
이번에는 neural network를 학습할 때 주의해야하고 꼭 알아두면 좋은 tip들에 대해서 알아보고자 한다. 특히, training 과정에서 변화시켜야 하는 parameter들에 대해서 집중해서 보고자 한다. 기본적인 learning rate, regularization과 여러 hyperparameter들을 어떻게 최적화 시킬지에 대해서 알아볼 것이다.
Learning rate
 Learning rate는 SGD와 같은 optimizer를 사용할 때 weight를 얼마만큼 한번에 update 할 것인지를 결정하는 중요한 parameter이다. Learning rate도 hyperparameter로 training 과정에서 data에 의해서 따로 학습되는 것이 아니다. 어떠한 learning rate가 가장 좋은지 결정하는 일은 쉽지 않다.
Learning rate는 SGD와 같은 optimizer를 사용할 때 weight를 얼마만큼 한번에 update 할 것인지를 결정하는 중요한 parameter이다. Learning rate도 hyperparameter로 training 과정에서 data에 의해서 따로 학습되는 것이 아니다. 어떠한 learning rate가 가장 좋은지 결정하는 일은 쉽지 않다.
좌측의 그래프는 training을 하면서 loss가 어떻게 변하는지 경향성을 보여주고 있다. 노란선과 같이 learning rate를 너무 높게 잡으면 loss가 폭발하게 될 것이다. 파란선과 같이 learning rate를 너무 낮게 잡으면 반대로 convergence 속도가 느려지게 될 것이다. 초록선과 같이 learning rate를 너무 크지 않고 적당히 크게 설정하면 폭발은 일어나지 않는 대신에 초반에는 학습이 빠를지 몰라도 그 이후부터는 saturation 되어 더이상 성능이 좋아지지 않을 것이다. 그래서 우리는 빨간선과 같이 적당히 좋은 learning rate를 설정하고 scheduling 해줘야 좋은 성능을 기대할 수 있다.
그리고 learning rate를 설정해주고 고정시킨 상태로 진행하는 것이 아니라 시간에 따라서 그 값을 점점 줄여주면서 더 정교하게 볼 수 있도록 유도해줘야 한다. 이러한 과정을 decay라고 부르고, 여기에는 다양한 방법들이 존재한다. 가장 간단한 step decay의 경우에는 일정 epoch마다 learning rate를 일정한 비율로 줄여주게 된다. Exponential decay는 epoch에 따라서 gradual하게 줄여주게 된다.
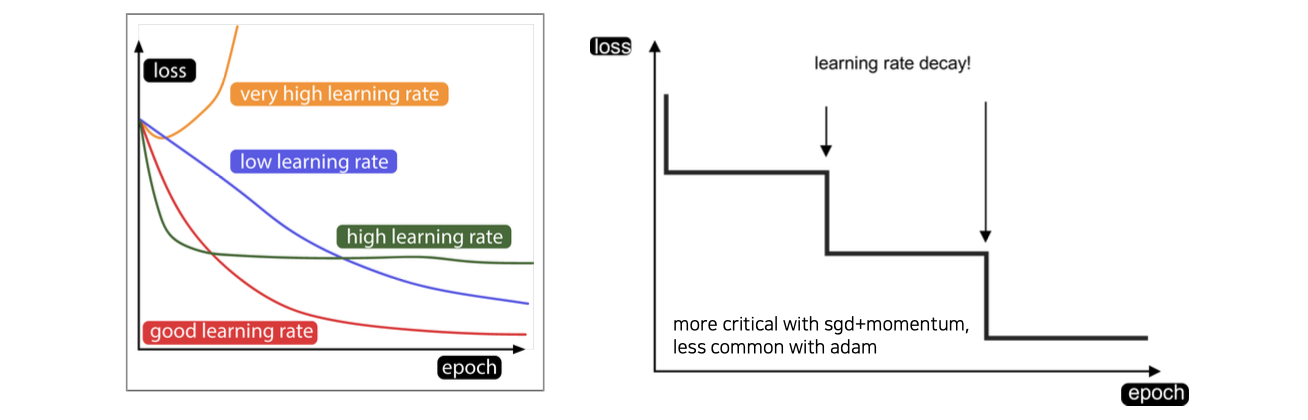 Step decay는 위와 같이 일정 epoch마다 learning rate를 줄여주는 방법이다. 그래서 learning rate decay를 step decay로 사용할 때 장점은 training을 하다가 어느정도 saturation 되었을 때 learning rate를 바꿔줌으로써 학습이 다시 진행이 될 수 있다. 그 결과는 우측과 같이 learning rate를 줄여주는 것이 학습에 변화를 일으켰음을 확인할 수 있다. Learning rate decay는 Adam보다도 SGD나 SGD+Momentum과 같은 것들을 사용할 때 더 중요한 factor가 될 것이다.
Step decay는 위와 같이 일정 epoch마다 learning rate를 줄여주는 방법이다. 그래서 learning rate decay를 step decay로 사용할 때 장점은 training을 하다가 어느정도 saturation 되었을 때 learning rate를 바꿔줌으로써 학습이 다시 진행이 될 수 있다. 그 결과는 우측과 같이 learning rate를 줄여주는 것이 학습에 변화를 일으켰음을 확인할 수 있다. Learning rate decay는 Adam보다도 SGD나 SGD+Momentum과 같은 것들을 사용할 때 더 중요한 factor가 될 것이다.
 일반적으로는 learning rate decay 방법을 Adam으로 사용하면서 robust하게 진행하는 것이 좋은 선택이 된다. SGD+Momentum의 방식을 사용할 때는 learning rate를 잘 tuning 해줘야 한다. 이렇게 직접 tuning을 해주었을 때는 오히려 Adam보다도 더 좋은 성능을 불러낼 수도 있다. 만약 우리가 mini-batch가 아닌 full-batch를 사용할 수 있는 경우에는 L-BFGS와 같은 first-order보다 second-order에 가까운 optimizer를 사용하면 learning rate scheduling에 대한 의존성을 많이 줄일 수가 있다. 또 주의해야 하는 부분으로 이렇게 second-order optimizer를 사용하는 경우에는 noise에 굉장히 취약하다는 것이다. 그래서 noise를 최대한 줄이는 것이 중요하다.
일반적으로는 learning rate decay 방법을 Adam으로 사용하면서 robust하게 진행하는 것이 좋은 선택이 된다. SGD+Momentum의 방식을 사용할 때는 learning rate를 잘 tuning 해줘야 한다. 이렇게 직접 tuning을 해주었을 때는 오히려 Adam보다도 더 좋은 성능을 불러낼 수도 있다. 만약 우리가 mini-batch가 아닌 full-batch를 사용할 수 있는 경우에는 L-BFGS와 같은 first-order보다 second-order에 가까운 optimizer를 사용하면 learning rate scheduling에 대한 의존성을 많이 줄일 수가 있다. 또 주의해야 하는 부분으로 이렇게 second-order optimizer를 사용하는 경우에는 noise에 굉장히 취약하다는 것이다. 그래서 noise를 최대한 줄이는 것이 중요하다.
 그리고 우리가 learning rate를 조정하고 결정해줄 때 어느정도로 맞출지 고민해볼 수 있을 것이다. 특정 epoch를 가늠하는 기준은 delta factor만큼의 norm과 원래 parameter의 norm의 비율이 정도가 되면 적당한 learning rate를 가지고 있다고 이야기할 수 있다. 이것은 어떠한 이론은 아니며 0.01만큼씩 parameter가 update가 된다는 것은 결국 한번의 iteration을 돌아서 gradient descent를 통해서 weight를 update 했을 때 1%씩 update된다는 이야기다. 0.001만큼이라면 0.1%씩 update가 된다는 것이다. 그렇다면 weight를 1%씩 바꿔서 전체적으로 다른 weight를 만든다고 한다면 100번의 iteration을 통해서 weight가 충분히 달라졌을 것이라는 기대를 할 수 있게 된다. 0.001이라면 1000번의 iteration 이후에 완전히 바뀔 것이다.
그리고 우리가 learning rate를 조정하고 결정해줄 때 어느정도로 맞출지 고민해볼 수 있을 것이다. 특정 epoch를 가늠하는 기준은 delta factor만큼의 norm과 원래 parameter의 norm의 비율이 정도가 되면 적당한 learning rate를 가지고 있다고 이야기할 수 있다. 이것은 어떠한 이론은 아니며 0.01만큼씩 parameter가 update가 된다는 것은 결국 한번의 iteration을 돌아서 gradient descent를 통해서 weight를 update 했을 때 1%씩 update된다는 이야기다. 0.001만큼이라면 0.1%씩 update가 된다는 것이다. 그렇다면 weight를 1%씩 바꿔서 전체적으로 다른 weight를 만든다고 한다면 100번의 iteration을 통해서 weight가 충분히 달라졌을 것이라는 기대를 할 수 있게 된다. 0.001이라면 1000번의 iteration 이후에 완전히 바뀔 것이다.
Regularization
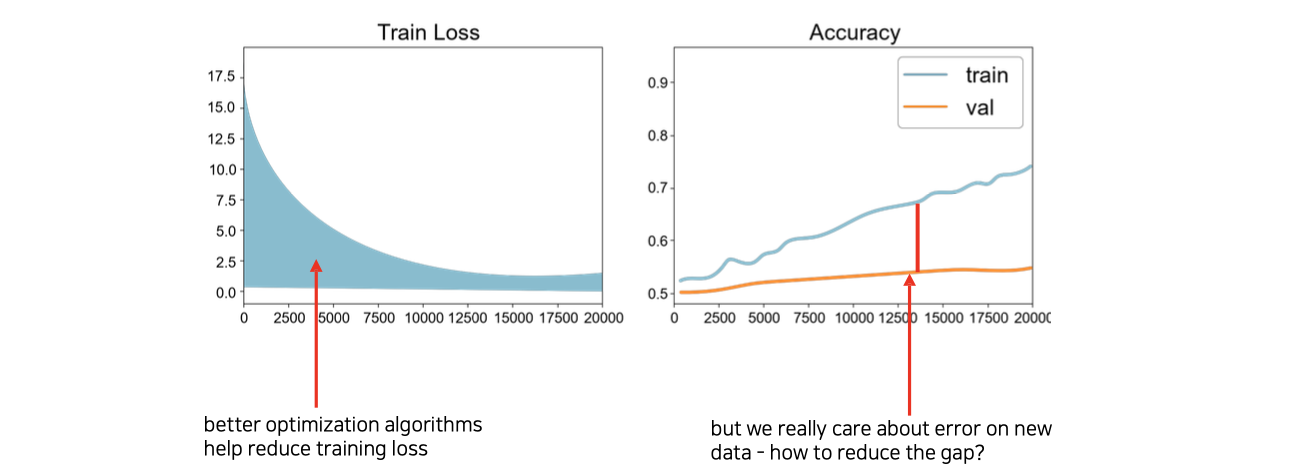 다음으로 학습을 통해서 보정해야 하는 것으로 regularization이 있다. Train loss의 경우에는 적당한 hyperparameter를 설정하고 optimizer를 이용하다보면 좌측과 같이 줄어들 것이다. 그런데 accuracy를 측정했을 때 training과 validation이 차이를 보일 수가 있다. 우측과 같이 차이가 점점 벌어지고 있는데, 이와 같이 training accuracy와 validation accuracy 차이를 generalization gap이라고 한다.
다음으로 학습을 통해서 보정해야 하는 것으로 regularization이 있다. Train loss의 경우에는 적당한 hyperparameter를 설정하고 optimizer를 이용하다보면 좌측과 같이 줄어들 것이다. 그런데 accuracy를 측정했을 때 training과 validation이 차이를 보일 수가 있다. 우측과 같이 차이가 점점 벌어지고 있는데, 이와 같이 training accuracy와 validation accuracy 차이를 generalization gap이라고 한다.
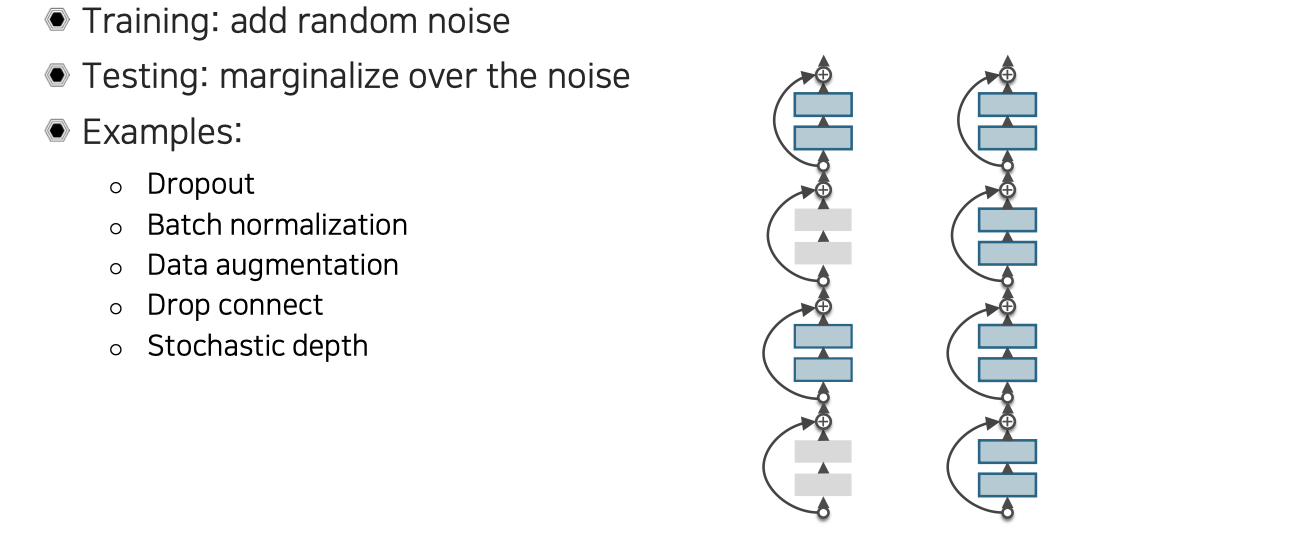 이러한 차이를 줄이는 방법으로 제안된 것이 바로 regularization이다. Regularization은 training을 하면서는 noise factor들을 추가할 수 있을 것이고, 이를 augmentation으로 볼 수도 있을 것이다. 반면 testing에서는 이러한 noise를 marginalization하는 것이 일반적인 패턴이다. 우리는 이러한 regularization을 loss에다가 사용할 수 있는데, neural network에서는 이외에도 다른 기법들이 등장하게 되었다.
이러한 차이를 줄이는 방법으로 제안된 것이 바로 regularization이다. Regularization은 training을 하면서는 noise factor들을 추가할 수 있을 것이고, 이를 augmentation으로 볼 수도 있을 것이다. 반면 testing에서는 이러한 noise를 marginalization하는 것이 일반적인 패턴이다. 우리는 이러한 regularization을 loss에다가 사용할 수 있는데, neural network에서는 이외에도 다른 기법들이 등장하게 되었다.
대표적으로 dropout은 중간중간 activation을 0으로 꺼버리는 것이다. Batch normalization도 regularization과 같은 효과를 낼 수 있다. Data augmentation의 경우 testing에서 marginalization의 의미는 하나의 sample을 test할 때 augmentation을 통해서 여러개의 sample로 늘린 다음에 각각 sample에 대해서 inference를 적용해서 각각의 output을 얻게된다. Augmentation을 했으니 같은 data라도 input이 달라졌을 것이고, 이에따라 output도 조금씩 차이를 보일 것이다. Output의 평균을 구해서 ensemble을 하는 것을 marginalization이라고 한다. Drop connection은 dropout과 다르게 중간중간 weight connection을 끊어버리는 것이다. 즉, 중간에 weight 값을 0으로 만들어버리는 것이다. 이외에도 stochastic depth라고 해서 ResNet처럼 skip connection이 있는 것에다가 중간 weight를 통째로 빼버리는 것이다. 중간에 weight를 제거하더라도 identity mapping이 존재해서 network가 그대로 작동을 한다. 이외에도 굉장히 많은 regularization 기법들이 등장하고 있다.
Babysitting the learning process
Training을 하면서 적절한 learning rate를 설정하고 scheduling을 정하는 것부터 시작해서 regularization을 추가하기도 했는데, 그 이외에 시작부터 어떠한 부분들을 신경을 쓰면서 우리가 학습을 안정화시킬 수 있을지에 대해서 하나씩 알아보고자 한다.
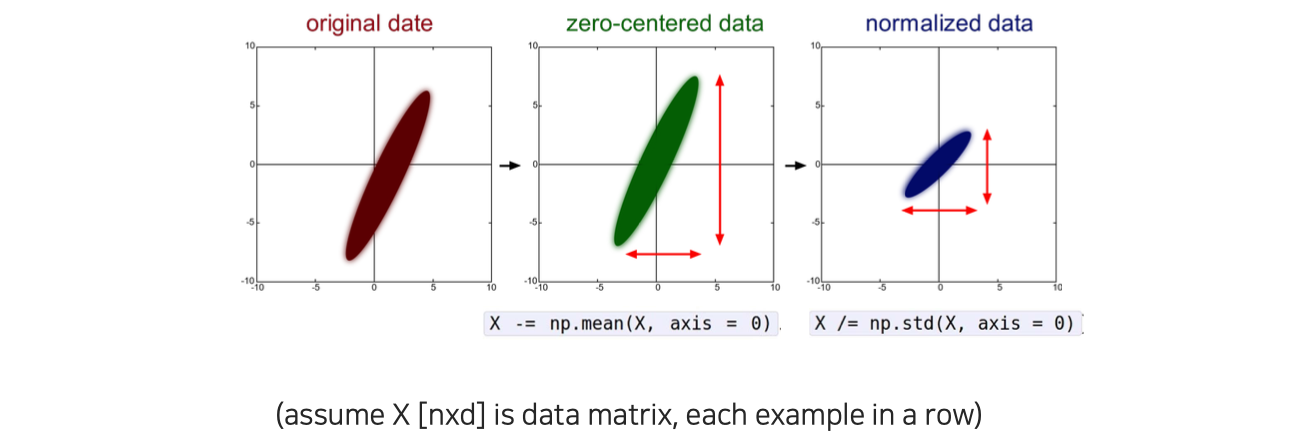 첫번째로는 당연하게 input data가 zero-centered 되어 있도록 preprocessing을 잘해야 한다는 것이다.
첫번째로는 당연하게 input data가 zero-centered 되어 있도록 preprocessing을 잘해야 한다는 것이다.
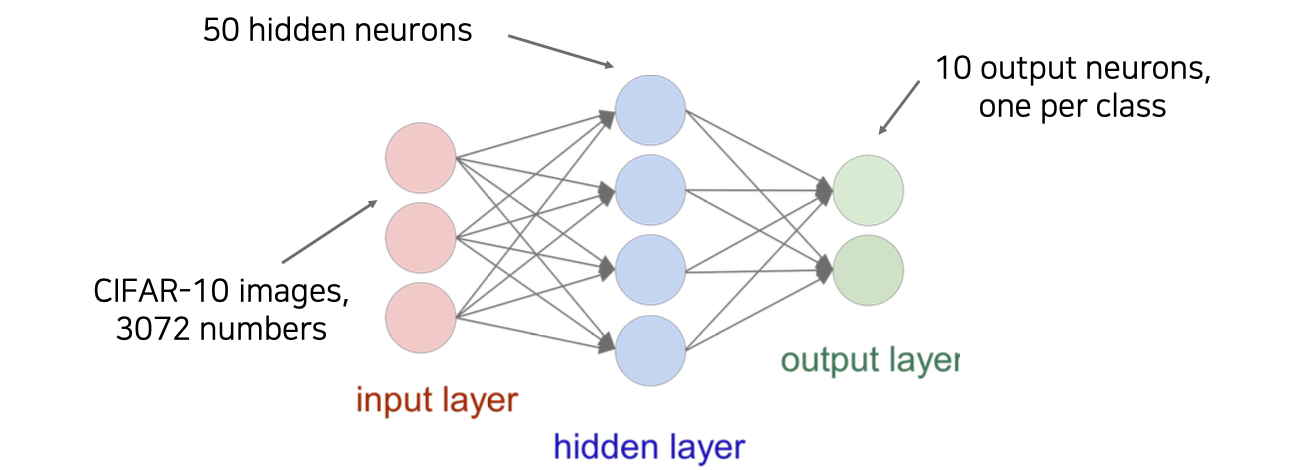 두번째로는 model architecture를 잘 만드는 것이다. One time setup으로 설정한 후에도 학습을 하면서 hyperparameter를 조절하면서 성능을 측정할 수 있을 것이다.
두번째로는 model architecture를 잘 만드는 것이다. One time setup으로 설정한 후에도 학습을 하면서 hyperparameter를 조절하면서 성능을 측정할 수 있을 것이다.
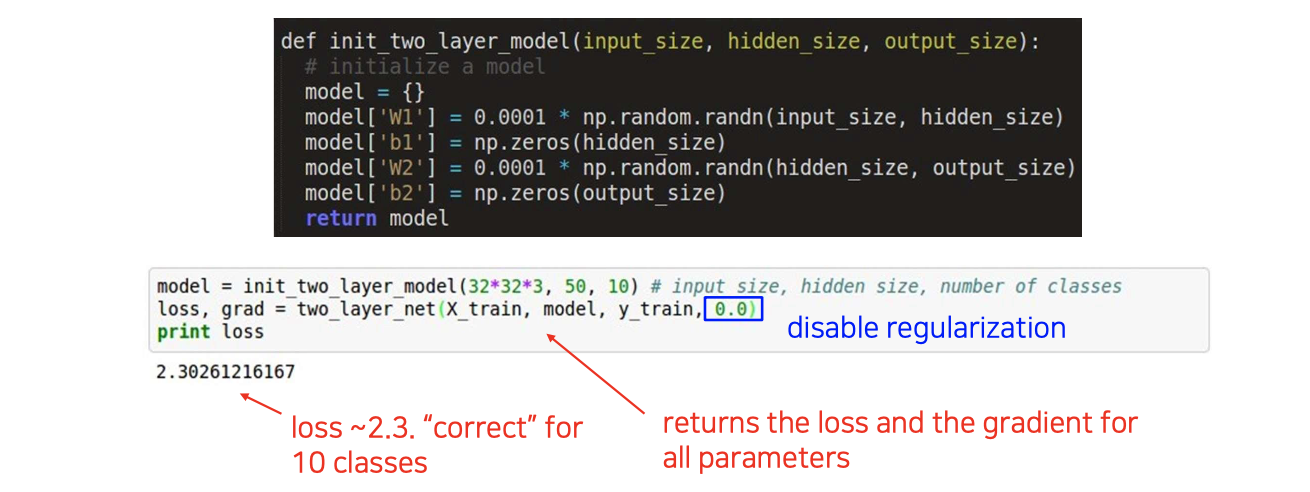 Architecture까지 잘 만들었다면 다음에는 loss를 측정해보는 것이다. 학습을 진행하는 과정이 아니라 우선은 initialization을 한 뒤에 적당한 input을 넣어서 loss를 계산해보는 것이다. 일단은 여기서는 초기에 설정한 것으로만 진행하고 어떠한 regularization도 사용하지 않는다.
Architecture까지 잘 만들었다면 다음에는 loss를 측정해보는 것이다. 학습을 진행하는 과정이 아니라 우선은 initialization을 한 뒤에 적당한 input을 넣어서 loss를 계산해보는 것이다. 일단은 여기서는 초기에 설정한 것으로만 진행하고 어떠한 regularization도 사용하지 않는다.
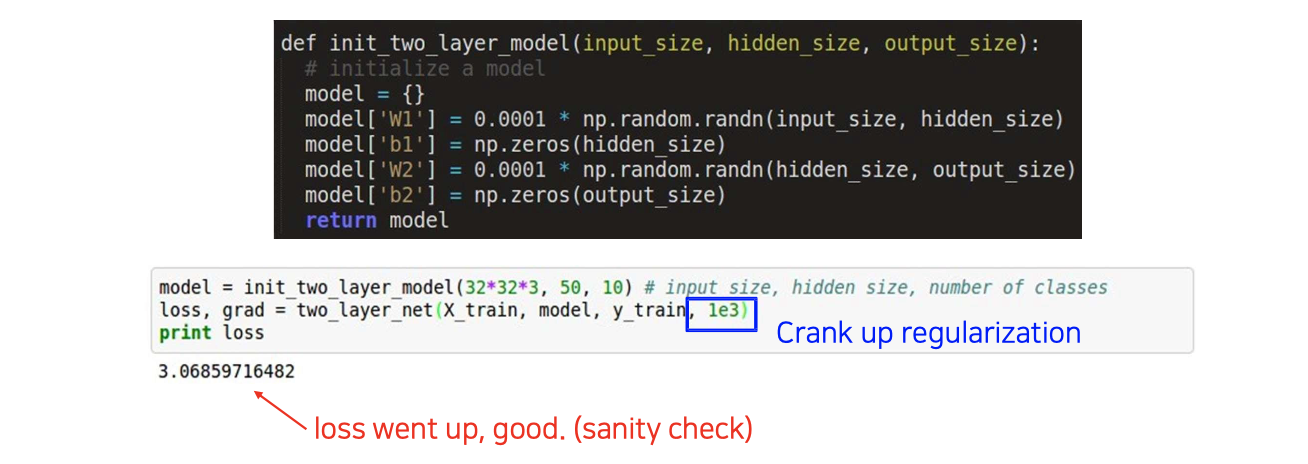 그 다음으로는 regularization을 적용해서 loss가 그거에 맞게끔 올라가는지를 통해서 architecture가 제대로 setup이 되고 initialization이 잘 되어서 loss가 제대로 측정이 되었는지를 확인해본다.
그 다음으로는 regularization을 적용해서 loss가 그거에 맞게끔 올라가는지를 통해서 architecture가 제대로 setup이 되고 initialization이 잘 되어서 loss가 제대로 측정이 되었는지를 확인해본다.
 이제부터는 본격적으로 training을 해주는 것이다. 이때, large scale dataset을 바로 적용하는 것은 엄청난 시간 낭비가 될 수 있다. 예를 들어서, training을 한번 하는데 일주일의 시간이 걸린다고 하면은 만약 처음부터 잘못 setting 되어 있다고 하면 그만큼의 시간을 낭비하게 되는 것이다.
이제부터는 본격적으로 training을 해주는 것이다. 이때, large scale dataset을 바로 적용하는 것은 엄청난 시간 낭비가 될 수 있다. 예를 들어서, training을 한번 하는데 일주일의 시간이 걸린다고 하면은 만약 처음부터 잘못 setting 되어 있다고 하면 그만큼의 시간을 낭비하게 되는 것이다.
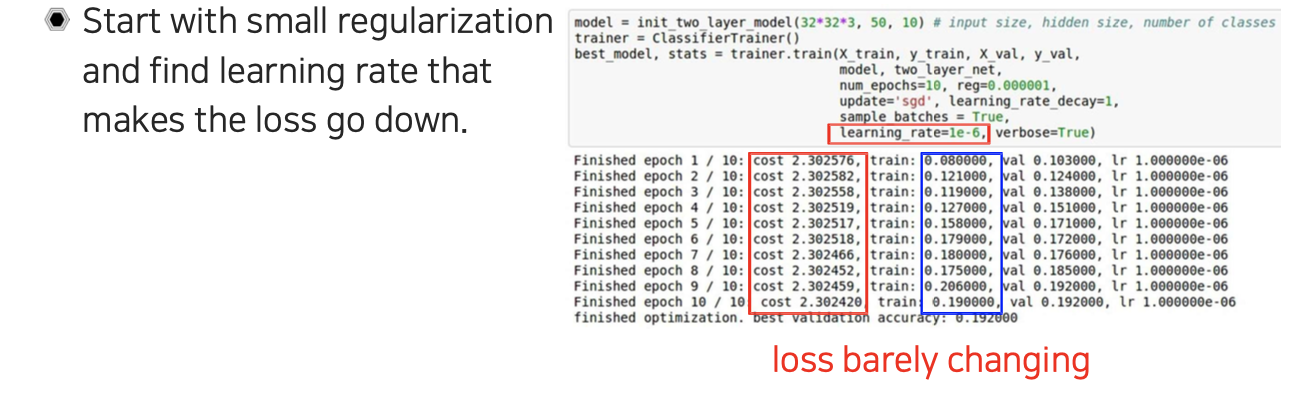
이를 현명하게 하려면 먼저 training data를 굉장히 적은 양만을 가지고 학습을 하는 것이다. 그리고 이를 이용해서 overfitting 문제가 발생하는지 확인하는 것이다. 여기서 underfitting이 되면 문제가 있는 것이다. Overfitting이 일어나서 training error가 0이 되도록 하는 것이 중요하다.
위의 예시는 20개의 data만을 이용하면서 overfitting을 발생시키기 위해서 모든 regularization을 끈 뒤에 기본적인 SGD와 같은 optimizer를 적용해서 학습을 시킨 것이다. 이렇게 했을 때 발생하는 training loss를 보고 어떻게 수정을 해야하는지를 결정할 수 있게 된다. 적당하게 learning rate를 설정해주고 보니 loss는 줄어들고 accuracy가 1로 잘 되는 것을 볼 수 있다. 이러한 경우에는 setting이 잘 되어 있음을 의미해서 다음 단계로 넘어갈 수 있게 된다.
 이렇게 overfitting을 확인한 뒤에는 regularization을 다시 살리는 것이다. 이때, regularization은 작은 것부터 시작해야 한다. 만약 regularization loss가 target loss보다 커지게 되면 핵심이 바뀌는 셈이 된다. Dropout의 경우에도 작은 값에서 큰 값으로 바꿔가면서 점진적으로 설정해줘야 한다. Learning rate를 으로 설정하고 loss를 보니 loss가 거의 바뀌지 않은 것을 확인할 수 있었다.
이렇게 overfitting을 확인한 뒤에는 regularization을 다시 살리는 것이다. 이때, regularization은 작은 것부터 시작해야 한다. 만약 regularization loss가 target loss보다 커지게 되면 핵심이 바뀌는 셈이 된다. Dropout의 경우에도 작은 값에서 큰 값으로 바꿔가면서 점진적으로 설정해줘야 한다. Learning rate를 으로 설정하고 loss를 보니 loss가 거의 바뀌지 않은 것을 확인할 수 있었다.
 Loss의 변화가 없다는 것은 learning rate가 너무 낮다는 것으로 해석할 수 있다. 이러한 경우에는 learning rate를 올려줘서 해결할 수 있다.
Loss의 변화가 없다는 것은 learning rate가 너무 낮다는 것으로 해석할 수 있다. 이러한 경우에는 learning rate를 올려줘서 해결할 수 있다.
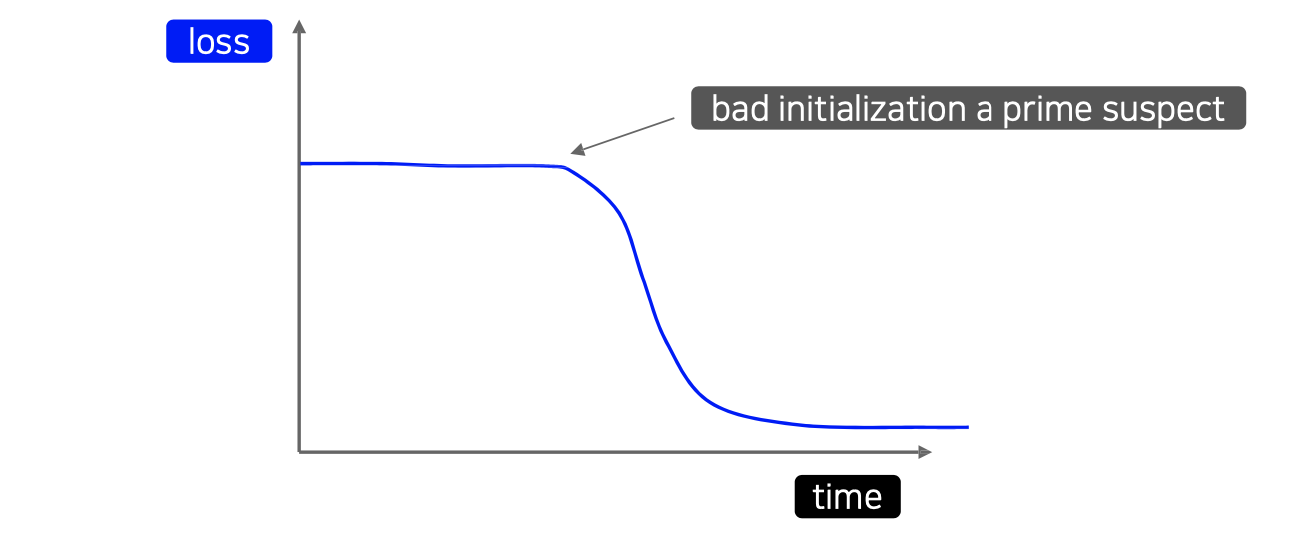 Training loss 그래프에서 시간이 어느정도 지나서 갑자기 줄어드는 현상이 발생했을 때는 initialization의 문제로 볼 수 있다. 그래서 우리는 initialization 문제와 learning rate 문제를 구분할 수 있어야 한다. 적당하게 학습을 진행시켰을 때 loss가 갑자기 줄어드는지, 아니면 그대로 쭉 가는지를 확인해서 어떠한 문제인지를 파악하는 것이 중요하다.
Training loss 그래프에서 시간이 어느정도 지나서 갑자기 줄어드는 현상이 발생했을 때는 initialization의 문제로 볼 수 있다. 그래서 우리는 initialization 문제와 learning rate 문제를 구분할 수 있어야 한다. 적당하게 학습을 진행시켰을 때 loss가 갑자기 줄어드는지, 아니면 그대로 쭉 가는지를 확인해서 어떠한 문제인지를 파악하는 것이 중요하다.
 Loss가 줄어들지 않는 상황에서 accuracy가 20%나 되고 조금씩 올라가는 것이 보인다고 하더라도 우리는 여기에 속으면 안된다. Image classification의 경우에 softmax를 사용하게 된다. 이 이야기는 다른 class와 대비해서 그 값이 조금이라도 높으면 softmax에 의해서 그 결과가 과장이 된다. 그러면 그 결과를 이용해서 accuracy를 측정하기 때문에 상대적인 결과에 따른 성능이지 절대적이라고 이야기하기 힘들다. 그래서 핵심은 loss를 보고 줄어들지 않으면 문제가 있다고 판단해야하는 것이다.
Loss가 줄어들지 않는 상황에서 accuracy가 20%나 되고 조금씩 올라가는 것이 보인다고 하더라도 우리는 여기에 속으면 안된다. Image classification의 경우에 softmax를 사용하게 된다. 이 이야기는 다른 class와 대비해서 그 값이 조금이라도 높으면 softmax에 의해서 그 결과가 과장이 된다. 그러면 그 결과를 이용해서 accuracy를 측정하기 때문에 상대적인 결과에 따른 성능이지 절대적이라고 이야기하기 힘들다. 그래서 핵심은 loss를 보고 줄어들지 않으면 문제가 있다고 판단해야하는 것이다.
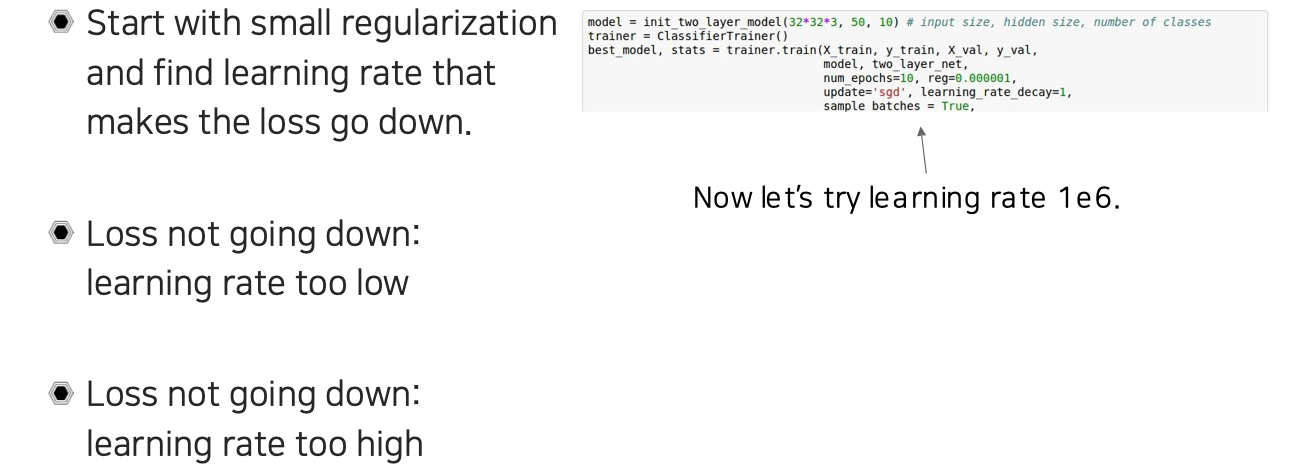 이번에는 learning rate를 으로 바꾸어 학습을 진행하는 상황을 가정해보자.
이번에는 learning rate를 으로 바꾸어 학습을 진행하는 상황을 가정해보자.
 학습을 진행해보니 loss가 바로 NaN(not a number)가 나오는 것을 확인할 수 있었다. 일반적으로 너무 높은 learning rate를 사용하면 NaN이 나오는게 당연하다. 그래서 NaN을 보게 되면 learning rate를 줄여주면 되는 것이다.
학습을 진행해보니 loss가 바로 NaN(not a number)가 나오는 것을 확인할 수 있었다. 일반적으로 너무 높은 learning rate를 사용하면 NaN이 나오는게 당연하다. 그래서 NaN을 보게 되면 learning rate를 줄여주면 되는 것이다.
 Learning rate를 으로 조금 줄여보았더니 loss가 처음에는 줄어드는 것처럼 보이더니 이번에는 inf(infinity)를 보이면서 loss가 폭발하게 되었다. 이러한 경우에도 learning rate가 크기 때문에 그 값을 줄여야겠다고 생각해야 한다. 그래서 적절한 learning rate는 일반적으로는 에서 정도가 된다.
Learning rate를 으로 조금 줄여보았더니 loss가 처음에는 줄어드는 것처럼 보이더니 이번에는 inf(infinity)를 보이면서 loss가 폭발하게 되었다. 이러한 경우에도 learning rate가 크기 때문에 그 값을 줄여야겠다고 생각해야 한다. 그래서 적절한 learning rate는 일반적으로는 에서 정도가 된다.
Hyperparameter optimization
학습을 진행할 때 다양한 hyperparameter들이 존재하게 된다. 굉장히 많은 hyperparameter들을 어떻게 결정해줘야 하는지 판단하기 어려울 것이다. 그래서 이번에는 이 값들을 어떻게 최적화시켜줄 수 있는지 알아보고자 한다.
 Training data만을 이용해서는 hyperparameter가 좋은지 판단하기 어렵기 때문에 cross-validation을 사용해야 한다. 첫번째는 먼저 적당한 epoch을 돌려보는 것이다. 이 과정에서 대략적으로 어떠한 parameter를 사용하면 좋을지 감을 얻는 것이다. 어느정도 감을 잡았으면 두번째로는 training을 길게 돌리면서 더 정교하게 hyperparameter 값들을 찾아가는 것이다. 끝까지 학습을 시키는 것보다는 조금씩 학습을 해보면서 원래 loss보다 약 3배 정도 값이 커지게 되면 이후에 loss가 폭발하게 될 것이라고 판단할 수 있게 된다. 이러한 경우에는 현재 hyperparameter로는 더이상 학습이 불가능하다고 판단하여 hyperparameter를 수정해줘야 한다.
Training data만을 이용해서는 hyperparameter가 좋은지 판단하기 어렵기 때문에 cross-validation을 사용해야 한다. 첫번째는 먼저 적당한 epoch을 돌려보는 것이다. 이 과정에서 대략적으로 어떠한 parameter를 사용하면 좋을지 감을 얻는 것이다. 어느정도 감을 잡았으면 두번째로는 training을 길게 돌리면서 더 정교하게 hyperparameter 값들을 찾아가는 것이다. 끝까지 학습을 시키는 것보다는 조금씩 학습을 해보면서 원래 loss보다 약 3배 정도 값이 커지게 되면 이후에 loss가 폭발하게 될 것이라고 판단할 수 있게 된다. 이러한 경우에는 현재 hyperparameter로는 더이상 학습이 불가능하다고 판단하여 hyperparameter를 수정해줘야 한다.
Random search vs. Grid search
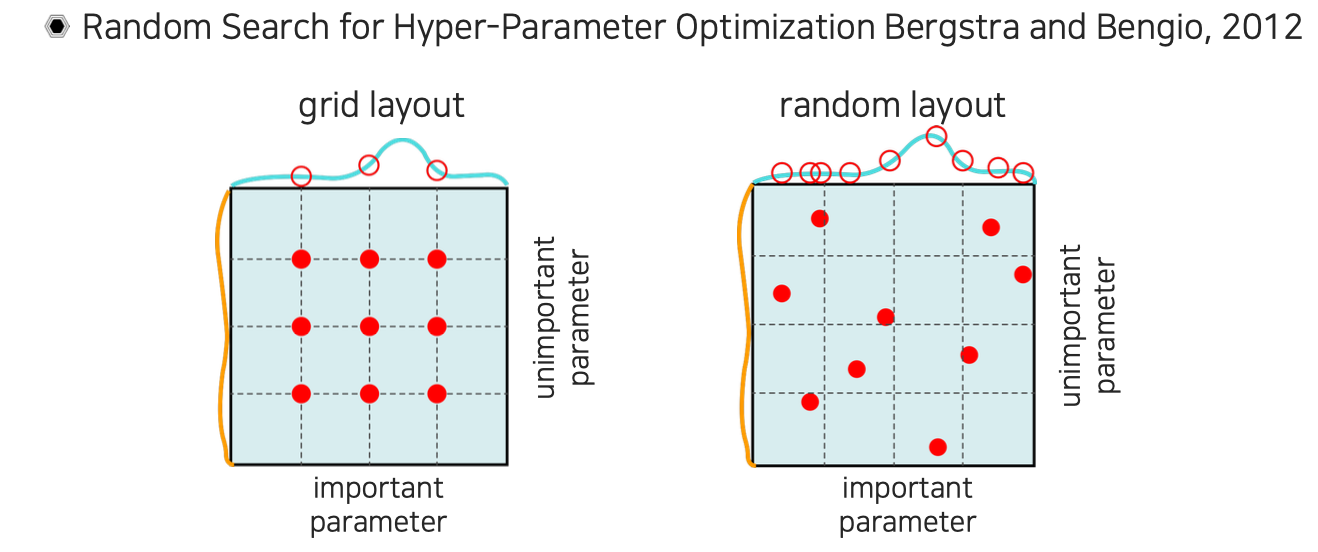 적당한 범위의 hyperparameter를 설정해서 학습을 돌려보고 최종 accuracy가 어떻게 되는지를 보는 과정을 반복하면서 더 좋은 hyperparameter를 찾아가는 과정이 된다. 이때, hyperparameter space에서 적당하게 균일한 sampling을 통해서 hyperparameter를 제시하고 성능을 평가해서 좋은 hyperparameter를 결정할 수 있을 것이다. 하지만 hyperparameter를 추천할 때 좌측과 같이 grid search를 하게되면 넓은 영역에 해당하는 결과들을 볼 수는 있지만, 정작 중요한 부분을 놓칠 가능성이 크다는 문제점이 있다. 그래서 만약 우측과 같이 random하게 설정해서 운에 맡기게 되면 중요한 hyperparameter를 가져올 수 있을 가능성이 존재하게 된다. 이러한 관점에서 random search가 좀 더 효과적인 방법이 될 수도 있다. 계획적으로 맡기는 것도 좋지만 가끔씩은 운에 맡기는 것이 더 좋은 방안이 될 수 있다.
적당한 범위의 hyperparameter를 설정해서 학습을 돌려보고 최종 accuracy가 어떻게 되는지를 보는 과정을 반복하면서 더 좋은 hyperparameter를 찾아가는 과정이 된다. 이때, hyperparameter space에서 적당하게 균일한 sampling을 통해서 hyperparameter를 제시하고 성능을 평가해서 좋은 hyperparameter를 결정할 수 있을 것이다. 하지만 hyperparameter를 추천할 때 좌측과 같이 grid search를 하게되면 넓은 영역에 해당하는 결과들을 볼 수는 있지만, 정작 중요한 부분을 놓칠 가능성이 크다는 문제점이 있다. 그래서 만약 우측과 같이 random하게 설정해서 운에 맡기게 되면 중요한 hyperparameter를 가져올 수 있을 가능성이 존재하게 된다. 이러한 관점에서 random search가 좀 더 효과적인 방법이 될 수도 있다. 계획적으로 맡기는 것도 좋지만 가끔씩은 운에 맡기는 것이 더 좋은 방안이 될 수 있다.
 그리고 hyperparameter를 이용해서 최적화를 할 때 random하게 고려해야 하는 것으로는 network architecture의 hyperparameter들부터해서 learning rate, decay schedule, update type(optimizer), regularization 기법 등도 전부 hyperparameter가 될 수 있다. 여러가지 평가 기준에 따라서 hyperparameter를 바꿔가면서 최적화해줘야 하는 것이다.
그리고 hyperparameter를 이용해서 최적화를 할 때 random하게 고려해야 하는 것으로는 network architecture의 hyperparameter들부터해서 learning rate, decay schedule, update type(optimizer), regularization 기법 등도 전부 hyperparameter가 될 수 있다. 여러가지 평가 기준에 따라서 hyperparameter를 바꿔가면서 최적화해줘야 하는 것이다.
 이렇게 hyperparameter를 수정한다고 하더라도 batch size 등 해결해야 하는 문제들이 많아 아직까지도 여러 연구들이 진행되고 있다. 여전히 hyperparameter의 경향성들이 이해되지 않아서 쉽게 추정이 되지 않는 부분도 존재한다. 그렇기 때문에 random search를 해야하는 부분도 존재하는 것이다.
이렇게 hyperparameter를 수정한다고 하더라도 batch size 등 해결해야 하는 문제들이 많아 아직까지도 여러 연구들이 진행되고 있다. 여전히 hyperparameter의 경향성들이 이해되지 않아서 쉽게 추정이 되지 않는 부분도 존재한다. 그렇기 때문에 random search를 해야하는 부분도 존재하는 것이다.
 지금까지 여러가지 training tip을 알아보았는데, 일반적으로 많이 사용하는 것들이 위에 정리되어있다.
지금까지 여러가지 training tip을 알아보았는데, 일반적으로 많이 사용하는 것들이 위에 정리되어있다.
