Introduction
실험을 할 때 어떤 의도를 가지고 접근하느냐를 명확히 할 필요가 있다.
실험의 설계를 제대로 해주어야 나중에 고생하지 않는다.
결과를 해석하기 위해서는 이론적인 탄탄함, 다양한 경험을 통한 노하우 등이 필요한 것 같다.
Obstacles & Walkthrough
지난번 마지막 실험에서 validation accuracy가 우상향 하는 그래프를 얻었다. 하지만 이후로 2주간 모든 실험의 그래프들은 평행을 그리는 모습을 보였다. 여기에서 결과가 나오지를 않는 원인을 찾고 그것을 제대로 분석하고 보완 했어야 하는데 나는 그러지를 못하고, 양치기 식으로 모델의 파라미터만을 바꿔가다보면 언젠가는 좋은 결과가 나올거라고 진행을 했다.
Analysis about output embeddings of the model
train & valid dataset comparison
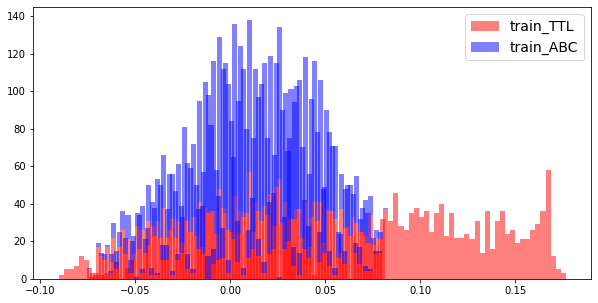
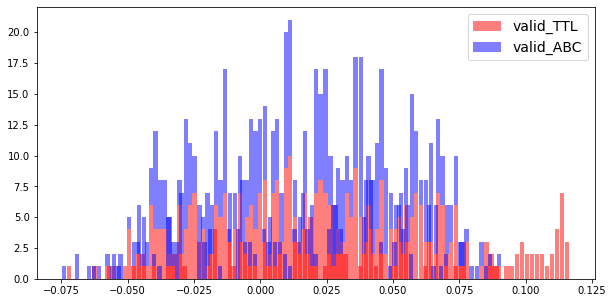
교수님의 조언에 따라 가장 먼저 생각해볼 수 있는 원인은 train dataset과 valid dataset 사이에 어떤 차이가 있는지를 확인하는 일이었다. 특이할만한 점은 title embedding이 abc embedding에서는 찾아볼 수 없는 어떤 군집(그림에서 동그라미 친 부분)을 이루고 있다는 것이다. 이 부분을 해석하기는 조금 어렵지만 학습이 어떤 식으로든 잘되지 않았다는 것을 알 수 있을 것 같다. 저 타이틀들을 따로 뽑아서 확인을 했어야 하는데 제대로 확인하지를 않았다.
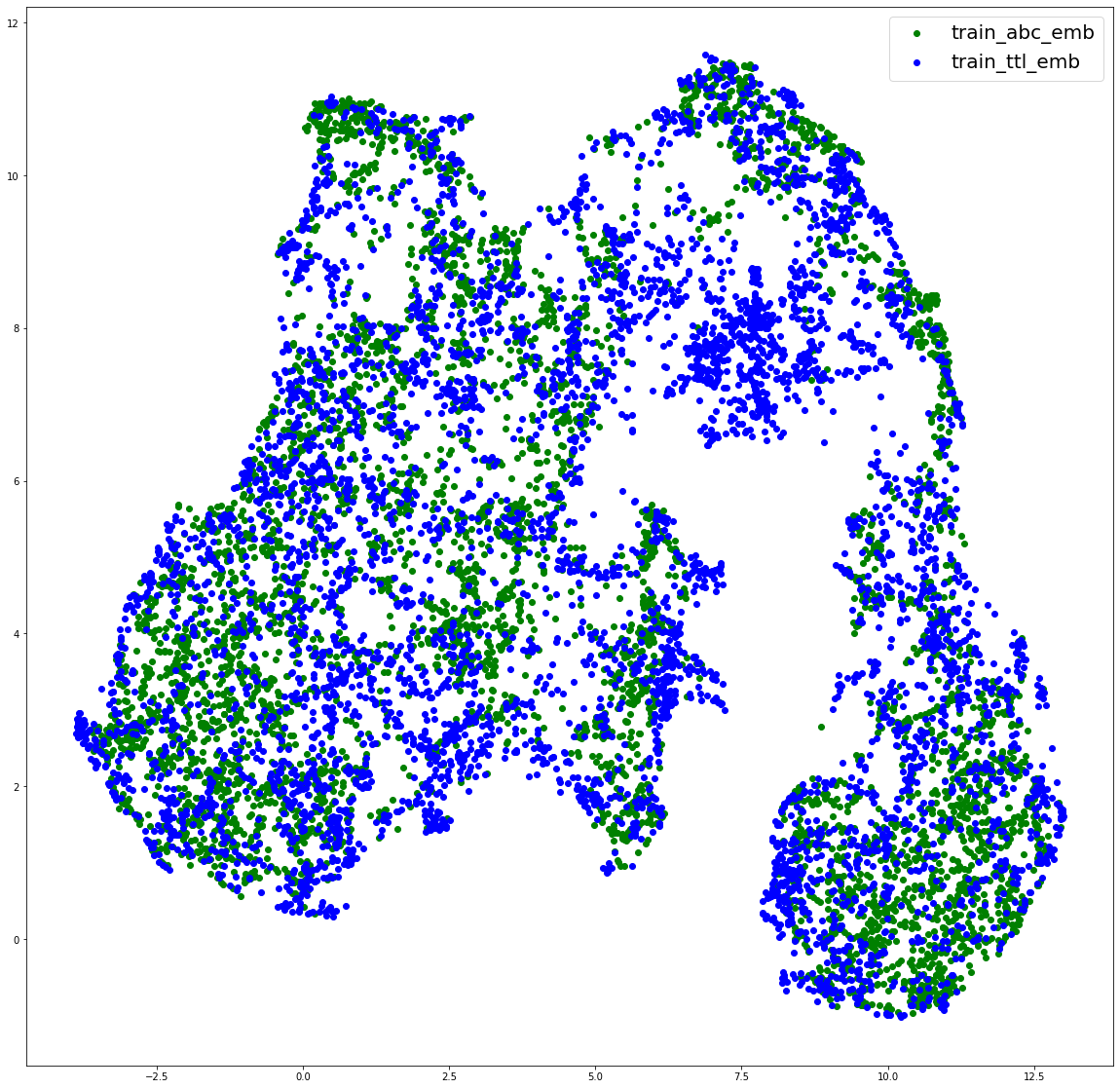
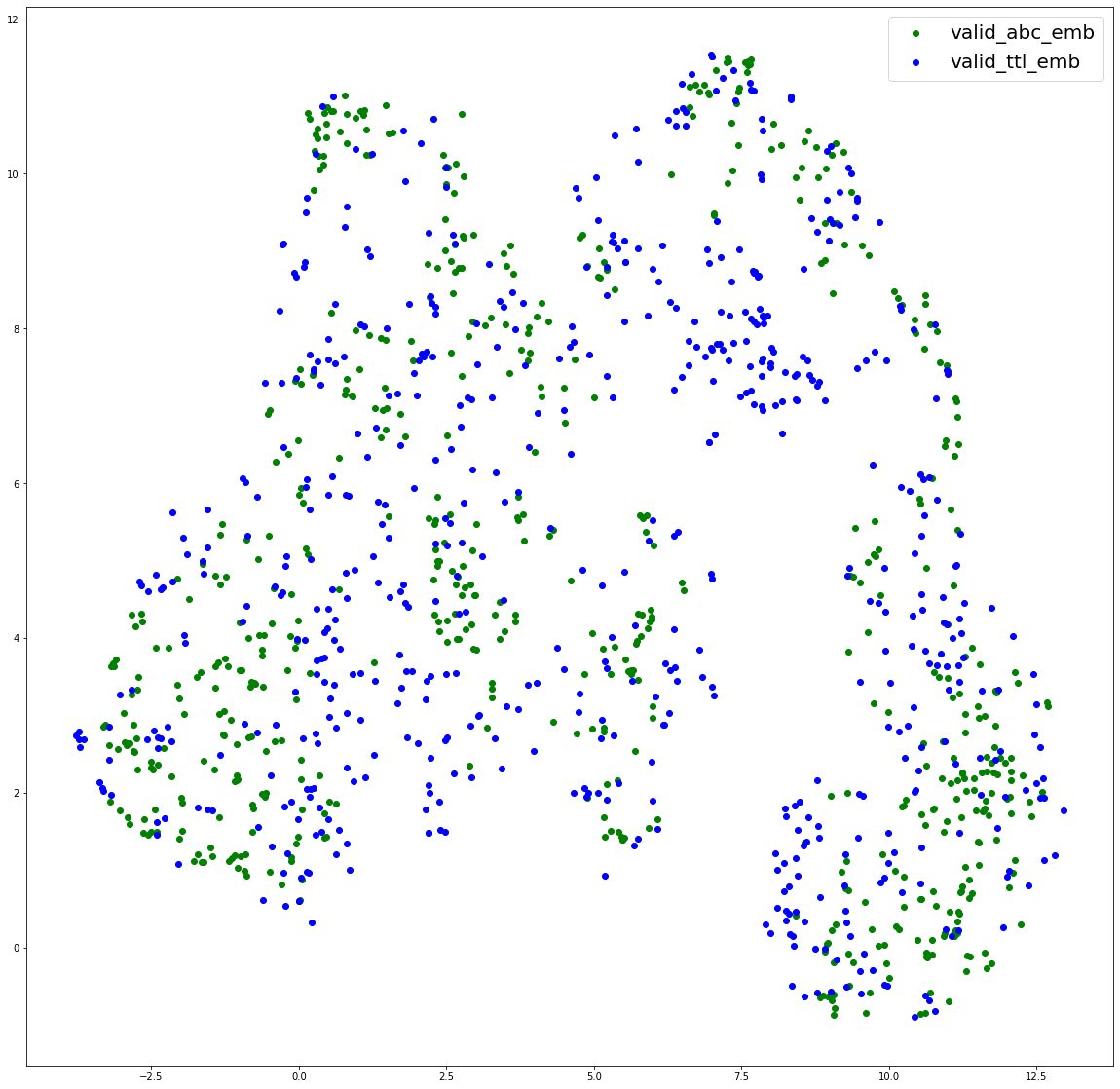
방법적으로는 UMAP, TSNE, PCA를 통해 가장 성능이 좋았던 모델의 output embedding을 2차원으로 축소해 그려보았다.
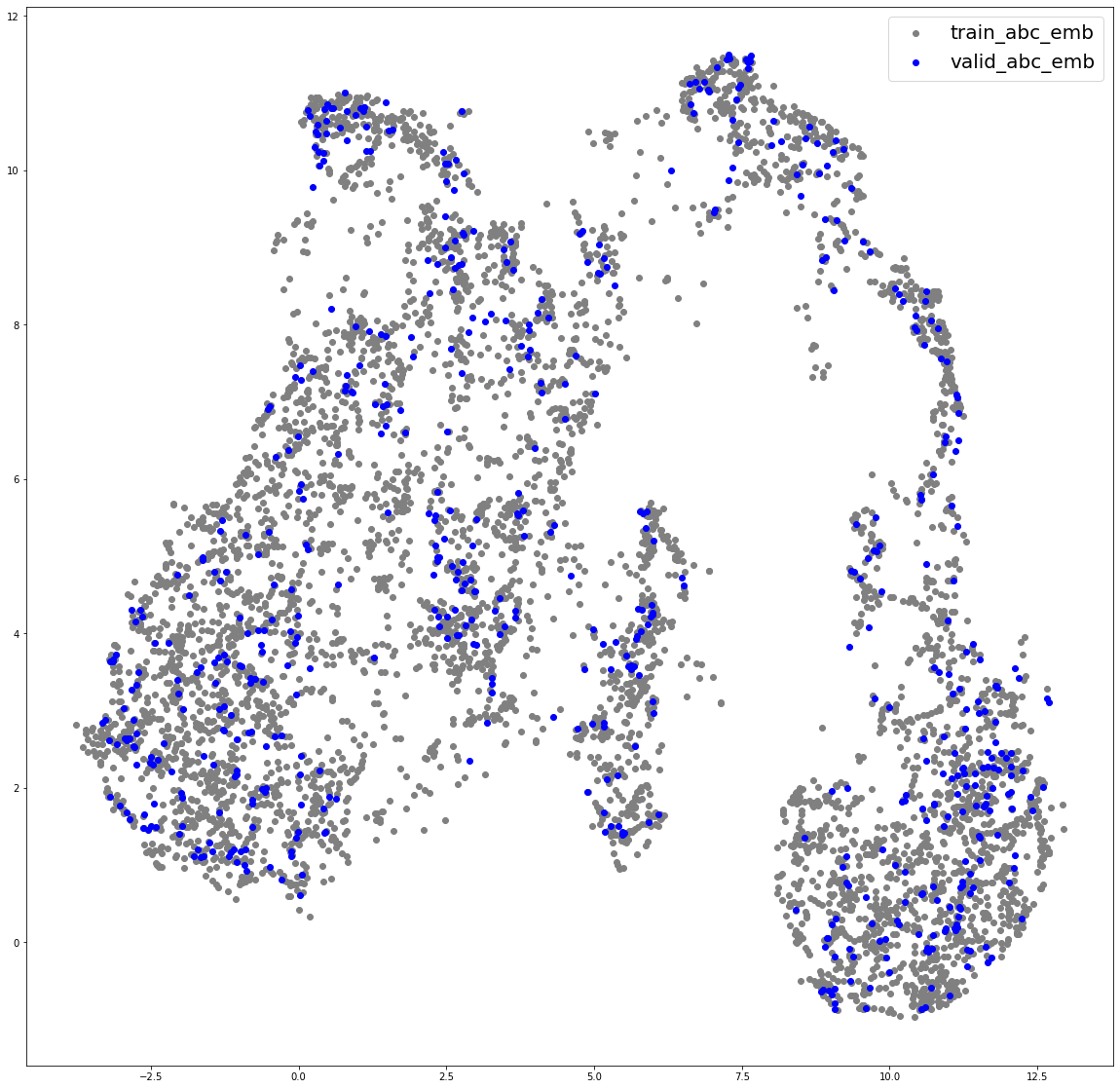
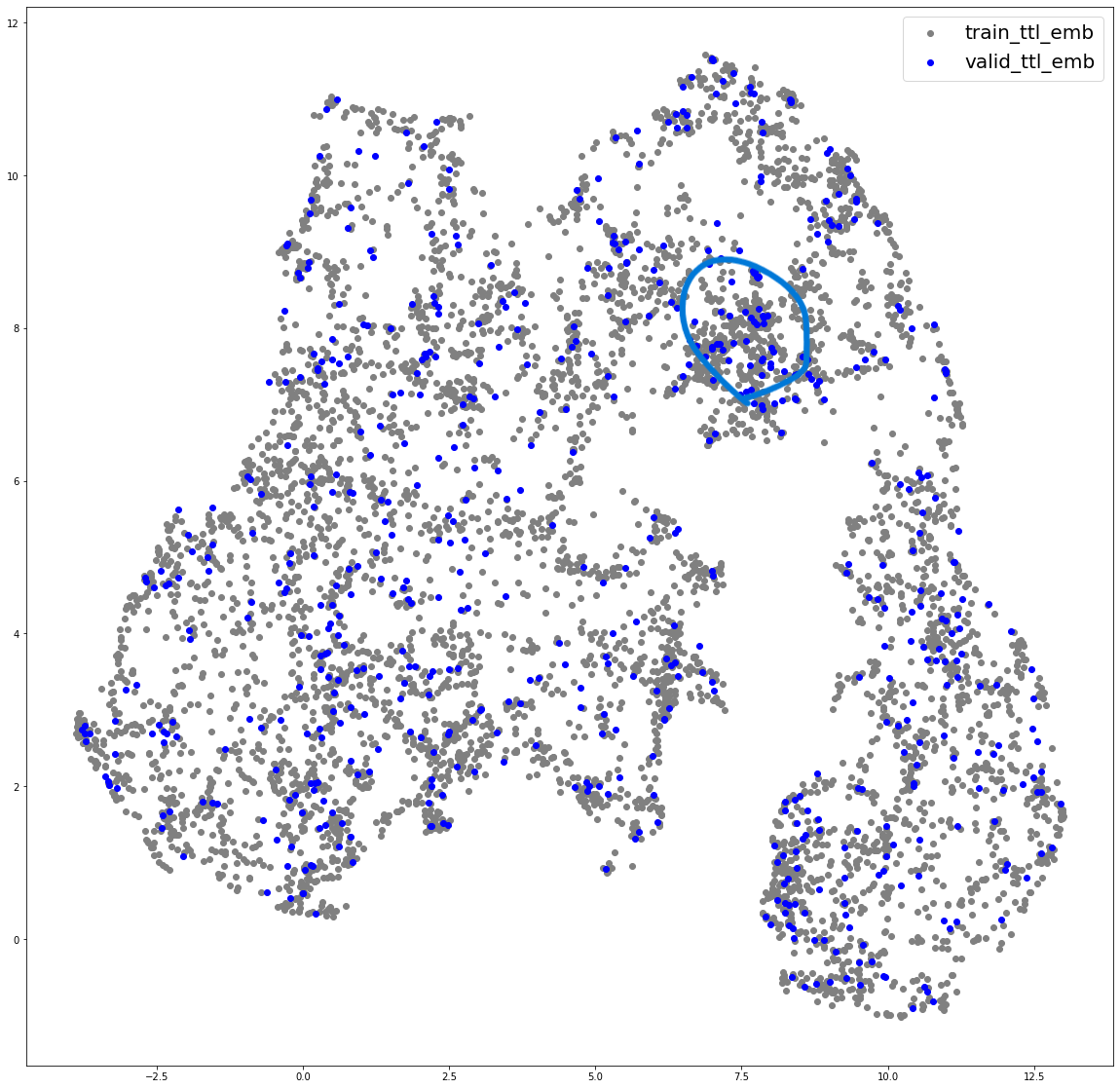
plotting embeddings of title and abc
타이틀과 abc 임베딩이 같은 공간에서 어떻게 분포하는 지를 그려보았다. 적당한 거리를 잘 형성하고 있지만 앞서 발견한 군집을 이루는 부분이 신경 쓰인다. 지금 포스팅을 하는 시점에서 2주 전이기에 그때는 그냥 그러려니 하고 넘어갔는데 지금은 이걸 잡아야한다는 것을 알게된 것 같다.
Cosine Similarity between each tune to other tunes
이 그래프는 하나의 tune이 다른 tune과 어떤 거리 관계를 가지는 지를 확인한 그래프이다. 모델의 아웃풋으로 나온 하나의 튠 정보(title, abc)가 다른 튠의 정보들과 어떤 거리를 가지는 지를 확인하는 방법인데 일반적으로는 다른 정보들과는 비슷한 거리 즉 cosine similarity를 기준으로는 평균이 0에 가까운 tune이 많은게 정상일 듯 하다. 하지만 title을 보았을 때 다른 튠들과는 특별히 더 멀리 떨어진 튠들이 있다는 것을 확인할 수 있었다. 이 부분도 학습이 잘 이루어지지 않았다는 것 특히나 이후에 살펴볼 데이터셋에 문제가 있다는 것을 의미하고 있다는 것을 알 수 있다.
Check the answer which LM has made
아래는 가장 좋았던 모델이 답으로 예측한 20개의 타이틀과 실제 답을 적어보고 어떤 연관성이나 특이한 점을 찾기 위해 만들어본 파일이다. 모델은 1천개의 튠 중에서 40개 정도의 답을 찾아내고 있었다.
picked_titles : ['The Emyvale', 'Christy Campbell', 'The Cross Of Inverness', "The Marquis Of Huntly's", 'The Mountain Pathway', "The Fiddler's Hickey", 'Crossing The Minch', "The Fochaber's Rant", 'Major George Morrison, DSO', 'The Golden Monocle', "Irene Meldrum's Welcome To Bon Accord", 'Cairngorum Mountain', 'Lady Athenry', "Mary MacDonald's", 'The Marchioness Of Huntly', 'The Campbelltown Kiltie Ball', "Sandy's New Chanter", "John MacKenzie's Fancy", "Miss Campbell's Awkward Adolescant Advances", 'The Humours Of Ballyconnell']
correct_title : The Devil In The Kitchen
picked_titles : ["The Scaffie's Cairt", "The Lady's Well", 'A Mhisg A Chur An Lolig Oirn', "Colonel Graham's Favourite", "Erin's Shore", "Jimmy Duffy's Highland", 'Cottesloe Beach', 'Good Ship Planet', 'Miss Hannah Of Elgin', 'The Marchioness Of Tullibardine', 'As I Went Out Upon The Ice', "I'll Buy Boots For Maggie", 'The Gullane', 'Bonnie Galloway', 'The House Of Letterfourie', 'Mrs Helen L MacDonald Of Dunach', 'Inverness Fiddlers', "Cofey's", "Parnell's March", 'The Bay Tree']
correct_title : 10th Bat Crossing Rhine
picked_titles : ['The Knotted Cord', 'The Flooded Road To Glenties', 'Baldy Hollow', 'The Grey Daylight', 'Clear The Decks', 'Burning Of Auchindoun', 'Branohm', 'The Curragh Races', "Coen's Memories", 'The Northern', "Jenny's Welcome To Charlie", 'The Road To Sligo', 'The Maid Of Mount Kisco', 'The Glen Of Aherlow', 'The New Leaf', 'The Seamless Gutter', 'An Páistín Fionn', 'Computer Joe', "Carolan's Farewell To Music", "Rodney's Glory"]
correct_title : 1st August
picked_titles : ['The Essex Bazurka', 'Last Of The Starrs', 'When Cloe', 'Air Moving', "Sophie's", 'Down By The River Side', 'Amazing Grace', 'The Siege Of Ennis', 'The Home Ruler', 'Finnish', 'Miss Baird Of Saughton Hall', 'The Coburg', 'Barham Down', 'Lament For The Fox', 'Ice On The Water', 'Swiss', "Mr Preston's", 'Fir Bolg', 'The Rambling Pitchfork', 'The Anderson Family Fling']
correct_title : 2D Or Not 2D
picked_titles : ['Sticks Pass', "The Bride's Favourite", 'The Kingussie', 'The Caledon Line', 'Fried Black Pudding And Laverbread', 'Around The Twist', 'The Straw Seat', "Tom Bawcock's Eve", 'The Trip To Gortin', 'The Wheatsheaf', "Father O'Flynn", 'In Continental Mood', 'The Happy Farmer', 'The Golden Fish', 'Off She Goes', "The Banshee's Cry", "Tyrell's Pass", 'The Curragh', 'Boring The Leather', "Bill Flynn's"]
correct_title : The 30 Year
picked_titles : ['Blue Rain', "Maggie Brown's Favourite", 'Mockingbird Hill', "Angler's", "The Gartan Mother's Lullaby", 'Spatter The Dew', 'The Quimper', 'The Hammersmith Flyover', 'The Baltiorum', 'High Caul Cap', 'Craignish Milkmaid', 'Wind Chimes And Nursery Rhymes', 'The Grumpy Old Fart', "Roy Trounce's Doggedness", "Christie's Quickstep", 'The Blackthorn Stick', 'Aisling Gheal', 'The Wooden Shutters', 'The Wind And Rain', 'Diferion Arian']
correct_title : 30th Anniversary
picked_titles : ['Baldy Hollow', 'The Flooded Road To Glenties', 'Branohm', 'The Wild Swans At Coole', 'The Seamless Gutter', 'Moving In Old Decency', 'The Knotted Cord', 'Computer Joe', 'The Maple Leaf', 'From Galway To Dublin', 'The Man From Glengarry', 'The Old Crossroads', 'The Marathon', 'The Northern', "Mrs Carolan's", "Andy Renwick's Ferret", 'Cluck Old Hen', 'Courthouse', 'Old Molly Oxford', "Alasdair's"]
correct_title : 5:30am
*********************Below one got the answer!*********************
picked_titles : ['The High Road To Linton', 'Bodmin Riding', 'John Of The Glen', 'The Glencoe', "Roof Thatcher's Daughter", "The 72nd Highlanders' Farewell To Aberdeen", 'The Doon Highland', 'The Nova Scotia', "Graham And Jilly's Wedding", 'Domhnall Dubh', 'The Bluestack Highland', 'Beauty Of The North', 'Munlochy Bridge', "John Doherty's Highland", 'The Flowers Of Edinburgh', 'Woodland Flowers', 'The Hills Of New Zealand', "Jimmy O' The Bu's", 'The High Road To Galway', 'The German Beau']
correct_title : The 72nd Highlanders' Farewell To AberdeenChanging accuracy rate by TopK parameter
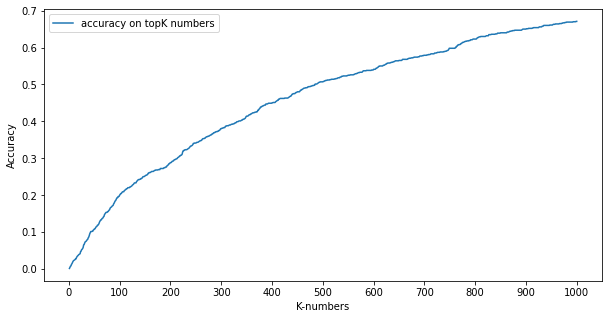
현재의 accuracy는 모델의 예측 중에 topK를 지정하고 여기에 정답이 있는지를 확인하는 방식으로 계산이 되고 있다. batch의 수에 따라 accuracy가 요동을 칠 수 있지만(1000개 중에 20개의 보기를 주는 것과 2000개 중에 20개의 보기를 주는 것은 확실히 다르다) 지금 실험은 full batch로 그 개수가 거의 차이가 없는 실험이기에 크게 문제될 것은 없다.
해당 그래프는 topK의 값에 따라 accuracy가 어떻게 변화하는 지를 그린 그래프이다.
추가로 현재는 rank-based accuracy를 체크하는 방법으로 MRR(Mean Reciprocal Rank)을 사용하고 있는데 DCG를 사용해서 추가적인 모니터링이 필요하다. 이 부분은 어서 구현해야하는데...
Experiment hoping lottery or 기도메타
이때까지만 해도 사실 원인 분석보다는 예전에 좋았던 실험을 재구현하는 것 그리고 좋은 결과는 운빨?인가라는 생각이 있었다. 하지만 이는 틀렸다. 좋은 결과에는 원인이 있고, 그래야만 한다. 아래 이미지는 2~3일간 모델의 hidden size를 16단위로 바꿔가며 실험하던 내용이다. 아무 근거가 없었고, 아무 목적도 없었다. 기도는 다른 사람들을 위해서 하자.

Case Check : Pretrained Title Embedding model
이어서 모델의 아웃풋을 실제 텍스트로 살펴보던 와중에 데이터셋에 크나큰 결함이 있다는 것을 발견했다.
1.제목들에 영어가 아닌 언어들이 포함이 되어 있음(게일어, 웨일즈어 ex)Mhisg a Chur an Lòirig Oirn)
2.어순이 이상한 제목(the가 제목의 끝에 위치하는)이 있음
3.타이틀이 없는 튠들이 포함되어 있음타이틀이 'x'로 표기된 2천여개의 튠)
2,3번의 문제는 쉽게 처리가 가능 했지만 1번의 경우가 문제가 되려면 현재 사용하고 있는 pretrained title embedding model이 이 언어들의 의미정보를 어떻게 처리하고 있는지를 확인할 필요가 있었다.
pretrained title embedding model로는 Sentence Transformer를 사용하고 있었는데 openai에서도 embedding model을 저렴하게? 제공하고 있었기에 이를 사용해보고, 둘 사이의 차이 그리고 두 모델이 만들어내는 embedding space를 plotly를 사용해서 확인해보기로 했다.
velog는 html 파일을 바로 읽지 못하는 것 같다. plotly를 이용한 3D 그래프를 보는 꿀팁은 오른쪽 마우스클릭도 함께 사용하는 것이다 :)
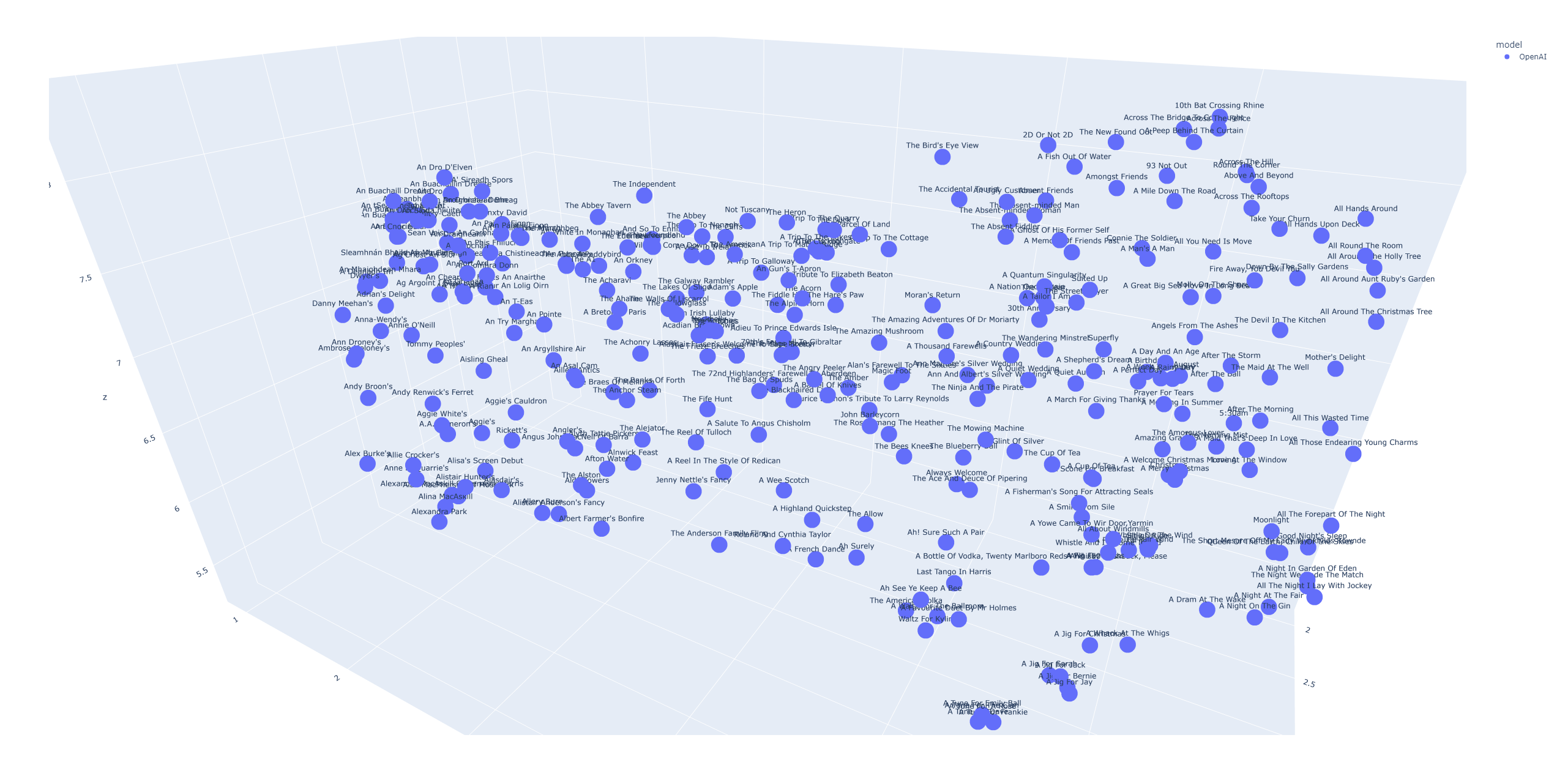
살펴보면 모델은 게일어나 웨일즈어 혹은 특정한 언어로 만들어진 문장들을 비슷한 곳에 몰아넣으려는 경향이 있는 것 같았다.
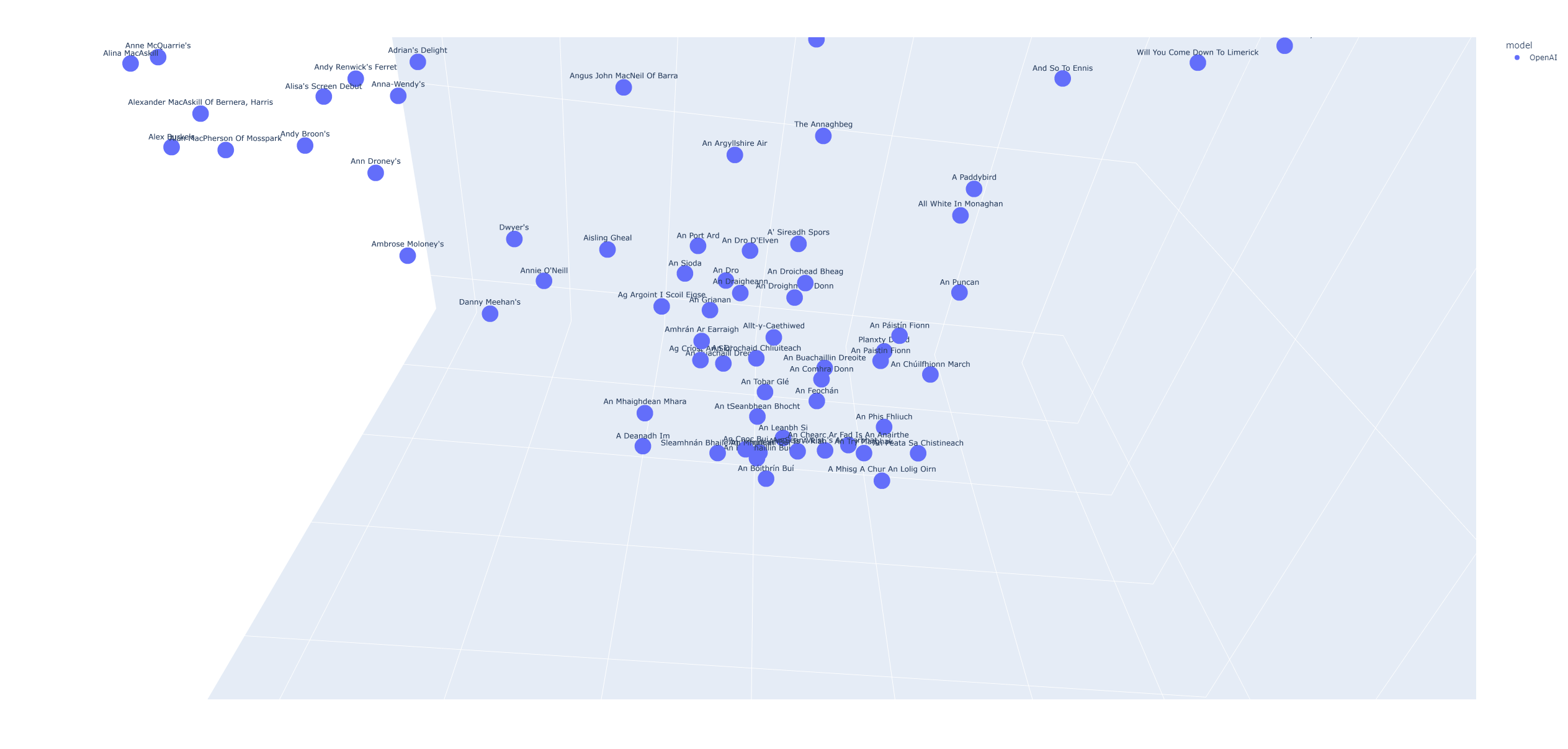
하지만 이를 확신할 수 없는 것이 "Aisling Gheal"이라는 타이틀과 가장 유사하다고 임베딩한 문장들을 순서대로 나열해보니 각각의 뜻에는 의미론적으로도 연관성이 존재한다는 것을 어렴풋이 느낄 수 있었다. 그러니까 이 타이틀들이 비슷한 공간에 묶인 것은 chatgpt의 설명에 따르면 단순히 Irish로 묶여있기 때문이라고 말하기는 힘들다는 것이었다. 더불어 황당하지만 나는 "Aisling Gheal" 주변의 단어들이 Irish라는 의미로 묶여있기 때문이라면 이들을 제거한다면 좀더 좋은 title embedding을 가지고 학습을 진행할 수 있다는 생각으로 "Aisling Gheal"과 가장 높은 연관성을 가지는 300개의 문장을 제거하고 학습을 진행해보았다. 결과는 좋지 않았다 당연할 수도 있지만 ;) 이 부분은 추가적인 확인이 필요하다.
It is not possible to determine the semantic relevance among the titles you provided without additional context. The titles appear to be names of places, people, or cultural references in the Irish language, but their relevance to each other would depend on their connection to a specific topic, historical event, geographical location, or cultural tradition.
"Aisling Gheal" - Bright Vision
"Eibhlí Gheal Chiúin Ní Chearbhaill" - Bright Quiet Eileen O'Carroll
"Sliabh Geal gCua" - Bright Mountain of the Back
"Caisleán An Óir" - Castle of Gold
"Geaftaí Baile Bhuí" - Yellow Town Gaeltacht
"The Cuil Aodha" - The Quiet Nook
"An Draigheann" - The Thorn
"Ril An Suaimhnis" - Stream of Calm
"Oilean" - Island
"Oró A Bhuachaillín" - Song of the Boy
"An Grianan" - The Sunny Place
"The Gaelic Farmer" - The Farmer in Gaelic
"Muing A tSionnaigh" - MacSweeny's Wall
"The Gallowhill" - The Hill of the Gallows
"Eileen O'Callaghan's" - Eileen O'Callaghan's Place/LandCase Check : Context Information
pretrained sentence(title) embedding model에 넣어주는 정보는
1.title only - "Aisling Gheal"
2.title with song - "Song Title: Aisling Gheal"
3.title with song with genre - "Song Title: Aisling Gheal; Genre: Irish folk music"
로 구성을 바꾸어보았다.
titles which have low semantic information without context
어떤 타이틀들은 문맥이 없이 그 자체의 정보로는 상대적으로 적은 의미론적 정보를 가지는 경우가 있었다. 이를 계산하는 방법은 title only의 임베딩과 title with song의 임베딩의 cosine similarity를 비교한 뒤에 이 값들의 차이가 큰 제목을 찾아내면 된다. 운이 좋게도 전위적인 제목이 아닌 실제로 제목을 붙이지 못했다는 의미에서 untitled라는 제목의 곡들이 있는 것을 찾을 수 있었고, 더불어 이러한 제목의 곡들을 제외한 채로 학습을 시킬 경우에 일시적이었지만 가장 좋은 결과의 validation accuracy를 얻을 수도 있었다. 하지만 실험을 다시 보니 token이 fixed된 형태가 아니고 랜덤하게 30개를 샘플링하는 토큰이라 우연일 수도 있겠다는 의심이 들어서 이 부분은 추가적인 확인이 필요할 것 같다.
['Untitled', 'Home', 'For', 'Apple', 'Christmas', 'Coffee', 'Mary', 'Atlantic',
'Spanish', 'February', 'Cookie Shine', 'Hamilton House', 'September', 'Atlantic Drive',
'Border', 'Empty Wallet', "Stephen Campbell's", 'Summer', 'The Chinese', 'Why So',
'The Japanese', 'David Power', "Fraher's", "Henry Cave's", 'Boolavogue', 'The House',
'Skipping Lambs', 'Castle Dangerous', "Elizabeth Donald's", "Sam Cormier's",
"MacDonald's", 'Mad', 'Log Drivers', 'Uist', "Forest Rogers'", 'George Booker',
'Always Welcome', 'Delighted', "Joe Cormier's", 'The Independent', 'Bretonia',
"Martin Rochford's", "Alex Burke's", 'Friendsville', 'C+', "Lewis Proudlock's",
'Election', 'Absent Friends', "Sean Reid's", "Anthony Murray's"]Which pretrained embedding type is better?
현재는 모든 유니크한 타이틀에 대해서 각각의 embedding 값을 pretrained model을 통해 계산한 뒤에 이를 csv파일로 저장을 해두고 필요에 따라 바꿔가며 이 값을 불러와 사용을 하고 있다. 그리고 지금 확실하다고 말하기는 어렵지만 title only를 쓰는 경우보다 title 앞에 "song title: "을 붙여주는 경우에 학습의 지표가 더 나은 모습을 보여주고 있다. 따라서 이를 먼저 확인한 뒤에 의미론적인 정보가 부족한 타이틀들을 제거한 결과를 확인하고, 마지막으로 다른 언어를 사용한 경우에도 비교 실험을 진행을 할 필요가 있을 것 같다. 장르 정보를 추가하는 경우는 실험의 목적인 title만을 이용하는 것과 무관하므로 진행하지 않는 것이 좋을 것 같다. 다만 타이틀 중에는 "Jig for Jay", "Waltz for joy"와 같이 이미 장르의 정보가 포함이 된 타이틀들이 있다. 이 타이틀들은 추가적인 의미와 상관없이 매우 가까이 분포를 하는 모습을 보인다.
Extra : training time check
학습의 시간이 오래걸린다면 이를 먼저 수정하고 추가적인 진행을 해야한다. 교수님이 답답하셨던지 개인 면담시간에서 어떤 부분이 시간을 잡아먹는지 체크하고 또 수정하는 방법을 알려주셨다. 그 결과 기존보다 1step의 학습이 2초가량 줄어들 수 있었다. 내 경우에는 get_item에서 batch를 꺼내오는 부분과 loss를 계산하는 부분에서 시간이 오래 걸리는 것을 확인할 수 있었다.
