
Overview of Multi-modal Learning
이번에는 multi-modal learning에 대해서 알아볼 것인데, 그중에서도 visual data를 중심으로 어떻게 text data를 다루는지에 대해서 알아볼 것이다.
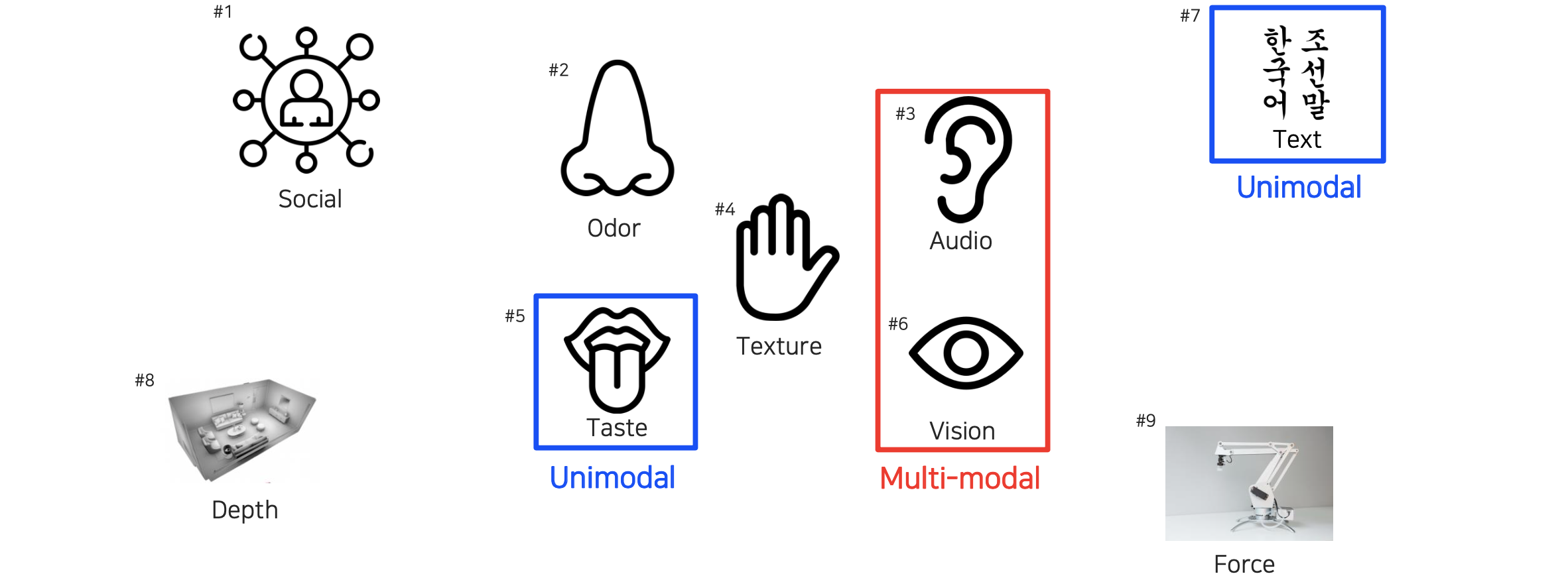 사람이 이 세상과 소통하기 위해서는 오감을 활용하곤 한다. 그래서 눈으로는 보고 귀로는 들으며 손으로는 만지면서 촉감을 느끼는 것이다. 이러한 수단 각각을 modality라고 부른다. 하지만 이렇게 오감을 느끼는 5개의 modality만 있는 것은 아니다. 흔히 사람의 겉모습을 보고 느끼는 social perception이나 3D 감각을 느끼는 depth perception 등도 modality에 포함시킬 수 있다. 이외에도 우리가 많이 활용하고 정보량이 많다고 생각하는 text도 하나의 modality가 될 수 있다. 이렇게 우리가 세상의 표현 방식인 signal이 들어오고 나가는 하나하나를 modality라고 볼 수가 있는 것이다.
사람이 이 세상과 소통하기 위해서는 오감을 활용하곤 한다. 그래서 눈으로는 보고 귀로는 들으며 손으로는 만지면서 촉감을 느끼는 것이다. 이러한 수단 각각을 modality라고 부른다. 하지만 이렇게 오감을 느끼는 5개의 modality만 있는 것은 아니다. 흔히 사람의 겉모습을 보고 느끼는 social perception이나 3D 감각을 느끼는 depth perception 등도 modality에 포함시킬 수 있다. 이외에도 우리가 많이 활용하고 정보량이 많다고 생각하는 text도 하나의 modality가 될 수 있다. 이렇게 우리가 세상의 표현 방식인 signal이 들어오고 나가는 하나하나를 modality라고 볼 수가 있는 것이다.
우리가 세상을 이해한다고 다시 생각해보면 눈만으로 세상을 이해한다고 말할 수는 없을 것이다. 눈으로는 보면서 소리로 들으면서 판단하는 것이 일반적으로 사람들이 행하는 방식이다. 즉, 우리는 하나의 modality가 아닌 multi-modality를 활용하게 되는 것이다. 각각의 modality를 unimodal이라 하며, 여러개의 modality를 multi-modal이라고 하는 것이다. 사람들 대부분이 뇌에서 처리되는 정보량들은 일반적으로 눈에서부터 들어오는 것들이다. 그래서 보통 눈을 중심으로 다른 감각 기관이 보조적으로 활용되는 것이다. 이렇게 multi-modal을 활용하면 좋겠지만, 여기에는 몇가지 어려운 부분들이 존재한다.
 우선, 각 data마다 표현하는 방식이 전부 다르다. Audio같은 경우 1D signal로 진동되어 들어오게 되는데, 이는 시간마다 디지털화 되어 저장이 된다. Image의 경우에는 공간적으로 네모난 상자에 2D array 형태로 저장이 된다. 사실 image는 색상도 존재한다고 하면 tensor 형태로 저장이 된다. Text는 단어마다 의미가 있기 때문에 이를 각각 의미있게 표현하기 위해서는 embedding 시켜서 사용해야 한다. 이렇게 각 modality마다 data의 표현법이 다르고, 같은 modality라고 하더라도 그 안에서 표현하는 방식이 다를 수 있다. 그래서 차원과 형태가 다른 modality들을 합치는 과정에서 고려를 많이 해줘야 한다.
우선, 각 data마다 표현하는 방식이 전부 다르다. Audio같은 경우 1D signal로 진동되어 들어오게 되는데, 이는 시간마다 디지털화 되어 저장이 된다. Image의 경우에는 공간적으로 네모난 상자에 2D array 형태로 저장이 된다. 사실 image는 색상도 존재한다고 하면 tensor 형태로 저장이 된다. Text는 단어마다 의미가 있기 때문에 이를 각각 의미있게 표현하기 위해서는 embedding 시켜서 사용해야 한다. 이렇게 각 modality마다 data의 표현법이 다르고, 같은 modality라고 하더라도 그 안에서 표현하는 방식이 다를 수 있다. 그래서 차원과 형태가 다른 modality들을 합치는 과정에서 고려를 많이 해줘야 한다.
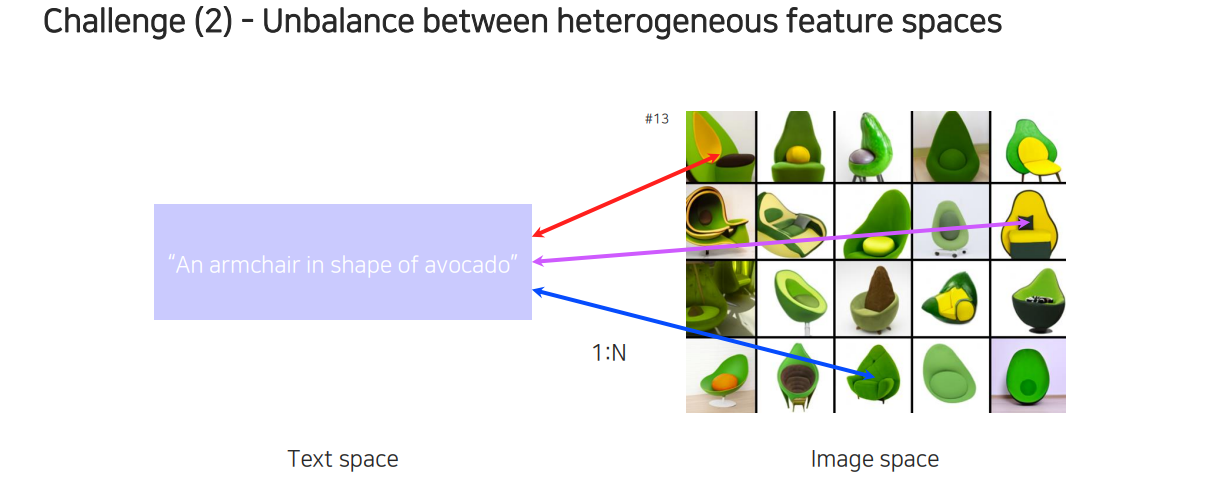 두번째 문제는 이종간 modality의 관계성이 symmetric한 관계가 아니라 unbalance한 관계라는 것이다. 예를 들어 위와 같이 아보카도 모양의 의자가 있다라는 text가 있다고 해보자. 만약 이러한 식으로 검색창에 검색을 했다라고 한다면 해당 text와 관련이 있는 여러 영상들을 찾을 수 있을 것이다. 엄밀히 따져보면 완전히 틀렸다고 할 수 없는 결과들도 다수 존재할 것이다. 이렇게 1:N의 결과를 가지게 되는데, 이러한 1대 다수의 mapping이 처리하기 어려운 경우에 해당하게 된다. 우리가 함수를 배울 때 보통 1:1 mapping을 정의하게 된다. Nerual network로 이러한 function을 mapping하는 과정은 상대적으로 간단하지만, 다수를 mapping하는 과정은 어려운 경우에 해당하게 된다.
두번째 문제는 이종간 modality의 관계성이 symmetric한 관계가 아니라 unbalance한 관계라는 것이다. 예를 들어 위와 같이 아보카도 모양의 의자가 있다라는 text가 있다고 해보자. 만약 이러한 식으로 검색창에 검색을 했다라고 한다면 해당 text와 관련이 있는 여러 영상들을 찾을 수 있을 것이다. 엄밀히 따져보면 완전히 틀렸다고 할 수 없는 결과들도 다수 존재할 것이다. 이렇게 1:N의 결과를 가지게 되는데, 이러한 1대 다수의 mapping이 처리하기 어려운 경우에 해당하게 된다. 우리가 함수를 배울 때 보통 1:1 mapping을 정의하게 된다. Nerual network로 이러한 function을 mapping하는 과정은 상대적으로 간단하지만, 다수를 mapping하는 과정은 어려운 경우에 해당하게 된다.
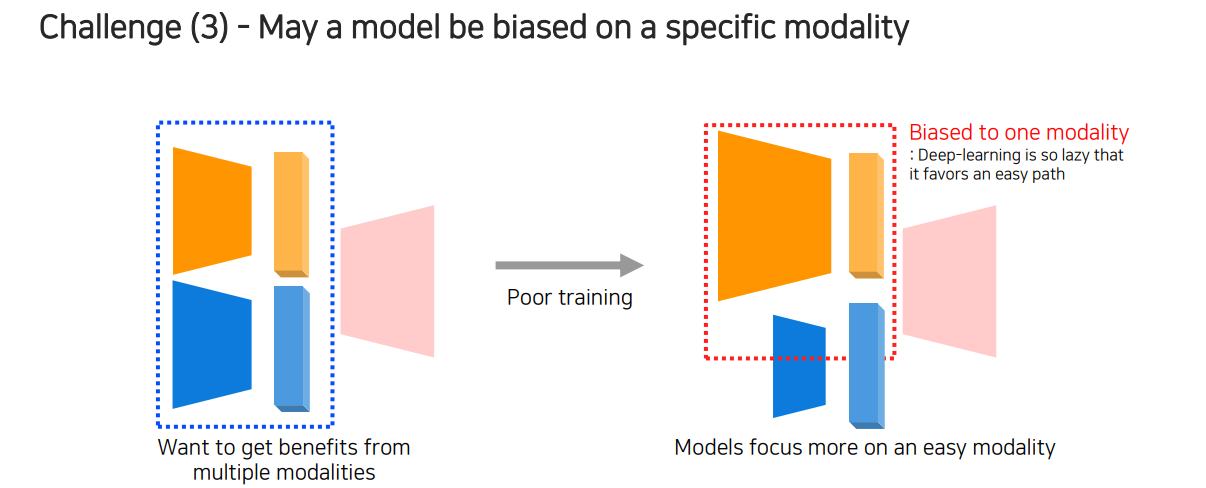 다음으로 어려운 부분은 model 자체가 특정 modality에 bias 되기가 쉽다는 것이다. 우리가 위와 같이 여러 modality를 input으로 받아 하나의 task를 수행한다고 했을 때, 이 정보들을 종합적으로 판단해서 성능을 올리고 싶을 것이다. 하지만 두가지 서로 다른 modality를 활용해서 학습을 진행하게 되면 일반적으로 학습이 잘 진행되지 않는다.
다음으로 어려운 부분은 model 자체가 특정 modality에 bias 되기가 쉽다는 것이다. 우리가 위와 같이 여러 modality를 input으로 받아 하나의 task를 수행한다고 했을 때, 이 정보들을 종합적으로 판단해서 성능을 올리고 싶을 것이다. 하지만 두가지 서로 다른 modality를 활용해서 학습을 진행하게 되면 일반적으로 학습이 잘 진행되지 않는다.
만약 우측과 같이 한쪽에 많은 정보가 포함되어 있어 성능에 지배적인 영향을 끼친다고 한다면 다른 modality의 영향력이 작아 neural network 관점에서 언제 중요한 역할을 하는지 학습하는데 어려움이 존재하게 된다. 이렇게 되면 학습 과정에서 영향력이 큰 modality의 정보만을 이용하고 반대쪽 modality의 정보를 무시하는 결과를 보여주는 modality bias 현상이 발생하게 된다.
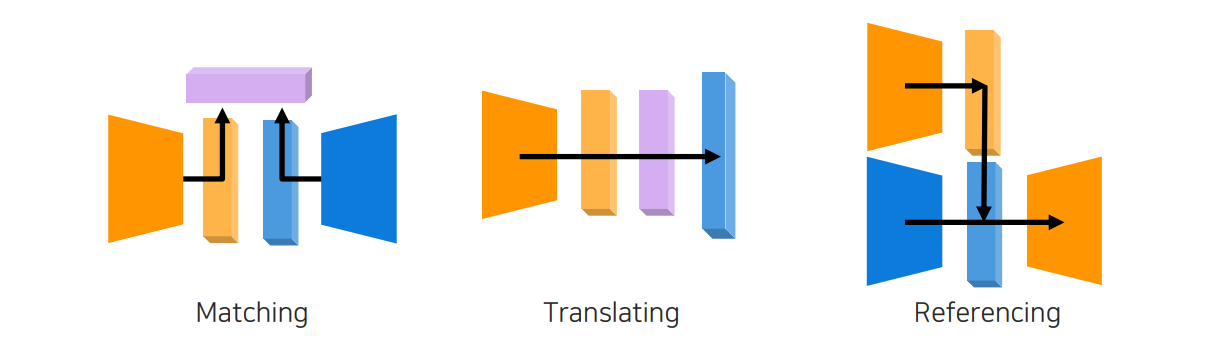 이러한 문제들에도 불구하고 multi-modal learning은 굉장히 중요한 task이며, 많은 application으로 이어질 수 있는 가능성이 있다. 그래서 이번에는 multi-modal learning을 위해서 서로 다른 data가 주어졌을 때 target task를 풀기 위한 방법들과 전략들을 위와 같이 3가지 관점에서 보고자 한다.
이러한 문제들에도 불구하고 multi-modal learning은 굉장히 중요한 task이며, 많은 application으로 이어질 수 있는 가능성이 있다. 그래서 이번에는 multi-modal learning을 위해서 서로 다른 data가 주어졌을 때 target task를 풀기 위한 방법들과 전략들을 위와 같이 3가지 관점에서 보고자 한다.
서로 다른 modality가 들어왔을 때 똑같은 정보를 표현할 수 있도록 matching 시키는 방법, 하나의 modality에서 다른 modality로 translating 시키는 방법, 그리고 target task를 위해서 참조를 통해서 매번 다르게 수행하도록 하는 referencing 방법이 있다. 이렇게 matching, translating, referencing으로 나누긴 했지만, 모든 구조가 이러한 식으로 정해지는 것은 아니다. 단지 크게 3가지로 나눠 활용할 수 있다는 것이다.
