Introduction
모델이 성장하는 것을 확인하는 것은 제대로된 metric을 설정했다는 것을 전제로 한다. 만약에 눈금자가 잘못 설정이 되었다면 그 자로 측정한 결과는 결코 제대로된 의미를 담고 있다고 말할 수 없을 것이다. 나의 경우에는 이 metric이 잘못 설정이 되었다는 것을 너무 늦게 알게 되었다.
Obstacles & Walkthrough
Hyper parameter
이 실험을 가장 크게 바꾸었던 파라미터는 margin의 값과 learning rate를 각각 1/10, 1/3 정도로 수정을 해주었을 때였다. 기존의 메트릭이 문제가 있었기에 실제 결과를 보고 모델의 유의미한 학습을 진행하는 경우를 가정하고 이를 실제의 좋은 결과로 만들어낼 수 있었다.
Checking Actual Results
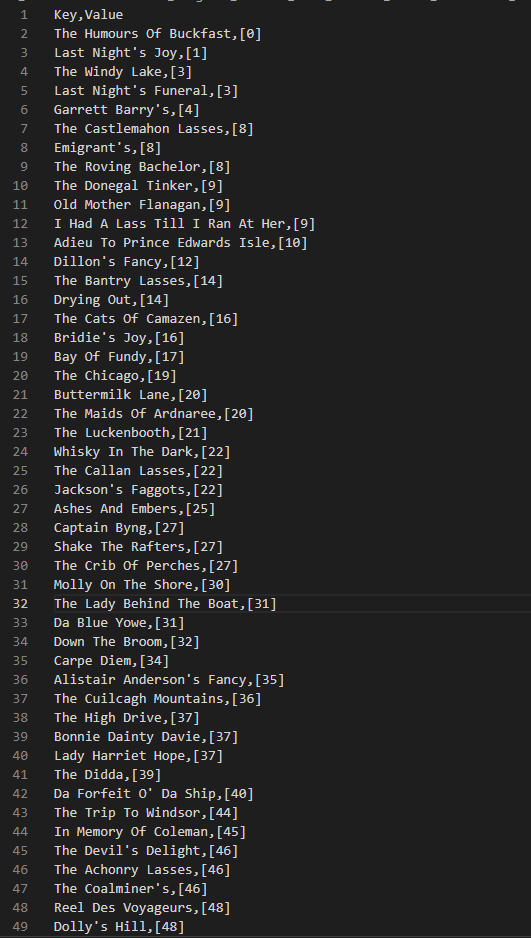
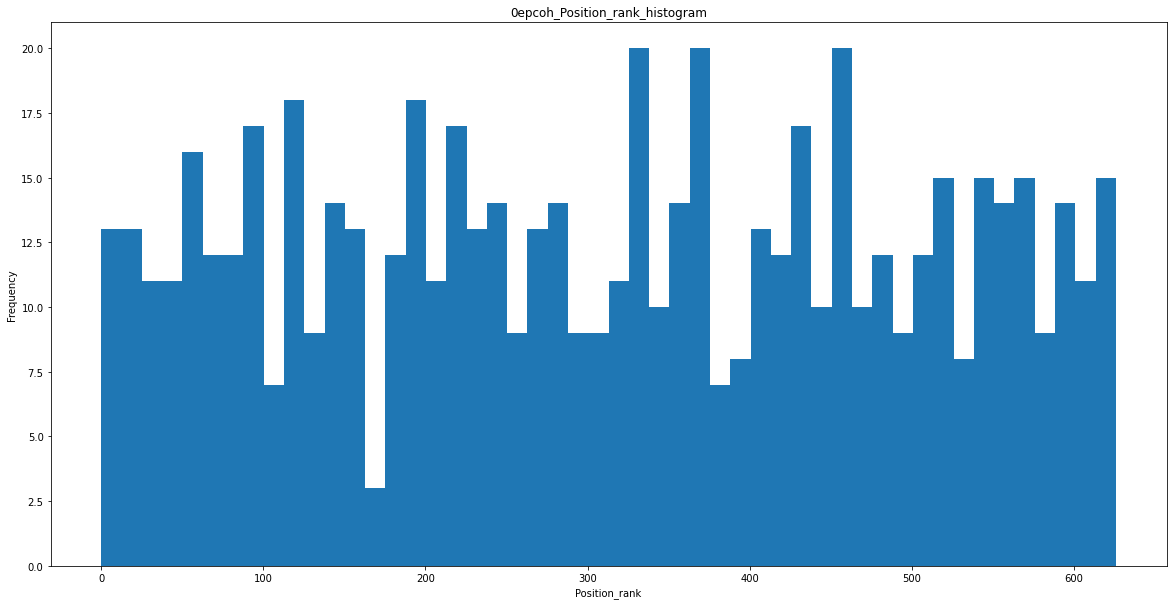
아래의 결과는 제목과 제목이 모델의 예측에서 획득한 등수를 기록한 csv 파일이다. 파일은 등수의 순서대로 정렬을 해두었다.
0 epoch
첫번째 이미지는 0 epoch 상태에서 획득한 등수이며
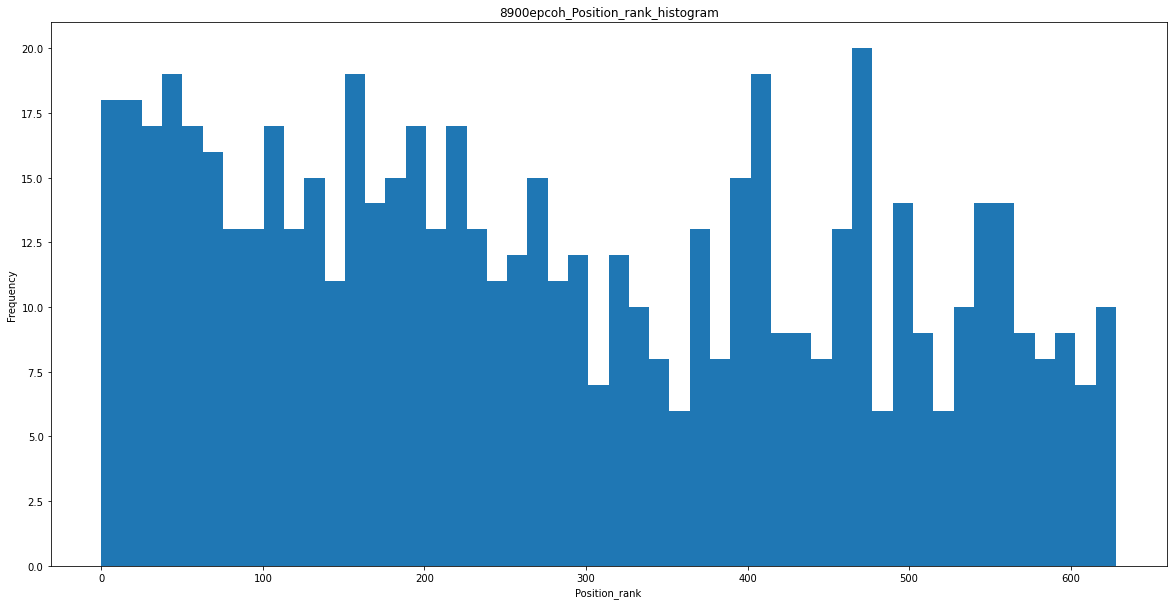
8000 epoch
두번째 이미지는 400 epoch 에서 획득한 등수이다.
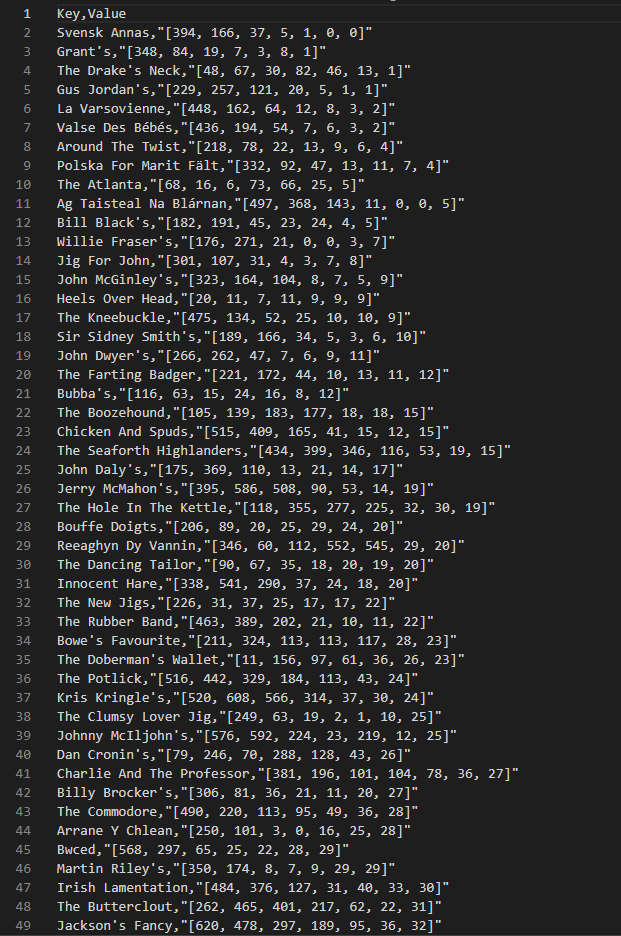
학습이 진행이 되면서 등수가 조금씩 더 올라가는 모습을 보인다. 기존의 MRR이나 nDCG 메트릭을 사용하는 경우에 discount를 하는 값이 초기 등수에 유리하게 만들어지기에 초반의 등수를 잘 맞추는 것으로도 좋은 점수를 얻는 경우가 생길 수 있었다. 물론 모델이 초반만 잘 맞추고 중후반을 잘 못 맞추는 경우는 충분히 학습이된 모델의 경우엔 관찰되지 않았다.
Wandb Graph
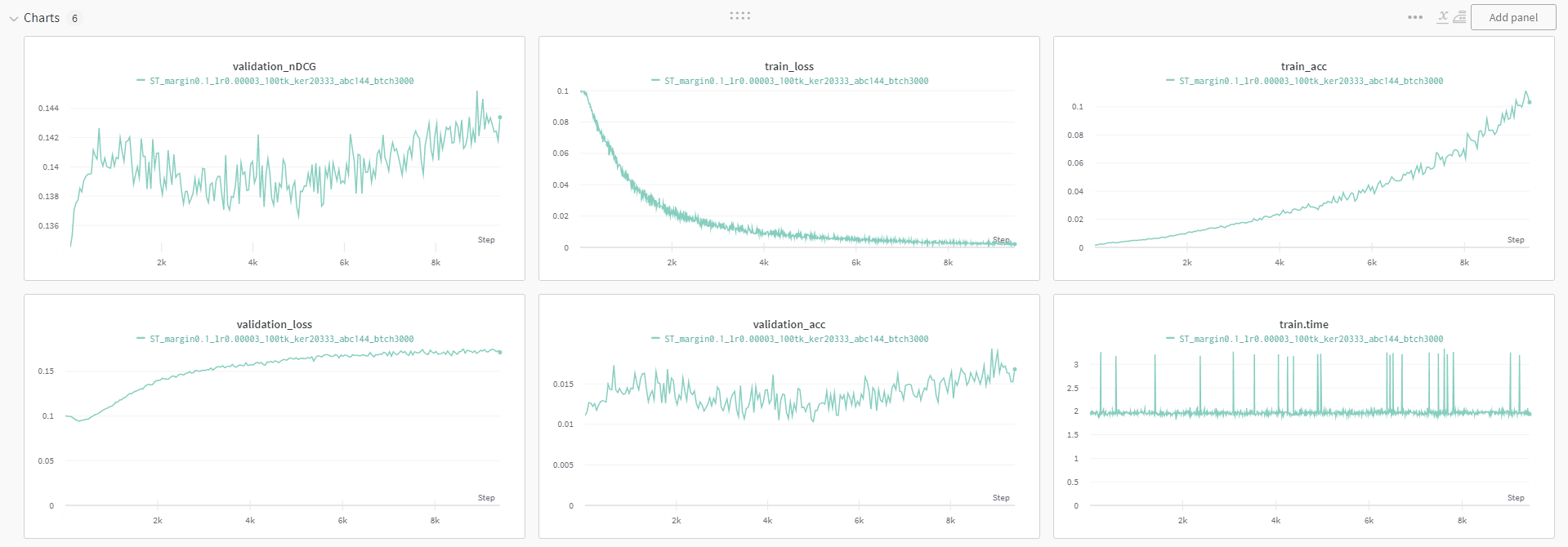
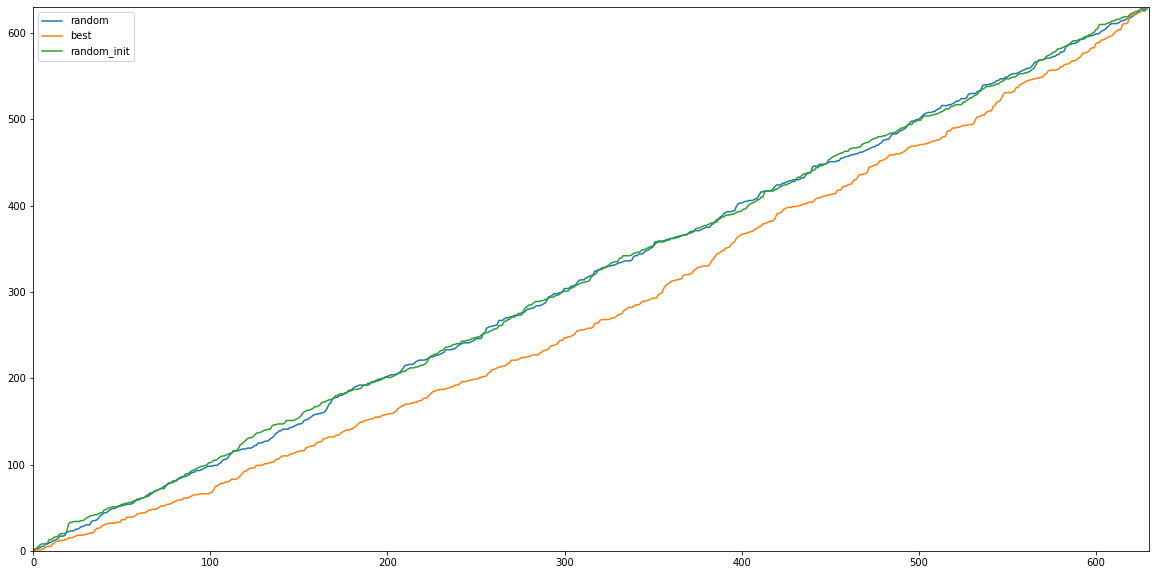
Position Graph
또한 630여개의 validation dataset으로 등수를 plot 함수로 그려본 결과 0 epoch(random)의 결과와 random하게 initialized된 값들의 그래프(random_init)와 제대로 학습이 된 모델의 결과의 그래프(best)는 확실히 차이가 있었다.
Position Histogram
등수를 히스토그램으로 그려보았을 때 충분히 학습이 된 모델의 경우에 상위권의 등수들의 양이 더 늘어난다는 것을 확인할 수 있었다.
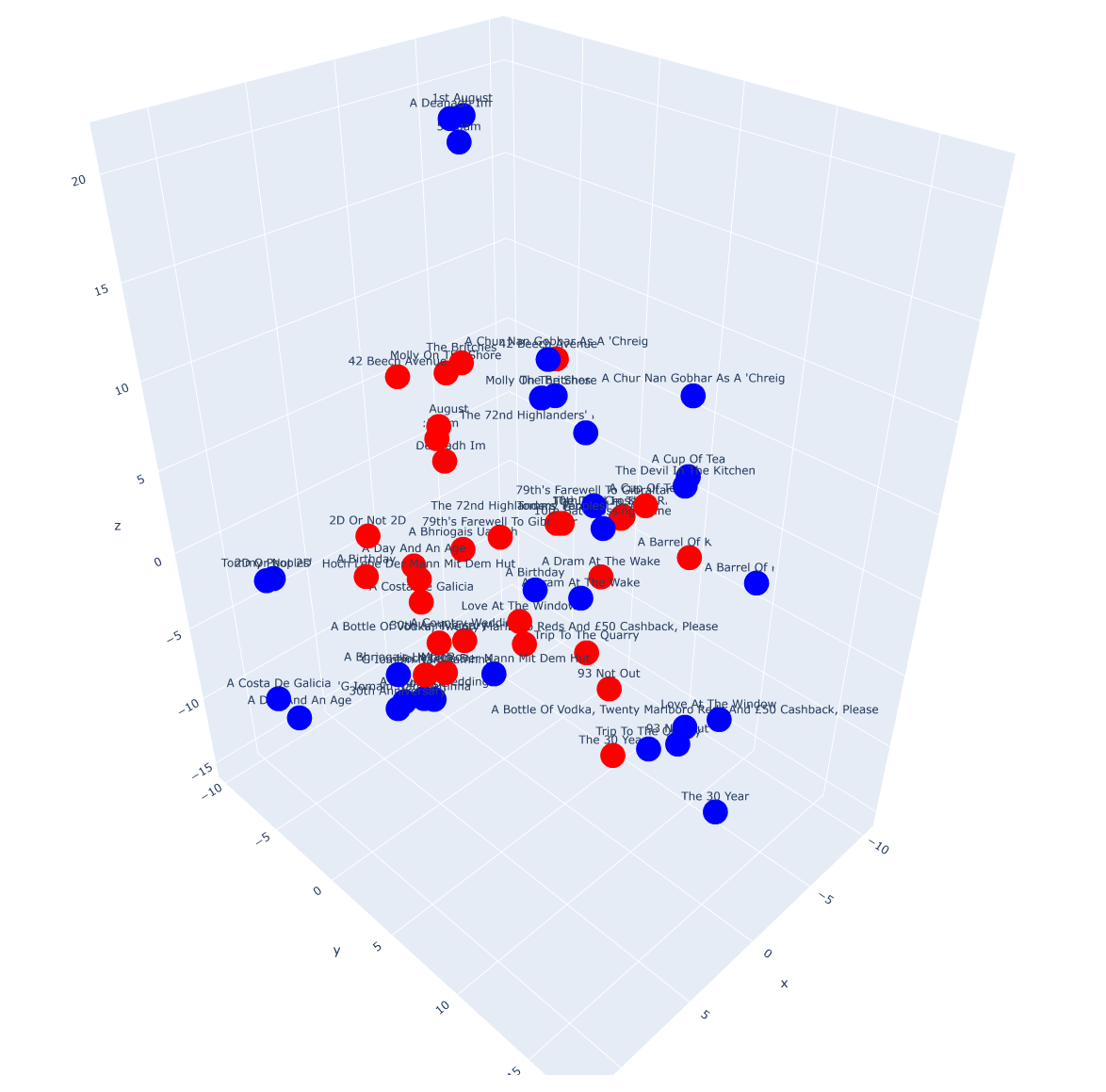
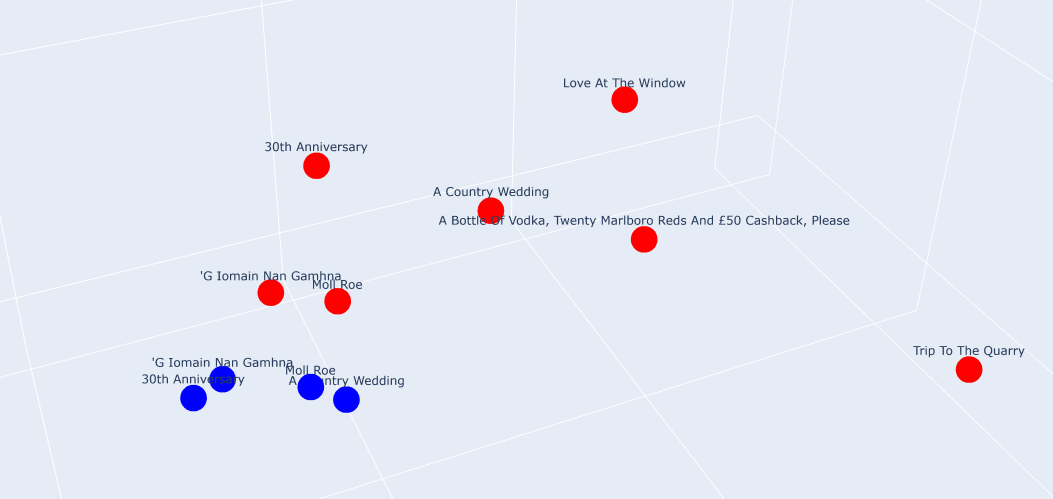
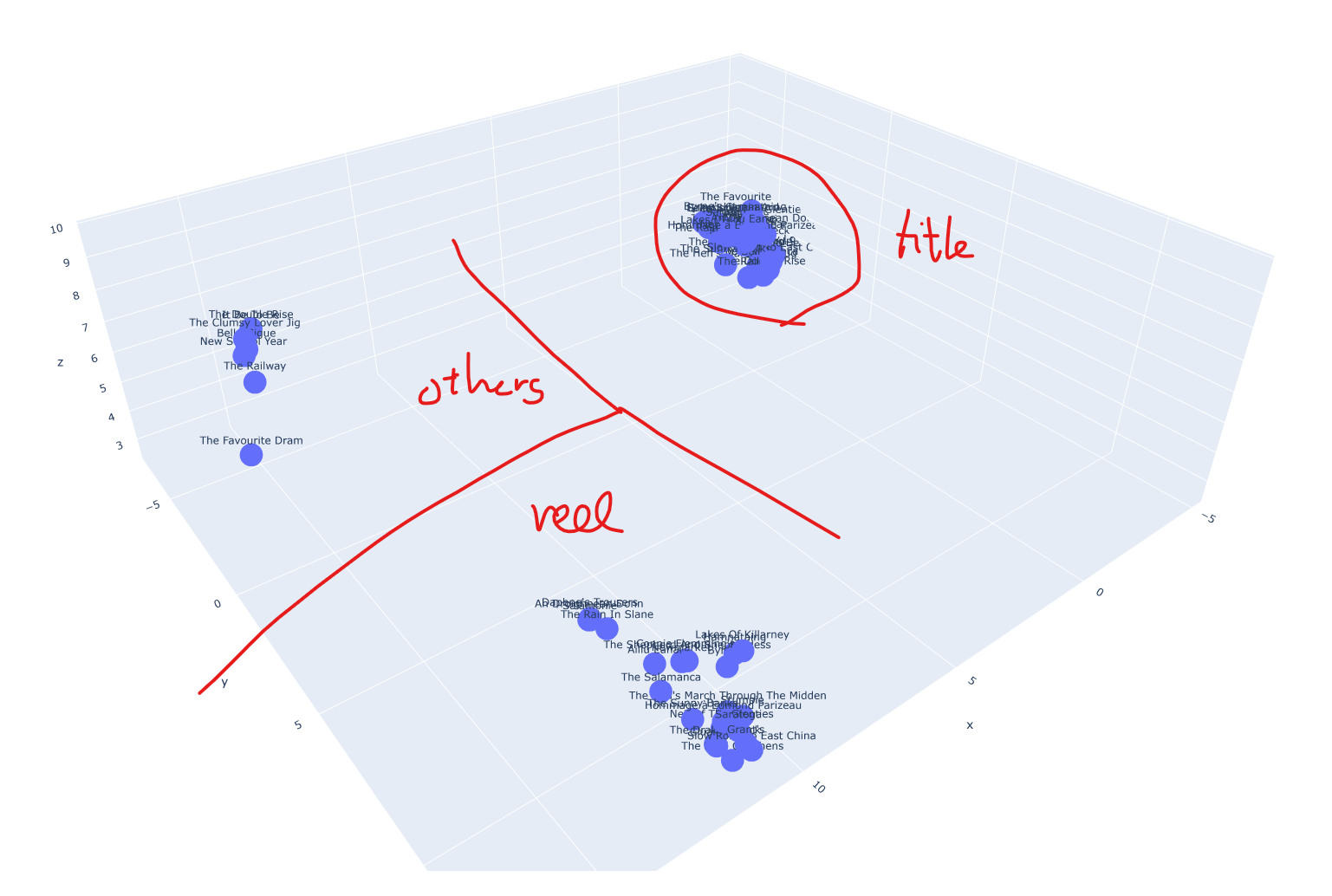
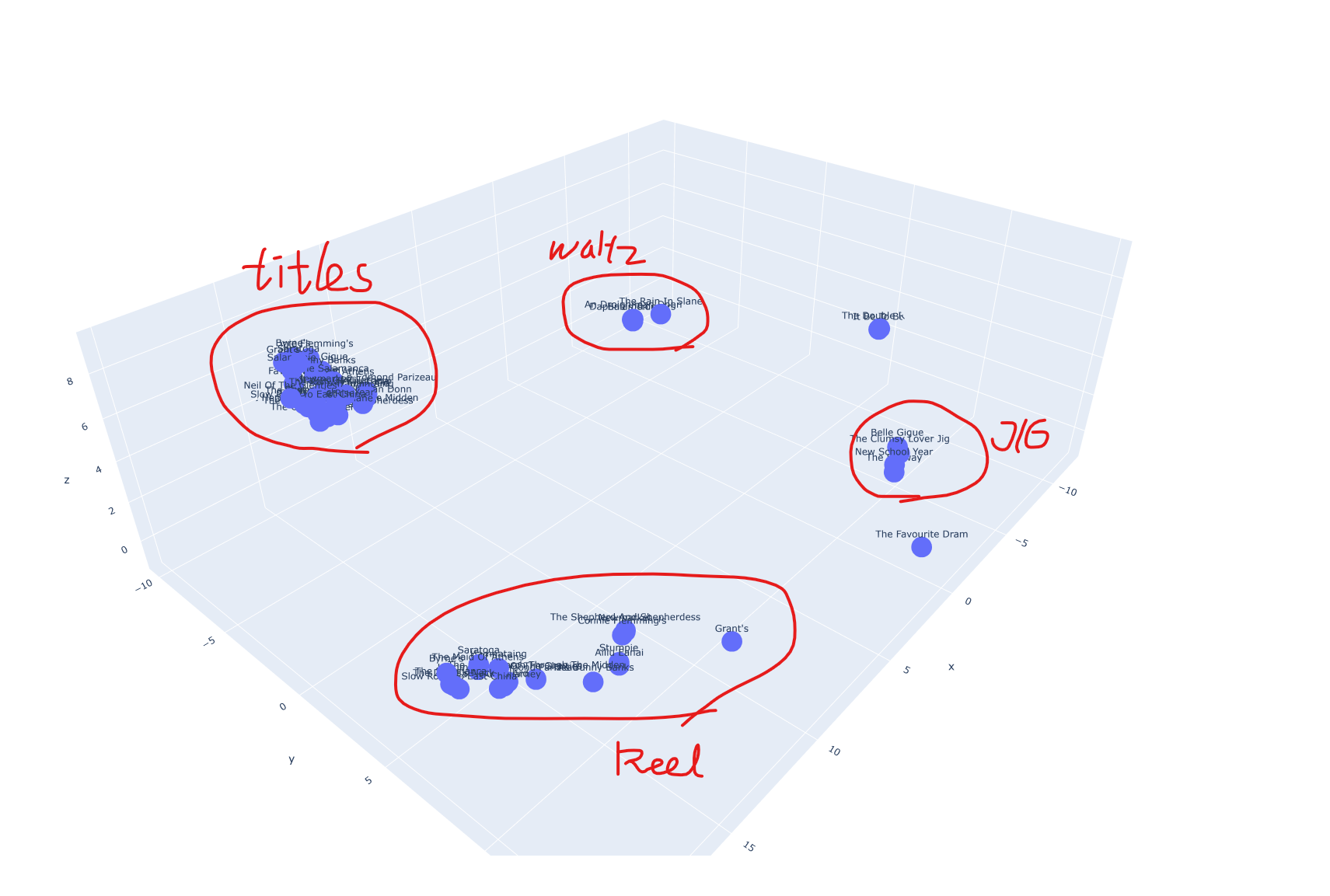
3D Plotting using UMAP
Normalize를 하고
# normalize the embeddings
emb_abc_norm = emb_abc / emb_abc.norm(dim=1, keepdim=True)
emb_ttl_norm = emb_ttl / emb_ttl.norm(dim=1, keepdim=True)
emb_all_norm = torch.cat([emb_abc_norm, emb_ttl_norm], dim=0)묶어서 차원 축소를 해주었다.
reducer_3d = umap.UMAP(n_components=3)
emb_reduced_3d = reducer_3d.fit_transform(emb_all_norm.detach().cpu().numpy())0 epoch with title
8000 epoch with title
3D Plotting using TSNE