
어떻게하면 기존에 이미 학습이 된 정보를 활용할 수 있는지, 그리고 학습할 때 unlabeled data를 원하는 target task에 대해서 어떻게 하면 실용적으로 성능을 끌어올릴 수 있는 방향으로 사용할 수 있는지에 대해서 알아보고자 한다.
Leveraging pre-trained information
우선 어떻게 하면 model에 녹아져 있는 pre-train이 된 knowledge를 활용할 수 있는지에 대해서 알아볼 것이다.
Transfer learning
The high-quality dataset is expensive and hard to obtain
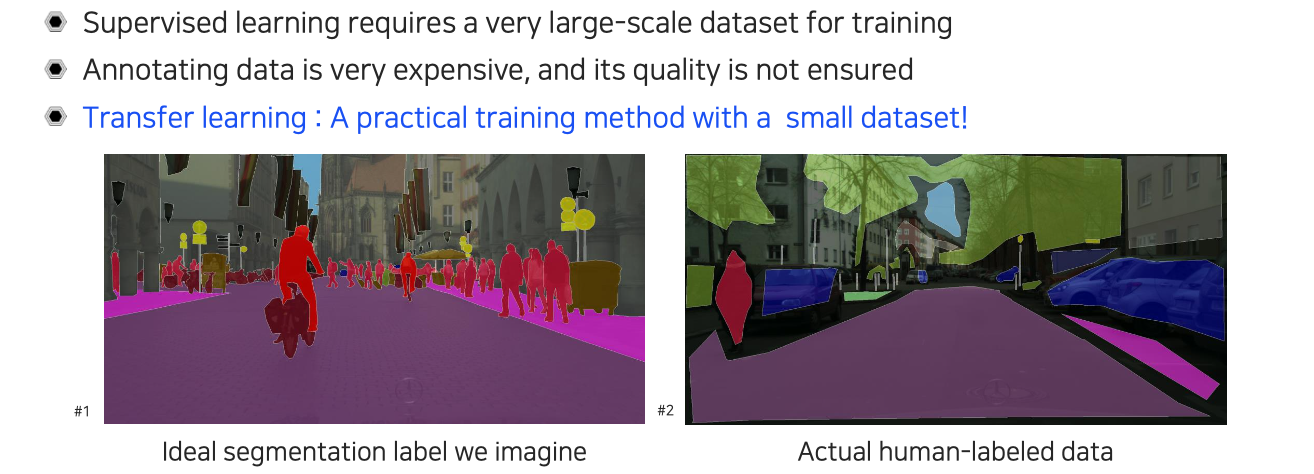 이렇게 high quality의 data가 있어야 기존의 supervised-learning 방식으로 model을 학습시킬 수 있었다. 즉, 높은 성능을 달성하기 위해서 supervised-learning에서는 data의 quality가 높고 많아야 한다. 여기서 문제는 이러한 high quality dataset을 얻는 것은 굉장히 비싸거나 quality가 보장이 되지 않는다. 결국에는 사람들이 Labeling을 직접 하게 되고, 학습할 때는 사람의 행동을 model이 따라하도록 만든다. Labeling을 잘하기 위해서는 정교하게 전문가를 고용해서 시킬 수가 있다. 하지만 요즘은 cloud sourcing이라 해서 많은 사람들이 누구나 labeling 작업에 참여할 수가 있다. 그렇기 때문에 결국 사람들이 하는 행동이기에 quality를 보장받기가 어려워진다. 여러가지 이유로부터 quality가 좋고 많은 양의 dataset을 구하기가 어려워 현실적으로는 적은 양의 dataset으로부터 학습을 시작하곤 한다. 하지만 적은 양의 dataset으로는 높은 성능을 이끌어내기 어렵다. 그래서 이렇게 적은 양으로도 높은 성능에 도달할 수 있도록 제안된 방법 중 하나가 transfer learning이다.
이렇게 high quality의 data가 있어야 기존의 supervised-learning 방식으로 model을 학습시킬 수 있었다. 즉, 높은 성능을 달성하기 위해서 supervised-learning에서는 data의 quality가 높고 많아야 한다. 여기서 문제는 이러한 high quality dataset을 얻는 것은 굉장히 비싸거나 quality가 보장이 되지 않는다. 결국에는 사람들이 Labeling을 직접 하게 되고, 학습할 때는 사람의 행동을 model이 따라하도록 만든다. Labeling을 잘하기 위해서는 정교하게 전문가를 고용해서 시킬 수가 있다. 하지만 요즘은 cloud sourcing이라 해서 많은 사람들이 누구나 labeling 작업에 참여할 수가 있다. 그렇기 때문에 결국 사람들이 하는 행동이기에 quality를 보장받기가 어려워진다. 여러가지 이유로부터 quality가 좋고 많은 양의 dataset을 구하기가 어려워 현실적으로는 적은 양의 dataset으로부터 학습을 시작하곤 한다. 하지만 적은 양의 dataset으로는 높은 성능을 이끌어내기 어렵다. 그래서 이렇게 적은 양으로도 높은 성능에 도달할 수 있도록 제안된 방법 중 하나가 transfer learning이다.
Benefits of using transfer learning
 Transfer learning은 기존에 잘 학습되어 있던 knowledge를 어떻게하면 우리가 원하는 새로운 task에 빠르게 적용을 시킬 수 있느냐에 관한 문제를 다룬다. 여기서 pre-trained knowledge라고 하는 것은 중간에 학습된 feature를 의미하게 된다.
Transfer learning은 기존에 잘 학습되어 있던 knowledge를 어떻게하면 우리가 원하는 새로운 task에 빠르게 적용을 시킬 수 있느냐에 관한 문제를 다룬다. 여기서 pre-trained knowledge라고 하는 것은 중간에 학습된 feature를 의미하게 된다.
Motivational observation: Similar datasets share common information
 이러한 동기는 위와 같이 4개의 dataset을 모아봤을 때 모두가 비슷한 정보를 공유한다는 점에서 생기게 되었다. 서로 완전히 다른 dataset이지만 사실 많은 content가 overlap 되어 있는 경우가 많다. 이 말은 하나의 dataset으로부터 얻은 knowledge는 다른 dataset으로 transfer될 수 있다는 이야기와 같다. 하나의 dataset으로 학습을 하고 다른 dataset에 적용했을 때 해당 dataset으로 학습한 것만큼 성능은 보장이 안되지만 어느정도는 model이 이해력을 가지고 있다고 가정할 수 있을 것이다. 이러한 가정과 직관에 의해서 디자인 된 학습 방법이 바로 transfer learning이다.
이러한 동기는 위와 같이 4개의 dataset을 모아봤을 때 모두가 비슷한 정보를 공유한다는 점에서 생기게 되었다. 서로 완전히 다른 dataset이지만 사실 많은 content가 overlap 되어 있는 경우가 많다. 이 말은 하나의 dataset으로부터 얻은 knowledge는 다른 dataset으로 transfer될 수 있다는 이야기와 같다. 하나의 dataset으로 학습을 하고 다른 dataset에 적용했을 때 해당 dataset으로 학습한 것만큼 성능은 보장이 안되지만 어느정도는 model이 이해력을 가지고 있다고 가정할 수 있을 것이다. 이러한 가정과 직관에 의해서 디자인 된 학습 방법이 바로 transfer learning이다.
Approach 1: Transfer knowledge from a pre-trained task to a new task
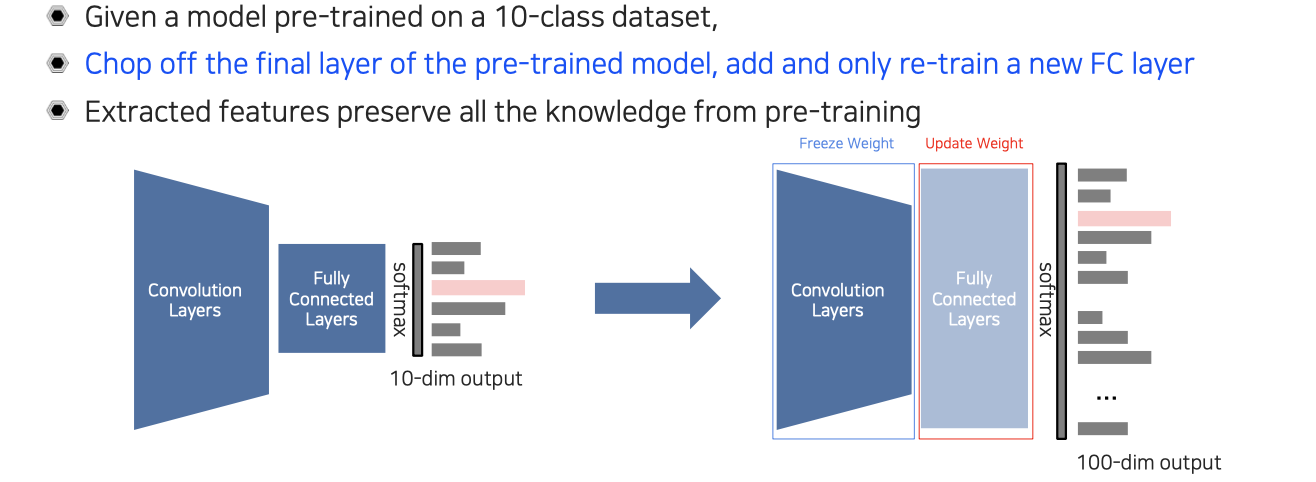 Transfer learning의 첫번째 접근 방식은 knowledge를 transfer시키는 것이다. 예를 들어 위와 같이 10개의 class에 대해서 미리 학습이 된 model이 있다고 해보자. 새로운 task는 100개의 class에 대해서 학습을 진행하고자 한다. 10개와 100개를 다루는 문제는 다른 문제이다. 그래서 사전에 10개의 class에 대해서 학습된 model을 그대로 사용하면 안되고, 마지막 layer를 잘라서 새로운 fully connected layer를 이어붙여서 100개의 class에 대한 결과가 나오도록 model을 교체해주는 것이다. 그리고 새로 교체된 부분만 다시 100개의 class에 대해서 학습을 진행하고 기존의 convolution layer 부분은 weight를 고정시켜 주는 것이다. 이렇게 하면 새로 교체된 layer에 대해서만 weight가 학습이 될 것이다.
Transfer learning의 첫번째 접근 방식은 knowledge를 transfer시키는 것이다. 예를 들어 위와 같이 10개의 class에 대해서 미리 학습이 된 model이 있다고 해보자. 새로운 task는 100개의 class에 대해서 학습을 진행하고자 한다. 10개와 100개를 다루는 문제는 다른 문제이다. 그래서 사전에 10개의 class에 대해서 학습된 model을 그대로 사용하면 안되고, 마지막 layer를 잘라서 새로운 fully connected layer를 이어붙여서 100개의 class에 대한 결과가 나오도록 model을 교체해주는 것이다. 그리고 새로 교체된 부분만 다시 100개의 class에 대해서 학습을 진행하고 기존의 convolution layer 부분은 weight를 고정시켜 주는 것이다. 이렇게 하면 새로 교체된 layer에 대해서만 weight가 학습이 될 것이다.
이렇게 되면 convolution layer 부분은 feature extractor로 볼 수 있다. 이렇게 학습된 feature들은 기존 dataset에 대한 knowledge를 포함하게 될 것이고, 이 feature들은 고정시킨 채로 feature를 이용해서 판단하는 상위 레벨만 새롭게 학습을 하자는 것이다. 이렇게 일부분만 학습을 다시하기 때문에 수렴 속도가 굉장히 빠르고 계산 속도도 빨라지며 시간도 단축될 것이다.
Approach 2: Fine-tuning the whole model
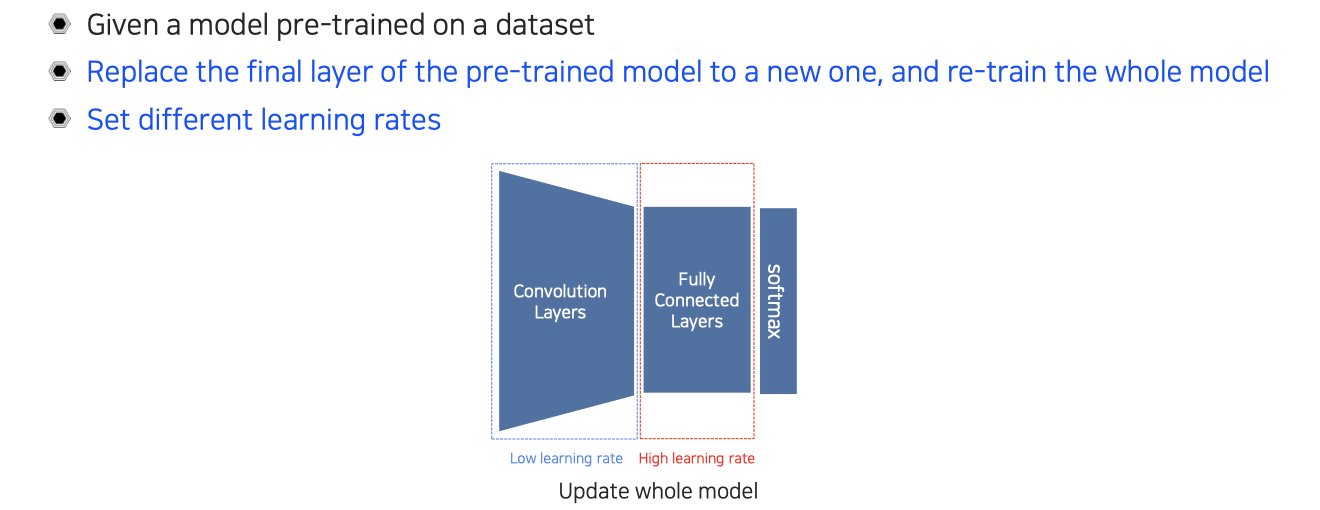 하지만 만약에 extractor로 뽑은 feature가 새로 적용시키려는 domain과 상대적으로 overlap이 적고 adaptation이 많이 필요하다고 하면은 전체 model을 전부 fine-tuning하는 접근 방식도 생각해볼 수 있다. 그래서 두번째 접근 방법은 먼저 첫번째 방법과 마찬가지로 하나의 model을 pre-training 시키고 똑같이 last layer는 새로운 layer로 교체해준다. 그리고 random initialization을 시켜주는데, 이번에는 다시 학습을 시킬 때 마지막 layer만 다시 하는 것이 아니라 전체를 다시 시키는 것이다.
하지만 만약에 extractor로 뽑은 feature가 새로 적용시키려는 domain과 상대적으로 overlap이 적고 adaptation이 많이 필요하다고 하면은 전체 model을 전부 fine-tuning하는 접근 방식도 생각해볼 수 있다. 그래서 두번째 접근 방법은 먼저 첫번째 방법과 마찬가지로 하나의 model을 pre-training 시키고 똑같이 last layer는 새로운 layer로 교체해준다. 그리고 random initialization을 시켜주는데, 이번에는 다시 학습을 시킬 때 마지막 layer만 다시 하는 것이 아니라 전체를 다시 시키는 것이다.
Convolution layer 부분은 pre-training된 결과로 initialization 되어 있고, fully connected layer는 random weight로 intialization이 되어 있다. 그렇기 때문에 뒷부분은 전혀 새로운 task에 대한 knowledge가 전혀 없고, 앞부분은 기존 task의 knowledge를 포함하고 있게 된다. 그래서 새로운 task에 대해서는 learning rate를 높게해서 빨리 적응하고 배우라는 식으로 지정하고 앞부분은 기존의 knowledge가 어느정도 있어서 learning rate를 낮게해서 기존의 knowledge는 유지하면서 새로운 task에 대해서 조금씩 adaptation을 하자는 식으로 learning rate를 서로 다르게 설정해서 전체 network를 학습하는 것이다.
Knowledge distillation
Passing what model learned to 'another' smaller model (Teacher-student learning)
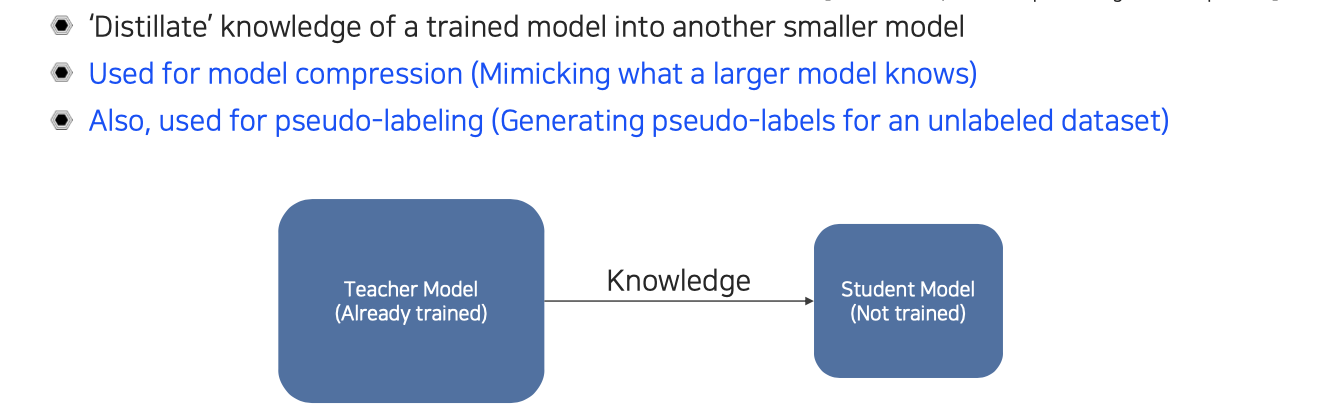 Knowledge distillation은 transfer learning의 특수한 경우에 해당한다. 위에서 이야기한 두가지 방식은 굉장히 간단해서 구현도 크게 어렵지 않다. 우리가 이 방법들 보다 조금 더 advanced 하게 knowledge를 transfer시키고 싶다고 하면 knowledge distillation 방식을 고려해볼 수 있을 것이다. 이 방법은 쉽지만 굉장히 실용적일 것이고, 이는 다른 말로 teacher-student learning이라고도 한다.
Knowledge distillation은 transfer learning의 특수한 경우에 해당한다. 위에서 이야기한 두가지 방식은 굉장히 간단해서 구현도 크게 어렵지 않다. 우리가 이 방법들 보다 조금 더 advanced 하게 knowledge를 transfer시키고 싶다고 하면 knowledge distillation 방식을 고려해볼 수 있을 것이다. 이 방법은 쉽지만 굉장히 실용적일 것이고, 이는 다른 말로 teacher-student learning이라고도 한다.
Teacher를 크게 사용하고 student를 작게 사용하거나, 그 반대로 사용할 수도 있을 것이다. 아니면 model 자체는 둘 다 똑같은 model을 사용하면서 teacher는 pre-trained network를 사용해서 똑같은 정도의 parameter를 가지는 다른 architecture에 전달을 해서 학습을 시키는 등 다양한 옵션이 가능하다. 주로 사용하는 것은 비슷한 크기의 network를 사용하기 보다는 student는 조금 더 작은 model을 사용해서 주로 model compression에 많이 사용이 된다. 결국에는 사전에 학습된 model의 knowledge를 더 작은 model에 옮겨서 가르친다고 생각하면 된다.
또 다른 식으로 보게 되면, 이미 사전에 학습된 teacher network가 어떠한 input을 넣었을 때 output을 생성하게 되는데, 이러한 output을 label로 사용하는 것이다. 우리는 이를 가짜 label이라고 해서 pseudo-labeling이라고 한다. Label이 되어 있지 않은 dataset이 주어졌을 때, teacher network를 이용해서 unlabeled data를 processing해서 미리 pseudo-label들을 전부 만들어 놓는 것이다. 이렇게 생성된 label들을 이용해서 supervised-learning을 할 수 있을 것이다. 그래서 학습이 되지 않은 student model에는 pseudo-label로 supervised 된 data를 활용해서 학습을 시킬 수가 있다. Teacher network가 예측한 pseudo-label을 이용해서 student network를 가르치는 것이기 때문에 지식을 전수하고 받는다고 볼 수 있다.
Teacher-student network structure
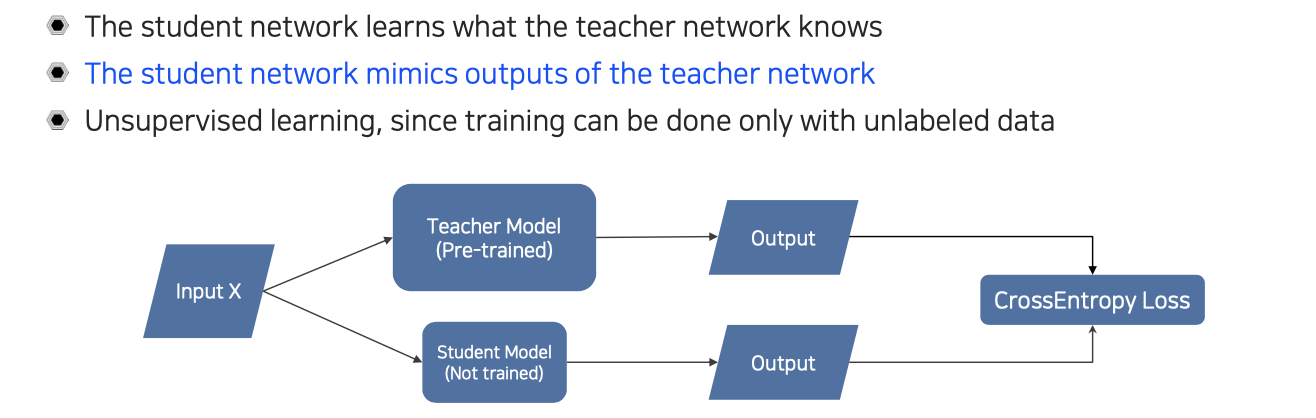 기본적인 teacher-student network는 위와 같은 구조로 되어있다. 어떠한 dataset이 주어졌을 때 pre-trained 된 teacher network와 학습이 되지 않고 random intialization이 된 student network가 있게 된다. 결국에는 student가 teacher가 알고있는 것이 무엇인지를 따라하는 형식으로 학습이 진행된다. 실제 구현할 때에는 teacher의 output과 student의 output을 비교해서 학습을 시키게 된다. 기본적으로 supervised-learning에서는 cross-entropy loss를 사용하는데, output의 특성이 one-hot vector가 아니라 다른 형태를 가지게 된다면 cross-entropy loss와 유사한 다른 형태로 변형이 될 것이다. 이러한 방식을 사용할 때에는 label이 되어있는 data를 사용하지 않아도 상관없다. Unlabeled data가 주어졌다고 하더라도 teacher model이 pseudo-labeling을 할 수 있는 기능이 존재하기 때문에 마치 supervised-learning인 것처럼 활용할 수도 있다.
기본적인 teacher-student network는 위와 같은 구조로 되어있다. 어떠한 dataset이 주어졌을 때 pre-trained 된 teacher network와 학습이 되지 않고 random intialization이 된 student network가 있게 된다. 결국에는 student가 teacher가 알고있는 것이 무엇인지를 따라하는 형식으로 학습이 진행된다. 실제 구현할 때에는 teacher의 output과 student의 output을 비교해서 학습을 시키게 된다. 기본적으로 supervised-learning에서는 cross-entropy loss를 사용하는데, output의 특성이 one-hot vector가 아니라 다른 형태를 가지게 된다면 cross-entropy loss와 유사한 다른 형태로 변형이 될 것이다. 이러한 방식을 사용할 때에는 label이 되어있는 data를 사용하지 않아도 상관없다. Unlabeled data가 주어졌다고 하더라도 teacher model이 pseudo-labeling을 할 수 있는 기능이 존재하기 때문에 마치 supervised-learning인 것처럼 활용할 수도 있다.
Knowledge distillation
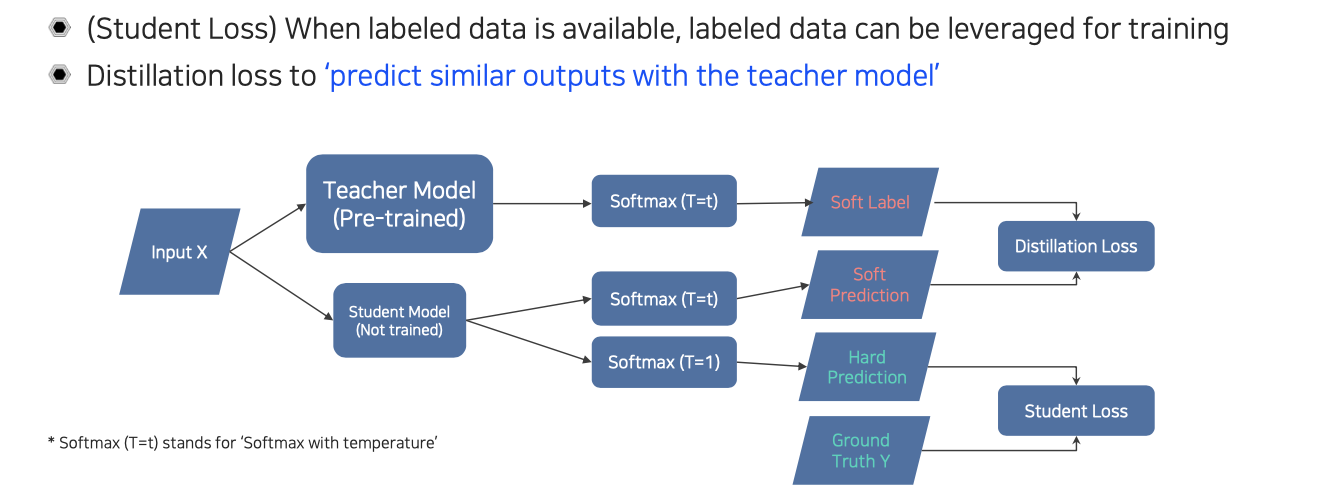 Unlabeled data를 활용할 수도 있지만 labeled data를 사용할 수도 있다. 이러한 경우에도 labeled data를 학습에 유용하게 활용할 수 있고, 이를 student loss라고 불러 학습시키게 된다. Distillation loss와 student loss를 전부 활용할 수가 있다.
Unlabeled data를 활용할 수도 있지만 labeled data를 사용할 수도 있다. 이러한 경우에도 labeled data를 학습에 유용하게 활용할 수 있고, 이를 student loss라고 불러 학습시키게 된다. Distillation loss와 student loss를 전부 활용할 수가 있다.
Distillation loss는 위에서 설명한 것처럼 teacher의 output을 따라하도록 만드는 loss이다. 그래서 위의 구조에서 보다시피 distillation loss와 student loss를 모두 활용하여 student network를 학습할 수 있다. Student model을 학습할 때 teacher model은 고정된 weight를 사용하게 된다. Teacher model에서는 softmax를 취해줘서 soft label을 만들게 되고, student model에서도 teacher와 마찬가지로 soft prediction이 생기게 된다. 이 둘 사이에서는 distillation loss를 계산하게 된다. 그리고 student model에서 또 다른 softmax를 취할 수가 있는데, 이때는 일반적인 softmax를 계산해서 hard prediction을 만들 수가 있다. 이것과 ground truth를 이용해서 student loss를 구해서 학습을 시키게 된다.
Hard label vs. Soft label
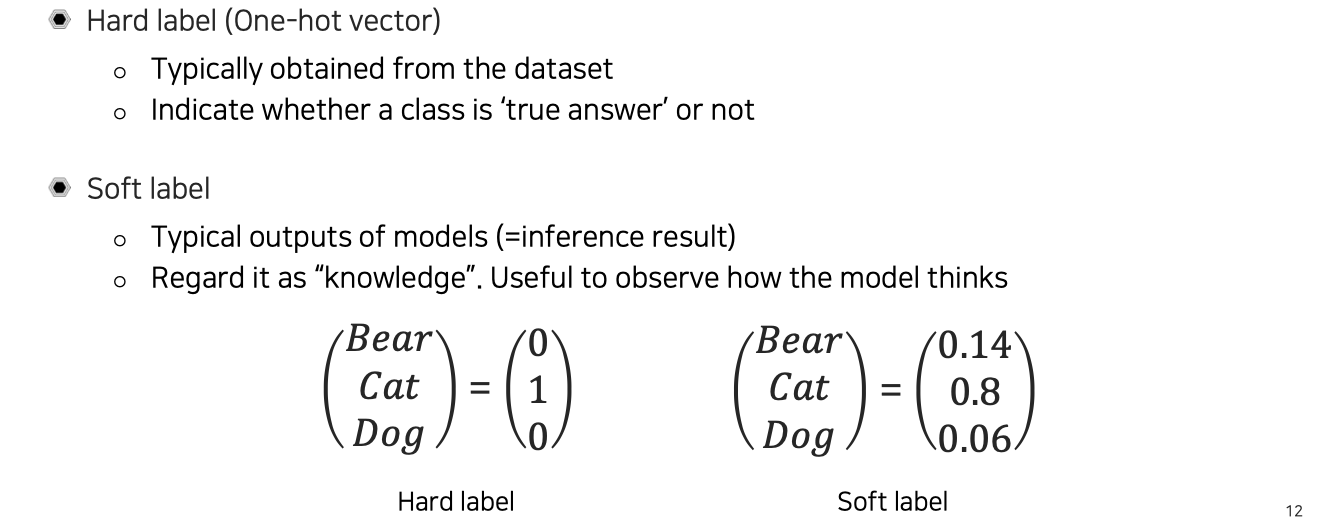 위에서 언급된 soft label과 hard label에 대해서 알아보고자 한다. Hard label은 우리가 이미 알고 있는 one-hot vector를 의미한다. 일반적인 dataset에서는 이러한 one-hot vector를 ground truth로 사용하게 된다.
위에서 언급된 soft label과 hard label에 대해서 알아보고자 한다. Hard label은 우리가 이미 알고 있는 one-hot vector를 의미한다. 일반적인 dataset에서는 이러한 one-hot vector를 ground truth로 사용하게 된다.
반면, soft label은 0과 1처럼 딱 떨어지는 것이 아니라 soft한 값을 가지게 되는데, 대부분 model의 output은 이와 같은 형태를 보일 것이다. 확실하게 0과 1로 구분할 수 없기 때문에 그 중간값으로 표현이 된다. 간단하게 생각하면 softmax를 통과한 확률값이라고 생각해도 된다. Soft label은 상대적인 결과를 볼 수 있기 때문에 model이 어떻게 생각하는지 볼 수가 있다.
Softmax with temperature()
 이렇게 soft label을 만들 때에는 0에서 1 사이의 값을 가지고 이를 모두 더해서 1이 되는 특성을 가지도록 만들게 된다. 가장 대표적인 방법이 바로 softmax인데, 여기서는 특별하게 temperature를 이용한 softmax를 사용하게 된다. Softmax에 temperature를 사용한다는 것은 output이 작은 값도 있고 큰 값도 있을텐데, 이 사이의 gap을 우리가 조절할 수 있도록 만드는 과정에서 temperature를 사용하는 것이다. 만약 temperature 값을 큰 값으로 사용하게 된다면, softmax의 input 값들 사이의 gap이 크더라도 이 차이를 줄여주는 역할을 수행하게 된다. 이렇게 되면 특정 값만 커지는 것을 막아줄 수 있게 된다.
이렇게 soft label을 만들 때에는 0에서 1 사이의 값을 가지고 이를 모두 더해서 1이 되는 특성을 가지도록 만들게 된다. 가장 대표적인 방법이 바로 softmax인데, 여기서는 특별하게 temperature를 이용한 softmax를 사용하게 된다. Softmax에 temperature를 사용한다는 것은 output이 작은 값도 있고 큰 값도 있을텐데, 이 사이의 gap을 우리가 조절할 수 있도록 만드는 과정에서 temperature를 사용하는 것이다. 만약 temperature 값을 큰 값으로 사용하게 된다면, softmax의 input 값들 사이의 gap이 크더라도 이 차이를 줄여주는 역할을 수행하게 된다. 이렇게 되면 특정 값만 커지는 것을 막아줄 수 있게 된다.
좌측과 같이 softmax의 temperature를 1로 두게 되면 softmax의 결과의 gap이 굉장히 커지게 만들 수가 있다. 이렇게 사용하는 것이 일반적인 softmax이며, 이를 hard prediction이라고 이름을 붙여서 soft prediction과 대조시킬 수가 있다. Temperature를 100으로 크게 설정하게 되면 똑같은 softmax input에 대해서 결과의 gap이 상당히 줄어든 것을 확인할 수 있다. 이렇게 soft prediction을 이용하면 대소비교가 가능한 다양한 값들을 사용할 수 있어서 knowledge를 transfer하기에 적합한 output이 만들어지게 된다.
Loss functions in knowledge distillation
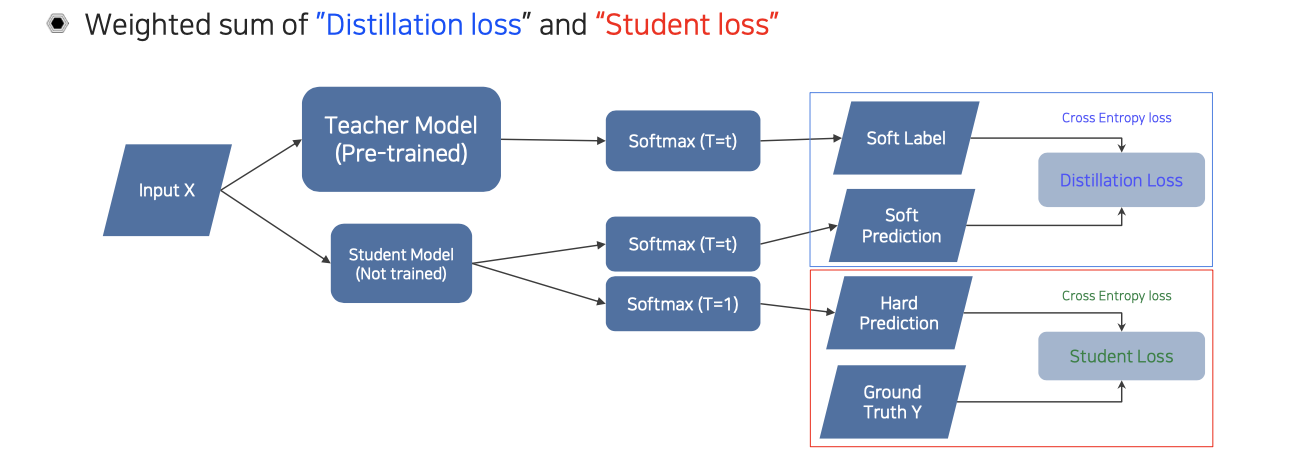 결국에는 soft prediction과 hard prediction을 활용해서 student model 자체를 학습할 때, distillation loss와 student loss를 weighted summation을 통해서 사용하게 된다. 물론 student loss를 사용하는 조건은 ground truth가 존재하는 경우에 해당한다. Label이 없으면 distillation loss만을 이용해서 학습을 하고, 이에 따라 어느정도 성능이 나오게 될 것이다.
결국에는 soft prediction과 hard prediction을 활용해서 student model 자체를 학습할 때, distillation loss와 student loss를 weighted summation을 통해서 사용하게 된다. 물론 student loss를 사용하는 조건은 ground truth가 존재하는 경우에 해당한다. Label이 없으면 distillation loss만을 이용해서 학습을 하고, 이에 따라 어느정도 성능이 나오게 될 것이다.
Intuition about the distillation loss and the student loss
 우리는 앞서 distillation loss와 student loss를 함께 사용한다고 했는데, 여기서 각 loss에 대한 직관이 어떠한지 이해해보고자 한다. 우선 distillation loss는 soft label과 soft prediction 사이에 cross-entropy를 이용해서 사용하게 되는데, 이는 student와 teacher의 probability distribution 자체의 difference를 구하는 것으로 볼 수가 있다. 그래서 teacher network가 무엇을 알고 있는지를 student network가 따라하도록 만드는 것이다. 그런데 여기서는 teacher network의 output을 그대로 따라하는 것이기 때문에 teacher network가 뱉어낸 답이 항상 맞는지는 보장할 수 없게 된다.
우리는 앞서 distillation loss와 student loss를 함께 사용한다고 했는데, 여기서 각 loss에 대한 직관이 어떠한지 이해해보고자 한다. 우선 distillation loss는 soft label과 soft prediction 사이에 cross-entropy를 이용해서 사용하게 되는데, 이는 student와 teacher의 probability distribution 자체의 difference를 구하는 것으로 볼 수가 있다. 그래서 teacher network가 무엇을 알고 있는지를 student network가 따라하도록 만드는 것이다. 그런데 여기서는 teacher network의 output을 그대로 따라하는 것이기 때문에 teacher network가 뱉어낸 답이 항상 맞는지는 보장할 수 없게 된다.
그래서 student loss를 이용해서 label에 의존하여 맞는 답인지를 판단할 수 있도록 보정이 가능해진다. 이는 student network의 output과 true label의 차이를 최소화시키는 식으로 학습이 진행이 된다. 여기서 student loss는 일반적인 cross-entropy loss가 되고, distillation loss는 모두 soft한 값이기 때문에 KL divergence로 convergence하게 될 것이다.
Learning without forgetting
Fine-tuning a model for both old and new tasks
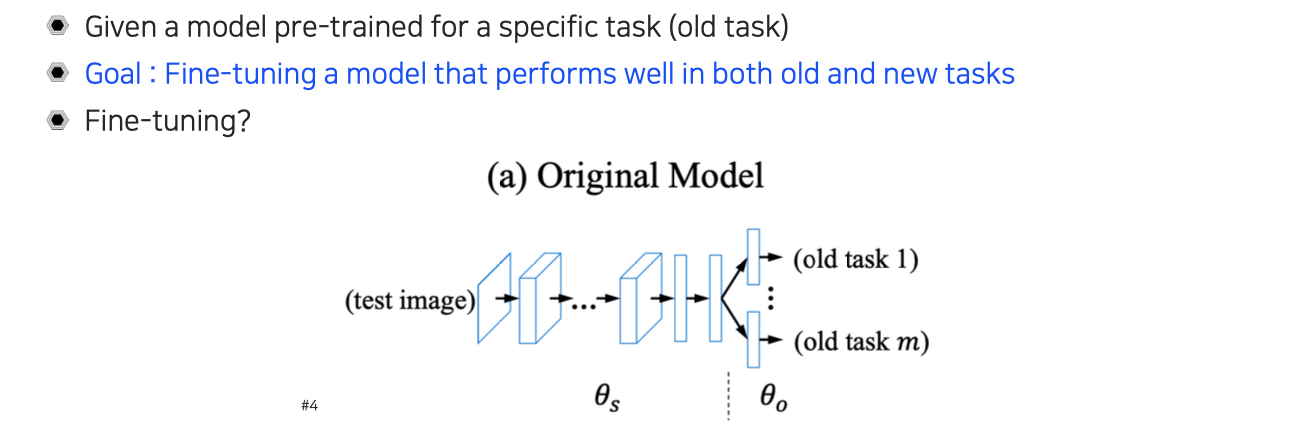 Knowledge distillation과 유사하지만 다른 문제를 들여다볼 수도 있다. 이번에는 새로운 task의 dataset에 대해서 knowledge distillation을 어떻게 활용할 수 있는지에 대해서 알아보고자 한다. Supervised dataset이 있을 때 student loss와 distillation loss를 적당히 함께 사용하면 될텐데, 이는 learning without forgetting 방식과 유사한 방식으로 볼 수 있다. 이는 old task에 학습된 model을 가지고 new task에 fine-tuning하는 task로 transfer learning하고 얼핏 유사하다.
Knowledge distillation과 유사하지만 다른 문제를 들여다볼 수도 있다. 이번에는 새로운 task의 dataset에 대해서 knowledge distillation을 어떻게 활용할 수 있는지에 대해서 알아보고자 한다. Supervised dataset이 있을 때 student loss와 distillation loss를 적당히 함께 사용하면 될텐데, 이는 learning without forgetting 방식과 유사한 방식으로 볼 수 있다. 이는 old task에 학습된 model을 가지고 new task에 fine-tuning하는 task로 transfer learning하고 얼핏 유사하다.
주어진 상황은 transfer learning과 유사하지만, 어떠한 model을 기존에 풀고 있었던 old task와 new task 전부에 대해서 전부 잘 작동하도록 fine-tuning하는 것이 여기서의 목표가 된다. 위와 같이 원래의 model이 있을 때 old task들이 위와 같이 존재하고, output들이 그대로 활용될 수 있도록 유지하면서 새로운 task에도 잘 작동하도록 모든 task에서 성능이 떨어지지 않도록 만드는 것이다.
Fine-tuning forgets old tasks
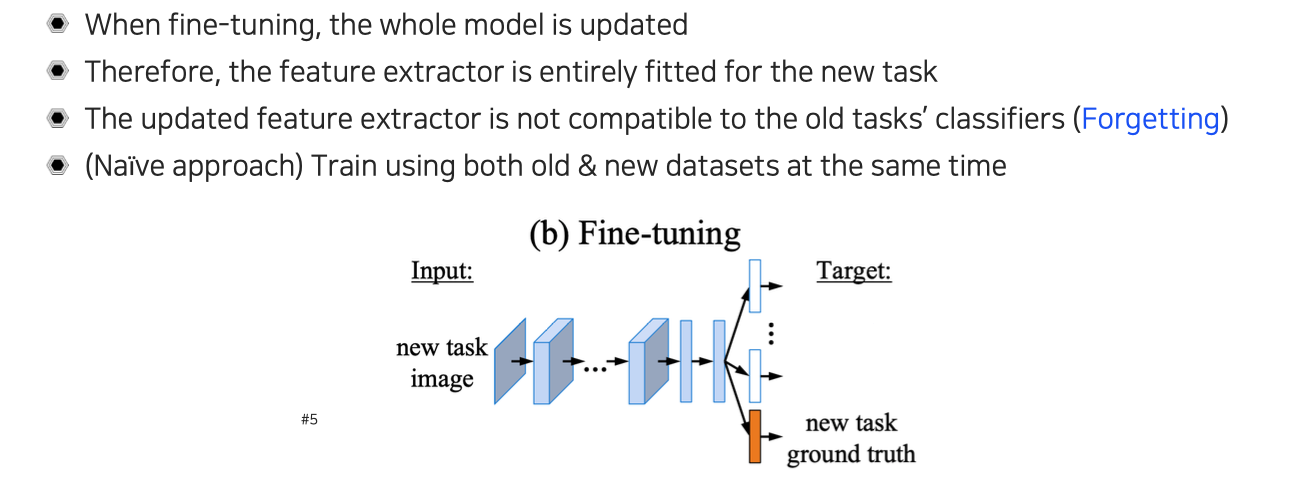 기존의 naive한 방법으로 fine-tuning을 해주면 성능의 한계를 보이게 된다. 그래서 모든 model을 update하는 fine-tuning을 사용할 때에는 새로운 task에 완전히 fitting을 하기 때문에 기존의 feature extractor 부분이 old task에 적용될 수 있는 feature하고 달라지게 된다. 기존의 old task classifier 부분과 호환성이 없어지게 되면서 forgetting effect가 발생하게 된다. 그래서 여기서 사용되는 classifier들은 고정이 되어 있고, 만약 feature extraction 부분이 바뀌었다고 한다면 새로운 task에 대해서 학습이 되면서 앞부분이 바뀌게 되면서 중간 결과도 바뀌게 될 것이다. 이렇게 되면 새로운 task에는 호환이 되지만 그 전에 고정되어 있던 task에는 호환성을 잃어버리게 된다. 간단한 해결 방법으로는 old task와 new task에 대해서 dataset을 모두 합쳐서 학습을 시키는 것이다. 이렇게 되면 naive하기는 하지만 기존 task에 대한 성능과 새로운 task에 대한 성능을 어느정도 유지할 수 있을 것이다.
기존의 naive한 방법으로 fine-tuning을 해주면 성능의 한계를 보이게 된다. 그래서 모든 model을 update하는 fine-tuning을 사용할 때에는 새로운 task에 완전히 fitting을 하기 때문에 기존의 feature extractor 부분이 old task에 적용될 수 있는 feature하고 달라지게 된다. 기존의 old task classifier 부분과 호환성이 없어지게 되면서 forgetting effect가 발생하게 된다. 그래서 여기서 사용되는 classifier들은 고정이 되어 있고, 만약 feature extraction 부분이 바뀌었다고 한다면 새로운 task에 대해서 학습이 되면서 앞부분이 바뀌게 되면서 중간 결과도 바뀌게 될 것이다. 이렇게 되면 새로운 task에는 호환이 되지만 그 전에 고정되어 있던 task에는 호환성을 잃어버리게 된다. 간단한 해결 방법으로는 old task와 new task에 대해서 dataset을 모두 합쳐서 학습을 시키는 것이다. 이렇게 되면 naive하기는 하지만 기존 task에 대한 성능과 새로운 task에 대한 성능을 어느정도 유지할 수 있을 것이다.
Learning without Forgetting (Incremental learning)
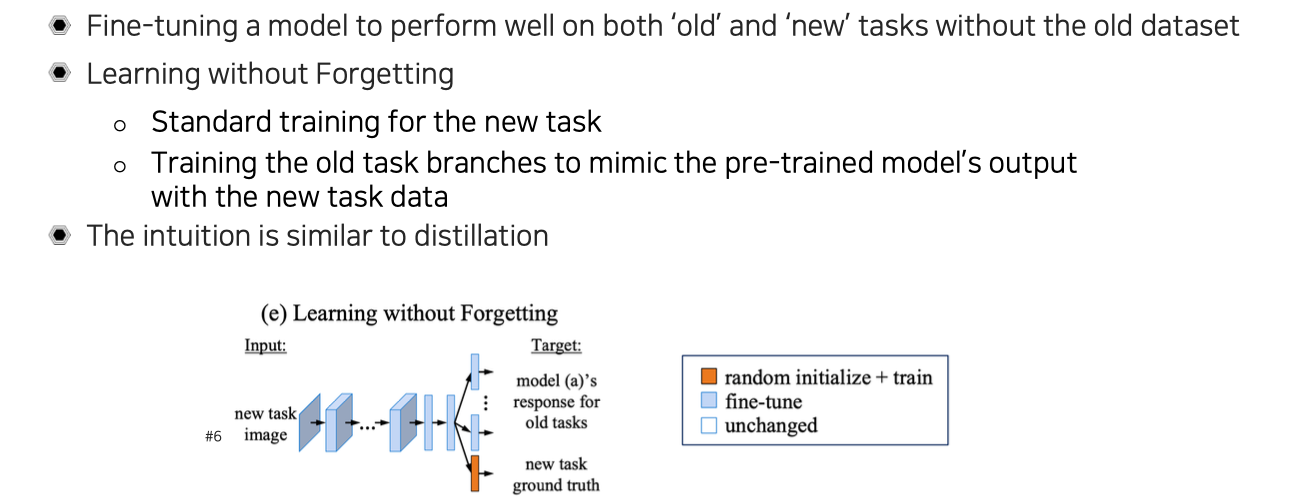 하지만 이렇게 동시에 양쪽 dataset을 활용하게 되면, 이전 dataset이 굉장히 많은 경우에는 old data에 대해서 유지하기가 부담스러울 것이다. 학습 시간도 기존의 task에 대해서 학습되는 시간에다가 새로운 task에 대해서 학습 시간까지 더해지기 때문에 굉장히 오래 걸릴 것이다. 시간도 문제이지만 data 사이의 imbalance 문제도 해결할 필요가 생긴다.
하지만 이렇게 동시에 양쪽 dataset을 활용하게 되면, 이전 dataset이 굉장히 많은 경우에는 old data에 대해서 유지하기가 부담스러울 것이다. 학습 시간도 기존의 task에 대해서 학습되는 시간에다가 새로운 task에 대해서 학습 시간까지 더해지기 때문에 굉장히 오래 걸릴 것이다. 시간도 문제이지만 data 사이의 imbalance 문제도 해결할 필요가 생긴다.
그래서 learning without forgetting같은 경우에는 이 문제를 기존의 old dataset 없이 해결하려는 방법이기 때문에 어떻게 보면 incremental learning으로 볼 수 있다. Old task를 유지하면서 새로운 task에 incremental하게 조금씩 점차적으로 더 학습하는 방식으로 볼 수 있다. 그래서 이 방식은 새로운 task에 대해서 standard하게 학습을 하면서 기존의 old task branch들은 기존의 pre-trained model의 output 자체가 새로운 task를 학습을 하면서도 기존의 output을 잊지 않도록 유지하면서 따라하도록 학습을 하는 것이다. 이러한 직관이 결국 distillation과 유사하게 된다. Teacher network가 따로 존재하는 것이 아니라 지금 model 자체가 스스로 teacher가 되어 old task에 대해서는 기존 지식을 잃지 않도록 계속 스스로 remind해주는 것이고, 새로운 task에 대해서는 ground truth dataset을 이용해서 새로운 task를 지속적으로 학습하는 것이다.
Loss functions in Learning without Forgetting
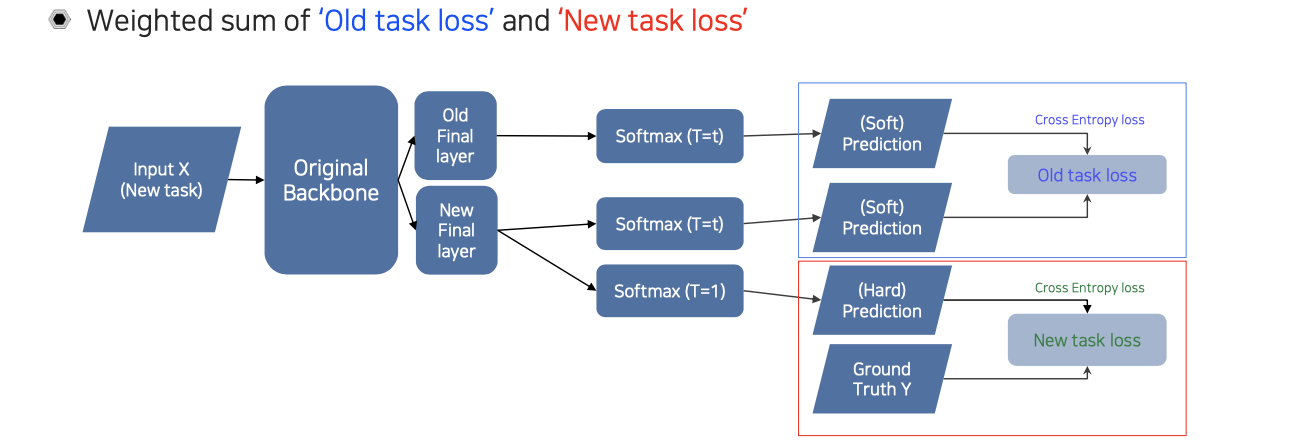 정리하면 ditillation loss와 student loss와 굉장히 비슷한 구조로 old task loss와 new task loss를 사용하게 된다. 차이는 여기에는 student와 teacher가 따로 존재하는 것이 아니라 backbone network가 있을 때 뒤에 old task layer와 new task layer가 분리가 되어 있고, 이 둘은 따로 독립인 상태이다. 이 상태에서 둘은 그저 feature만 공유하는 것이다.
정리하면 ditillation loss와 student loss와 굉장히 비슷한 구조로 old task loss와 new task loss를 사용하게 된다. 차이는 여기에는 student와 teacher가 따로 존재하는 것이 아니라 backbone network가 있을 때 뒤에 old task layer와 new task layer가 분리가 되어 있고, 이 둘은 따로 독립인 상태이다. 이 상태에서 둘은 그저 feature만 공유하는 것이다.
Leveraging unlabeld dataset for training
Semi-supervised learning
There are lots of unlabeled data
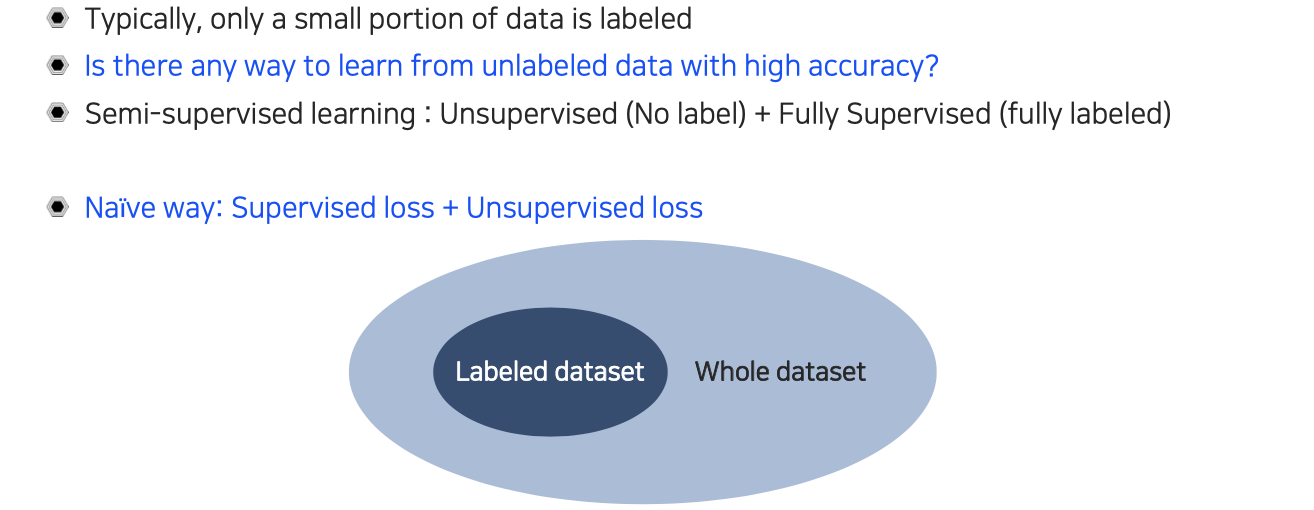 Unlabeled dataset을 이용해서 target task의 성능을 올리는 학습 방법을 semi-supervised learning이라고 한다. 우리가 unlabeled dataset을 구하는 것은 굉장히 저렴하면서도 쉽다. 보통 unlabeled dataset 규모에 비해서 labeled dataset의 규모는 굉장히 작은 편이다. Semi-supervised learning은 unlabeled data를 이용하는 방법과 labeled data를 동시에 사용하게 된다.
Unlabeled dataset을 이용해서 target task의 성능을 올리는 학습 방법을 semi-supervised learning이라고 한다. 우리가 unlabeled dataset을 구하는 것은 굉장히 저렴하면서도 쉽다. 보통 unlabeled dataset 규모에 비해서 labeled dataset의 규모는 굉장히 작은 편이다. Semi-supervised learning은 unlabeled data를 이용하는 방법과 labeled data를 동시에 사용하게 된다.
Semi-supervised learning with pseudo labeling
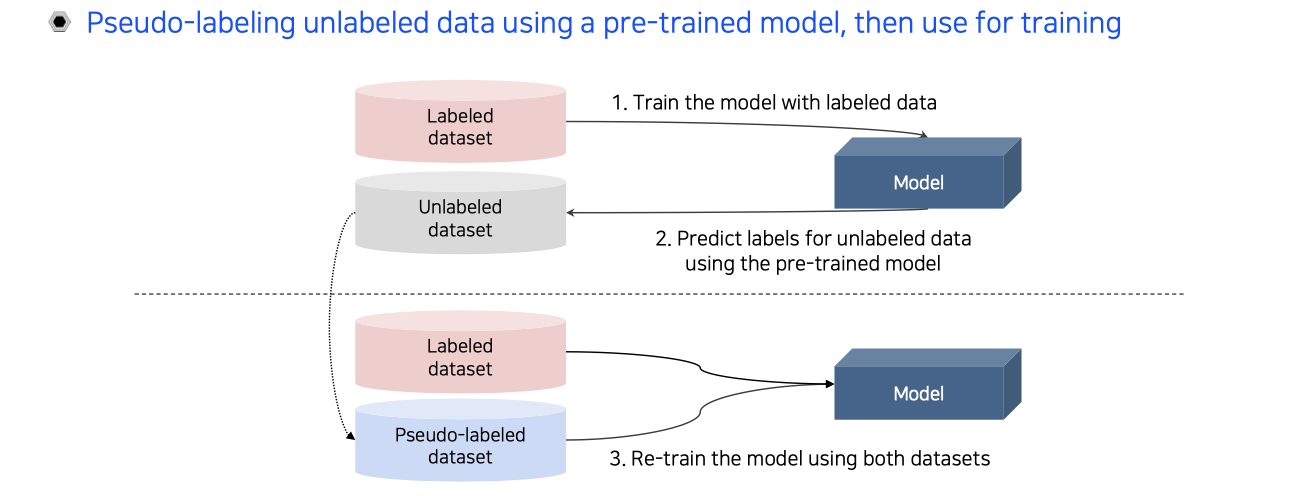 Semi-supervised learning을 하는 실용적인 방법 중 하나는 pseudo labeling을 하는 것이다. Pseudo labeling은 기존의 pre-trained model이 있을 때, 이것을 이용해서 학습을 하는 것이다. 먼저 labeled dataset을 이용해서 model을 학습시킨다. 그다음 이 model을 이용해서 unlabeled dataset에 적용해서 pseudo labeling을 진행한다. 이렇게 만들어진 pseudo-labeled dataset과 labeled dataset을 동시에 활용해서 다시 model을 학습하는 것이다. 이 방법이 가장 naive한 semi-supervised learning의 방법이다.
Semi-supervised learning을 하는 실용적인 방법 중 하나는 pseudo labeling을 하는 것이다. Pseudo labeling은 기존의 pre-trained model이 있을 때, 이것을 이용해서 학습을 하는 것이다. 먼저 labeled dataset을 이용해서 model을 학습시킨다. 그다음 이 model을 이용해서 unlabeled dataset에 적용해서 pseudo labeling을 진행한다. 이렇게 만들어진 pseudo-labeled dataset과 labeled dataset을 동시에 활용해서 다시 model을 학습하는 것이다. 이 방법이 가장 naive한 semi-supervised learning의 방법이다.
Recap: Data efficient learning methods so far
 하지만 이렇게 naive한 방법으로 성능을 올리는데는 한계가 존재한다. 우리는 지금까지 다양한 방법으로 성능을 올릴 수 있음을 확인했다. 이러한 방법들을 적절하게 조합해서 성능이 좋은 semi-supervised learning을 만들 수 없을지 고민해볼 수 있다.
하지만 이렇게 naive한 방법으로 성능을 올리는데는 한계가 존재한다. 우리는 지금까지 다양한 방법으로 성능을 올릴 수 있음을 확인했다. 이러한 방법들을 적절하게 조합해서 성능이 좋은 semi-supervised learning을 만들 수 없을지 고민해볼 수 있다.
Self-training
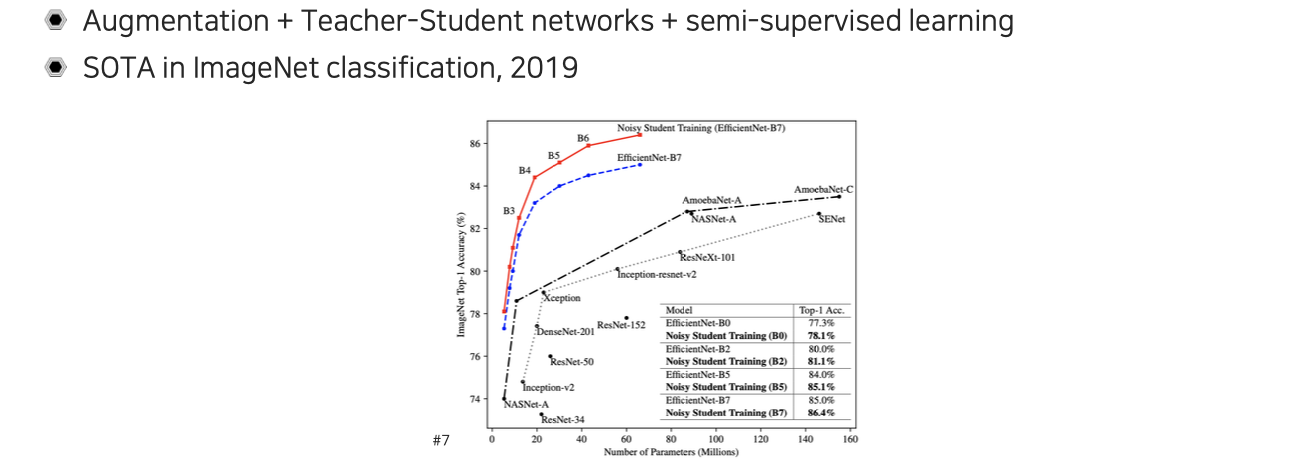 그 방법이 바로 cvpr 2020에 발표된 self-training 방법이다. Self-training은 data augmentation과 teacher-student network의 distillation, 그리고 semi-supervised learning의 장점들을 하나로 합친 형태로 볼 수 있다.
그 방법이 바로 cvpr 2020에 발표된 self-training 방법이다. Self-training은 data augmentation과 teacher-student network의 distillation, 그리고 semi-supervised learning의 장점들을 하나로 합친 형태로 볼 수 있다.
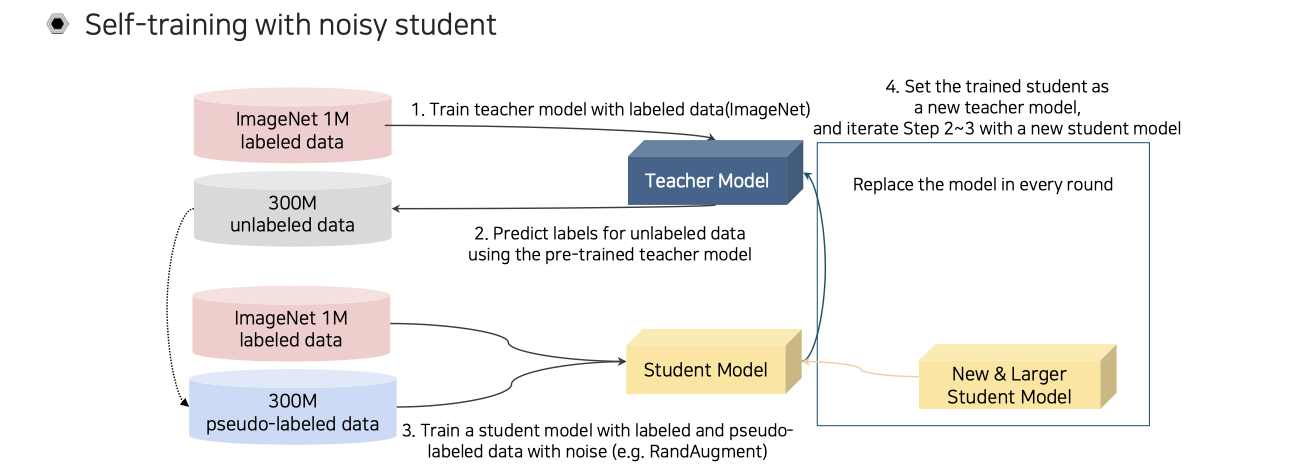 Self-training은 noisy student라는 개념을 이용해서 반복적으로 수행된다. 먼저 ImageNet labeled data가 1M개와 300M개의 unlabeled data가 방대하게 주어졌다고 해보자. 이때 먼저 teacher network에 대해서 labeled data로 pre-training 시켜보자. 그러면 학습된 teacher model을 이용해서 unlabeled data에 pseudo labeling을 시켜주게 된다. 이제 labeled data와 더불어 300M개의 pseudo-labeled data를 가지고 있게 된다. 이 2개의 data를 동시에 가지고 student model을 학습시키게 된다. 이때, RandAugmentation을 강하게 해서 pseudo-labeled data와 labeled data를 굉장히 noisy하게 만들어 student model을 최대한 잘 학습하도록 만들게 해준다. Augmentation을 통해서 student model을 더 강하게 만들어주는 것이다. 다음 과정은 이렇게 학습이 잘 된 student model을 teacher model로 올려주는 것이다. 새로운 teacher로 올린 다음에는 unlabeled data를 다시 re-labeling 해준다. 이렇게 계속해서 student model을 대체하면서 반복하는 것이다. 이때, 중요한 점은 student model의 크기가 점점 커져야 한다는 것이다.
Self-training은 noisy student라는 개념을 이용해서 반복적으로 수행된다. 먼저 ImageNet labeled data가 1M개와 300M개의 unlabeled data가 방대하게 주어졌다고 해보자. 이때 먼저 teacher network에 대해서 labeled data로 pre-training 시켜보자. 그러면 학습된 teacher model을 이용해서 unlabeled data에 pseudo labeling을 시켜주게 된다. 이제 labeled data와 더불어 300M개의 pseudo-labeled data를 가지고 있게 된다. 이 2개의 data를 동시에 가지고 student model을 학습시키게 된다. 이때, RandAugmentation을 강하게 해서 pseudo-labeled data와 labeled data를 굉장히 noisy하게 만들어 student model을 최대한 잘 학습하도록 만들게 해준다. Augmentation을 통해서 student model을 더 강하게 만들어주는 것이다. 다음 과정은 이렇게 학습이 잘 된 student model을 teacher model로 올려주는 것이다. 새로운 teacher로 올린 다음에는 unlabeled data를 다시 re-labeling 해준다. 이렇게 계속해서 student model을 대체하면서 반복하는 것이다. 이때, 중요한 점은 student model의 크기가 점점 커져야 한다는 것이다.
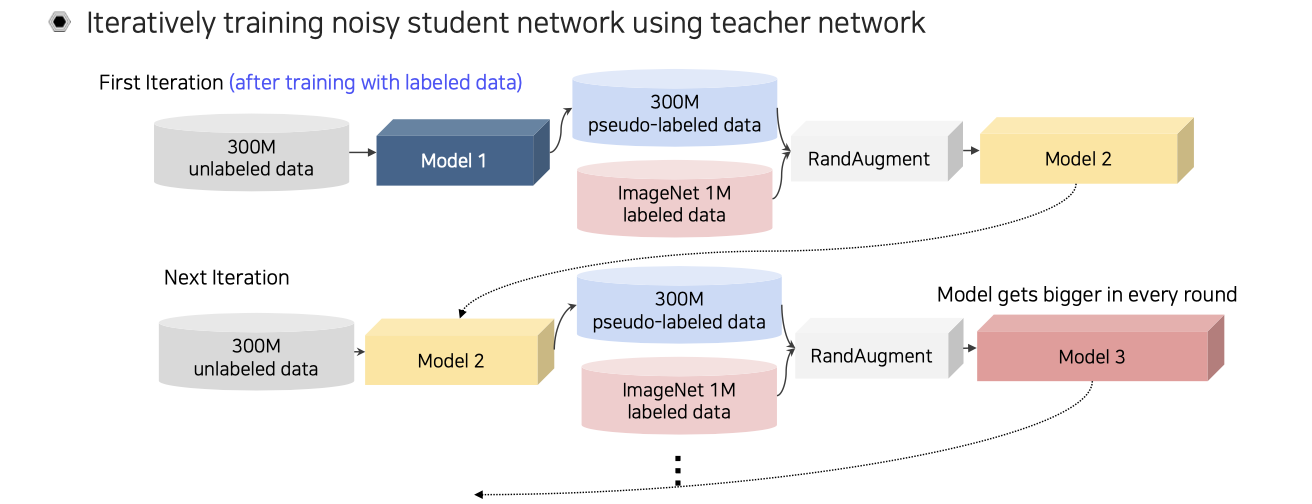 이 과정을 위와 같이 정리해볼 수 있다. Model의 크기는 커지면서 학습 시간도 오래 걸리지만 성능의 향상이 있었다.
이 과정을 위와 같이 정리해볼 수 있다. Model의 크기는 커지면서 학습 시간도 오래 걸리지만 성능의 향상이 있었다.
Brief overview of self-training

