Introduction
AI music generation challenge를 마무리한지가 한달이 넘었지만 마지막으로 갈 수록 실력이 부족한 나는 무언가를 주도적으로 하기보단 교수님의 어깨에 얹혀서 따라갈 수 밖에 없었다. 이후에 작업의 내용과 코드를 공부를 하기위해 노력했지만 이 내용들을 이해한다는 것도 벅차 정리를 차일피일 미루기만 하고 있었다. 실력이 부족하면 채워나가면 되는 법!이기에 간단하게라도 정리를 해보려던 찰나 나에게는 title 생성이라는 과업이 (연말 제출) 남았기에 모델을 다시금 살펴보고 정리를 해볼 수 있는 시간을 가질 수 있었다. 내가 저번까지 정리한 내용은 multi embedding이었고 당시에 정보는 pitch, duration에 key, meter, length, rhythm을 더한 6가지 였지만 최종 마무리를 한 시점의 모델에서는 embedding 해야할 정보들이 무려 20개가 되었다. 이 개수만 보아도 교수님이 제대로된 노트의 생성을 위해 얼마나 많은 대상들을 다루고 계셨던 건지 놀랍기만 하다. 오늘 내가 정리를 할 내용은 과제 제출에 최종적으로 사용이 된 MeasureNote 모델의 forwad 단을 살펴보며 input의 shape의 변화를 따라가며 layer들이 어떤 역할을 하는지를 간략하게 짚어보려고 한다.
Obstacles & Walkthrough
Dataset
# MeasureNoteModel과 MeasureNumberSet을 사용하는 경우를 분석하려고 한다.
# MeasureNumberSet은 get_item의 경우에 3가지 종류의 아웃풋을 내보낸다.
# melody, shifted_melody, measure_numbers의 아웃풋 중에서
# melody와 measure_numbers만을 모델의 인풋으로 넣어주면 된다.
# shifted_melody는 melody를 한 칸씩 shift한 것으로 모델의 pred와 비교해 loss를 구할때 사용한다.# trainer.py에서 batch를 받아서 3등분을 해준다.
# melody, shifted_melody, measure_numbers = batch
# collate_fn을 거쳐 각각은 packed sequence로 만들어진다.
# 따라서 인풋은 token_size x input_size의 텐서로 변환된다.
# MeasureNumberSet 데이터셋의 경우에는 input_size가 20이다.
# 그 종류는 아래와 같다.
['main', 'dur', 'pitch_class', 'octave', 'm_idx', 'm_idx_mod4', 'm_offset', 'is_onbeat', 'is_middle_beat',
'key', 'meter', 'unit_length', 'rhythm', 'root', 'mode', 'key_sig', 'numer', 'denom','is_compound', 'is_triple']forward
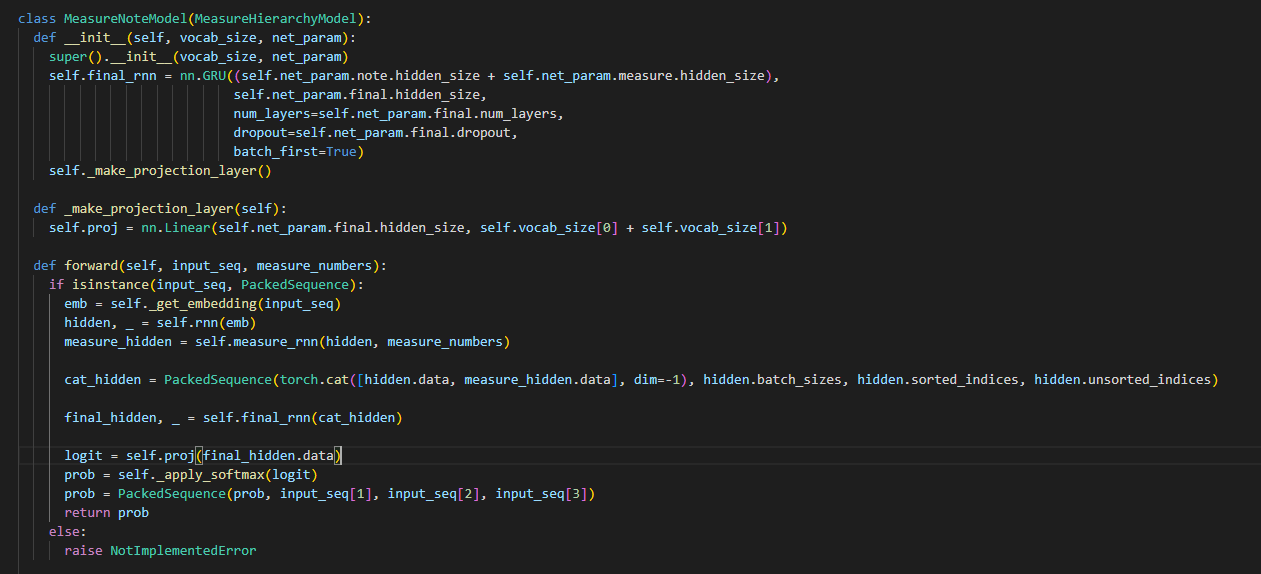
모델의 forward의 순서는 input_seq -> embedding layer -> rnn layer -> measure_rnn -> final_rnn -> projection(linear) layer로 이루어져 있다.
def forward(self, input_seq, measure_numbers):
if isinstance(input_seq, PackedSequence):
emb = self._get_embedding(input_seq)
hidden, _ = self.rnn(emb)
measure_hidden = self.measure_rnn(hidden, measure_numbers)
cat_hidden = PackedSequence(torch.cat([hidden.data, measure_hidden.data], dim=-1), hidden.batch_sizes, hidden.sorted_indices, hidden.unsorted_indices)
final_hidden, _ = self.final_rnn(cat_hidden)
logit = self.proj(final_hidden.data)
prob = self._apply_softmax(logit)
prob = PackedSequence(prob, input_seq[1], input_seq[2], input_seq[3])
return prob
else:
raise NotImplementedErrorembedding
vs code에서 debug모드를 사용해서 shape을 추적했기 때문에 코드가 조금 특이하게 보일 수 있다. embedding은 아래와 같이 20개의 정보 각각을 embedding 하고 이를 concate하기에 무려 2624차원의 벡터를 가지게 된다.
MultiEmbedding(
(layers): ModuleList(
(0): Embedding(87, 384)
(1): Embedding(12, 384)
(2): Embedding(15, 64)
(3): Embedding(15, 64)
(4): Embedding(52, 256)
(5): Embedding(7, 128)
(6): Embedding(26, 256)
(7): Embedding(5, 64)
(8): Embedding(5, 64)
(9): Embedding(48, 128)
(10): Embedding(7, 128)
(11): Embedding(1, 128)
(12): Embedding(11, 128)
(13): Embedding(12, 64)
(14): Embedding(4, 64)
(15): Embedding(17, 64)
(16): Embedding(6, 64)
(17): Embedding(3, 64)
(18): Embedding(2, 64)
(19): Embedding(2, 64)
)
)# model.emb에 들어가는 것은 3가지 input 중에서 melody이다.
data_sample = next(iter(train_loader))
emb = model._get_embedding(data_sample[0])
data_sample[0].data.shape # torch.Size([4820, 20])
emb.data.shape # torch.Size([4820, 2624])rnn
rnn은 GRU를 사용하였으며 크게 특이한점은 없다.
self.rnn = nn.GRU(net_param.emb.total_size,
net_param.note.hidden_size,
num_layers=net_param.note.num_layers,
dropout=net_param.note.dropout,
batch_first=True)# rnn에서 헷갈리기 쉬운 것은 hidden과 last_hidden이다.
# hidden은 token(sum of timestep of input sequence in every batch) x embedding_size(2624)를
# token x hidden_size(512)로 변환해준다.
# last_hidden은 마지막 token이 가질 모든 정보를 담고 있다.
# num_layers(3) x num_directions(1) x batch_size(32) x hidden_size(512)
hidden, last_hidden = model.rnn(emb)
hidden.data.shape # torch.Size([4820, 512])
last_hidden.data.shape # torch.Size([3, 32, 512])measure_rnn
rnn과 attention을 사용한다. measure 정보를 학습하기 위해 따로 만들어졌다. 하지만 이를 제대로 이해하지는 못했다. 궁금하시다면 irish-maler의 module.py에서 MesureGRU를 찾아보시길...
# input 중에서 3번째 값인 measure_numbers를 함께 넣어준다.
measure_hidden = model.measure_rnn(hidden, data_sample[2])
measure_hidden.data.shape # torch.Size([4820, 512])final_rnn
노트의 정보와 measure의 정보를 한번 더 rnn으로 학습시키기 위한 layer이다.
self.final_rnn = nn.GRU((self.net_param.note.hidden_size + self.net_param.measure.hidden_size),
self.net_param.final.hidden_size,
num_layers=self.net_param.final.num_layers,
dropout=self.net_param.final.dropout,
batch_first=True)# cat_hidden은 hidden과 measure_hidden의 data 부분을 concat한 것이다.
# 이로써 각 토큰은 1024차원의 latent vector를 갖게 된다.
# 이 latent vector를 final_rnn에 넣어준다.
cat_hidden = PackedSequence(torch.cat([hidden.data, measure_hidden.data], dim=-1), hidden.batch_sizes, hidden.sorted_indices, hidden.unsorted_indices)
final_hidden, last_final_hidden = model.final_rnn(cat_hidden)
final_hidden.data.shape # torch.Size([4820, 512])
last_final_hidden.data.shape # torch.Size([3, 32, 512])이후는 language model이 그렇듯 projection layer에서 logit을 만들어내고 이를 softmax를 취해서 probablity를 구하며 forward단은 마무리가 된다. 사실 모델의 inference 단이 코드에서 정말 어렵고 설명이 필요한 부분이지만 이 내용은 차차 정리하는 걸로 하기로 했다.
우선 나는 title generation을 위해서 충분히 학습이 된 모델의 파라미터를 가져와서 final_hidden에 추가적으로 학습을 위한 rnn을 쌓아 각 tune에 대한 요약 정보를 담은 벡터를 만들어야 한다. 열심히 작업 해야할 것 같다. 작업이 어느정도 진전이 되면 이 내용도 정리를 해야겠다. 파이팅파이팅...!!
