에는 어떠한 것들이 있는지 알아볼 것이다.
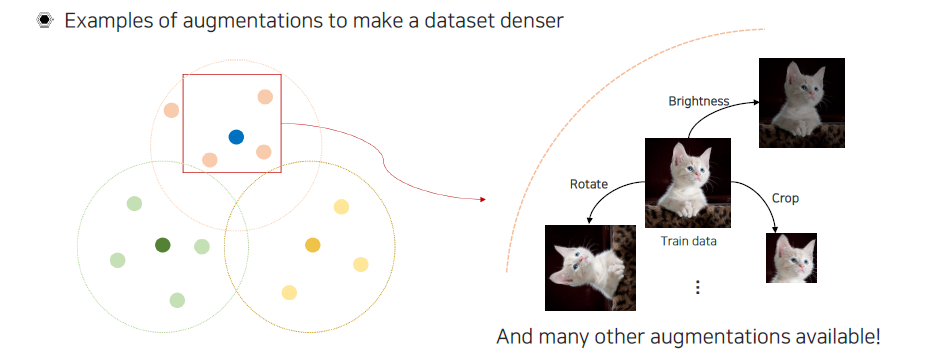 Dataset의 sample space 분포를 굉장히 밀집하게 만드는 것에는 여러가지 방법이 존재한다. 대표적으로 하나의 data가 주어졌을 때 밝기를 바꾸거나 일부분을 자르거나 혹은 전체를 회전시키는 등 기존의 data를 변형시켜서 가상의 data를 만들 수가 있다.
Dataset의 sample space 분포를 굉장히 밀집하게 만드는 것에는 여러가지 방법이 존재한다. 대표적으로 하나의 data가 주어졌을 때 밝기를 바꾸거나 일부분을 자르거나 혹은 전체를 회전시키는 등 기존의 data를 변형시켜서 가상의 data를 만들 수가 있다.
Image data augmentation
 특히, image data를 augmentation하는 방법에는 다양한 것들이 존재한다. 밝기를 바꾸는 등의 photometric한 방법도 있으며 영상을 변형시키는 geometric한 방법들도 존재한다. 이러한 것들은 OpenCV와 같은 library 등을 통해서 쉽게 구현이 가능할 것이다. 결국 이렇게 함으로써 training dataset의 distribution이 real dataset의 distribution을 어느정도 커버할 수 있도록 만들어 줄 수 있다.
특히, image data를 augmentation하는 방법에는 다양한 것들이 존재한다. 밝기를 바꾸는 등의 photometric한 방법도 있으며 영상을 변형시키는 geometric한 방법들도 존재한다. 이러한 것들은 OpenCV와 같은 library 등을 통해서 쉽게 구현이 가능할 것이다. 결국 이렇게 함으로써 training dataset의 distribution이 real dataset의 distribution을 어느정도 커버할 수 있도록 만들어 줄 수 있다.
Brightness adjustment
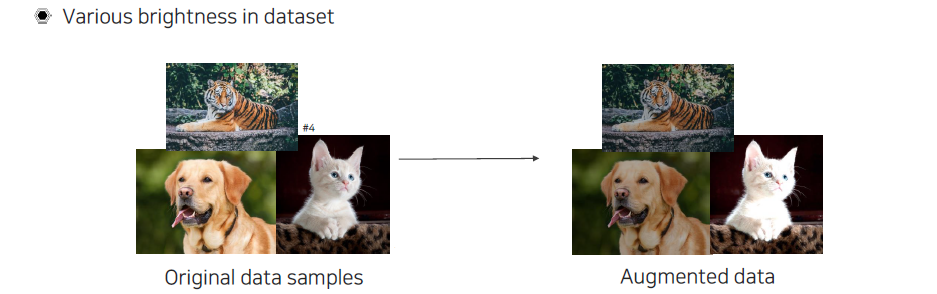 먼저 brightness쪽으로 augmentation을 적용하게 되면 어둡게 만들거나 밝게 만들어서 밝기의 변화가 생기게 하면 된다.
먼저 brightness쪽으로 augmentation을 적용하게 되면 어둡게 만들거나 밝게 만들어서 밝기의 변화가 생기게 하면 된다.
 이는 간단하게 color 값에다가 offset을 더해주면 된다. 이때 핵심은 너무 큰 값이나 음수가 나오지 않도록 clipping 과정이 필요하다는 것이다.
이는 간단하게 color 값에다가 offset을 더해주면 된다. 이때 핵심은 너무 큰 값이나 음수가 나오지 않도록 clipping 과정이 필요하다는 것이다.
Rotate, flip
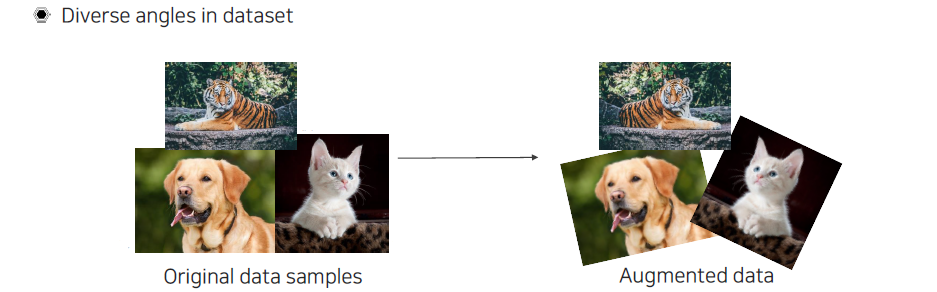 이번에는 영상을 회전시키는 rotation이나 뒤집는 flipping이 있다.
이번에는 영상을 회전시키는 rotation이나 뒤집는 flipping이 있다.
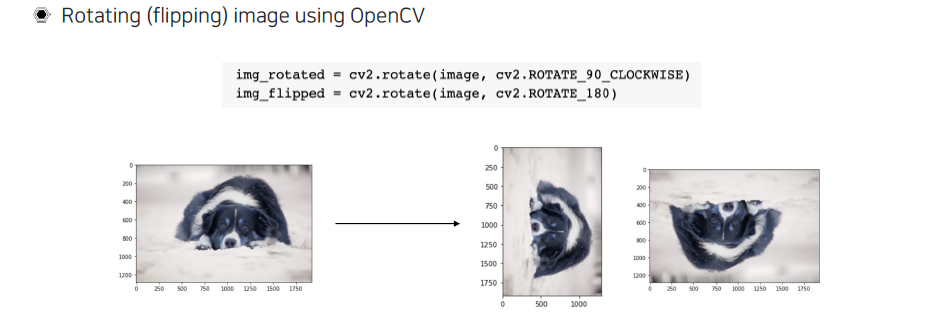 Rotation나 flipping도 기본적으로 OpenCV library를 통해서 쉽게 구현이 가능하다.
Rotation나 flipping도 기본적으로 OpenCV library를 통해서 쉽게 구현이 가능하다.
Crop
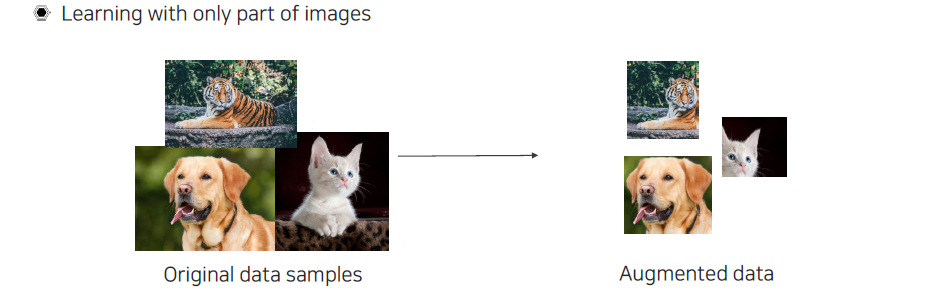 Crop은 영상 내에서 특정 크기로 임의로 잘라내는 것이다. 머리만 보더라도 전체를 본 것과 같이 학습이 되는 것이 좋을 것이고, 이러한 과정을 통해서 robust한 모델을 만들어야 한다.
Crop은 영상 내에서 특정 크기로 임의로 잘라내는 것이다. 머리만 보더라도 전체를 본 것과 같이 학습이 되는 것이 좋을 것이고, 이러한 과정을 통해서 robust한 모델을 만들어야 한다.
 Crop은 마찬가지로 array를 특정 범위로 결정해서 잘라낼 수 있을 것이다.
Crop은 마찬가지로 array를 특정 범위로 결정해서 잘라낼 수 있을 것이다.
Affine transformation
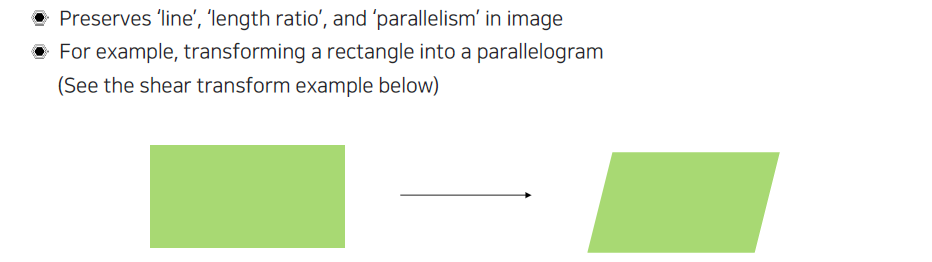 Affine transformation은 평행을 유지하는 transformation으로 사다리꼴 형태로 살짝 틀어주는 것이다.
Affine transformation은 평행을 유지하는 transformation으로 사다리꼴 형태로 살짝 틀어주는 것이다.
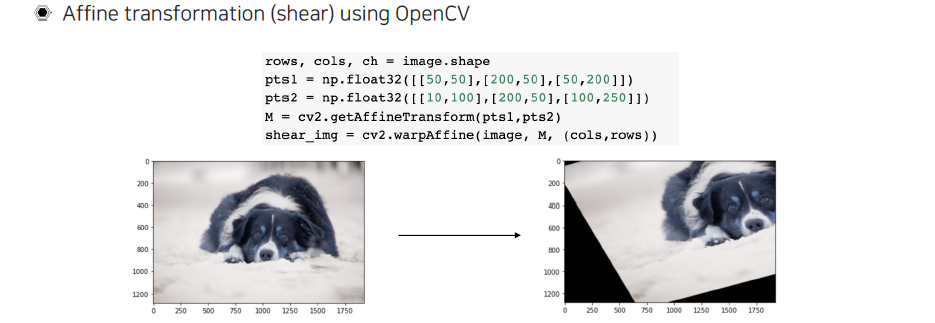 Affine transformation은 control point 3개를 이용해서 영상을 틀어줄 수 있다. 여러 각도에서 찍은 사진 구도 등을 핸들링 할 수 있을 것이다.
Affine transformation은 control point 3개를 이용해서 영상을 틀어줄 수 있다. 여러 각도에서 찍은 사진 구도 등을 핸들링 할 수 있을 것이다.
Modern augmentation techniques
CutMix
 지금까지는 기본적인 photometric transformation이나 geometric transformation만 영상에 적용해서 변환시켰는데, 현대에는 다양한 기법들이 등장해서 효과를 많이 볼 수 있었다. 모델의 관점이나 machine learning의 성능 관점에서 성능의 향상을 보여준 여러가지 사례가 존재하고, 이중 대표적인 방법이 바로 CutMix이다. CutMix 이전에도 MixUp과 같은 mix 계열의 augmentation 기법들이 많이 등장했다.
지금까지는 기본적인 photometric transformation이나 geometric transformation만 영상에 적용해서 변환시켰는데, 현대에는 다양한 기법들이 등장해서 효과를 많이 볼 수 있었다. 모델의 관점이나 machine learning의 성능 관점에서 성능의 향상을 보여준 여러가지 사례가 존재하고, 이중 대표적인 방법이 바로 CutMix이다. CutMix 이전에도 MixUp과 같은 mix 계열의 augmentation 기법들이 많이 등장했다.
CutMix는 image가 2개가 있을 때, 한 image 일부 영역에 다른 image의 일부 영역을 잘라서 붙이는 것이다. 이렇게하면 모델이 어떠한 object를 보았을 때 더욱 잘 localization 한다고 볼 수 있다. 영상을 대충 보는 것이 아니라 세분화해서 자세히 봐서 추론할 수 있는 능력이 생기는 것이다.
Generating new training image
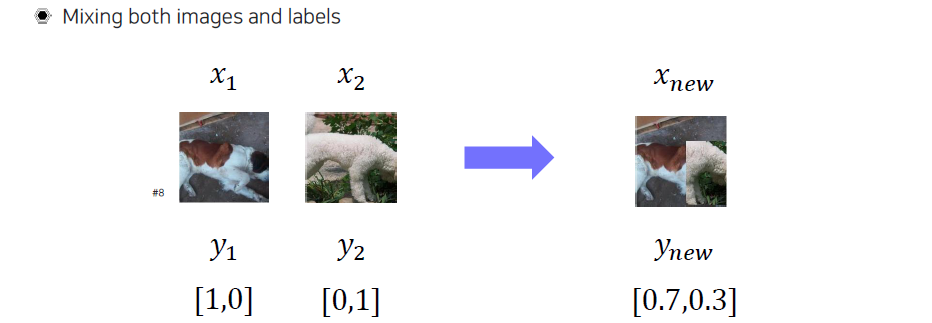 두가지 영상을 퍼즐처럼 붙이는 것뿐만 아니라, image와 label이 동시에 존재하는 supervised-learning의 경우에 영상들을 붙이는 비율에 따라서 one-hot vector 형태의 label도 일정 비율로 바꿔줄 수가 있다.
두가지 영상을 퍼즐처럼 붙이는 것뿐만 아니라, image와 label이 동시에 존재하는 supervised-learning의 경우에 영상들을 붙이는 비율에 따라서 one-hot vector 형태의 label도 일정 비율로 바꿔줄 수가 있다.
RandAugment
 굉장히 많은 augmentation 기법들이 존재하는데, 어떠한 방법이 내가 풀고자 하는 문제에 가장 최적의 augmenation인지를 결정하는 과정도 여러번 해보고 결정할 수 있을 것이다. 문제는 이러한 기법들을 하나만 사용하는 것이 아니라 조합해서 사용이 가능할 수도 있다는 것이다. 결국, 조합 문제가 되면 지수승으로 complexity가 올라가서 최적의 조합을 찾는 것은 굉장히 어려운 문제가 될 것이다. 여러번 반복해서 겨우 하나를 찾게 될텐데, 이 또한 어느정도 한계가 존재할 것이다. 무작정 시도를 하는 것 보다 자동적으로 효율적으로 찾을 수 있을지에 대한 방법으로 소개된 것이 RandAugment이다. 위에 정리된 기법들이 random하게 sampling 될 수 있는 다양한 augmentation 기법들이다.
굉장히 많은 augmentation 기법들이 존재하는데, 어떠한 방법이 내가 풀고자 하는 문제에 가장 최적의 augmenation인지를 결정하는 과정도 여러번 해보고 결정할 수 있을 것이다. 문제는 이러한 기법들을 하나만 사용하는 것이 아니라 조합해서 사용이 가능할 수도 있다는 것이다. 결국, 조합 문제가 되면 지수승으로 complexity가 올라가서 최적의 조합을 찾는 것은 굉장히 어려운 문제가 될 것이다. 여러번 반복해서 겨우 하나를 찾게 될텐데, 이 또한 어느정도 한계가 존재할 것이다. 무작정 시도를 하는 것 보다 자동적으로 효율적으로 찾을 수 있을지에 대한 방법으로 소개된 것이 RandAugment이다. 위에 정리된 기법들이 random하게 sampling 될 수 있는 다양한 augmentation 기법들이다.
 Augmentation을 적용할 때 어떠한 augmenation을 선택할지가 hyperparameter이고, 하나가 선택이 되었을 때 얼마만큼 강하게 적용할 것인지가 또다른 hyperparameter이다.
Augmentation을 적용할 때 어떠한 augmenation을 선택할지가 hyperparameter이고, 하나가 선택이 되었을 때 얼마만큼 강하게 적용할 것인지가 또다른 hyperparameter이다.
 Sampling을 하게될 때 결국에는 policy라는 것을 sampling하게 되는데, 이는 몇개의 augmentation을 어떠한 순서로 적용할지를 결정하는 과정이다. 이렇게 sampling된 policy를 이용해서 network를 학습하고 평가하는 과정으로 진행된다.
Sampling을 하게될 때 결국에는 policy라는 것을 sampling하게 되는데, 이는 몇개의 augmentation을 어떠한 순서로 적용할지를 결정하는 과정이다. 이렇게 sampling된 policy를 이용해서 network를 학습하고 평가하는 과정으로 진행된다.
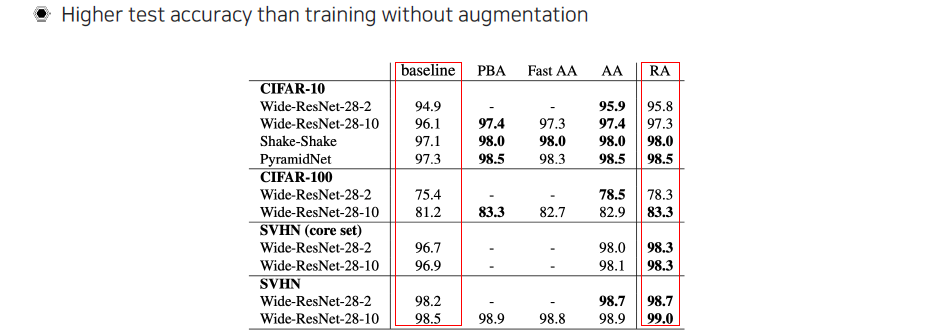 Augmentation의 결과를 보았을 때 generalization이 잘 되었는지 확인할 수 있다.
Augmentation의 결과를 보았을 때 generalization이 잘 되었는지 확인할 수 있다.
