Introduction
타이틀과 심볼릭 노트의 연관성을 통해 represention을 얻는 것을 목표로 하고 있다. 이 representation이 의미있게 만들어진다면 이걸 이용해서 downstream task에 title을 만드는 작업도 가능할 것이다.
Obstacles & Walkthrough
간단히 생각해보아도 노트 정보에서 타이틀을 연결 짓는다는게 쉬운 일이 아니라는 것은 쉽게 알 수 있다. 음원과 같이 템포나, 악기의 음색 정보를 배제한 채로 노트의 관계만으로 타이틀과의 연결 관계를 찾는 것은 사람에게도 쉬운 태스크가 아닐 것이다. 그래서인지 RNN을 활용한 모델에서는 끝끝내 좋은 결과를 얻을 수가 없었다. 정확히는 이 문제를 해결할 방법을 찾지를 못했다.
RNN Embedding model
모델은 전이학습을 사용했다. 이 과제의 데이터셋은 irish folk 음악의 심볼릭 토큰 데이터를 기반으로 하고 있다. 각각의 튠은 다음과 같이 생겼으며 음원 토큰들은 전처리가 된 데이터로 정다샘 교수님께서 작업을 해주셨다.
X: 1
T: 'G Iomain Nan Gamhna
S: https://thesession.org/tunes/11931#setting11931
Z: G Major
R: slip jig
M: 9/8
L: 1/8
K: C Major
=G=E=E=E2=D=E=D=C|=G=E=E=E=F=G=A=B=c|=G=E=E=E2=D=E=D=C|=A=D=D=G=E=C=D2=A|=G=E=E=E2=D=E=D=C|=G=E=E=E=F=G=A=B=c|=G=E=E=E2=D=E=D=C|=A=D=D=G=E=C=D2=D|=E=D=E=c2=A=B=A=G|=E=D=E=A/2=B/2=c=A=B2=D|=E=D=E=c2=A=B=A=G|=A=D=D=D=E=G=A2=D|=E=D=E=c2=A=B=A=G|=E=D=E=A/2=B/2=c=A=B2=B|=G=A=B=c=B=A=B=A=G|=A=D=D=D=E=G=A=B=c|이 데이터셋을 사용하게 된 데에는 이전의 시리즈에서 짐작할 수 있듯이 AI Music Generation challenge를 참여하기 위한 것이었으며 여기에서 첫번째 태스크로 symbolic music generation을 rnn + attention 모델로 마무리를 할 수 있었다. 나는 이 모델의 주요 파라미터를 note를 embeding하는 목적의 모델에 전이를 해서 사용을 했다. 내가 추가해준 emb_rnn의 경우에는 bi directional 하게 인풋을 봄으로써 input sequence의 마지막이 인풋으로 들어간 emb_rnn의 두번째 output(last_emb_hidden)은 num_layers * bi-direction(2), batch_size, hidden_size의 shape을 가지고 있기에 이를 활용한다면 각각의 batch들의 요약된 embedding을 구할 수 있을 거라고 보았다. 물론 이는 교수님의 조언이었다.
class ABC_measnote_emb_Model(nn.Module):
def __init__(self, trans_emb=None, trans_rnn=None, trans_measure_rnn=None, trans_final_rnn=None, emb_size=256):
super().__init__()
self.emb_size = emb_size
self.emb = trans_emb
self.rnn = trans_rnn
self.measure_rnn = trans_measure_rnn
self.final_rnn = trans_final_rnn
self.emb_rnn = nn.GRU(input_size=512, hidden_size=128, num_layers=2, dropout=0.3, batch_first=True, bidirectional=True)
self.hidden_size = self.emb_rnn.hidden_size * 2 * self.emb_rnn.num_layers
self.proj = nn.Linear(self.hidden_size, self.emb_size)
def _get_embedding(self, input_seq):
if isinstance(input_seq, PackedSequence):
emb = PackedSequence(self.emb(input_seq[0]), input_seq[1], input_seq[2], input_seq[3])
return emb
else:
pass
def forward(self, input_seq, measure_numbers):
if isinstance(input_seq, PackedSequence):
emb = self._get_embedding(input_seq)
hidden, _ = self.rnn(emb)
measure_hidden = self.measure_rnn(hidden, measure_numbers)
cat_hidden = PackedSequence(torch.cat([hidden.data, measure_hidden.data], dim=-1), hidden.batch_sizes, hidden.sorted_indices, hidden.unsorted_indices)
final_hidden, _ = self.final_rnn(cat_hidden)
emb_hidden, last_emb_hidden = self.emb_rnn(final_hidden)
# last_emb_hidden.data.shape # torch.Size([4, batch_size, hidden_size])
extr = last_emb_hidden.data.transpose(0,1) # torch.Size([batch_size, 4, hidden_size])
extr_batch = extr.reshape(len(input_seq.sorted_indices),-1) # torch.Size([batch_size, 4 * hidden_size])
batch_emb = self.proj(extr_batch) # torch.Size([batch_size, self.emb_size])
# batch_emb = batch_emb[emb_hidden.unsorted_indices] # for title matching, we need to sort the batch_emb
return batch_emb
else:
raise NotImplementedErrorloss & metric
batch contrastive loss
두 개의 임베딩이 들어왔을 때 hinge loss를 만들기 위해 교수님이 작성해주신(?) loss function이다. 기본적인 골자는 consine similarity를 활용해서 positive sim을 음의 값으로 두어 최대한 작아지게 하고, negative sim을 양의 값으로 두어 이 또한 줄어들게 하는 방향으로 loss fucntion을 구성하는 것이다.
def get_batch_contrastive_loss(emb1, emb2, margin=0.4):
num_batch = len(emb1)
dot_product_value = torch.matmul(emb1, emb2.T)
emb1_norm = norm(emb1, dim=-1)
emb2_norm = norm(emb2, dim=-1)
cos_sim_value = dot_product_value / emb1_norm.unsqueeze(1) / emb2_norm.unsqueeze(0)
positive_sim = cos_sim_value.diag().unsqueeze(1) # N x 1
non_diag_index = [x for x in range(num_batch) for y in range(num_batch) if x!=y], [y for x in range(len(cos_sim_value)) for y in range(len(cos_sim_value)) if x!=y]
# tuple of two lists, each list has len = N*(N-1)
# batch_size * (batch_size-1)
negative_sim = cos_sim_value[non_diag_index].reshape(num_batch, num_batch-1)
loss = torch.clamp(margin - (positive_sim - negative_sim), min=0)
return loss.mean()mean reciporal rank accuracy
ranking-based task를 위해서 accuracy를 mrr의 방식으로 계산하였다. 이전의 방식은 전체 tune과 title embedding 간의 유사도를 계산하여 top 20개를 추려내 이중에서 답이 있는지 없는 지를 계산하는 방식으로 accuracy를 계산했다. 하지만 이 방식으로는 모델이 좀더 답을 정확히 맞추고 있는지를 확인할 방법이 없기도 하고, 또 accuracy 값이 크게 변화가 없을 수도 있었기 때문에 mrr의 방식을 도입을 하게 되었다. 이 방식은 모델의 예측이 top 20에서 상위권에 있을 수록 더 높은 가중치를 두는 방법이다.
def validate(self, external_loader=None, topk=20):
if external_loader and isinstance(external_loader, DataLoader):
loader = external_loader
print('An arbitrary loader is used instead of Validation loader')
else:
loader = self.valid_loader
self.abc_model.eval()
self.ttl_model.eval()
validation_loss = 0
validation_acc = 0
num_total_tokens = 0
total_sentence = 0
#correct_emb = 0
sum_mrr = 0
abc_emb_all = torch.zeros(len(loader.dataset), self.abc_model.emb_size) # valid dataset size(10% of all) x embedding size
ttl_emb_all = torch.zeros(len(loader.dataset), self.abc_model.emb_size)
with torch.inference_mode():
for idx, batch in enumerate(tqdm(loader, leave=False)):
melody, title, measure_numbers = batch
emb1 = self.abc_model(melody.to(self.device), measure_numbers.to(self.device))
emb2 = self.ttl_model(title.to(self.device))
start_idx = idx * loader.batch_size
end_idx = start_idx + len(title)
abc_emb_all[start_idx:end_idx] = emb1
ttl_emb_all[start_idx:end_idx] = emb2
if len(melody[3]) == 1: # got 1 batch
continue
if self.loss_fn == CosineEmbeddingLoss():
loss = self.loss_fn(emb1, emb2, torch.ones(emb1.size(0)).to(self.device))
else:
loss = get_batch_contrastive_loss(emb1, emb2)
#loss = get_batch_contrastive_loss(emb1, emb2)
num_tokens = melody.data.shape[0] # number of tokens ex) torch.Size([5374, 20])
validation_loss += loss.item() * num_tokens
#print(validation_loss)
num_total_tokens += num_tokens
'''
# for comparing MRR loss between randomly initialized model and trained model
abc_emb_all = torch.rand(len(self.valid_loader.dataset), 128) # valid dataset size(10% of all) x embedding size 128
ttl_emb_all = torch.rand(len(self.valid_loader.dataset), 128)
'''
# calculate MRR
mrrdict = {i-1:1/i for i in range(1, topk+1)} # {0:1.0, 1:0.5, ...}
cos_sim = cosine_similarity(abc_emb_all.detach().cpu().numpy(), ttl_emb_all.detach().cpu().numpy())
# tokens x emb(128) mat emb(128) x tokens = tokens x tokens of cosine similarity
sorted_cos_idx = np.argsort(cos_sim, axis=-1)
for idx in range(len(loader.dataset)):
if idx in sorted_cos_idx[idx][-topk:]: # pick best 20 scores
position = np.argwhere(sorted_cos_idx[idx][-topk:][::-1] == idx).item() # changing into ascending order
quality_score = mrrdict[position]
sum_mrr += quality_score
return validation_loss / num_total_tokens, sum_mrr / len(loader.dataset)Experiment with RNN
Dropout
실험에서 가장 먼저 진행한 것은 randomly initialized model과 학습된 모델을 비교하는 것이었는데 이 둘의 차이가 아주 미미했다. 그래서 다양한 실험을 진행했는데 drop out layer를 추가하면 확실히 과적합을 늦출 수 있는 것을 확인할 수 있었다.
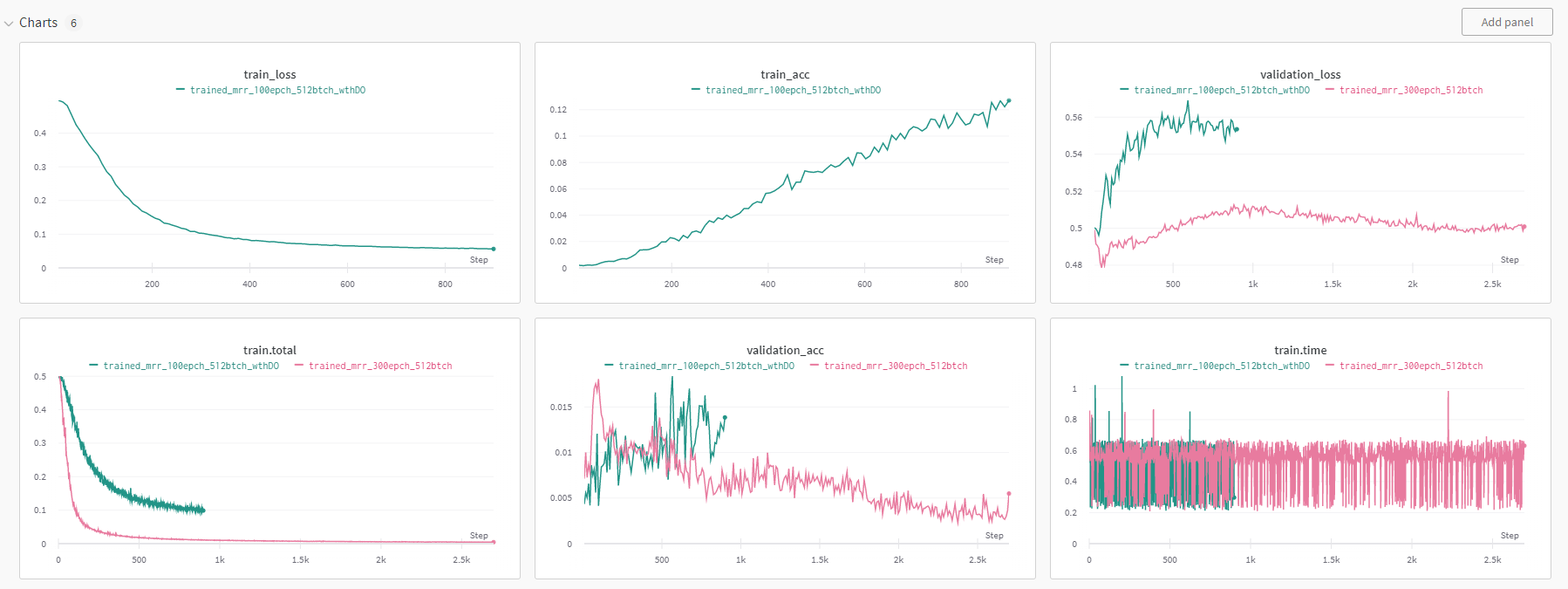
output emb size
학습이 잘 진행이 되질 않아서 emb size를 달리해보았다. 이렇게 하면 tune이나 title을 담는 그릇의 크기가 달라지니까 상황을 좀더 살펴볼 수 있는 듯 하다. 교수님의 조언을 따른 거라 나는 정확히 무얼 확인하기 위한 건지를 인지하지는 못했다.
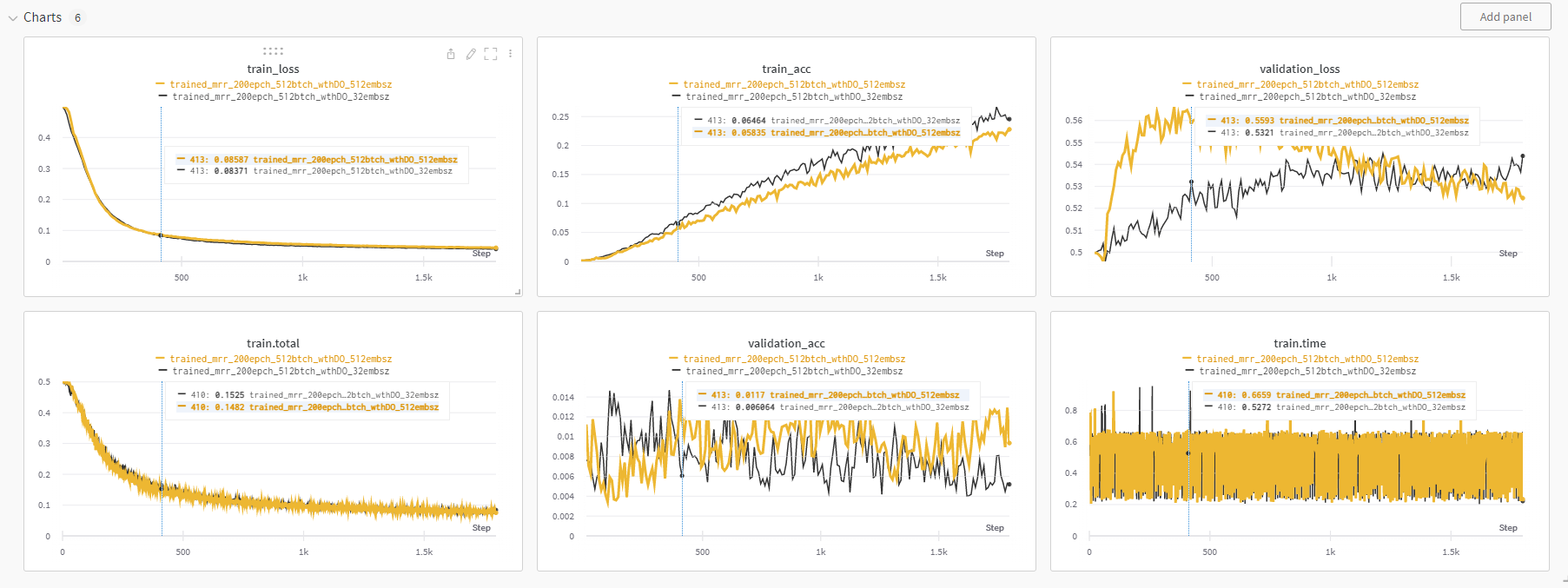
이것도 embedding size를 바꿔가며 실험을 했는데 왜 256크기의 embedding이 64크기의 embedding 모델보다 좀더 빠르게 과적합이 일어난건지는 잘 모르겠다.
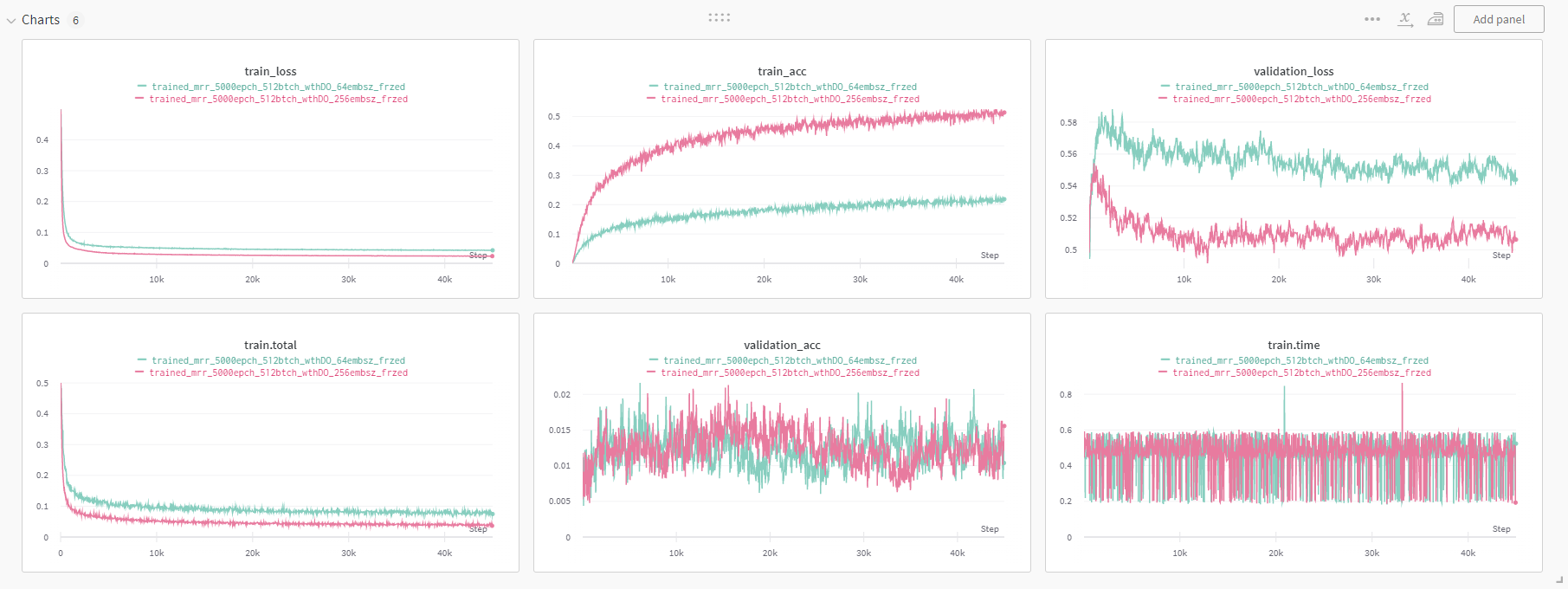
transfered parameter freezing
다음으로 진행한 것은 전이한 파라미터를 학습이 되지 않도록 고정하는 것이었다. 유의미한 차이를 발견할 수는 없었다.
# freeze all parameters except proj
for para in model_abc_trans.parameters():
para.requires_grad = False
for name, param in model_abc_trans.named_parameters():
if name in ['proj.weight', 'proj.bias']:
param.requires_grad = True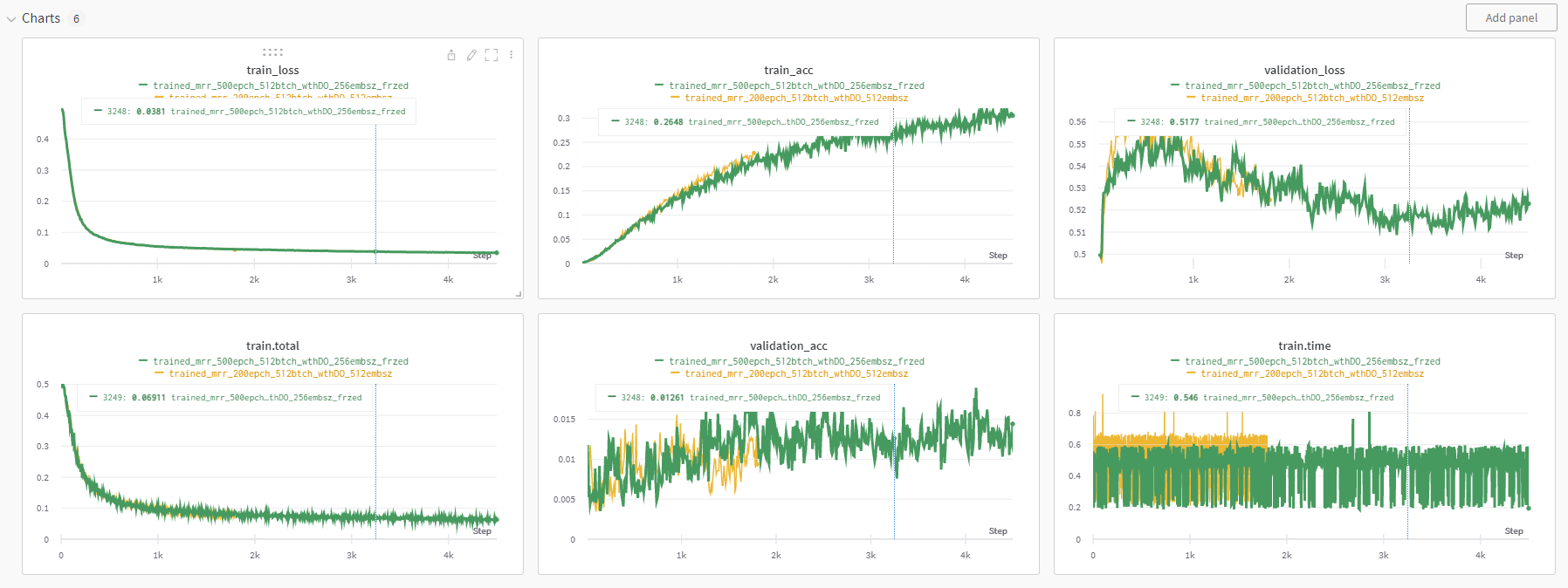
changing loss function
학습이 너무 안돼서 고민이 많았다. loss function에 혹시 놓치고 있는게 있지는 않을까 싶어서 pytorch에서 제공하는 batch contrastive loss인 CosineEmbeddingLoss를 사용해 보았다. 하지만 결과는 크게 다르지 않았다.
CNN Embedding Model
RNN에서 해결책을 찾지를 못해서 CNN 모델로 architecture를 바꿔 보았다. 모델은 embedding layer를 전이할 수도 있게 만들었었지만 이렇게되면 embedding size가 2624가 되어 첫 인풋의 channel의 크기가 무려 2624가 되어버린다.
# cnn layer 파라미터의 개수를 구해보자. 파라미터의 개수를 알아야 지금 모델이 내가 감당할 만한 모델인지 알 수 있다.
# kernel의 목적은 보고 있는 timestep 혹은 픽셀 정보를 1개의 뉴런으로 바꾸어주는 곱연산이다. ex) 3(kernel size) to 1
# 그리고 채널이란 독립적으로 존재하는 timestep 혹은 픽셀의 정보다. 이는 종합적으로 사용이 될 개별 정보로서 채널은 절대로 연속된 정보가 아니다.
# 따라서 kernel size x channel size가 바로 1개의 뉴런으로 요약이 된다고 보면 된다.
# 이 연산은 kernel이 연산되고 ex) a x p1 + b x p2 + c x p3
# 도장이 channel을 따라 꾸욱 눌러지는 형태로 그러니까 각각의 채널에서 따로 연산된 kernel 연산이 다시 더해진다. ex) (a x p1 + b x p2 + c x p3) + (d x p4 + e x p5 + f x p6) + ...
# 이 연산은 사용되는 kernel의 개수인 output_channel의 개수 만큼 반복된다.
# 따라서 필요해지는 parameter의 개수는 kernel_size x in_channel_num x output_channel_num이 된다.이에 따라 내가 만약에 2624의 channel을 그대로 5 kernel size의 1024 output channel로 계산할 경우 13 million의 크기의 1개의 layer를 사용하는 것이다. 이렇게 되면 bert-base가 12layers 110 million의 크기 였으니 너무 파라미터의 개수가 커지게 된다. 따라서 처음에는 2624를 1 kernel size로 linear layer와 같은 작동을 하는 conv1d를 사용했지만 이걸 교수님의 조언에 따라 embedding layer를 추가함으로써 1/10의 사이즈를 가지는 252개의 embedding size로 바꿔주게 되었다. 여기에서 이 비율은 20개의 토큰 info가 가지는 비율을 그대로 적용을 했다.(아니 근데 코드를 다시 보니까 1/0을 적용하지 않았다... 실험할 거리가 늘었다.)
class ABC_cnn_emb_Model(nn.Module):
def __init__(self, trans_emb=None, vocab_size=None, net_param=None, emb_size=256, hidden_size=128, emb_ratio=1/10):
super().__init__()
self.emb_size = emb_size
self.emb_ratio = emb_ratio
if vocab_size is not None and net_param is not None and trans_emb is None:
self.vocab_size_dict = vocab_size
self.net_param = net_param
self._make_embedding_layer()
elif trans_emb is not None:
self.emb = trans_emb
self.emb_total_list = [x.embedding_dim for x in self.emb.layers]
self.emb_total_size = sum(self.emb_total_list)
self.conv_layer = nn.Sequential(
nn.Conv1d(in_channels=self.emb_total_size, out_channels=128, kernel_size=1, stride=1, padding=0),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.Conv1d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.Dropout(0.5),
nn.MaxPool1d(2),
nn.Conv1d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.Dropout(0.5),
nn.MaxPool1d(2),
nn.Conv1d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.Dropout(0.5),
nn.MaxPool1d(2),
# nn.Conv1d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=0),
# nn.BatchNorm1d(128),
# nn.ReLU(),
# nn.Dropout(0.5),
# nn.MaxPool1d(2),
nn.Conv1d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.AdaptiveMaxPool1d(1),
)
self.linear_layer = nn.Sequential(
nn.Linear(128, emb_size)
# nn.Linear(256, 512),
# nn.ReLU(),
# nn.Linear(512, emb_size),
)
def _make_embedding_layer(self):
self.emb = MultiEmbedding(self.vocab_size_dict, self.net_param.emb)
def _get_embedding(self, input_seq):
if isinstance(input_seq, PackedSequence):
emb = PackedSequence(self.emb(input_seq[0]), input_seq[1], input_seq[2], input_seq[3])
return emb
else:
pass
def forward(self, input_seq, measure_numbers):
if isinstance(input_seq, PackedSequence):
emb = self._get_embedding(input_seq)
unpacked_emb, _ = pad_packed_sequence(emb, batch_first=True)
unpacked_emb = unpacked_emb.transpose(1,2)
after_conv = self.conv_layer(unpacked_emb)
before_linear = after_conv.view(after_conv.size(0), -1)
batch_emb = self.linear_layer(before_linear)
return batch_emb
else:
raise NotImplementedErrorExperiment with CNN
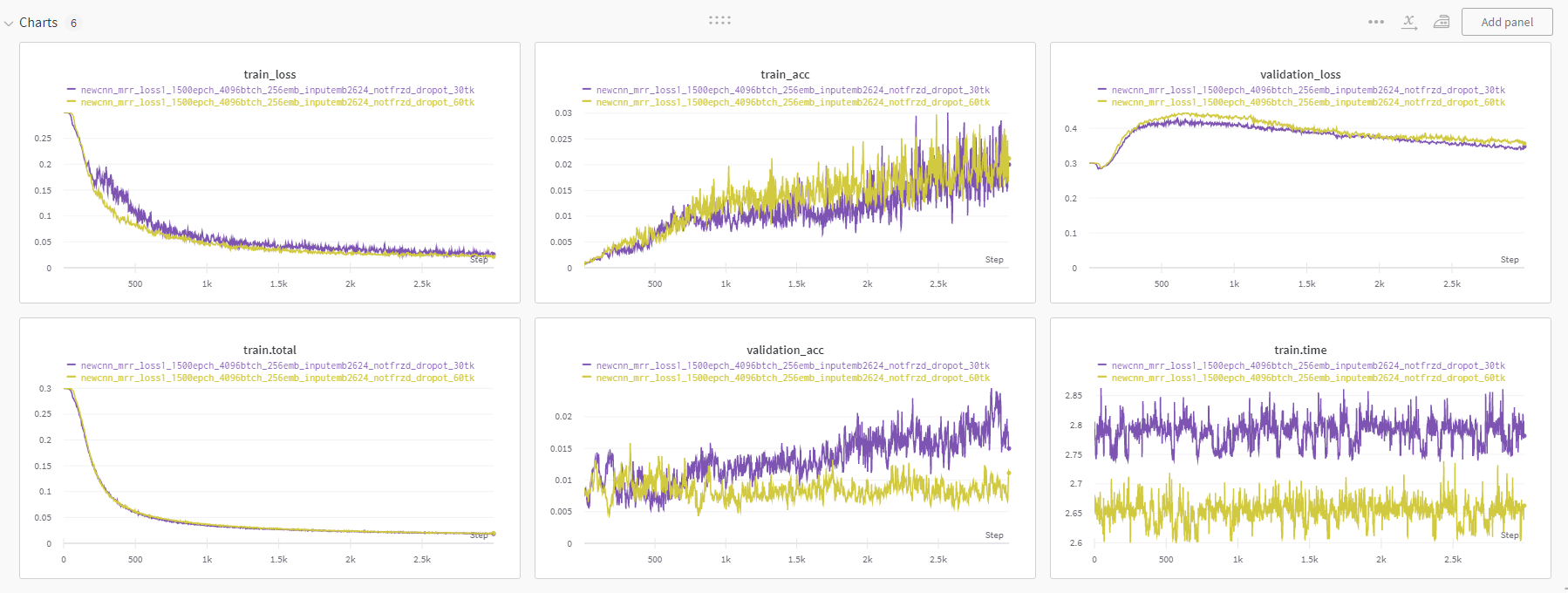
token size
교수님께서 조언해 주신 부분은 왜 학습이 잘 안될까라는 부분은 어쩌면 token 정보가 너무 과다하기 때문일 수도 있다는 것이었다. 그러니까 인풋으로 전체 정보를 주게되면 이 중에서 모델이 유니크한 패턴을 그냥 외워버려서 타이틀과 매칭을 할 수 있다는 것이다. 따라서 같은 타이틀에서도 다양한 input이 매칭될 수 있도록 토큰을 임의의 크기로 샘플링 하는 작업을 해보았다. 다만 적다보니 데이터셋에서 샘플링을 진행하는 것이 아니라 dataloader에서 진행을 해버리면 매번 불러올 때마다 tune의 정보가 달라질테니 너무 쉽게 data augmentation을 할 수가 있을 것 같다는 걸 알게되었다.(코드 작성할게 늘었다...)
self.data=[]
if self.tune_length is not None:
for x in data:
if len(x[0]) < self.tune_length:
continue
sampled_num = random.randint(0,len(x[0])-self.tune_length)
self.data.append(x[0][sampled_num:sampled_num+self.tune_length])
else:
self.data = [x[0] for x in data]
self.header = [x[1] for x in data]경이로운 train_acc 1을 보라 모델은 잘 외운다.
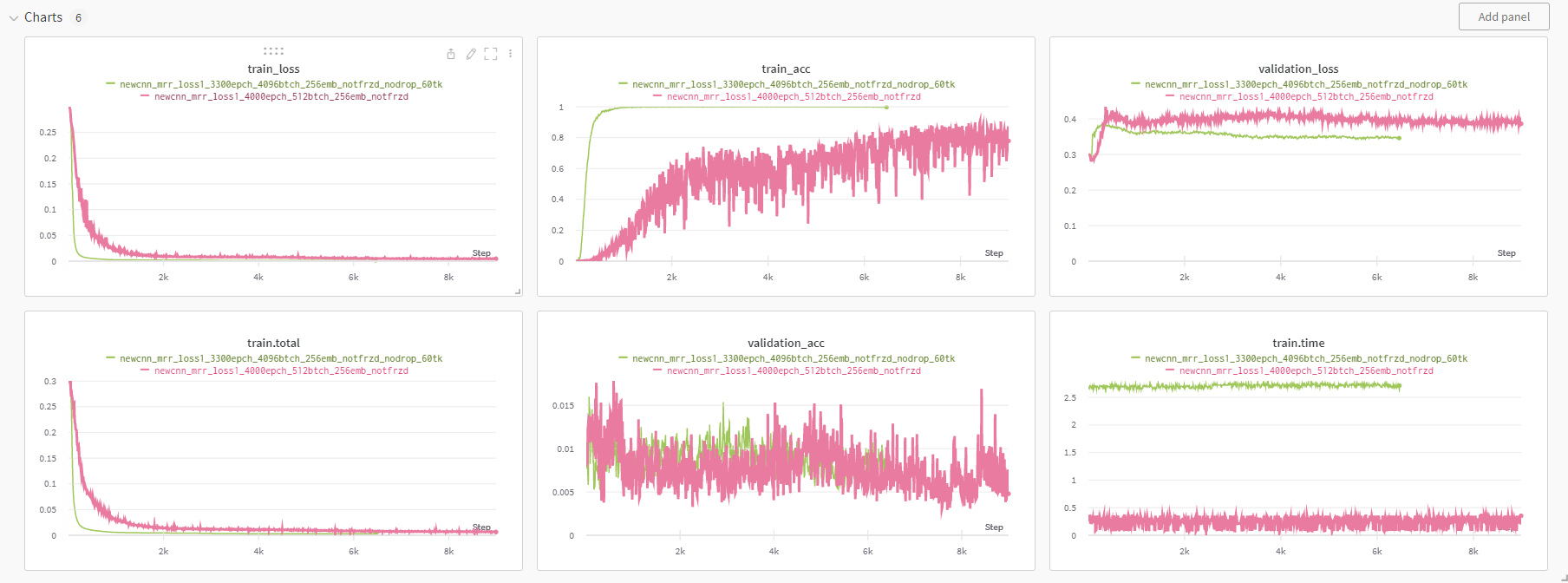
어쩌면 안되는건가라는 생각이 들 무렵 희망을 보았다. 30개의 토큰으로 줄여서 학습을 시키니 그동안 꿈적도 않던 validation acc가 우상향하는 모습을 보였다. 여기에서 한번도 넘지 못했던 0.02의 벽을 넘어섰다. 이제 이걸 기반으로 실험을 더 진행할 가능성이 생긴 것 같다.