
Landmark localization
 Landmark localization은 facial keypoint나 human pose에서의 skeleton을 구성하는 기본적인 요소인 anchor point들을 찾는 task이다. 이를 위해서 landmark라는 단어의 정의가 먼저 필요하다. Facial landmark라고 하는 것은 입꼬리라든지 입 중간 지점 등 얼굴에 대한 구조를 파악하는데 필요한 기본적인 point들의 구성이라고 생각하면 된다. Human pose의 경우에는 관절과 손발의 끝과 같이 관절 구조를 정의하는 것이 landmark가 된다. 그래서 landmark localization을 keypoint estimation이라고도 한다. Landmark localization 문제는 결국 keypoint들의 coordinate들을 prediction하는 문제로 귀결이 된다.
Landmark localization은 facial keypoint나 human pose에서의 skeleton을 구성하는 기본적인 요소인 anchor point들을 찾는 task이다. 이를 위해서 landmark라는 단어의 정의가 먼저 필요하다. Facial landmark라고 하는 것은 입꼬리라든지 입 중간 지점 등 얼굴에 대한 구조를 파악하는데 필요한 기본적인 point들의 구성이라고 생각하면 된다. Human pose의 경우에는 관절과 손발의 끝과 같이 관절 구조를 정의하는 것이 landmark가 된다. 그래서 landmark localization을 keypoint estimation이라고도 한다. Landmark localization 문제는 결국 keypoint들의 coordinate들을 prediction하는 문제로 귀결이 된다.
Coordinate regression
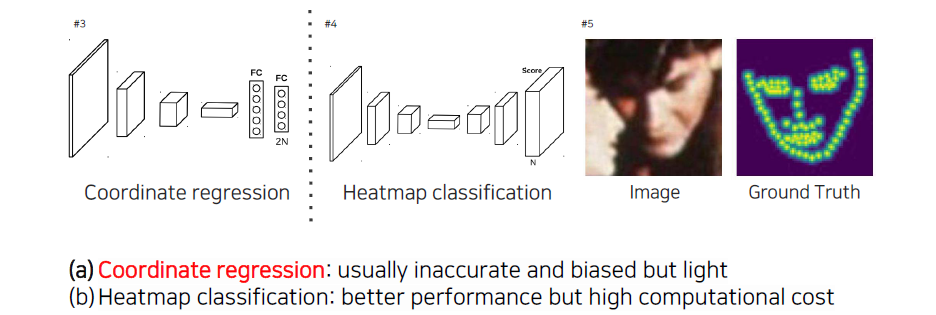 Landmark localization 문제를 해결하는 대표적인 방법으로는 regression과 heatmap이 있는데, 먼저 coordinate regression 방법부터 알아보고자 한다. Regression의 경우 input이 들어왔을 때 좌표를 바로 출력으로 추정하는 방식이다. 이 방식은 부정확하거나 bias 된 결과를 만들 때가 많지만, 가볍고 빠르게 하고 싶을 때는 효과적인 방식에 해당하게 된다.
Landmark localization 문제를 해결하는 대표적인 방법으로는 regression과 heatmap이 있는데, 먼저 coordinate regression 방법부터 알아보고자 한다. Regression의 경우 input이 들어왔을 때 좌표를 바로 출력으로 추정하는 방식이다. 이 방식은 부정확하거나 bias 된 결과를 만들 때가 많지만, 가볍고 빠르게 하고 싶을 때는 효과적인 방식에 해당하게 된다.
DensePose
 Direct regression 방법 중에서 DensePose에 대해서 알아보고자 한다. DensePose는 사람의 surface를 바로 regression한다. 굉장히 dense한 모든 point들의 landmark를 prediction하는 방법이다.
Direct regression 방법 중에서 DensePose에 대해서 알아보고자 한다. DensePose는 사람의 surface를 바로 regression한다. 굉장히 dense한 모든 point들의 landmark를 prediction하는 방법이다.
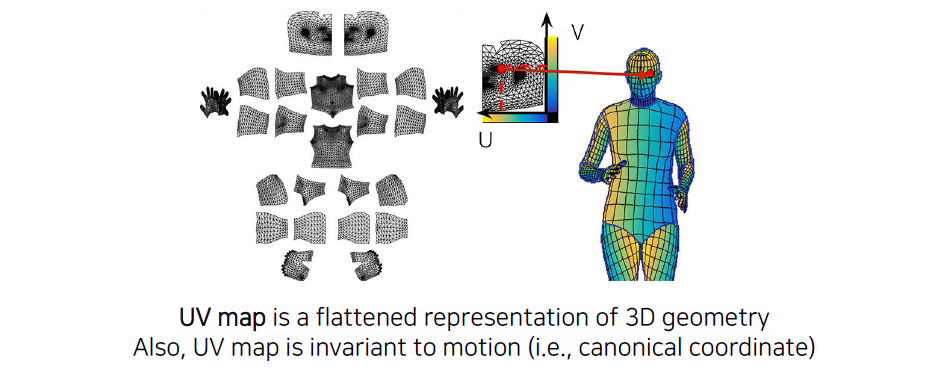 3D surface의 모든 point들을 regression하기 위해서 point들에 대한 3D 대응점들을 정의해야 한다. Graphics나 3D rendering 쪽 domain에서 많이 사용되는 UV map을 이용해서 할 수 있다. UV map은 texture map으로 image 형태로 위와 같이 구성이 된다. 부분부분 잘라서 좌표를 정의하고 거기다가 색칠을 해서 그림을 그리게 된다. 이렇게 해서 옷을 입힌다고 생각하면 된다. 각 위치에서 좌표를 와 같이 정의하게 되는데, 이때 3D 상에 대응되는 지점인 3D point나 mesh에 이 좌표를 저장해놓는다. 우측에서 노란색과 파란색으로 표현이 된 것은 좌표를 나타내고 있다고 생각하면 된다. Mesh 위에 색을 직접 입히기 전에 좌표를 먼저 입혀놓고, 여기에 해당하는 점을 UV map에서 참조하면 거기서 색 정보를 얻어올 수 있게 된다. 이러한 식으로 lookup table 형태로 UV map을 사용하는 것이다. 그래서 UV map을 한번 결정해놓고 나면 texture map만 교체해서 바로바로 3D model에 올릴 수 있는 것이다. 3D model이 움직인다고 하더라도 이러한 옷이 3D model을 따라서 움직이게 되는 것이다. 이러한 UV map은 motion에 대해서 invariant한 특징이 있고, 이러한 이유 덕분에 graphics나 3D rendering 쪽에서 많이 사용된다.
3D surface의 모든 point들을 regression하기 위해서 point들에 대한 3D 대응점들을 정의해야 한다. Graphics나 3D rendering 쪽 domain에서 많이 사용되는 UV map을 이용해서 할 수 있다. UV map은 texture map으로 image 형태로 위와 같이 구성이 된다. 부분부분 잘라서 좌표를 정의하고 거기다가 색칠을 해서 그림을 그리게 된다. 이렇게 해서 옷을 입힌다고 생각하면 된다. 각 위치에서 좌표를 와 같이 정의하게 되는데, 이때 3D 상에 대응되는 지점인 3D point나 mesh에 이 좌표를 저장해놓는다. 우측에서 노란색과 파란색으로 표현이 된 것은 좌표를 나타내고 있다고 생각하면 된다. Mesh 위에 색을 직접 입히기 전에 좌표를 먼저 입혀놓고, 여기에 해당하는 점을 UV map에서 참조하면 거기서 색 정보를 얻어올 수 있게 된다. 이러한 식으로 lookup table 형태로 UV map을 사용하는 것이다. 그래서 UV map을 한번 결정해놓고 나면 texture map만 교체해서 바로바로 3D model에 올릴 수 있는 것이다. 3D model이 움직인다고 하더라도 이러한 옷이 3D model을 따라서 움직이게 되는 것이다. 이러한 UV map은 motion에 대해서 invariant한 특징이 있고, 이러한 이유 덕분에 graphics나 3D rendering 쪽에서 많이 사용된다.
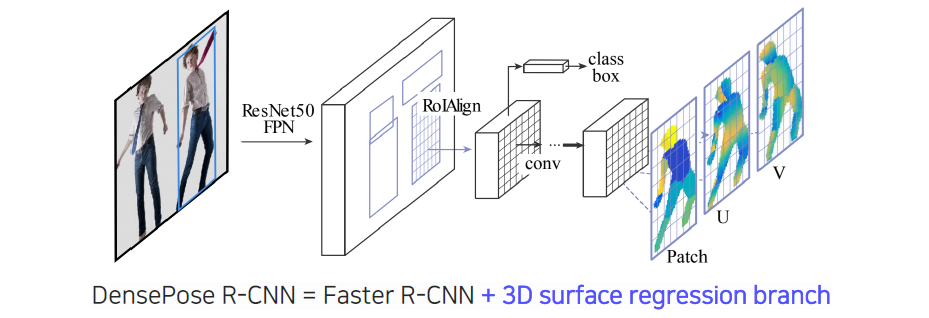 이렇게 data를 표현하기 위해서 UV map을 먼저 정의할 수 있었다. DensePose는 기존의 2-stage network인 faster R-CNN을 기반으로 해서 RPN으로부터 RoIAlign을 하고 convolution feature map을 뽑아낸 다음에 여기에 대해서 classification과 bounding box regression을 하면서 동시에 mask R-CNN과 같이 mask뿐만 아니라 part segmentation이 나오고 UV 좌표가 regression 되어서 나올 것이다. 그래서 어떻게보면 DensePose는 mask R-CNN의 직접적인 확장버전으로 생각할 수 있다. 결과적으로 제안된 DensePose R-CNN은 Faster R-CNN과 3D surface regression을 어떠한 식으로 결합할지에 대해서 제안한 방식이라고 볼 수 있다.
이렇게 data를 표현하기 위해서 UV map을 먼저 정의할 수 있었다. DensePose는 기존의 2-stage network인 faster R-CNN을 기반으로 해서 RPN으로부터 RoIAlign을 하고 convolution feature map을 뽑아낸 다음에 여기에 대해서 classification과 bounding box regression을 하면서 동시에 mask R-CNN과 같이 mask뿐만 아니라 part segmentation이 나오고 UV 좌표가 regression 되어서 나올 것이다. 그래서 어떻게보면 DensePose는 mask R-CNN의 직접적인 확장버전으로 생각할 수 있다. 결과적으로 제안된 DensePose R-CNN은 Faster R-CNN과 3D surface regression을 어떠한 식으로 결합할지에 대해서 제안한 방식이라고 볼 수 있다.
최종적으로 출력을 학습하는데는 cross-entropy를 통해서 classification loss를 학습하고 smooth L1 loss로 bounding box regression 등 나머지 regression에 대해서 학습을 하게 된다.
RetinaFace
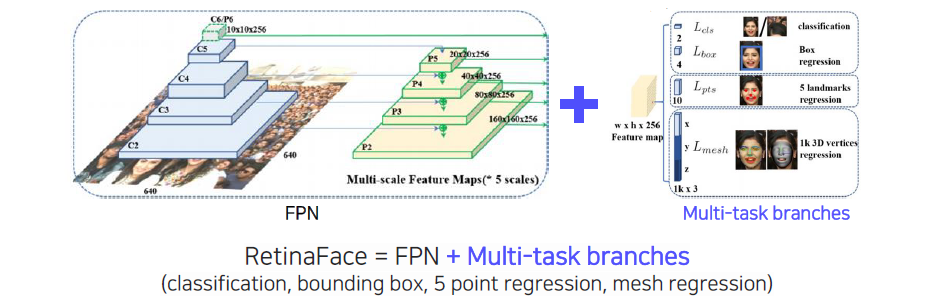 RetinaFace는 1-stage 연구의 응용으로, FPN과 multi-task branch를 각 scale마다 적용한 1-stage 구조이다. RetinaFace에서 재미있는 부분은 동시에 4가지 task를 수행하는 head를 사용한다는 것이다.
RetinaFace는 1-stage 연구의 응용으로, FPN과 multi-task branch를 각 scale마다 적용한 1-stage 구조이다. RetinaFace에서 재미있는 부분은 동시에 4가지 task를 수행하는 head를 사용한다는 것이다.
Extension pattern
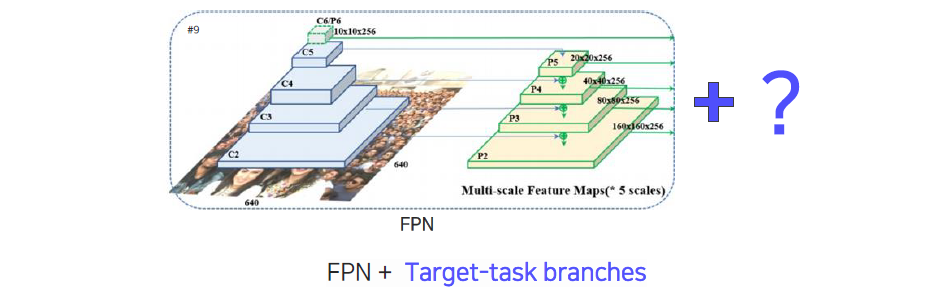 FPN 구조나 object detector를 구성하고 있던 backbone network 구조 위에다가 1-stage든 2-stage든, region proposal을 사용하든 안하든 상관없이 object detector 위에 target task의 head를 디자인해서 올리는 것에서 많은 확장이 가능하고 서로 다른 application을 만들 수 있는 좋은 구조이다. 그래서 object detector가 물체를 그저 탐지하는 지루한 task로 볼 수도 있지만, 뒤쪽의 head를 어떻게 설계하느냐에 따라서 훨씬 다양하고 획기적인 문제로 발전할 수 있는 가능성이 있다.
FPN 구조나 object detector를 구성하고 있던 backbone network 구조 위에다가 1-stage든 2-stage든, region proposal을 사용하든 안하든 상관없이 object detector 위에 target task의 head를 디자인해서 올리는 것에서 많은 확장이 가능하고 서로 다른 application을 만들 수 있는 좋은 구조이다. 그래서 object detector가 물체를 그저 탐지하는 지루한 task로 볼 수도 있지만, 뒤쪽의 head를 어떻게 설계하느냐에 따라서 훨씬 다양하고 획기적인 문제로 발전할 수 있는 가능성이 있다.
Heatmap classification
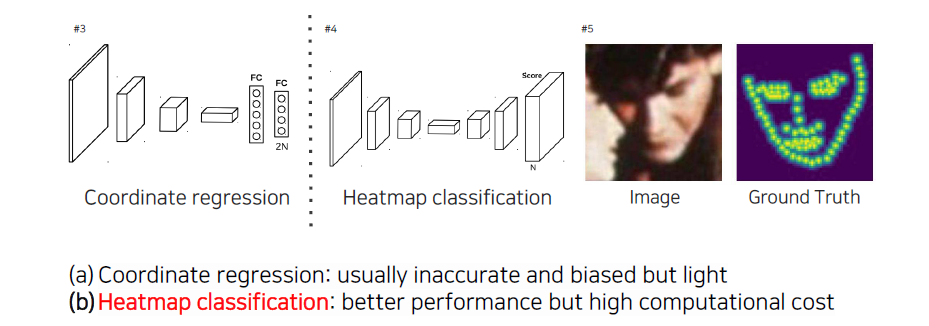 지금까지 살펴본 regression의 장점은 차원이 작아 여러개의 task를 중첩해서 사용하는 multi-task가 가능하다는 것과 dense한 keypoint를 prediction이 가능하다는 것이다. Heatmap classification은 우측의 예시와 같이 어떠한 좌표의 점으로 정확히 찍힌 것이 아니라 Gaussian과 같이 score map 형태로 나온 것을 classification하는 것이다. 일반적으로 heatmap을 사용하는 방식의 성능이 더 좋다. 하지만 heatmap을 구하는 과정에서 computational cost가 굉장히 큰 문제가 있다. 그 이유는 영상의 픽셀들을 돌면서 해당 픽셀이 keypoint인지, landmark인 확률이 어떠한지에 대해서 계산을 해야하기 때문이다. 그리고 heatmap을 좌표로 추출하기 위한 과정이 추가적으로 필요하다. Heatmap classification은 heatmap을 발생시키기 때문에 각 채널마다 하나의 heatmap 정도밖에 표현을 못하는 경우도 있고, 여러 heatmap을 표현하다고 하더라도 하나의 의미를 가지는 keypoint에 대해서 다양한 위치를 특정하는 것은 가능하다. 앞서 살펴본 regression과 같이 픽셀끼리 연결이 되어있는 정교한 표현은 heatmap으로는 불가능하다.
지금까지 살펴본 regression의 장점은 차원이 작아 여러개의 task를 중첩해서 사용하는 multi-task가 가능하다는 것과 dense한 keypoint를 prediction이 가능하다는 것이다. Heatmap classification은 우측의 예시와 같이 어떠한 좌표의 점으로 정확히 찍힌 것이 아니라 Gaussian과 같이 score map 형태로 나온 것을 classification하는 것이다. 일반적으로 heatmap을 사용하는 방식의 성능이 더 좋다. 하지만 heatmap을 구하는 과정에서 computational cost가 굉장히 큰 문제가 있다. 그 이유는 영상의 픽셀들을 돌면서 해당 픽셀이 keypoint인지, landmark인 확률이 어떠한지에 대해서 계산을 해야하기 때문이다. 그리고 heatmap을 좌표로 추출하기 위한 과정이 추가적으로 필요하다. Heatmap classification은 heatmap을 발생시키기 때문에 각 채널마다 하나의 heatmap 정도밖에 표현을 못하는 경우도 있고, 여러 heatmap을 표현하다고 하더라도 하나의 의미를 가지는 keypoint에 대해서 다양한 위치를 특정하는 것은 가능하다. 앞서 살펴본 regression과 같이 픽셀끼리 연결이 되어있는 정교한 표현은 heatmap으로는 불가능하다.
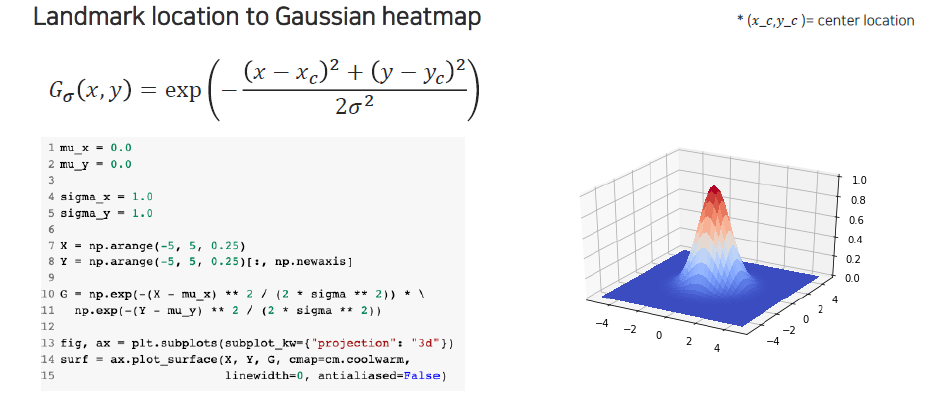 Heatmap으로부터 실제로 좌표 형태로 해석하기 위한 방법에 대해서 설명하고자 한다. 여기에는 추가적인 과정이 필요하다고 앞서 이야기했는데, 좌표를 활용하는 것이 이후에 더 유용하기 때문에 center location을 추출하고 싶을 것이다. 이를 위해서는 landmark에서 Guassian heatmap으로 가는 방법, 혹은 반대로 가는 방법에 대해서 먼저 알아야 한다.
Heatmap으로부터 실제로 좌표 형태로 해석하기 위한 방법에 대해서 설명하고자 한다. 여기에는 추가적인 과정이 필요하다고 앞서 이야기했는데, 좌표를 활용하는 것이 이후에 더 유용하기 때문에 center location을 추출하고 싶을 것이다. 이를 위해서는 landmark에서 Guassian heatmap으로 가는 방법, 혹은 반대로 가는 방법에 대해서 먼저 알아야 한다.
Gaussian의 식을 보면 normalization 부분은 없지만 exponential 안에 center location과 주변 좌표 값들 사이의 거리가 계산이 되어있다. 그래서 center 좌표를 이용해서 landmark location에서 Gaussian heatmap으로 변환하는 과정은 식에 대입하면 된다. 이번에는 반대로 heatmap이 있는 경우에 center location을 뽑아내는 과정은 우선 heatmap을 probability model로 보는 것이다. 결국 우리가 원하는 center location은 heatmap을 기준으로 기대값을 계산하는 것과 동일하게 생각해볼 수 있다.
Hourglass network
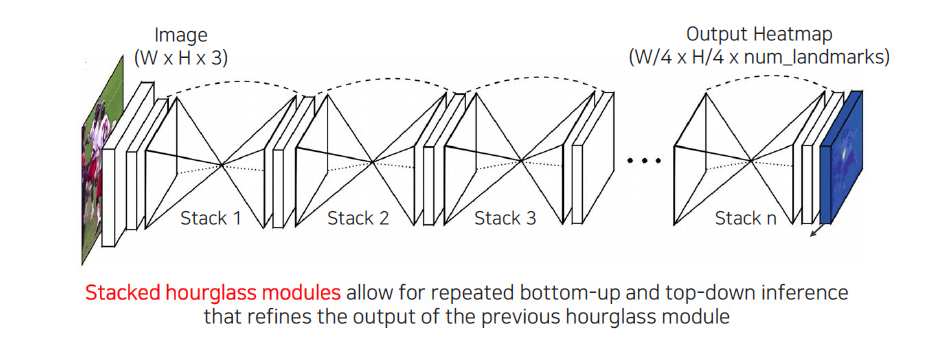 Heatmap representation을 가장 잘 활용한 network로 Hourglass network 연구가 있다. Hourglass는 결국 모래시계를 의미하게 되는데, 해당 연구에서는 stacked hourglass module이라는 것을 사용했다. 중간에 resolution을 줄였다가 키우는 식의 구조를 여러번 쌓아서 학습을 하는 구조이다.
Heatmap representation을 가장 잘 활용한 network로 Hourglass network 연구가 있다. Hourglass는 결국 모래시계를 의미하게 되는데, 해당 연구에서는 stacked hourglass module이라는 것을 사용했다. 중간에 resolution을 줄였다가 키우는 식의 구조를 여러번 쌓아서 학습을 하는 구조이다.
Spatial 영역이 줄어들게 되면 영상에 대한 전체 정보가 작은 차원에 압축이 되어야 하기 때문에 영상에 대해서 receptive field가 굉장히 커지게 된다. 이러면 영상 전체에 대한 context를 잘 고려할 수 있게 되고, 이를 다시 원래의 차원으로 복원을 해줘서 landmark에 대한 localization 성능을 높일 수가 있는 구조이다. 이러한 형식의 hourglass를 여러번 반복한다는 것은 high resolution으로 간 정보를 다시 전체적인 context를 고려해서 압축하면서 정확한 location을 찾는 구조로서 제안이 된 것이다. 중간중간 output을 계속 반복하면서 heatmap 표현을 개선했다고 보면 된다.
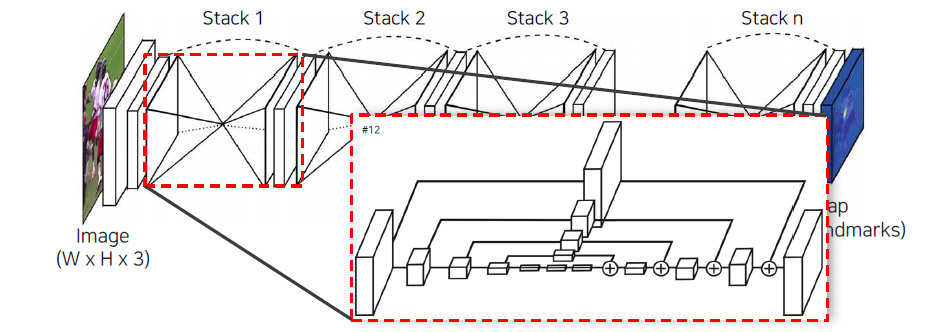 중간에 있는 hourglass network 구조를 자세하게 살펴보면 중간에 spatial dimension에 대한 bottleneck이 있는데, 이것만 사용하게 되면 공간상의 디테일들을 잃어버릴 수 있기 때문에 중간에 feature transform을 통해서 U-Net과 같이 뒤쪽에 더해주는 식으로 설계되어 있다. 이렇게 하면 low layer에 있는 local한 정보를 high layer로 보내는 역할을 수행하게 된다.
중간에 있는 hourglass network 구조를 자세하게 살펴보면 중간에 spatial dimension에 대한 bottleneck이 있는데, 이것만 사용하게 되면 공간상의 디테일들을 잃어버릴 수 있기 때문에 중간에 feature transform을 통해서 U-Net과 같이 뒤쪽에 더해주는 식으로 설계되어 있다. 이렇게 하면 low layer에 있는 local한 정보를 high layer로 보내는 역할을 수행하게 된다.
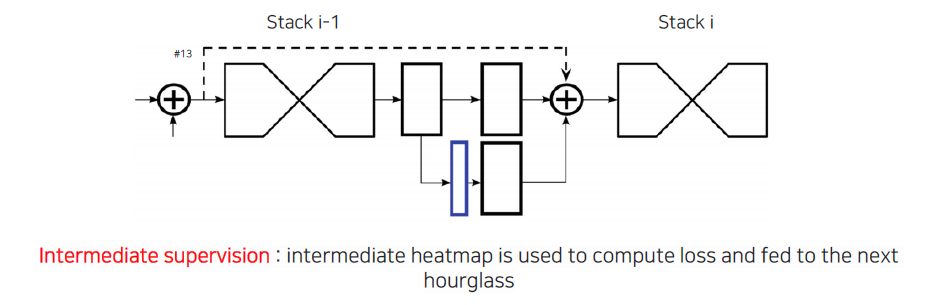 그리고 각 module을 쌓을 때 단순히 그냥 쌓는 것이 아니라 이전 정보를 skip connection을 해주게 된다. 이때 중간의 정보를 한번 빼오게 되는데, 이로부터 heatmap 계산을 한번 수행해준다. 여기에 loss를 걸어줘서 heatmap이 학습될 수 있도록 만들어주고, heatmap을 똑같이 더해줘서 heatmap 정보도 feature 정보와 함께 포함시켜준다.
그리고 각 module을 쌓을 때 단순히 그냥 쌓는 것이 아니라 이전 정보를 skip connection을 해주게 된다. 이때 중간의 정보를 한번 빼오게 되는데, 이로부터 heatmap 계산을 한번 수행해준다. 여기에 loss를 걸어줘서 heatmap이 학습될 수 있도록 만들어주고, heatmap을 똑같이 더해줘서 heatmap 정보도 feature 정보와 함께 포함시켜준다.
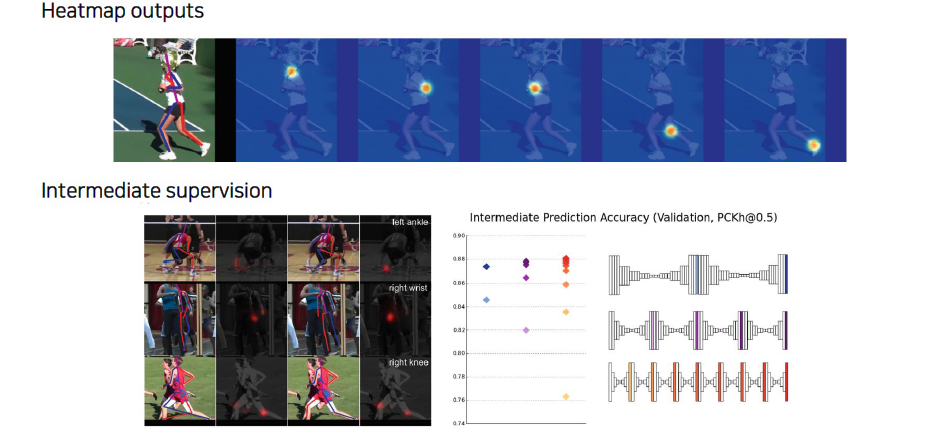 Loss를 걸어줘서 위와 같이 heatmap output이 나올 수 있도록 만들어서 heatmap representation이 잘 나올 수 있도록 해야한다. 각 채널마다 하나의 관절에 대한 heatmap이 나오게 되고, 나온 heatmap의 peak point를 expection을 취하든 max operation을 취하든 해서 좌표로 만들게 된다.
Loss를 걸어줘서 위와 같이 heatmap output이 나올 수 있도록 만들어서 heatmap representation이 잘 나올 수 있도록 해야한다. 각 채널마다 하나의 관절에 대한 heatmap이 나오게 되고, 나온 heatmap의 peak point를 expection을 취하든 max operation을 취하든 해서 좌표로 만들게 된다.
Extensions
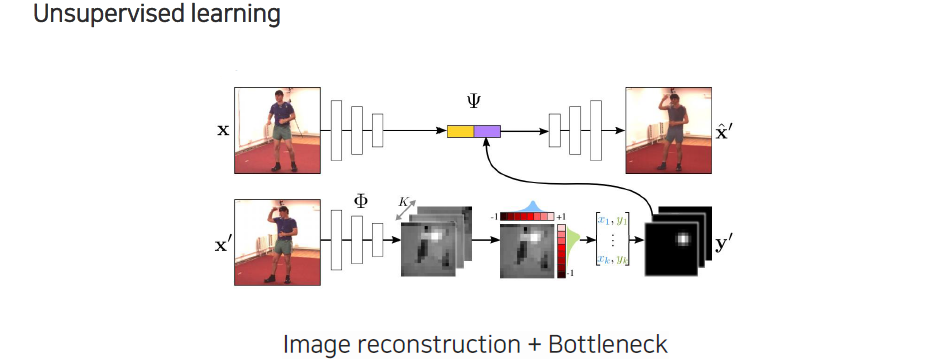 이러한 heatmap 표현을 supervised learning을 통해서 관절을 찾는데만 응용하는 것이 아니라 unsupervised learning에서의 bottleneck으로도 사용할 수 있다. Point 형태로 regression 되는 것에 어떠한 bias를 제공해줄 수 있다. 먼저 image를 input으로 주고 encoder를 통해서 feature로 출력해준다. 이렇게 나온 feature에 어떠한 condition 정보를 넣어주게 된다. 이 condition을 통해서 output으로 움직인 영상이 나올 수 있도록 만들 수 있다.
이러한 heatmap 표현을 supervised learning을 통해서 관절을 찾는데만 응용하는 것이 아니라 unsupervised learning에서의 bottleneck으로도 사용할 수 있다. Point 형태로 regression 되는 것에 어떠한 bias를 제공해줄 수 있다. 먼저 image를 input으로 주고 encoder를 통해서 feature로 출력해준다. 이렇게 나온 feature에 어떠한 condition 정보를 넣어주게 된다. 이 condition을 통해서 output으로 움직인 영상이 나올 수 있도록 만들 수 있다.
여기서 condition은 output으로 나오는 frame에 해당하는 정보를 input으로 넣어서 어떠한 feature를 뽑아내게 된다. 이때 개의 heatmap 표현이 되도록 만들어준다. 다음에 여기에 expectation 식을 이용해서 형태로 뽑아내게 된다. Heatmap과 좌표 벡터 사이에는 미분이 가능하다. Expectation 수식이 선형식이기 때문에 미분이 가능하고 이렇게 heatmap으로부터 landmark를 출력하고, 이를 다시 Gaussian kernel 형태로 깨끗하게 만들어준 것들을 중간 feature map에 concatenation 해줌으로써 condition으로 사용하게 되는 것이다. 이렇게 해서 중간의 bottleneck으로부터 자동으로 keypoint를 정의되도록 유도할 수 있다.
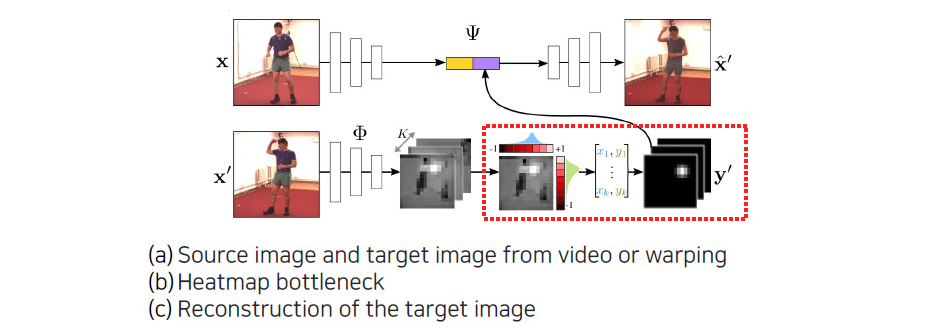 위와 같은 과정으로 학습이 진행된다.
위와 같은 과정으로 학습이 진행된다.
 그 결과로 얼굴에 대한 landmark를 정의해준 적이 없음에도 불구하고 고른 분포의 중요한 point들을 알아서 잘 정의한 것을 볼 수 있다.
그 결과로 얼굴에 대한 landmark를 정의해준 적이 없음에도 불구하고 고른 분포의 중요한 point들을 알아서 잘 정의한 것을 볼 수 있다.
