
U-Net
U-Net은 FCN 이후에 나온 semantic segmentation의 대표적인 모델이다. U-Net은 fully convolutional network로 FCN과 동일한 성질을 공유한다. FCN과 많은 공통점을 가지면서도 큰 차이점이 존재하는데, 이러한 차이점이 성능에 큰 변화를 보여준다.
먼저 dense한 semantic segmentation map을 prediction하기 위해서 feature map을 concatenation한다는 점도 FCN에서의 skip connection과 굉장히 유사하다. 이러한 부분에서 U-Net은 정보 활용을 더 잘해서 좋은 성능을 이끌어냈다.
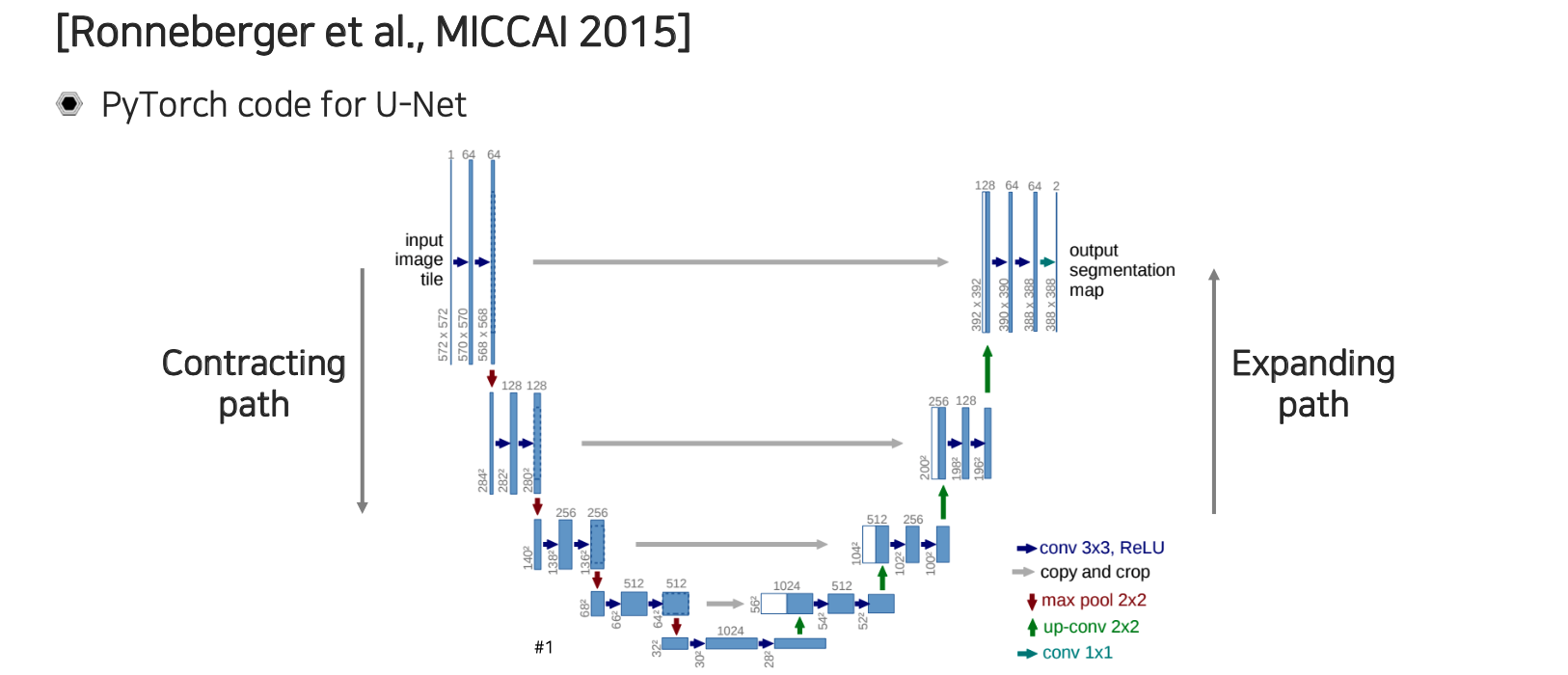
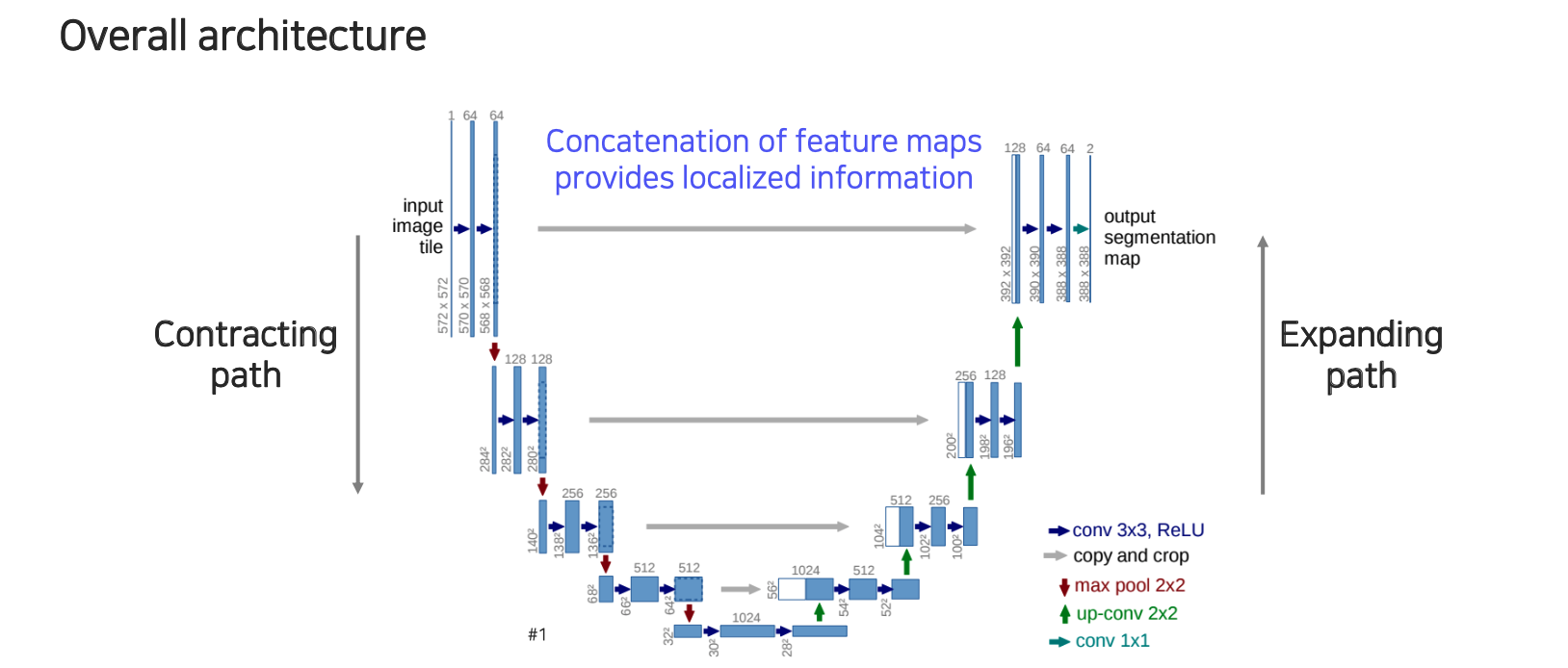 U-Net의 구조는 위와 같으며 이름 그대로 U자 모양을 하고 있어서 U-Net이라 부른다. U-Net은 contracting path와 expanding path로 나눌 수 있다. U-Net은 단순한 operation 여러개를 조합해서 만들어졌다.
U-Net의 구조는 위와 같으며 이름 그대로 U자 모양을 하고 있어서 U-Net이라 부른다. U-Net은 contracting path와 expanding path로 나눌 수 있다. U-Net은 단순한 operation 여러개를 조합해서 만들어졌다.
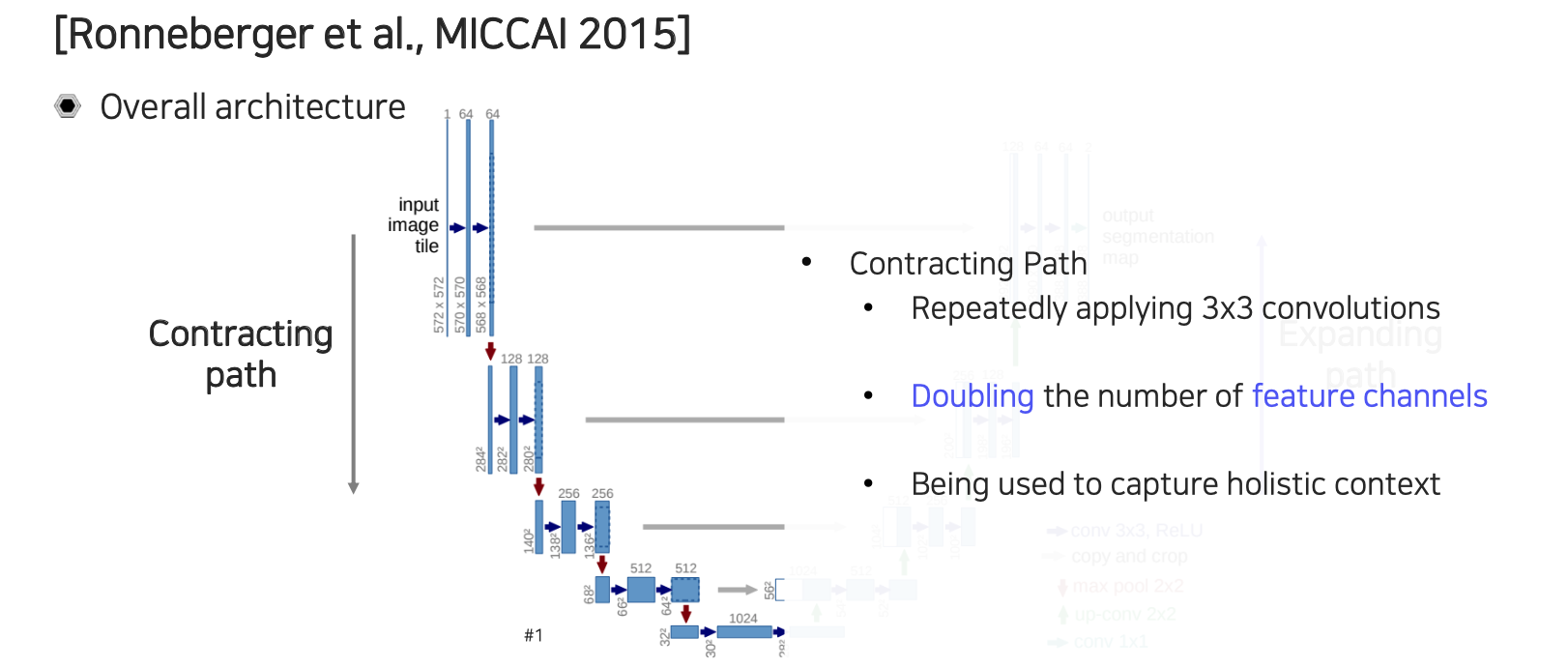 우선 contracting path에서는 convolution이 연속적으로 적용이 된다. 이때, feature의 채널을 2배씩 늘려주게 된다. 위에서 보면 처음에는 64 채널이 resolution이 줄어들 때마다 128, 256과 같이 2배씩 증가하고 있다.
우선 contracting path에서는 convolution이 연속적으로 적용이 된다. 이때, feature의 채널을 2배씩 늘려주게 된다. 위에서 보면 처음에는 64 채널이 resolution이 줄어들 때마다 128, 256과 같이 2배씩 증가하고 있다.
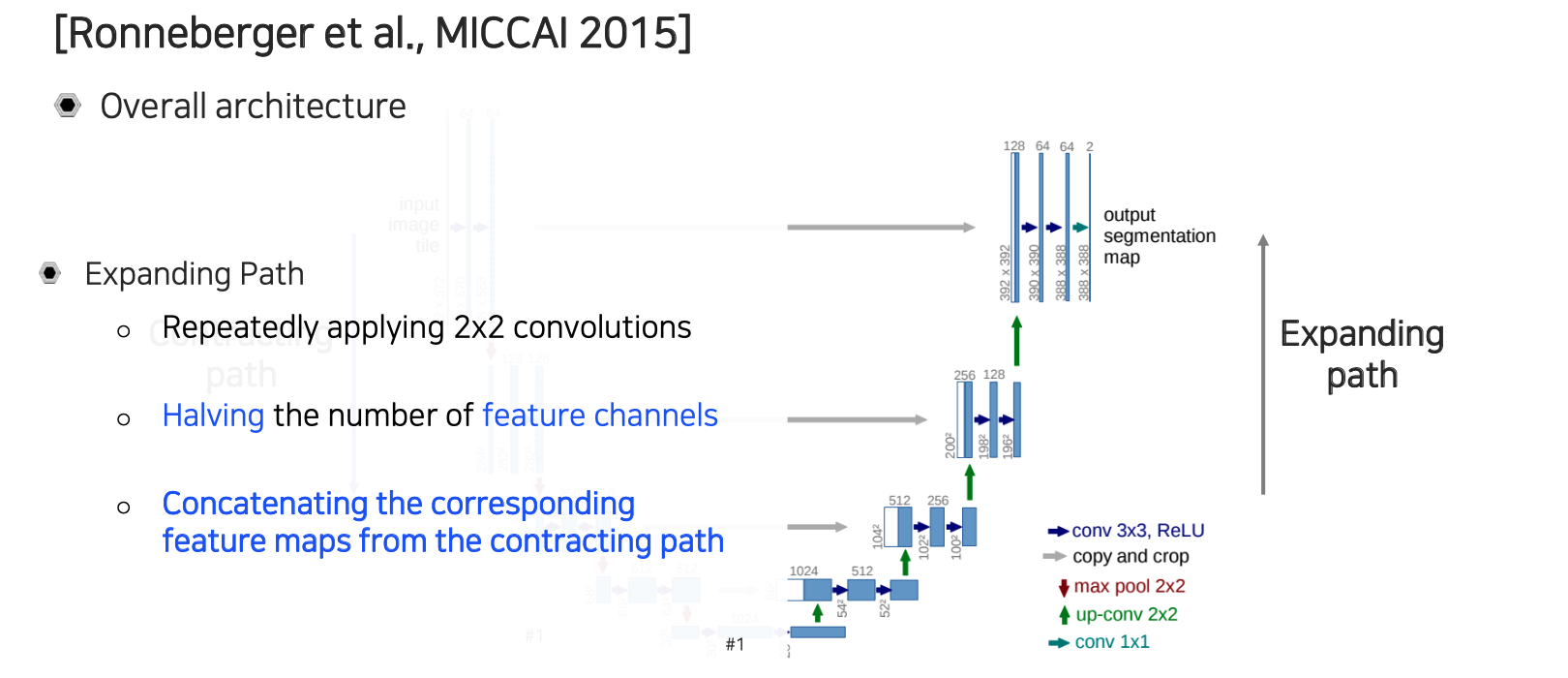 Expanding path에서는 convolution을 연속적으로 활용해준다. 여기서는 feature의 채널이 공간 resolution이 올라갈 때마다 절반씩 줄어들게 된다. 이렇게해서 원래 input과 정확히 대칭이 되는 구조로 만들어준다. 그리고 contracting path에서 나온 중간 feature들이 expanding path 쪽으로 transfer 되어져서 concatenation이 된다. 이렇게 concatenation을 해서 low layer에 있던 feature map들이 high layer에 있는 feature map들로 전달이 될 수 있도록 해준다. 그리고 대칭 구조를 유지하기 위해서 같은 resolution 상에 있던 feature들을 skip connection을 이용해서 옮겨주게 되는 것이다.
Expanding path에서는 convolution을 연속적으로 활용해준다. 여기서는 feature의 채널이 공간 resolution이 올라갈 때마다 절반씩 줄어들게 된다. 이렇게해서 원래 input과 정확히 대칭이 되는 구조로 만들어준다. 그리고 contracting path에서 나온 중간 feature들이 expanding path 쪽으로 transfer 되어져서 concatenation이 된다. 이렇게 concatenation을 해서 low layer에 있던 feature map들이 high layer에 있는 feature map들로 전달이 될 수 있도록 해준다. 그리고 대칭 구조를 유지하기 위해서 같은 resolution 상에 있던 feature들을 skip connection을 이용해서 옮겨주게 되는 것이다.
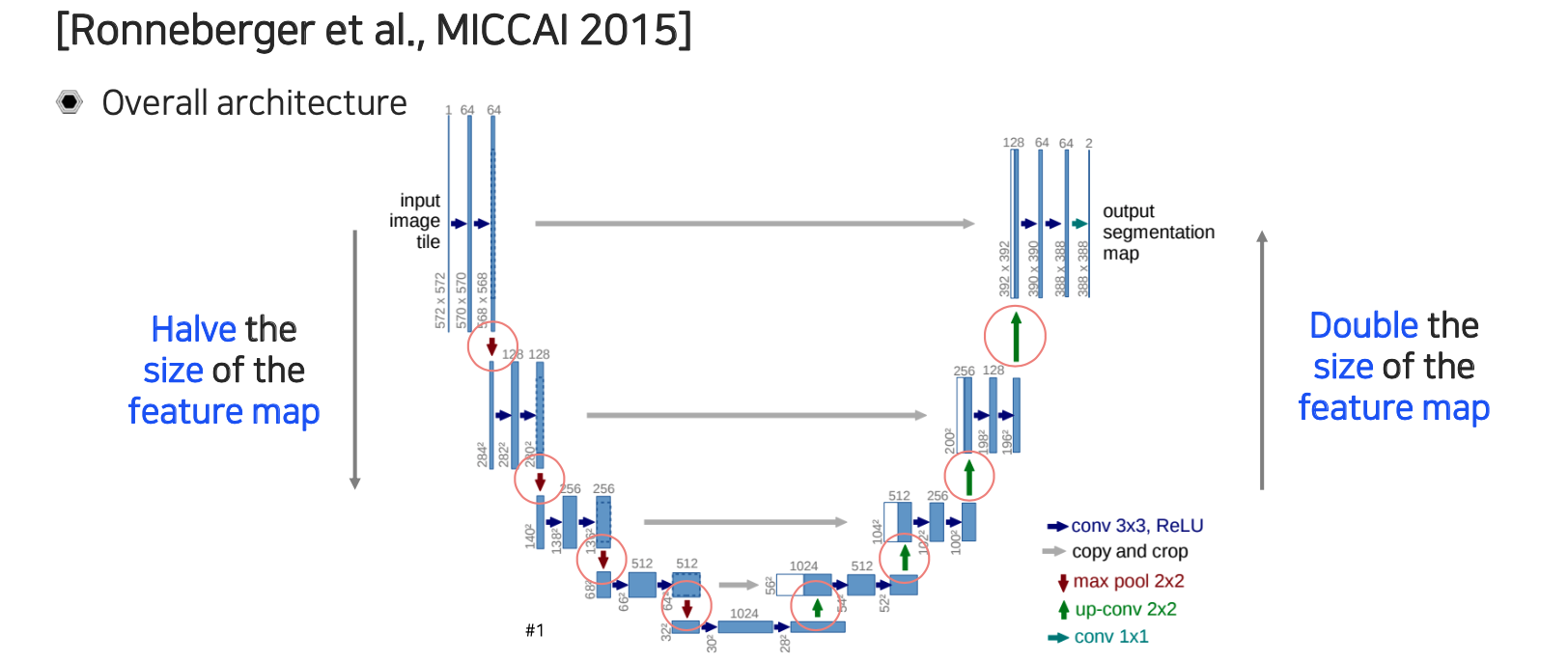
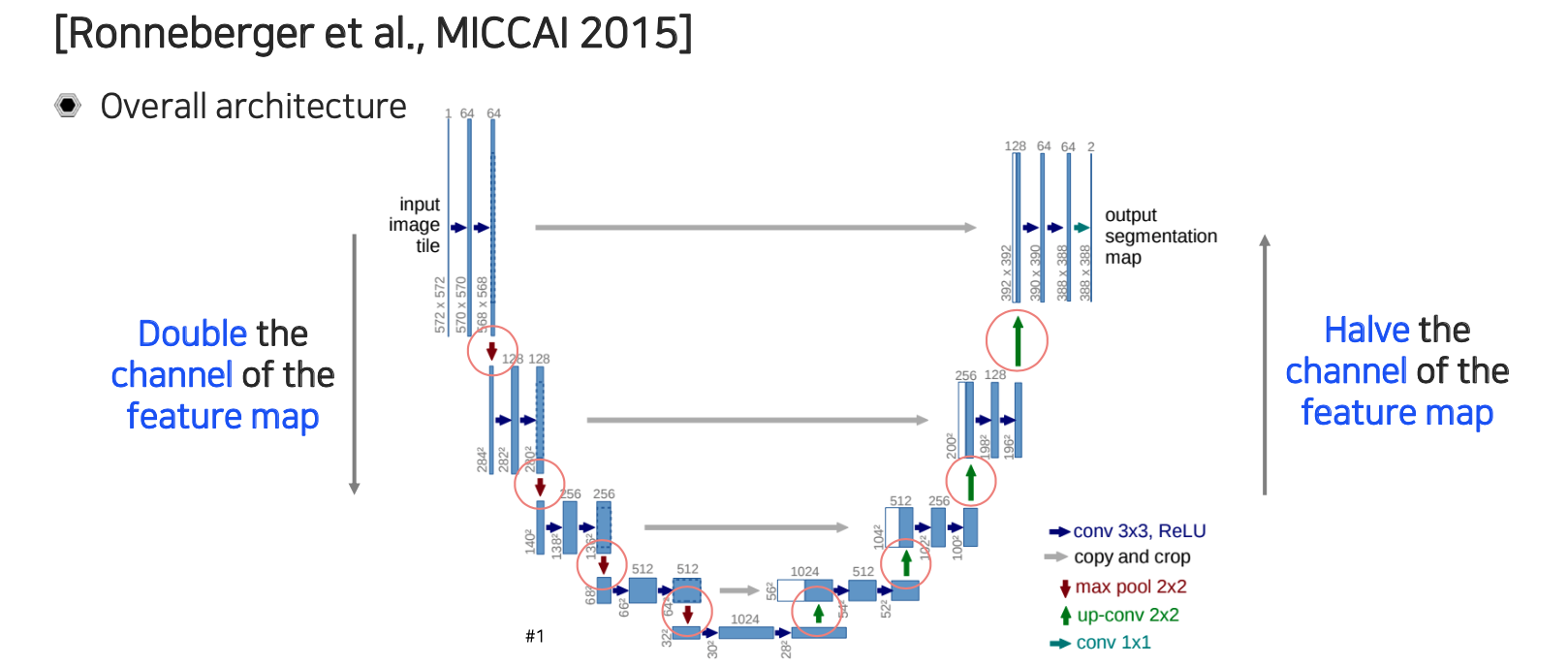 공간상의 resolution을 기준으로 보면 contracting path에서는 줄어들게 되고 expanding path에서는 늘어나게 되는 것이다. 반대로 채널은 resolution과는 반대로 contracting path에서는 늘어나게 되고 expanding path에서는 줄어들게 된다. 공간이 작아졌을 때 공간 정보를 잃는 만큼 이를 채널 쪽에다 넣어주는 그러한 효과를 보여준다고 볼 수 있다. 최대한 정보의 손실을 만회해주기 위해서 공간축을 줄이면 채널축을 늘리고 반대로 공간축을 늘리면 채널축을 줄이는 형태로 유지해준다고 볼 수 있다.
공간상의 resolution을 기준으로 보면 contracting path에서는 줄어들게 되고 expanding path에서는 늘어나게 되는 것이다. 반대로 채널은 resolution과는 반대로 contracting path에서는 늘어나게 되고 expanding path에서는 줄어들게 된다. 공간이 작아졌을 때 공간 정보를 잃는 만큼 이를 채널 쪽에다 넣어주는 그러한 효과를 보여준다고 볼 수 있다. 최대한 정보의 손실을 만회해주기 위해서 공간축을 줄이면 채널축을 늘리고 반대로 공간축을 늘리면 채널축을 줄이는 형태로 유지해준다고 볼 수 있다.
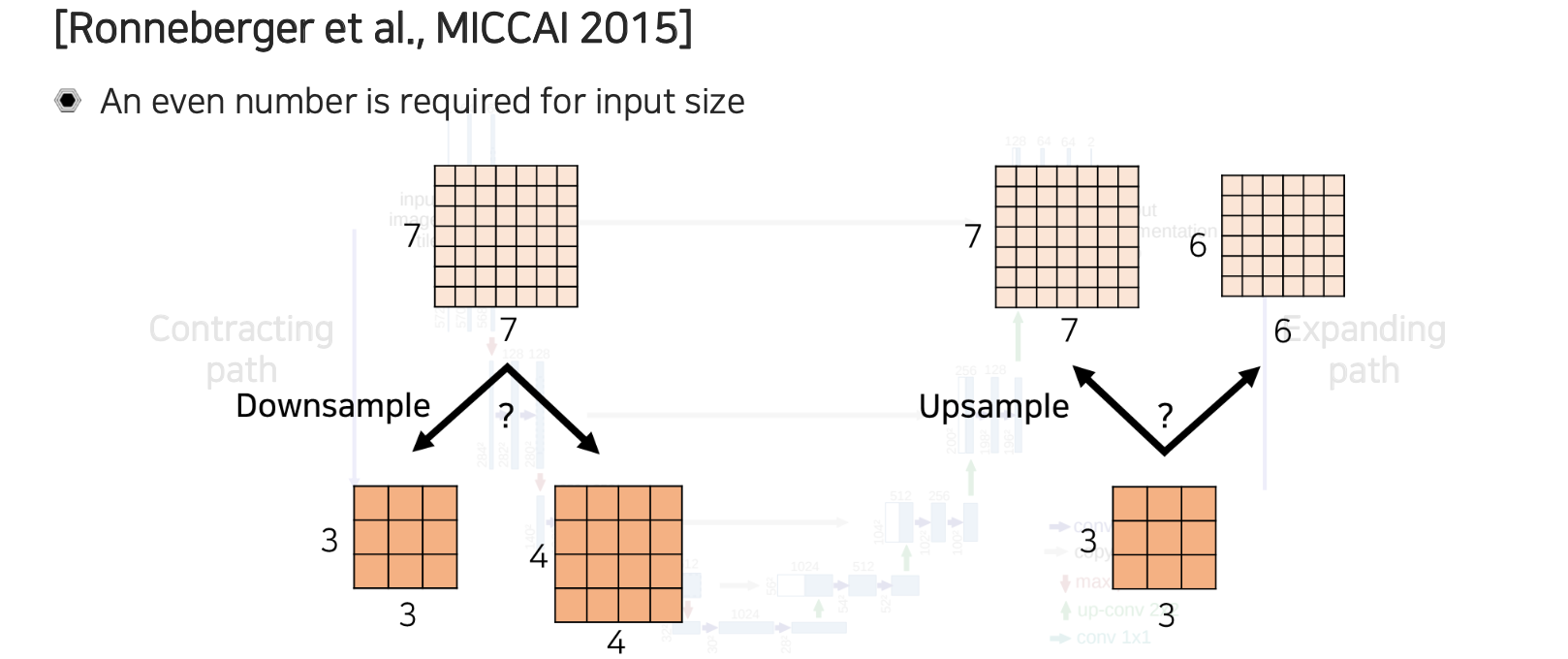 이러한 과정에서 중간에 feature map의 크기가 홀수인 경우에는 어떻게 처리를 해야할까? 공간 크기에 따라서 U-Net을 사용할 때에는 굉장히 민감하게 작용하기 때문에 신중하게 접근할 필요가 있다. 이는 구현상에서의 issue로 만약 홀수 resolution의 feature map이 있다고 한다면 우리는 downsampling을 적용하게 된다. Downsampling을 일반적으로 pooling으로 구현이 되어 있는데, 예를 들어 max pooling이라고 한다면 downsampling을 구현하는 방식에 따라서 크기가 7이었다면 3이 될수도 있고 4가 될수도 있는 것이다. 만약 pooling을 적용하면 마지막에는 적용할 수 없어서 일부분을 버리게 될 것이다. 이렇게 구현하다보면 일반적으로 크기가 4가 아닌 3으로 나오게 된다.
이러한 과정에서 중간에 feature map의 크기가 홀수인 경우에는 어떻게 처리를 해야할까? 공간 크기에 따라서 U-Net을 사용할 때에는 굉장히 민감하게 작용하기 때문에 신중하게 접근할 필요가 있다. 이는 구현상에서의 issue로 만약 홀수 resolution의 feature map이 있다고 한다면 우리는 downsampling을 적용하게 된다. Downsampling을 일반적으로 pooling으로 구현이 되어 있는데, 예를 들어 max pooling이라고 한다면 downsampling을 구현하는 방식에 따라서 크기가 7이었다면 3이 될수도 있고 4가 될수도 있는 것이다. 만약 pooling을 적용하면 마지막에는 적용할 수 없어서 일부분을 버리게 될 것이다. 이렇게 구현하다보면 일반적으로 크기가 4가 아닌 3으로 나오게 된다.
만약 크기가 3이 되었다면 이를 expanding path에서 upsampling을 해줄 때 contracting path와 크기가 동일해야 concatenation을 해서 skip connection을 만들 수 있기 때문에 7이 나와야 할 것이다. 하지만 일반적으로 구현할 때에는 upsampling에서는 2배가 되기 때문에 7이 아닌 6이 되는 문제가 발생하게 된다. 그래서 중간에 feature map이 홀수가 나타나게 되면은 우리가 FCN이기 때문에 임의의 크기를 넣어도 동작이 된다고는 했지만 중간에 resolution이 맞지 않는 문제가 발생할 수 있다.
 이러한 문제를 피하기 위해서 input이 몇번의 convolution 연산을 지나도 홀수가 발생하지 않도록 2의 배수로 resolution을 만들어줘야 한다. 그래서 이 부분을 구현할 때에는 주의해야 한다.
이러한 문제를 피하기 위해서 input이 몇번의 convolution 연산을 지나도 홀수가 발생하지 않도록 2의 배수로 resolution을 만들어줘야 한다. 그래서 이 부분을 구현할 때에는 주의해야 한다.
DeepLab
 다음으로 살펴 볼 DeepLab은 2015년부터 2018년까지 계속해서 버전이 증가해왔다. 지금은 더 좋은 구조의 모델들이 많이 있지만 U-Net과 DeepLab은 semantic segmentation에 있어서 많은 기여를 한 모델들이다.
다음으로 살펴 볼 DeepLab은 2015년부터 2018년까지 계속해서 버전이 증가해왔다. 지금은 더 좋은 구조의 모델들이 많이 있지만 U-Net과 DeepLab은 semantic segmentation에 있어서 많은 기여를 한 모델들이다.
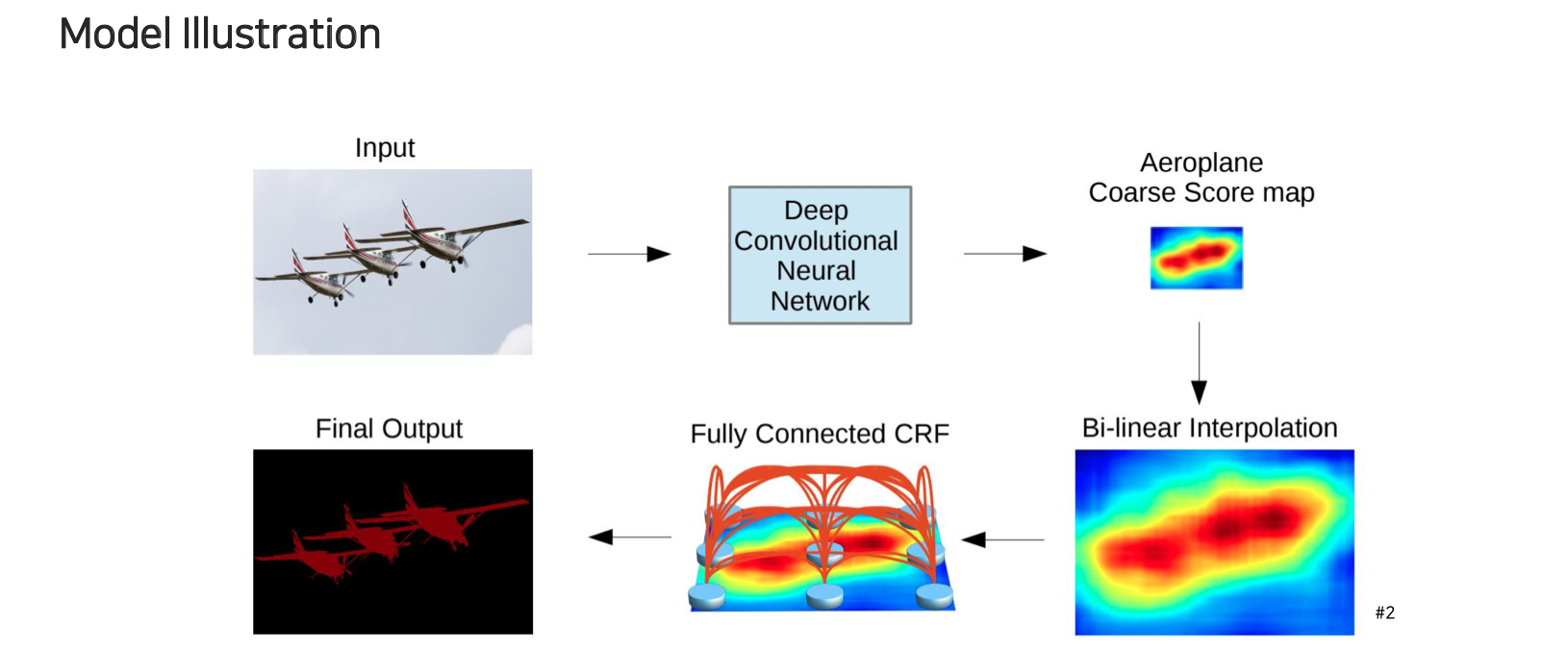 Deep
Deep
Lab의 구조는 input을 deep convolutional neural network에 넣어서 최종적으로 score map을 만들게 된다. 그리고 이 score map에 대해서 bi-linear interpolation을 통해서 정교한 boundary가 아닌 blurry한 low frequency의 output으로 만들어준다. 이것의 성능을 input과 맞춰서 굉장히 정교하게 만들어주기 위해서 fully connected CRF의 형태로 모델링을 해서 score 정보를 image input에 한번 더 refine을 해주는 식으로 최종 결과를 만들어낸다. 그래서 마지막 output은 굉장히 정교하게 segmentation이 되도록 만들어줄 수 있다.
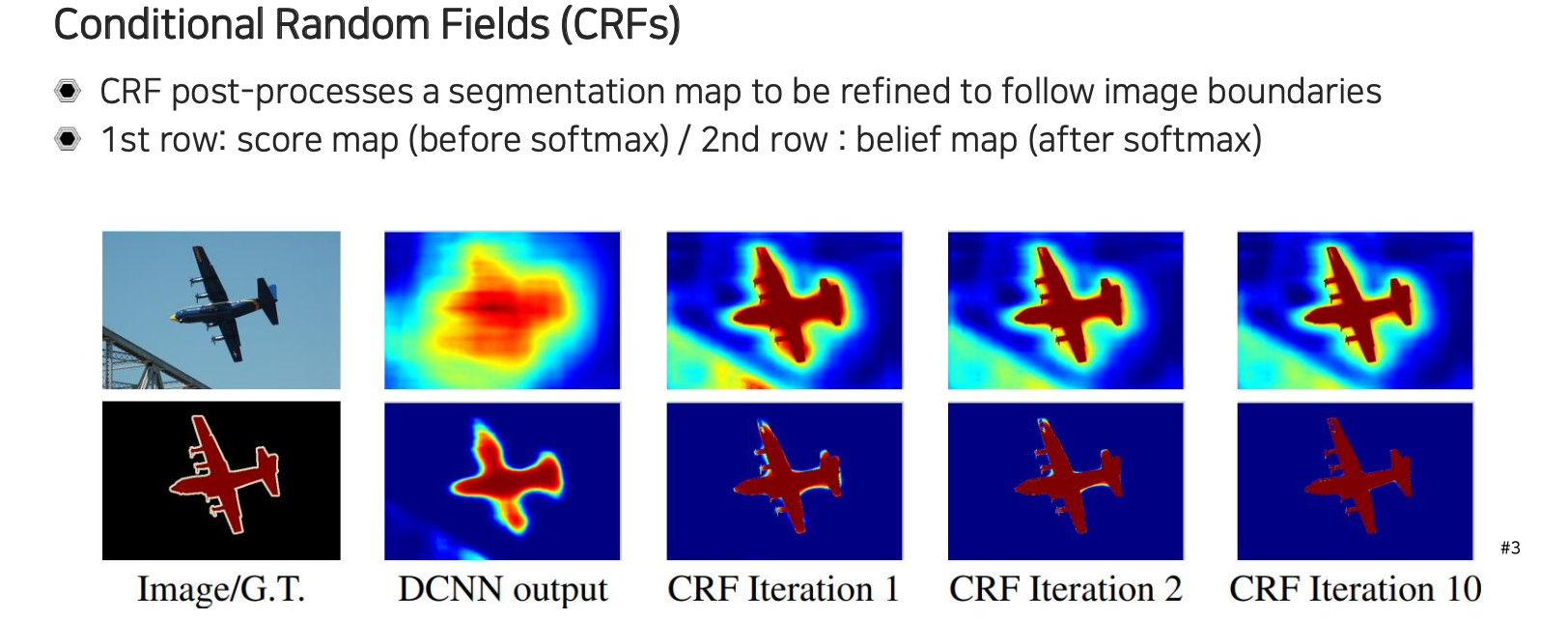 그래서 Conditional Random Fields(CRFs)라는 것은 확률을 모델링 하는 것이다. CRF는 결국 픽셀간의 dependancy를 모델링하는 것으로, segmentation map이 주어지게 되면 CRF를 post-processing으로 사용하게 된다. 일반적으로 image의 경우에는 경계선이 눈에 명확하게 띄는 경우가 있고 굉장히 high resolution이다. 그래서 image를 score map에 대비를 하면 굉장히 정교한 object의 경계 정보를 포함하고 있다고 볼 수 있다. 그래서 score map을 이용해서 경계에 따라서 propagation을 시켜주는 것으로 보면된다. Object의 중심에서는 score가 굉장히 높은데 이를 경계선까지 propagation 시키고 background 쪽 score는 전체적으로 비슷한 색을 포함하고 있기 때문에 배경에 대해서 propagation을 시켜서 edge 중간에서 양방향으로부터 닿게되면 픽셀 정보의 유사도 혹은 관계성에 따라서 정보를 refine해줘서 정교한 boundary를 찾을 수 있도록 만들어주는 것이다. 그래서 CRF로 모델링해서 image의 경계하고 score map과의 관계성을 통해서 refine을 진행해주게 되면 매 iteration마다 배경은 배경색이 짙어지고 object는 해당색이 짙어지게 될 것이다. 여기서 belief map이라는 것은 softmax를 score map에 취한 결과로 더 정교한 결과를 얻을 수 있게 된다.
그래서 Conditional Random Fields(CRFs)라는 것은 확률을 모델링 하는 것이다. CRF는 결국 픽셀간의 dependancy를 모델링하는 것으로, segmentation map이 주어지게 되면 CRF를 post-processing으로 사용하게 된다. 일반적으로 image의 경우에는 경계선이 눈에 명확하게 띄는 경우가 있고 굉장히 high resolution이다. 그래서 image를 score map에 대비를 하면 굉장히 정교한 object의 경계 정보를 포함하고 있다고 볼 수 있다. 그래서 score map을 이용해서 경계에 따라서 propagation을 시켜주는 것으로 보면된다. Object의 중심에서는 score가 굉장히 높은데 이를 경계선까지 propagation 시키고 background 쪽 score는 전체적으로 비슷한 색을 포함하고 있기 때문에 배경에 대해서 propagation을 시켜서 edge 중간에서 양방향으로부터 닿게되면 픽셀 정보의 유사도 혹은 관계성에 따라서 정보를 refine해줘서 정교한 boundary를 찾을 수 있도록 만들어주는 것이다. 그래서 CRF로 모델링해서 image의 경계하고 score map과의 관계성을 통해서 refine을 진행해주게 되면 매 iteration마다 배경은 배경색이 짙어지고 object는 해당색이 짙어지게 될 것이다. 여기서 belief map이라는 것은 softmax를 score map에 취한 결과로 더 정교한 결과를 얻을 수 있게 된다.
 Deep
Deep
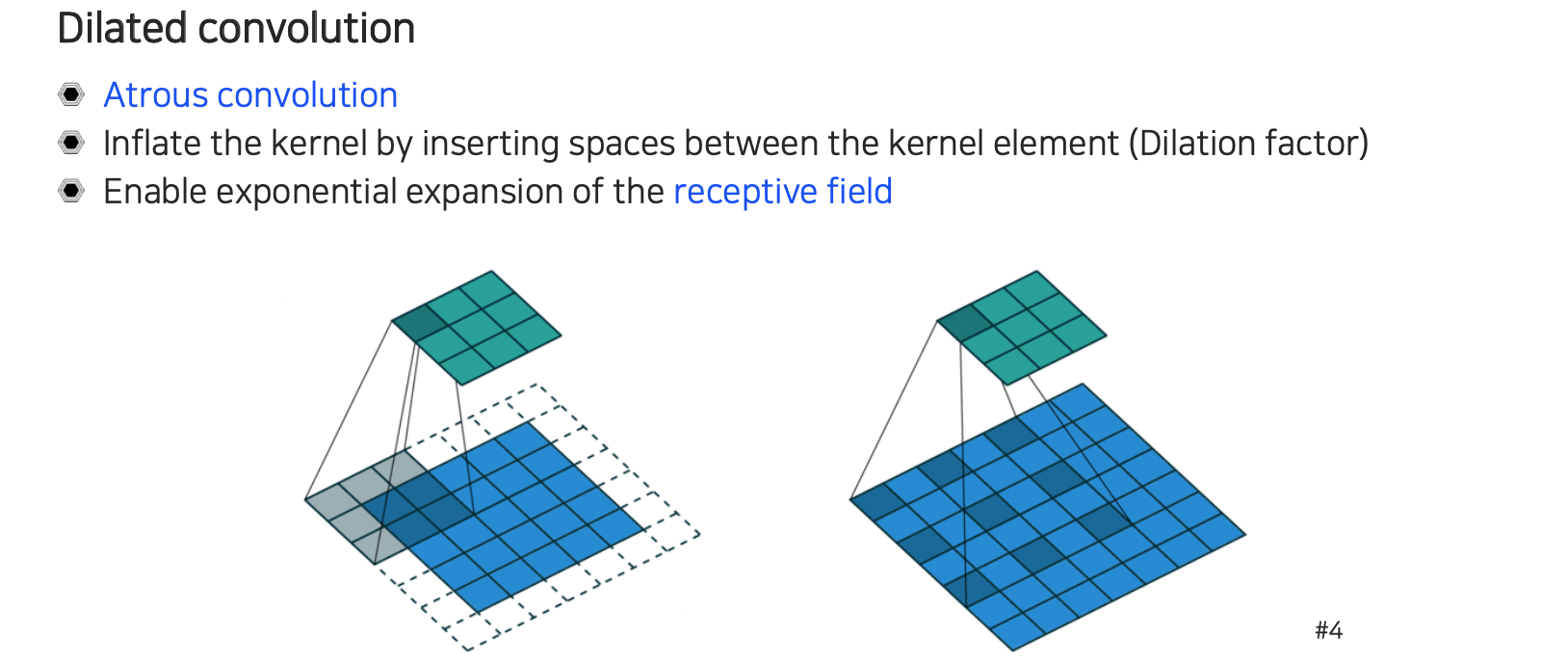
Lab에서 또 다른 중요한 개념으로는 dilated convolution 혹은 atrous convolution이 있다. 기존의 convolution에서는 하나의 값을 결정하기 위해서는 붙어 있는 값들 활용했다. Dilated convolution의 경우에는 동일한 크기의 kernel을 사용한다는 점은 같지만 dilation factor에 따라서 중간에 해당 크기만큼 건너 뛰면서 filter를 배치하게 된다. 그래서 사이에 건너뛴 픽셀의 값은 고려를 하지 않기 때문에 0을 사용하고 똑같이 크기가 3이라면 9개의 값을 사용하지만 대신 사용되는 범위가 달라지게 된다. 이러한 dilated convolution은 receptive field를 확장시키는데 굉장히 많은 도움을 준다. Semantic segmentation에서 receptive field의 크기는 굉장히 중요하다. 이 크기가 충분히 커야 현재 픽셀이 어떠한 object 내에 해당하는 픽셀인지 우리가 판단할 수 있었다. 그래서 이러한 trick들을 이용해서 동일한 파라미터 수를 사용하더라도 더 넓은 receptive field를 가져가는 식으로 활용할 수 있다.
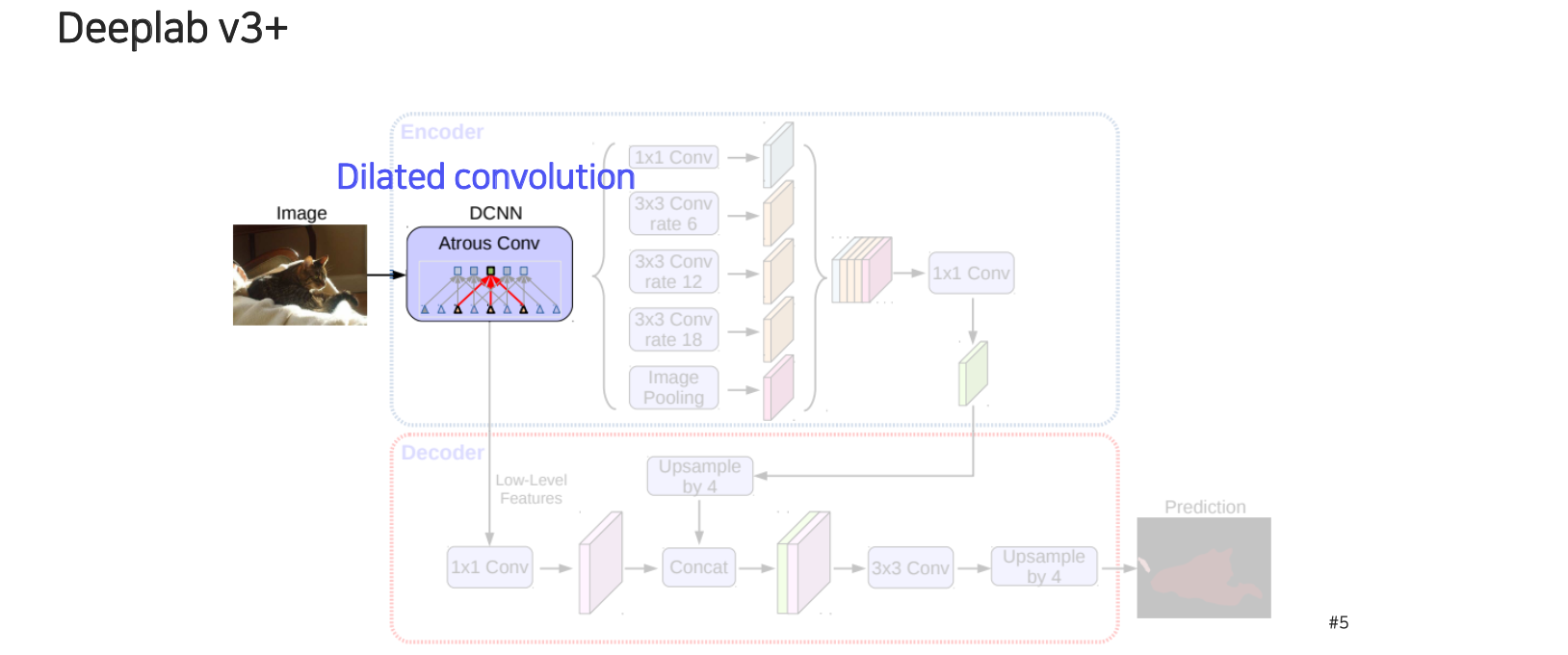 DeepLab v3+는 dilated convolution 이용한 deep convolutional neural network를 backbone network로 사용하게 된다.
DeepLab v3+는 dilated convolution 이용한 deep convolutional neural network를 backbone network로 사용하게 된다.
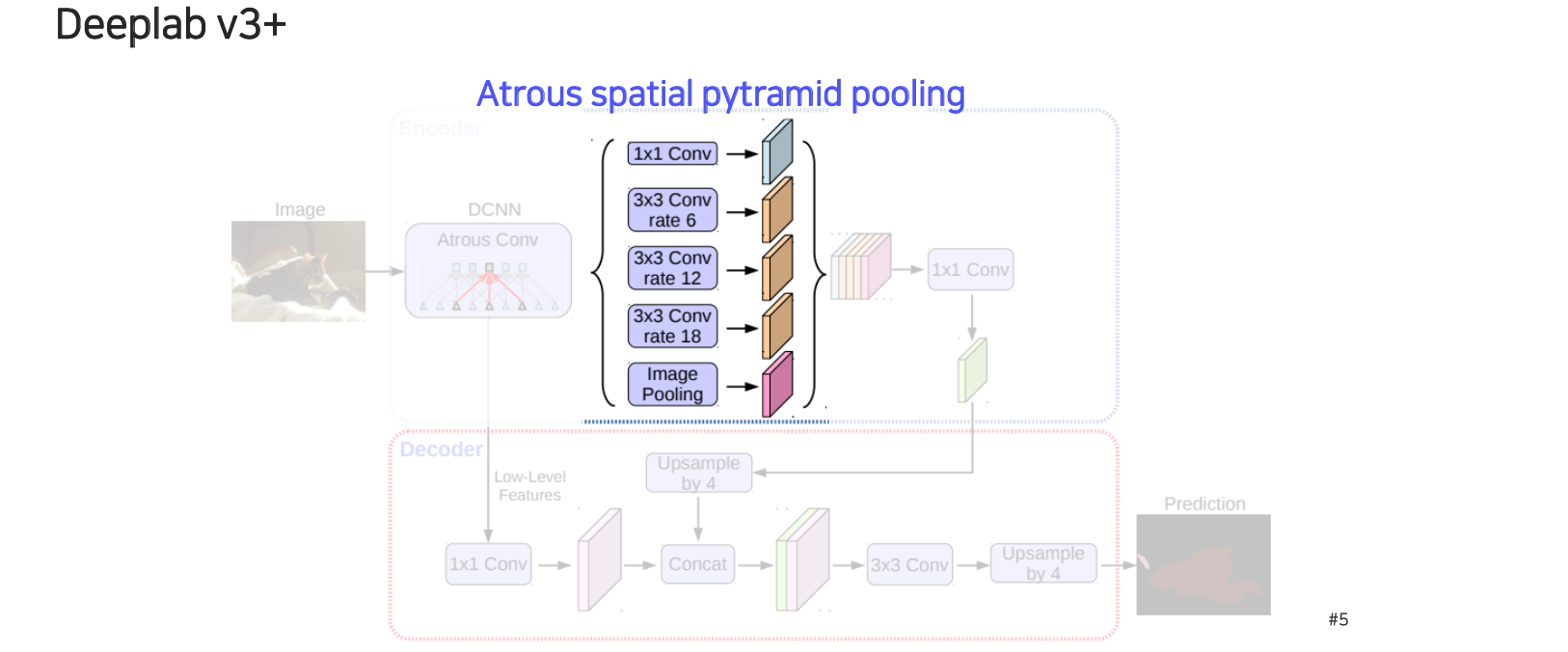 물체마다 크기가 다르고 봐야하는 context도 다 다르기 때문에 고정된 receptive field를 하나만 사용해서는 sementic segmentation에서는 불리할 수 있다. 그래서 여기에 도입된 것이 spatial pyramid pooling 기법이다. 우리가 집중하고 싶은 receptive field의 크기를 adaptive하게 조정하는 것이다. 각 convolution마다 rate를 다르게 주어 서로 다른 scale level을 다룰 수 있도록 만들어준다.
물체마다 크기가 다르고 봐야하는 context도 다 다르기 때문에 고정된 receptive field를 하나만 사용해서는 sementic segmentation에서는 불리할 수 있다. 그래서 여기에 도입된 것이 spatial pyramid pooling 기법이다. 우리가 집중하고 싶은 receptive field의 크기를 adaptive하게 조정하는 것이다. 각 convolution마다 rate를 다르게 주어 서로 다른 scale level을 다룰 수 있도록 만들어준다.
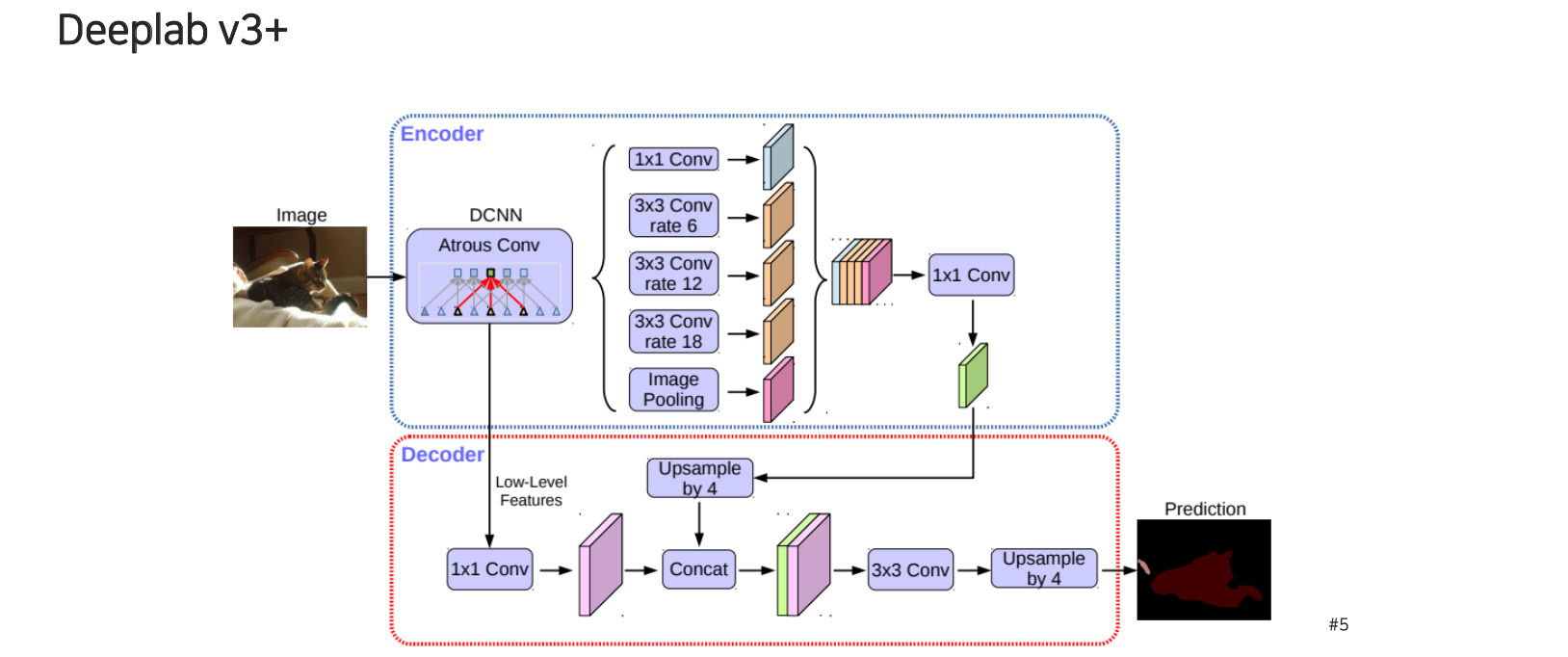 이렇게 얻은 여러 scale의 feature들을 concatenation을 해주고 convolution을 적용해서 하나의 feature map으로 압축시켜 준다. 이렇게 압축된 feature map에는 굉장히 좋은 정보가 담겨 있을거라는 가정을 하고 task를 수행하게 되는데 이를 encoder라고 한다.
이렇게 얻은 여러 scale의 feature들을 concatenation을 해주고 convolution을 적용해서 하나의 feature map으로 압축시켜 준다. 이렇게 압축된 feature map에는 굉장히 좋은 정보가 담겨 있을거라는 가정을 하고 task를 수행하게 되는데 이를 encoder라고 한다.
여기서 바로 prediction을 하게 되면 FCN이 가지고 있던 마지막 layer가 low resolution이기 때문에 semantic segmentation map이 굉장히 rough한 형태로 나오게 될 것이다. 그래서 DeepLab v3+에서는 decoder라고 해서 중간 feature map과 마지막 feature map을 결합할 수 있는 decoder 구조를 디자인하게 된다. Decoder에서는 low level feature를 먼저 convolution을 통해서 feature transform한 형태로 가져오고, low resolution으로 변한 encoder의 feature는 high level의 semantic 정보를 가지고 있는 feature map을 upsampling을 통해서 resolution을 맞춰서 concatenation을 해준다. 여기에 이제 convolution과 upsampling을 통해서 최종적으로 image input 크기와 동일한 output을 출력해주는 score map을 만들어주게 된다. 최종 prediction의 차원은 채널축이 결국 class의 개수가 된다.
 위는 이제 DeepLab v3+의 결과이다.
위는 이제 DeepLab v3+의 결과이다.
