
Instance segmentation
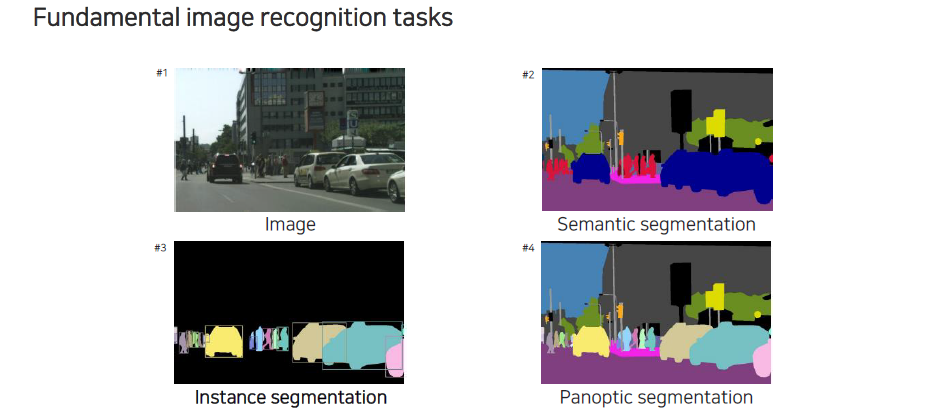 기존의 semantic segmentation은 여러 자동차가 있더라도 해당 픽셀들은 모두 자동차에 소속된 픽셀들이기 때문에 모두 자동차라고 인식이 되었다. 하지만 instance segmentation은 자동차 개별마다 자동차이면서 각각의 개체임을 구분할 수 있는 형태의 segmentation이다. Instance segmentation이 각각의 개체를 구분하기 때문에 background와 같이 구분하기 애매한 것들은 제외시키고 object를 대상으로 하는 task이다. 뒤쪽에서 살펴 볼 panoptic segmentation은 semantic segmentation과 instance segmentation을 합친 형태의 task이다.
기존의 semantic segmentation은 여러 자동차가 있더라도 해당 픽셀들은 모두 자동차에 소속된 픽셀들이기 때문에 모두 자동차라고 인식이 되었다. 하지만 instance segmentation은 자동차 개별마다 자동차이면서 각각의 개체임을 구분할 수 있는 형태의 segmentation이다. Instance segmentation이 각각의 개체를 구분하기 때문에 background와 같이 구분하기 애매한 것들은 제외시키고 object를 대상으로 하는 task이다. 뒤쪽에서 살펴 볼 panoptic segmentation은 semantic segmentation과 instance segmentation을 합친 형태의 task이다.
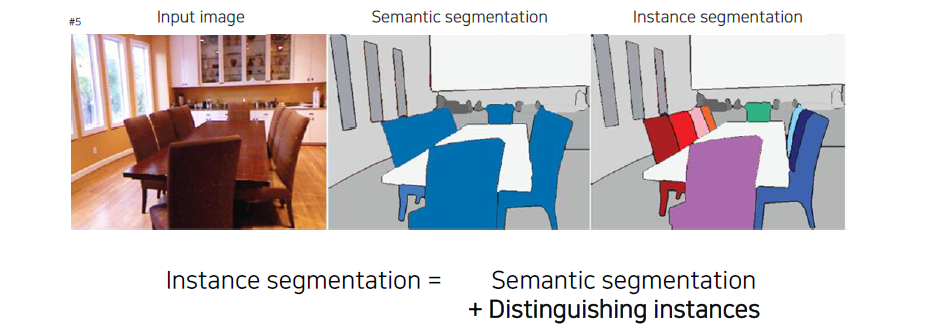 Instance segmentation을 좀 더 자세하게 살펴보면 semantic segmentation과 마찬가지로 각 픽셀의 의미적인 정보를 분석하는 방법이지만 차별점으로 각 instance를 구분한다는 것이다. 위의 예시에서 의자가 여러개 겹쳐져 있을 때 각각의 픽셀들이 의자라고 판단하는 semantic segmentation과는 달리 instance segmentation은 같은 의자라도 서로 다른 개체로 인식할 수 있다는 것이다.
Instance segmentation을 좀 더 자세하게 살펴보면 semantic segmentation과 마찬가지로 각 픽셀의 의미적인 정보를 분석하는 방법이지만 차별점으로 각 instance를 구분한다는 것이다. 위의 예시에서 의자가 여러개 겹쳐져 있을 때 각각의 픽셀들이 의자라고 판단하는 semantic segmentation과는 달리 instance segmentation은 같은 의자라도 서로 다른 개체로 인식할 수 있다는 것이다.
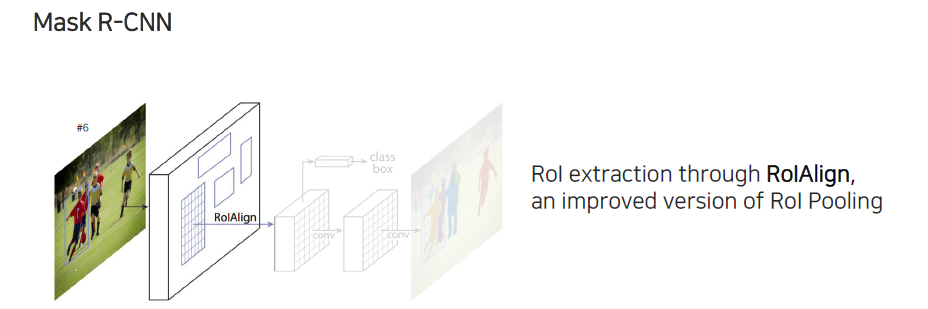 지금부터는 어떻게 instance segmentation을 구현하는지 알아볼 것이다. Object detection task에는 굉장히 유명한 faster R-CNN 모델이 있다. 이 모델의 확장 버전이 바로 mask R-CNN이다.
지금부터는 어떻게 instance segmentation을 구현하는지 알아볼 것이다. Object detection task에는 굉장히 유명한 faster R-CNN 모델이 있다. 이 모델의 확장 버전이 바로 mask R-CNN이다.
Mask R-CNN은 faster R-CNN과는 조금 다르게 RoIAlign을 통해서 RoI pooling을 수행한다. RoI pooling과 비슷한 역할을 하는데, 먼저 region을 추출해서 각 bounding box 위치에 feature들을 뽑아오는 역할을 한다. RoI pooling과 다른 점은 이보다 개선된 버전으로 bounding box의 좌표 정보를 regression하게 되는데, 이때 prediction된 bounding box의 좌표 정보가 정수로 정확하게 떨어지지 않고 실수로도 떨어지게 될 것이다. 이러한 실수 정보를 반영하기 위해서 RoIAlign은 feature의 중간값을 interpolation을 해서 사용한다. 위에서 RoIAlign을 통해서 feature를 뽑아올 때 bounding box 정보가 정수로 명확하게 떨어지지 않더라도 주변 값들을 이용해서 중심으로부터 얼마나 벗어나는지 비율을 이용해서 interpolation을 수행하고 feature들을 resampling해주게 된다. 이렇게 bi-linear resampling을 통해서 convolution feature를 구성하게 된다.
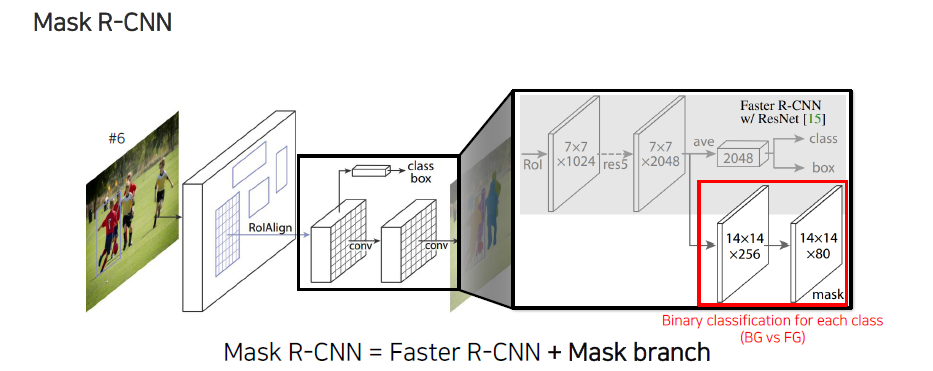 Feature가 추출된 후에는 각 class 정보와 bounding box regression 정보를 추출하는 detection branch가 있다. 이 부분을 자세하게 살펴보면 classification과 bounding box를 regression하는 branch가 존재하는데, 이들은 faster R-CNN과 동일하다고 보면 된다. Mask R-CNN과 faster R-CNN을 구분짓는 다른점은 mask R-CNN에는 mask head가 존재한다는 것이다. Feature map이 추출되면 이를 다시 convolution layer를 이용해서 크기를 변환해가면서 최종적으로 mask prediction을 output으로 만들어낸다. 마지막에 80이라는 숫자는 각 class의 개수를 의미하고, 이는 MS COCO라고 하는 instance segmentation dataset에 존재하는 class의 수이다. 결과적으로 80개 각각에 대한 segmentation map을 매번 prediction하는 것이라고 볼 수 있다. 정리하면 mask R-CNN은 결국 faster R-CNN에 mask branch가 추가된 형태로 볼 수 있다.
Feature가 추출된 후에는 각 class 정보와 bounding box regression 정보를 추출하는 detection branch가 있다. 이 부분을 자세하게 살펴보면 classification과 bounding box를 regression하는 branch가 존재하는데, 이들은 faster R-CNN과 동일하다고 보면 된다. Mask R-CNN과 faster R-CNN을 구분짓는 다른점은 mask R-CNN에는 mask head가 존재한다는 것이다. Feature map이 추출되면 이를 다시 convolution layer를 이용해서 크기를 변환해가면서 최종적으로 mask prediction을 output으로 만들어낸다. 마지막에 80이라는 숫자는 각 class의 개수를 의미하고, 이는 MS COCO라고 하는 instance segmentation dataset에 존재하는 class의 수이다. 결과적으로 80개 각각에 대한 segmentation map을 매번 prediction하는 것이라고 볼 수 있다. 정리하면 mask R-CNN은 결국 faster R-CNN에 mask branch가 추가된 형태로 볼 수 있다.
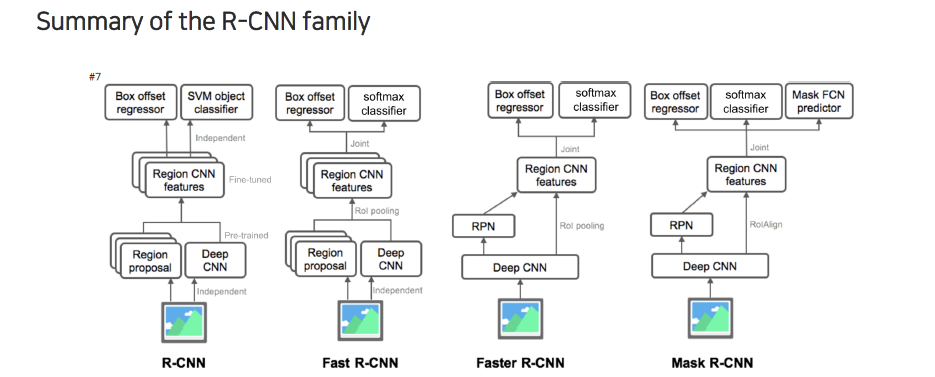 종합적으로 R-CNN은 위와 같이 계속 발전했다. R-CNN은 deep neural network에서 feature를 뽑아서 각 feature를 region에 맞게 독립적으로 매번 feeding을 했었다. Image를 region proposal에 맞게 매번 잘라서 deep neural network에 넣어서 feature를 뽑고 SVM classification을 진행했다. Fast R-CNN의 경우에는 RoI pooling을 도입하면서 end-to-end로 이어질 수 있도록 만들어서 학습을 할 때 region proposal을 제외한 나머지 부분들은 전부 한번에 학습이 되도록 유도했다. 다음으로 faster R-CNN에서는 region proposal마저도 미분 가능하게 만들어서 neural network로 구성했다. Region proposal마저도 region proposal network(RPN)을 이용해서 deep neural network가 feature를 뽑고 RoI pooling을 할 때 RoI pooling에 대한 정보가 RPN에서 나와서 한번에 classification과 bounding box regression을 할 수 있도록 만들었다. 이러한 구조가 굉장히 general하기 때문에 이 구조가 많이 참조되어 사용되었다. Mask R-CNN은 이와 동일한데 mask head가 추가된 것 뿐이다.
종합적으로 R-CNN은 위와 같이 계속 발전했다. R-CNN은 deep neural network에서 feature를 뽑아서 각 feature를 region에 맞게 독립적으로 매번 feeding을 했었다. Image를 region proposal에 맞게 매번 잘라서 deep neural network에 넣어서 feature를 뽑고 SVM classification을 진행했다. Fast R-CNN의 경우에는 RoI pooling을 도입하면서 end-to-end로 이어질 수 있도록 만들어서 학습을 할 때 region proposal을 제외한 나머지 부분들은 전부 한번에 학습이 되도록 유도했다. 다음으로 faster R-CNN에서는 region proposal마저도 미분 가능하게 만들어서 neural network로 구성했다. Region proposal마저도 region proposal network(RPN)을 이용해서 deep neural network가 feature를 뽑고 RoI pooling을 할 때 RoI pooling에 대한 정보가 RPN에서 나와서 한번에 classification과 bounding box regression을 할 수 있도록 만들었다. 이러한 구조가 굉장히 general하기 때문에 이 구조가 많이 참조되어 사용되었다. Mask R-CNN은 이와 동일한데 mask head가 추가된 것 뿐이다.
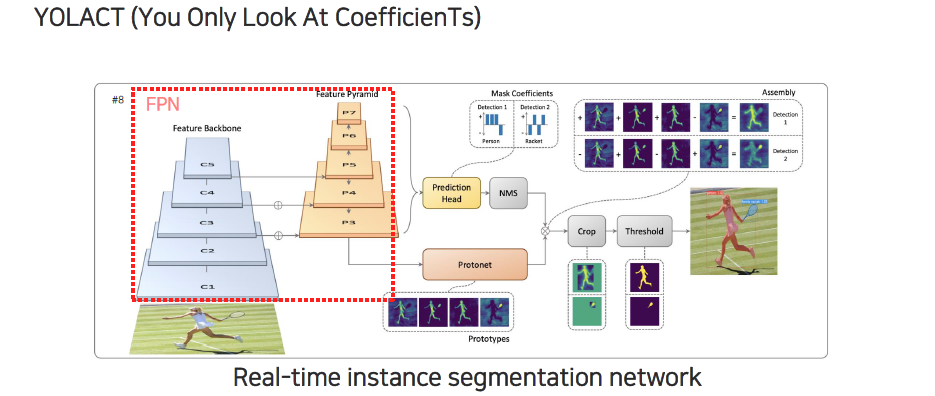 Mask R-CNN은 RPN을 별도로 사용하는 2-stage 구조였는데, feature pyramid network(FPN)을 사용하는 RetinaNet 기반의 instance segmentation도 존재한다. YOLACT는 1-stage 기반의 network로, RPN을 사용하지 않고 FPN에서 나온 각 feature에서 mask, classification, bounding box의 값을 한번에 prediction 하는 것이다.
Mask R-CNN은 RPN을 별도로 사용하는 2-stage 구조였는데, feature pyramid network(FPN)을 사용하는 RetinaNet 기반의 instance segmentation도 존재한다. YOLACT는 1-stage 기반의 network로, RPN을 사용하지 않고 FPN에서 나온 각 feature에서 mask, classification, bounding box의 값을 한번에 prediction 하는 것이다.
YOLACT라는 논문에서는 feature pyramid를 먼저 쌓아서 backbone network에서 feature를 추출한 뒤에 feature pyramid를 통해서 높은 layer에서부터 밑으로 내려가면서 feature를 fusion해주면서 high level 정보를 잘 저장하는 것과 low level의 정보를 함쳐서 종합적인 판단을 내려주게 된다. 이러한 식으로 FPN을 구성해주고 각 layer에서 모든 크기의 object를 고려해주기 위해서 전부 prediction을 해주게 된다. Prediction head는 detection score와 마찬가지인 mask coefficient라는 것을 출력하게 만든다. Protonet은 mask의 prototype 전부를 prediction하게 된다. Mask coefficient로부터 non maximum supression(NMS)를 이용해서 실제로 object라고 고려하기 어려운 여러 bounding box를 하나로 합쳐주게 된다. NMS 결과와 protonet 결과가 합쳐져서 최종적으로 각 instance에 대한 segmentation map이 나오게 된다. 그리고 이들을 적당히 crop해서 threshold를 함으로써 instance segmentation이 수행된다.
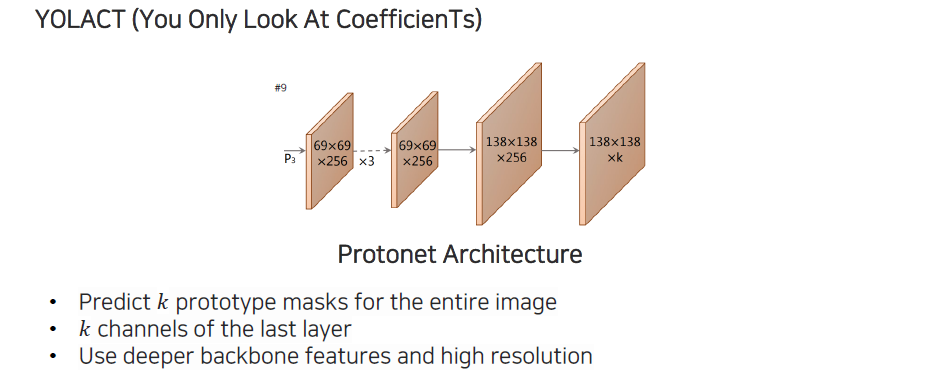 Prototype 부분을 좀 더 자세하게 살펴보고자 한다. Protonet은 먼저 하나의 feature pyramid로부터 여러번 convolution을 통과해서 위와 같은 구조로 feature를 뽑아서 사용하게 된다. 여기서 채널축을 보면 로 되어 있는데, 이는 class의 개수와 상관이 전혀 없으며 사용자가 정해주는 값이다. 개의 prototype mask를 전체 image에 대해서 한번 prediction을 해주게 된다. 여기서 prototype은 선형대수에서 배웠던 basis와 비슷한 역할을 하게된다. 그래서 어떠한 image가 주어졌을 때 우리가 최종적으로 instance segmentation을 하려는 mask를 span할 수 있는 prototype들을 개 만드는 것이다. 마지막에는 채널을 가지고 각각에 해당하는 basis를 prediction한 다음에 적절히 linear combination 해서 instance를 표현하도록 만드는 것이다.
Prototype 부분을 좀 더 자세하게 살펴보고자 한다. Protonet은 먼저 하나의 feature pyramid로부터 여러번 convolution을 통과해서 위와 같은 구조로 feature를 뽑아서 사용하게 된다. 여기서 채널축을 보면 로 되어 있는데, 이는 class의 개수와 상관이 전혀 없으며 사용자가 정해주는 값이다. 개의 prototype mask를 전체 image에 대해서 한번 prediction을 해주게 된다. 여기서 prototype은 선형대수에서 배웠던 basis와 비슷한 역할을 하게된다. 그래서 어떠한 image가 주어졌을 때 우리가 최종적으로 instance segmentation을 하려는 mask를 span할 수 있는 prototype들을 개 만드는 것이다. 마지막에는 채널을 가지고 각각에 해당하는 basis를 prediction한 다음에 적절히 linear combination 해서 instance를 표현하도록 만드는 것이다.
위에서 라고 나와있는 것은 backbone network에서 가장 깊은 feature에 해당하면서 고해상도이다. 이러한 이유는 mask는 경계가 뚜렷해야 하기 때문에 고해상도를 선호하는 것이다. 하지만 고해상도라고 하더라도 feature map 내에서 고해상도이기 때문에 결국에는 엄청 큰 해상도를 가지는 것은 아니다. Feature level에서는 큰 해상도로 볼 수 있지만, 전체적인 image level에서 보기에는 큰 해상도는 아닌 것이다. 그렇기 때문에 어떻게 보면 더 빠른 속도를 만들어내는 형태가 되는 것이다. 도 class의 개수와 상관없이 설정할 수 있기 때문에 class의 개수와 독립적으로 연산 속도를 동일하게 유지할 수 있다.
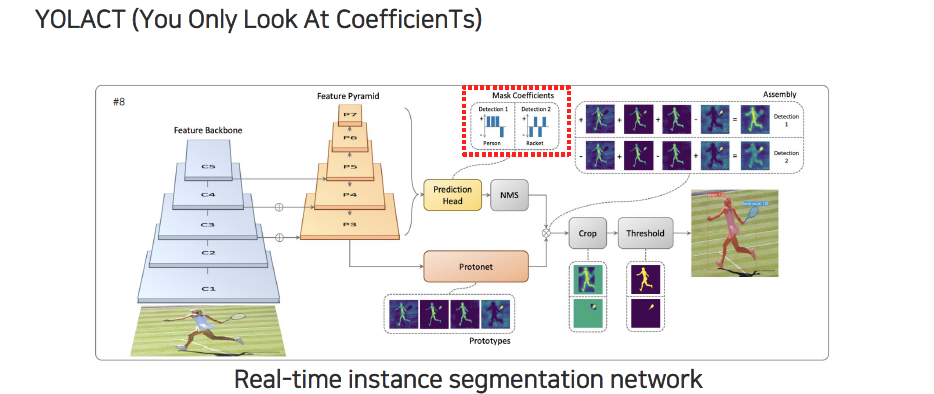 다음으로는 mask coefficient 부분이다. Mask coefficient 부분은 prototype들이 basis들을 prediction한 것인데, basis들의 각 coefficient는 어떠한 정도의 contribution을 가지고 detection하려는 부분을 만들어내는지를 prediction하게 된다. 이 coefficient들을 이용해서 prototype들을 linear combination 함으로써 각 instance의 mask를 표현하게 된다.
다음으로는 mask coefficient 부분이다. Mask coefficient 부분은 prototype들이 basis들을 prediction한 것인데, basis들의 각 coefficient는 어떠한 정도의 contribution을 가지고 detection하려는 부분을 만들어내는지를 prediction하게 된다. 이 coefficient들을 이용해서 prototype들을 linear combination 함으로써 각 instance의 mask를 표현하게 된다.
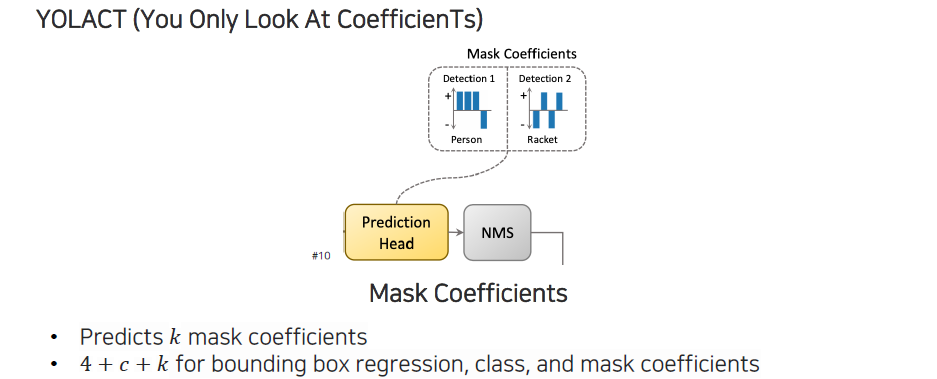 Prediction head에서는 매번 개의 mask coefficient들을 prediction하게 된다. 하나의 instance에 대해서 개의 coefficient가 출력이 되고, 이렇게 출력이 되면 prototype map이 coefficient들과 linear combination을 통해서 최종적으로 하나의 mask로 만들어지게 된다. 그래서 각 instance마다 bounding box regression, class, mask coefficient가 개가 나오게 되는 것이다.
Prediction head에서는 매번 개의 mask coefficient들을 prediction하게 된다. 하나의 instance에 대해서 개의 coefficient가 출력이 되고, 이렇게 출력이 되면 prototype map이 coefficient들과 linear combination을 통해서 최종적으로 하나의 mask로 만들어지게 된다. 그래서 각 instance마다 bounding box regression, class, mask coefficient가 개가 나오게 되는 것이다.
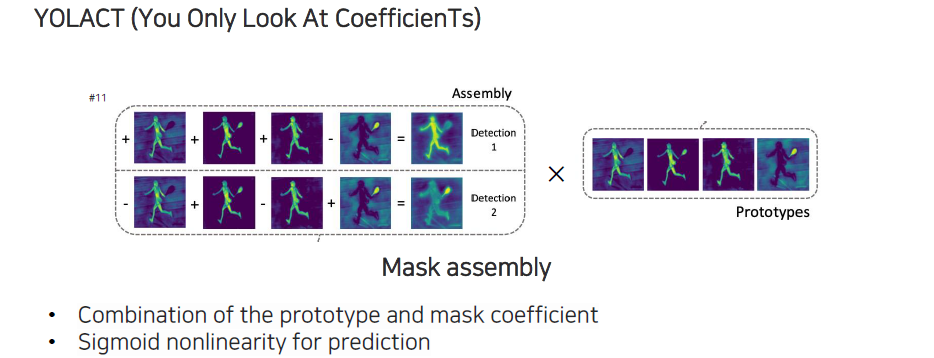 이렇게 linear combination을 통해서 mask assembly를 해주고, 결국에는 prototype하고 coefficient와 linear combination을 하는걸로 볼 수 있다. Prototype이 조합되고 나서는 sigmoid를 사용해서 0~1 사이로 만들어준다.
이렇게 linear combination을 통해서 mask assembly를 해주고, 결국에는 prototype하고 coefficient와 linear combination을 하는걸로 볼 수 있다. Prototype이 조합되고 나서는 sigmoid를 사용해서 0~1 사이로 만들어준다.
 이러한 1-stage 구조를 보이다보니 단위 시간동안 많은 결과를 처리할 수 있게 된다.
이러한 1-stage 구조를 보이다보니 단위 시간동안 많은 결과를 처리할 수 있게 된다.
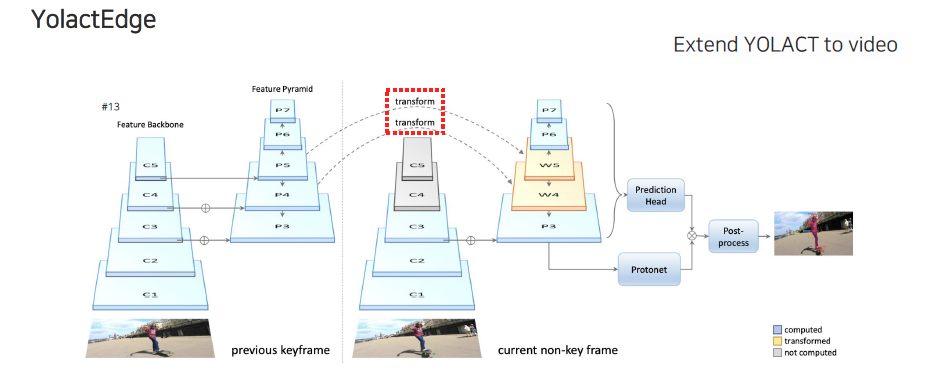 다음으로 YolactEdge의 경우에는 YOLACT를 video로 확장시킨 연구이다. 여기서는 기존의 keyframe과 현재의 frame 사이에서 feature를 transform해서 가져오는 역할을 한다. 기존의 YOLACT와 같이 기존의 feature를 다시 사용하는 것이 아니라 이전 frame의 feature를 사용한다는 차이점이 존재한다.
다음으로 YolactEdge의 경우에는 YOLACT를 video로 확장시킨 연구이다. 여기서는 기존의 keyframe과 현재의 frame 사이에서 feature를 transform해서 가져오는 역할을 한다. 기존의 YOLACT와 같이 기존의 feature를 다시 사용하는 것이 아니라 이전 frame의 feature를 사용한다는 차이점이 존재한다.
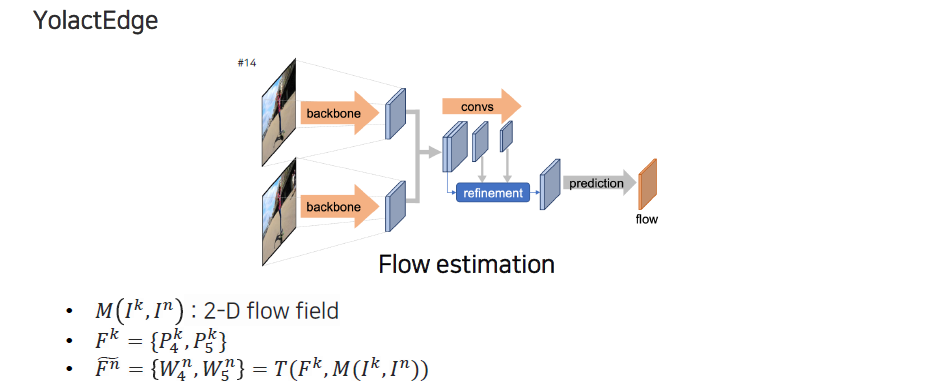 Feature를 transform하는 방법은 flow estimation을 통해서 진행된다. 어떠한 픽셀이 다음 frame에서 어디에 해당하는지 correspondence 관계를 굉장히 dense한 map 형태의 motion vector로 픽셀 단위로 나타나게 되고, 이를 optical flow map 또는 2-D flow field라고 부른다. 이러한 식으로 픽셀들이 어디 위치로 이동했는지에 대한 정보를 이용해서 해당 위치에 feature를 놓고 feature warping을 시킬 수 있다.
Feature를 transform하는 방법은 flow estimation을 통해서 진행된다. 어떠한 픽셀이 다음 frame에서 어디에 해당하는지 correspondence 관계를 굉장히 dense한 map 형태의 motion vector로 픽셀 단위로 나타나게 되고, 이를 optical flow map 또는 2-D flow field라고 부른다. 이러한 식으로 픽셀들이 어디 위치로 이동했는지에 대한 정보를 이용해서 해당 위치에 feature를 놓고 feature warping을 시킬 수 있다.
Panoptic segmentation
 Panoptic segmentation은 semantic segmentation과 instance segmentation을 합친 형태로 볼 수 있다.
Panoptic segmentation은 semantic segmentation과 instance segmentation을 합친 형태로 볼 수 있다.
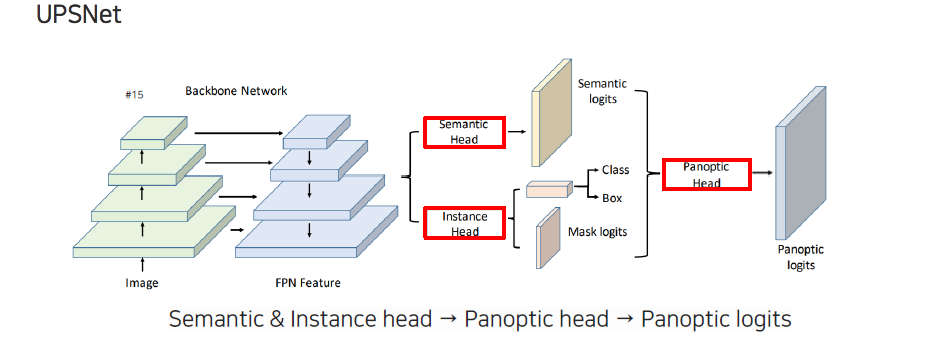 전체적으로 나누기 때문에 background와 foreground도 나누면서 각각을 또 나눠야하는 어려움이 존재한다. 하지만 어려움이 큰 만큼 활용도 측면에서는 더 크다. Panoptic segmentation의 대표적인 모델로 UPSNet이 있다. FPN 구조는 어디서든 유용하기 때문에 여기서도 이를 이용해서 feature를 추출하여 iamge를 multi-scale로 표현한다. Semantic segmentation과 instance segmentation이 합쳐진 형태이기 때문에 각각의 head가 모두 존재한 형태이다. Semantic segmentation head에서는 영상을 전체적으로 각 픽셀의 semantic 의미들을 prediction하도록 만들고, instance segmentation head에서는 object detection을 하듯이 classification과 box regression 그리고 mask regression을 같이 수행한다. 이렇게 나온 결과들을 전부 fusion하여 panoptic head를 통해서 최종적으로 panoptic prediction을 만들게 된다.
전체적으로 나누기 때문에 background와 foreground도 나누면서 각각을 또 나눠야하는 어려움이 존재한다. 하지만 어려움이 큰 만큼 활용도 측면에서는 더 크다. Panoptic segmentation의 대표적인 모델로 UPSNet이 있다. FPN 구조는 어디서든 유용하기 때문에 여기서도 이를 이용해서 feature를 추출하여 iamge를 multi-scale로 표현한다. Semantic segmentation과 instance segmentation이 합쳐진 형태이기 때문에 각각의 head가 모두 존재한 형태이다. Semantic segmentation head에서는 영상을 전체적으로 각 픽셀의 semantic 의미들을 prediction하도록 만들고, instance segmentation head에서는 object detection을 하듯이 classification과 box regression 그리고 mask regression을 같이 수행한다. 이렇게 나온 결과들을 전부 fusion하여 panoptic head를 통해서 최종적으로 panoptic prediction을 만들게 된다.
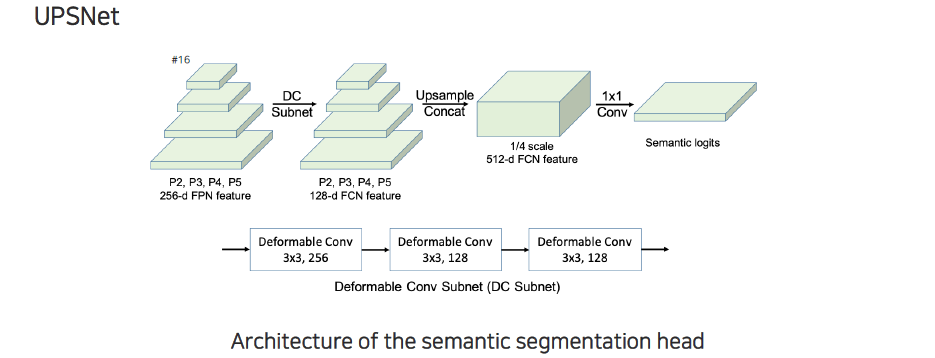 Backbone network 구조에 대해서 조금 더 알아보면 기존의 FPN과 조금 다른 부분은 feature transformation에서 deformable convolution을 사용한다는 것이다. 일반적인 convolution이 정형적인 모양의 filter만 고려할 수 있다면, deformable convolution의 경우에는 현재 존재하는 위치에서부터 filter가 어떻게 변형되고 움직여야 비슷한 object를 잘 표현할 수 있는지를 prediction하여 그 결과를 filter에 적용시키게 된다.
Backbone network 구조에 대해서 조금 더 알아보면 기존의 FPN과 조금 다른 부분은 feature transformation에서 deformable convolution을 사용한다는 것이다. 일반적인 convolution이 정형적인 모양의 filter만 고려할 수 있다면, deformable convolution의 경우에는 현재 존재하는 위치에서부터 filter가 어떻게 변형되고 움직여야 비슷한 object를 잘 표현할 수 있는지를 prediction하여 그 결과를 filter에 적용시키게 된다.
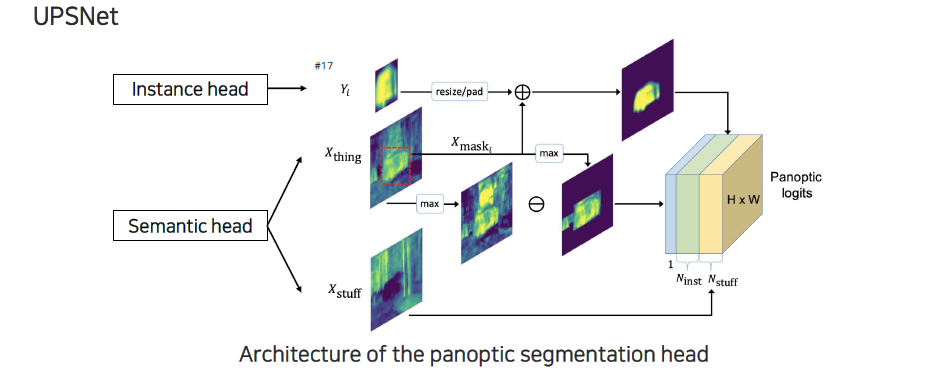 Panoptic segmentation head 부분에서는 instance head와 semantic head의 결과들을 하나로 합쳐주게 된다. 먼저 instance마다 각 bounding box 내에서 해당 instance마다 mask 형태가 나오게 된다. Semantic segmentation에서 object가 개별로 구분이 되어있지 않지만, instance segmentation 쪽에서 mask와 bounding box를 regression할 수 있기 때문에 thing 중에서 일부 구간을 masking 해서 가져오게 된다. 각 thing의 class들 중에서 confidence가 높은 것들만 모아서 map을 구성하게 되고, foreground에 대해서 max 값을 취해서 빼줌으로써 background 정보를 활용하게 된다. Foreground는 masking을 한 semantic segmentation의 정보와 instance segmentation의 mask 정보를 중간에 fusion해서 refine된 형태의 instance logit을 만들어서 instance 채널에 하나씩 slice 형태로 채워주게 된다. Stuff는 background 중에서도 알고 있는 stuff class의 logit들을 바로 넣어주게 된다. 전부 concatenation 시켜서 panoptic logit을 만들 수 있다.
Panoptic segmentation head 부분에서는 instance head와 semantic head의 결과들을 하나로 합쳐주게 된다. 먼저 instance마다 각 bounding box 내에서 해당 instance마다 mask 형태가 나오게 된다. Semantic segmentation에서 object가 개별로 구분이 되어있지 않지만, instance segmentation 쪽에서 mask와 bounding box를 regression할 수 있기 때문에 thing 중에서 일부 구간을 masking 해서 가져오게 된다. 각 thing의 class들 중에서 confidence가 높은 것들만 모아서 map을 구성하게 되고, foreground에 대해서 max 값을 취해서 빼줌으로써 background 정보를 활용하게 된다. Foreground는 masking을 한 semantic segmentation의 정보와 instance segmentation의 mask 정보를 중간에 fusion해서 refine된 형태의 instance logit을 만들어서 instance 채널에 하나씩 slice 형태로 채워주게 된다. Stuff는 background 중에서도 알고 있는 stuff class의 logit들을 바로 넣어주게 된다. 전부 concatenation 시켜서 panoptic logit을 만들 수 있다.
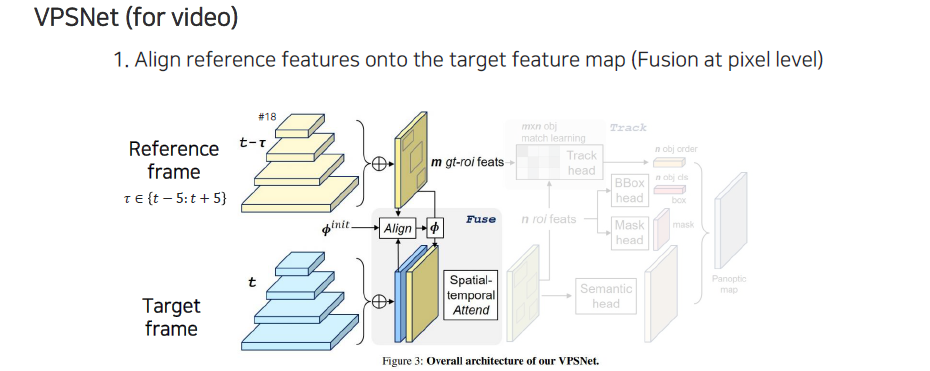 UPS의 경우 image마다 panoptic segmentation을 수행했는데 이를 video로 확장시킨 연구가 VPSNet이다. VPSNet은 reference frame과 target frame을 골라서 target frame을 segmentation하고 싶을 때 reference frame을 이용해서 feature를 뽑아서 bounding box를 먼저 regression을 해준다. 그 다음으로 2개의 frame 사이의 feature를 align해줘야 한다. 이는 feature를 transform해주는 것으로 feature를 합쳐서 fusion된 feature를 만들어준다.
UPS의 경우 image마다 panoptic segmentation을 수행했는데 이를 video로 확장시킨 연구가 VPSNet이다. VPSNet은 reference frame과 target frame을 골라서 target frame을 segmentation하고 싶을 때 reference frame을 이용해서 feature를 뽑아서 bounding box를 먼저 regression을 해준다. 그 다음으로 2개의 frame 사이의 feature를 align해줘야 한다. 이는 feature를 transform해주는 것으로 feature를 합쳐서 fusion된 feature를 만들어준다.
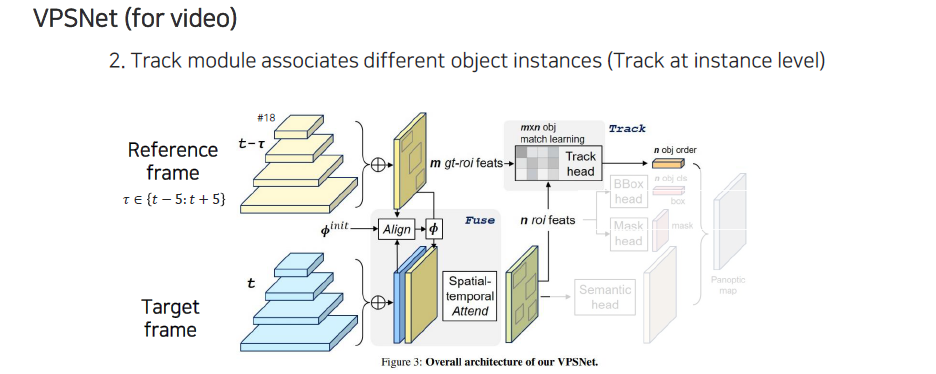 이 feature로부터 RoI를 prediction해준다. 각 RoI bounding box의 feature를 다 뽑으면 각 bounding box마다 feature가 출력이 되고, reference frame에서도 이미 bounding box들을 다 뽑아놓고 여기에 대한 feature들을 다 뽑은 상태에서 개의 reference frame에 있던 object와 개의 target frame에 있던 object를 이용해서 형태의 matrix를 만들 수 있게 된다. 이 matrix가 의미는 각 feature간 유사도 정보이다. 이렇게 similarity matrix를 만들어 놓으면 reference frame의 box와 target frame의 box를 matching 시킬 수 있게 된다. 결과적으로 이렇게 matching된 결과의 순서를 찾아낼 수 있다.
이 feature로부터 RoI를 prediction해준다. 각 RoI bounding box의 feature를 다 뽑으면 각 bounding box마다 feature가 출력이 되고, reference frame에서도 이미 bounding box들을 다 뽑아놓고 여기에 대한 feature들을 다 뽑은 상태에서 개의 reference frame에 있던 object와 개의 target frame에 있던 object를 이용해서 형태의 matrix를 만들 수 있게 된다. 이 matrix가 의미는 각 feature간 유사도 정보이다. 이렇게 similarity matrix를 만들어 놓으면 reference frame의 box와 target frame의 box를 matching 시킬 수 있게 된다. 결과적으로 이렇게 matching된 결과의 순서를 찾아낼 수 있다.
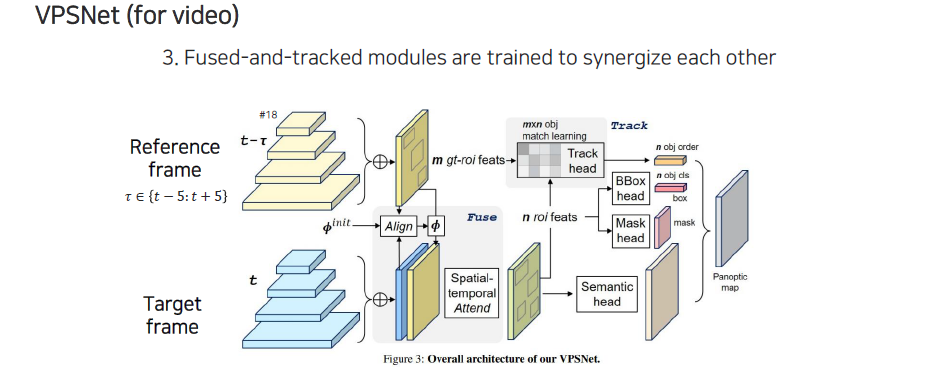 RoI feature에서 bounding box head와 mask head가 각각 나와서 classification, bounding box regression, mask prediction을 수행하게 된다. 그리고 아래쪽에 fusion된 network에서 sematic head로부터 prediction 함으로써 최종적으로 panoptic segmentation map을 형성할 수 있다.
RoI feature에서 bounding box head와 mask head가 각각 나와서 classification, bounding box regression, mask prediction을 수행하게 된다. 그리고 아래쪽에 fusion된 network에서 sematic head로부터 prediction 함으로써 최종적으로 panoptic segmentation map을 형성할 수 있다.
