My Objectives
I. Check validities through the paper : with explicit assumptions
II. Review Framework & Algorigthm : implicit assumptions
(III. Examine experiments methods : feasibility of proving the hypotheses)
CP review
Abstract
Background knowledge
one has to represent a piece of music, by a sequence of tokens drawn from a finite set of pre-defined vocabulary. Such a vocabulary usually involves tokens of various types. ... existing models usually treat them equally, in the same way as modeling words in natural languages.
(why not in languages? grammatical role (noun, verb, adjective, etc.), Named Entity Recognition (NER))
contirbutions
- we present a conceptually different approach that explicitly takes into account the type of the tokens, such as note types and metric types
- we propose a new Transformer decoder architecture that uses different feed-forward heads to model tokens of different types.
- extended Pop piano cover dataset
- compared to state-of-the-art models, the proposed model converges 5–10 times faster at training, and with comparable quality in the generated music.
Related Works
from Compound Word Transformer by Wen at el., linkcomparison, what is different
- Yet, instead of predicting them at different time steps, we predict multiple tokens of various types at once in a single time step
- From a theoretical point of view, the proposed model can be interpreted as a learner over discrete-time dynamic directed hypergraphs
(why the hypergraph theory is sited?)
why compound word representation
- we can now use different loss functions, sampling policies, and token embedding sizes for different token types.
- as a compound word represents multiple tokens at once, it requires much less time steps to generate a music piece using compound words
- it is possible to add new token types (by adding the corresponding feed-forward head) to increase the expressivity of the representation, without increasing the sequence length.
Linear Transformer
Kernel Function
Kernel function is kind of super-non-linear function. It is a concept commonly used in machine learning and especially in the context of support vector machines (SVMs) and other kernel methods. It allows you to implicitly perform computations in a higher-dimensional space without explicitly transforming the data into that space. This is often used for introducing non-linearity into algorithms that inherently operate in linear spaces.
from session explaining Linear transformer, link
converting sim into kernel function
sim(x,y)=ϕ(x)T*ϕ(y)check this explanation for detailed one, link
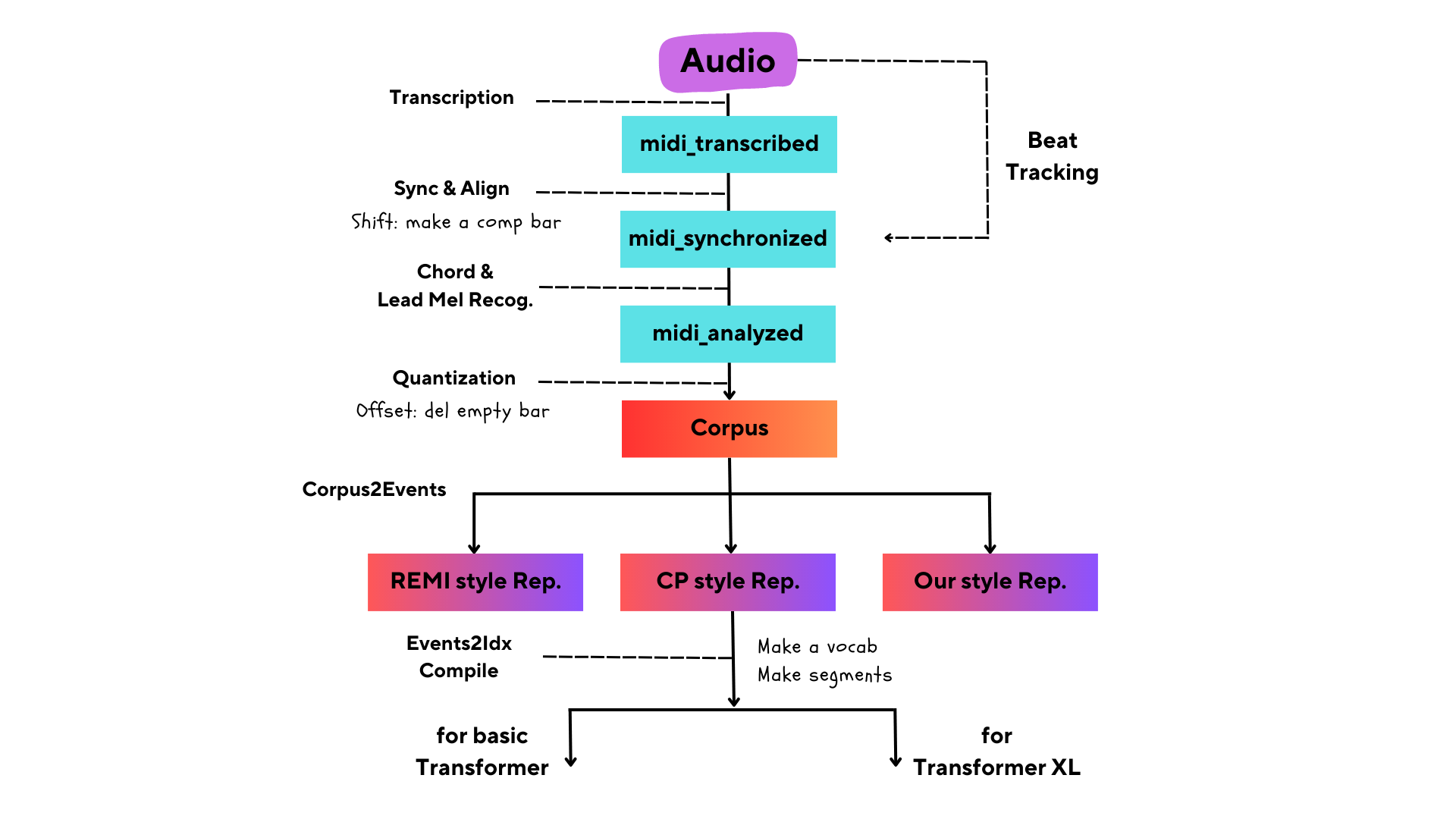
Methodology
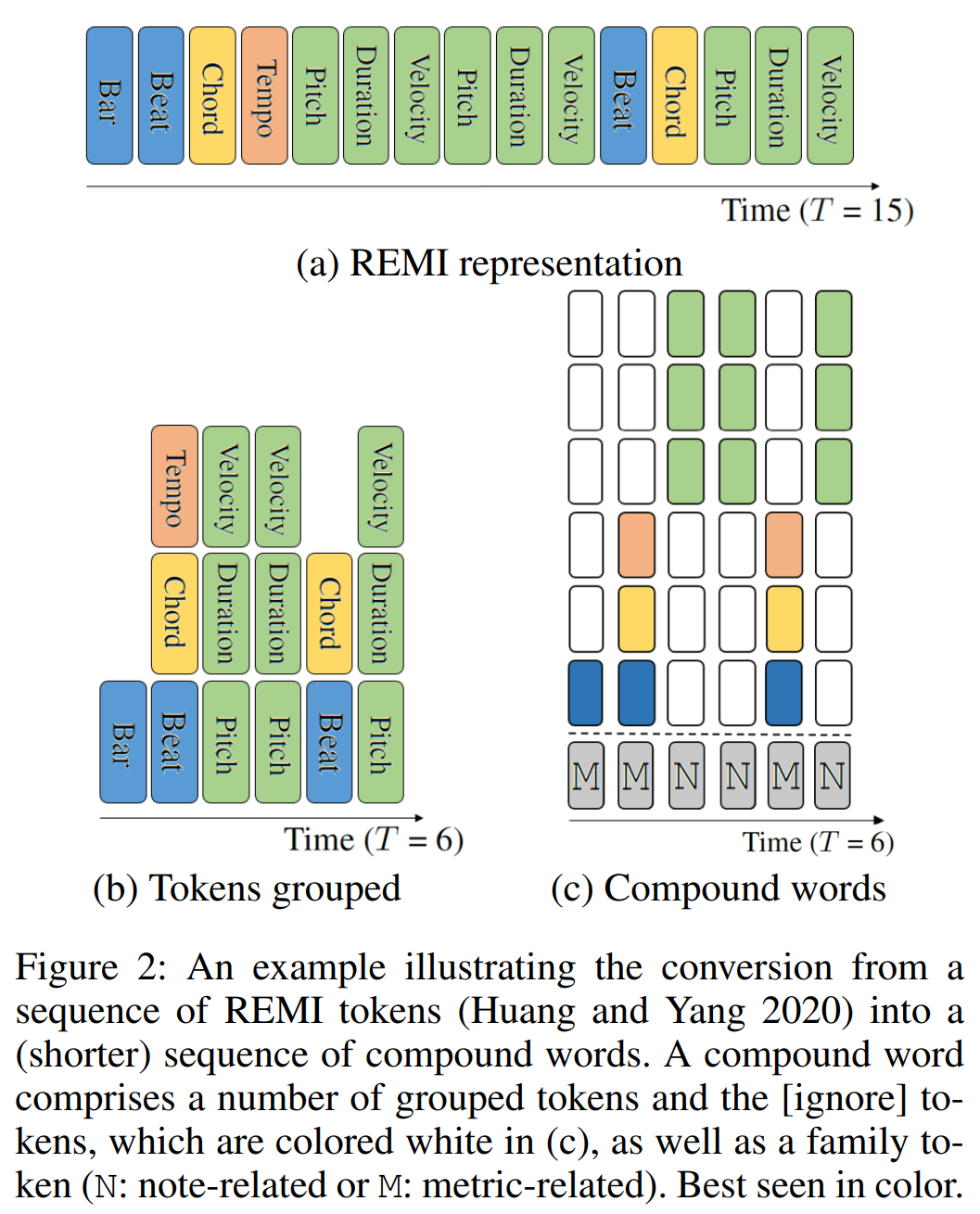
Events in the process of encoding
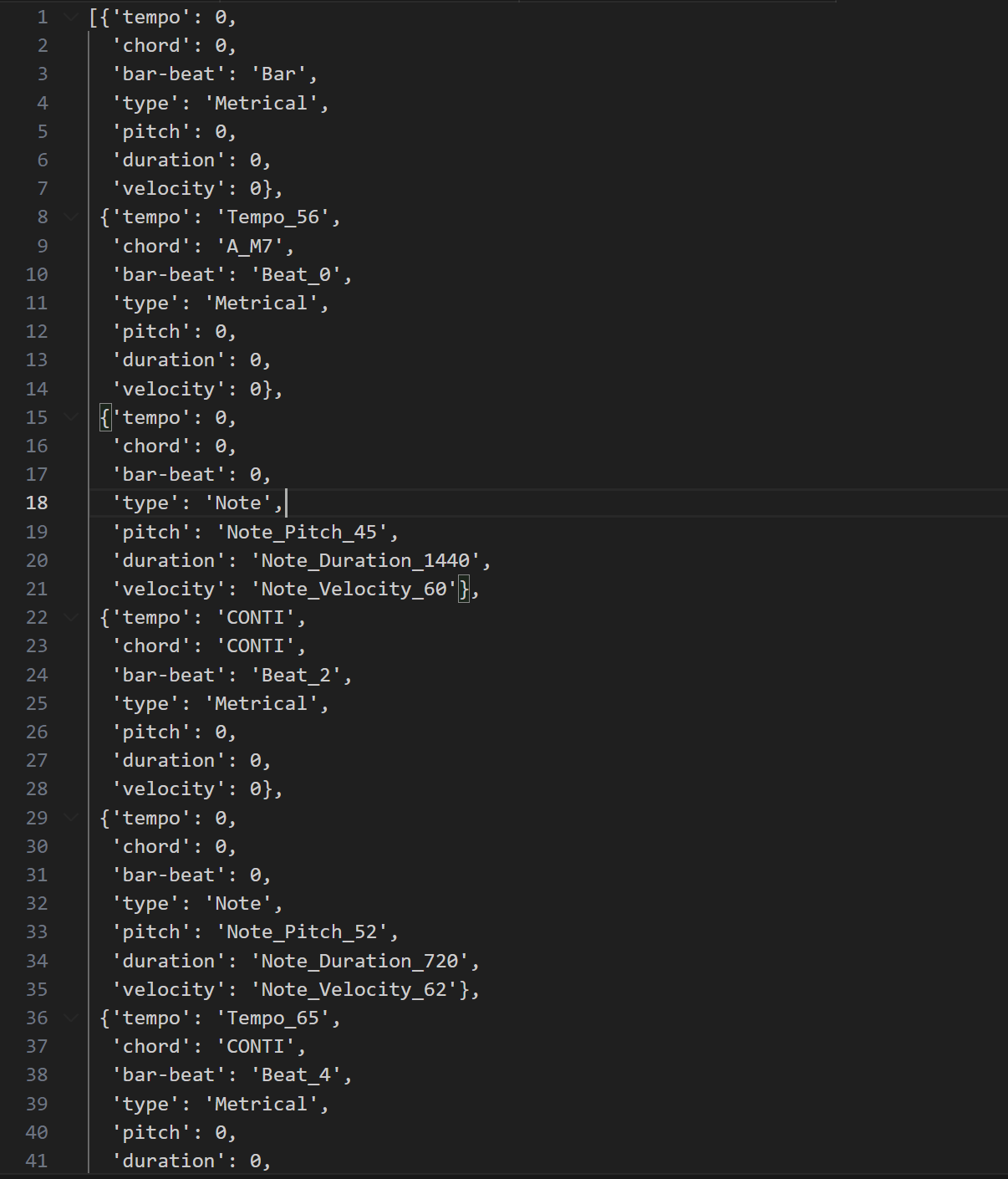
(why they used CONTI instead of actual information?)
Framework & Algorithms
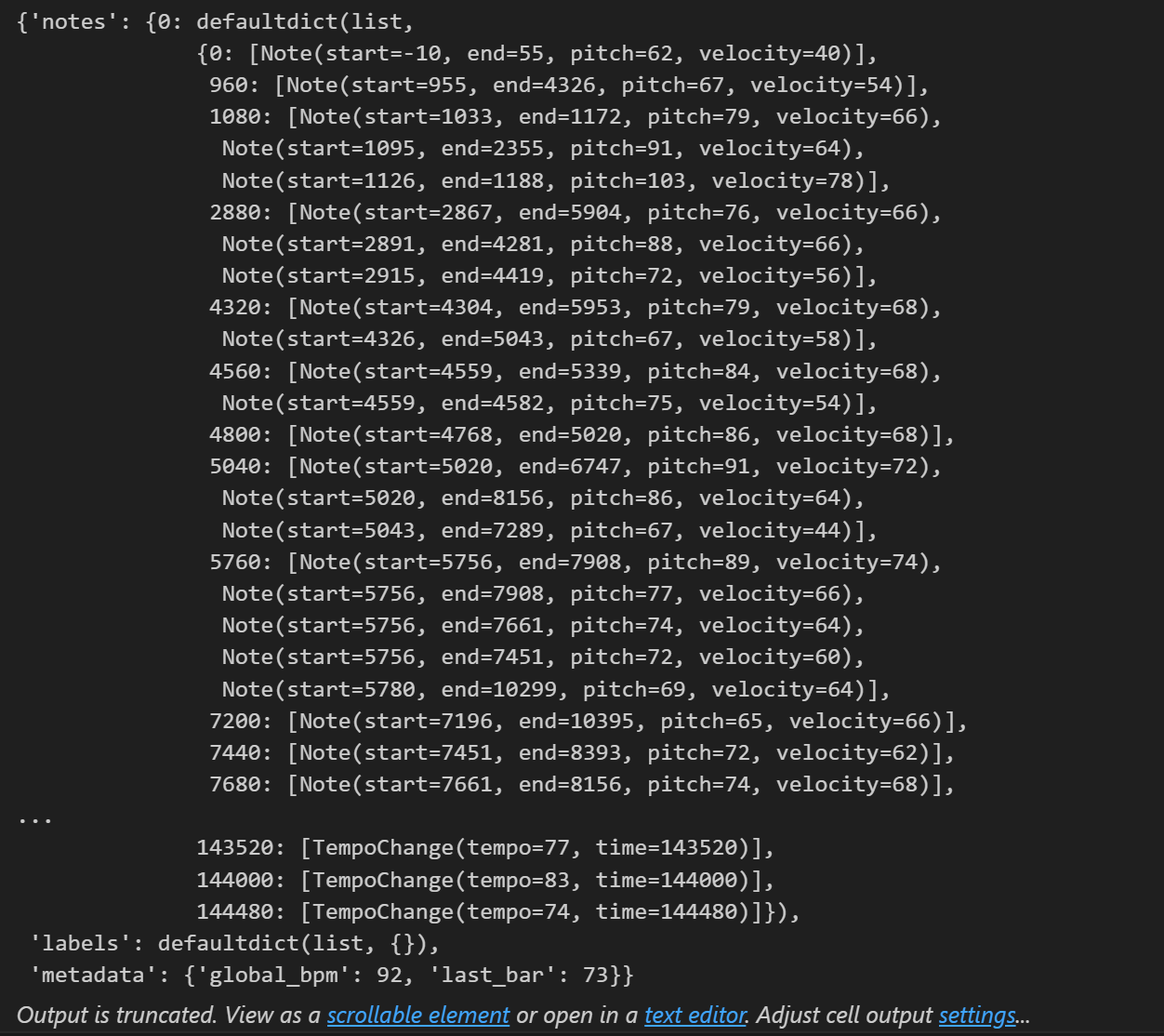
Corpus
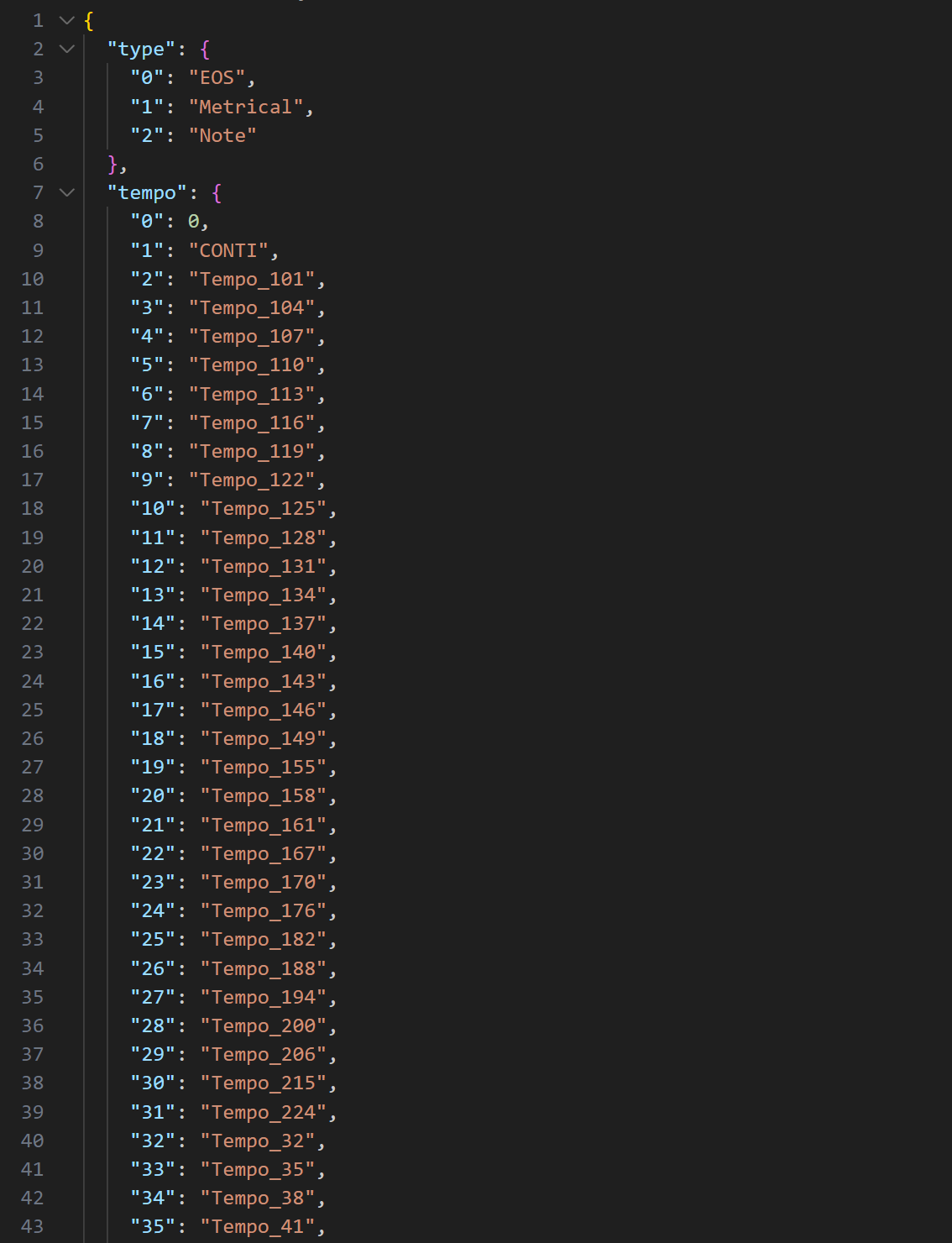
vocab
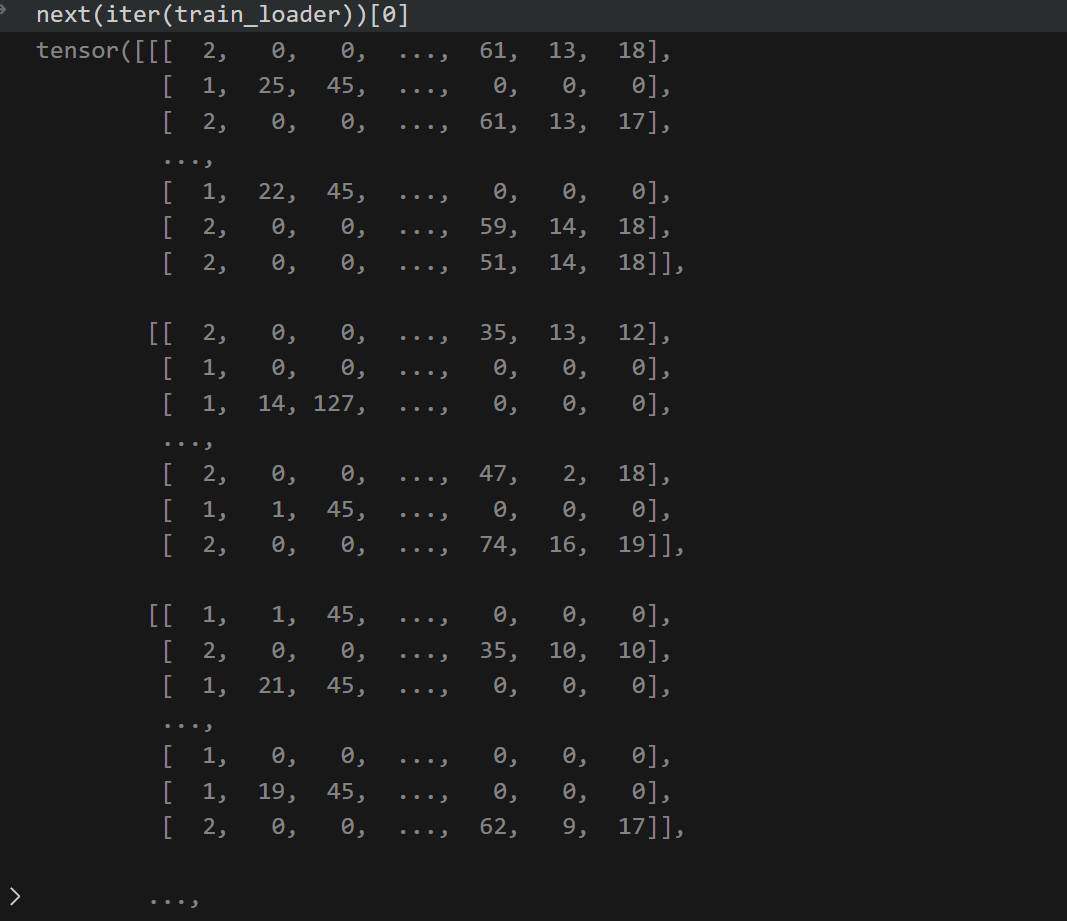
Compiled samples
Trained Results
CP representation + Vanilla Transformer
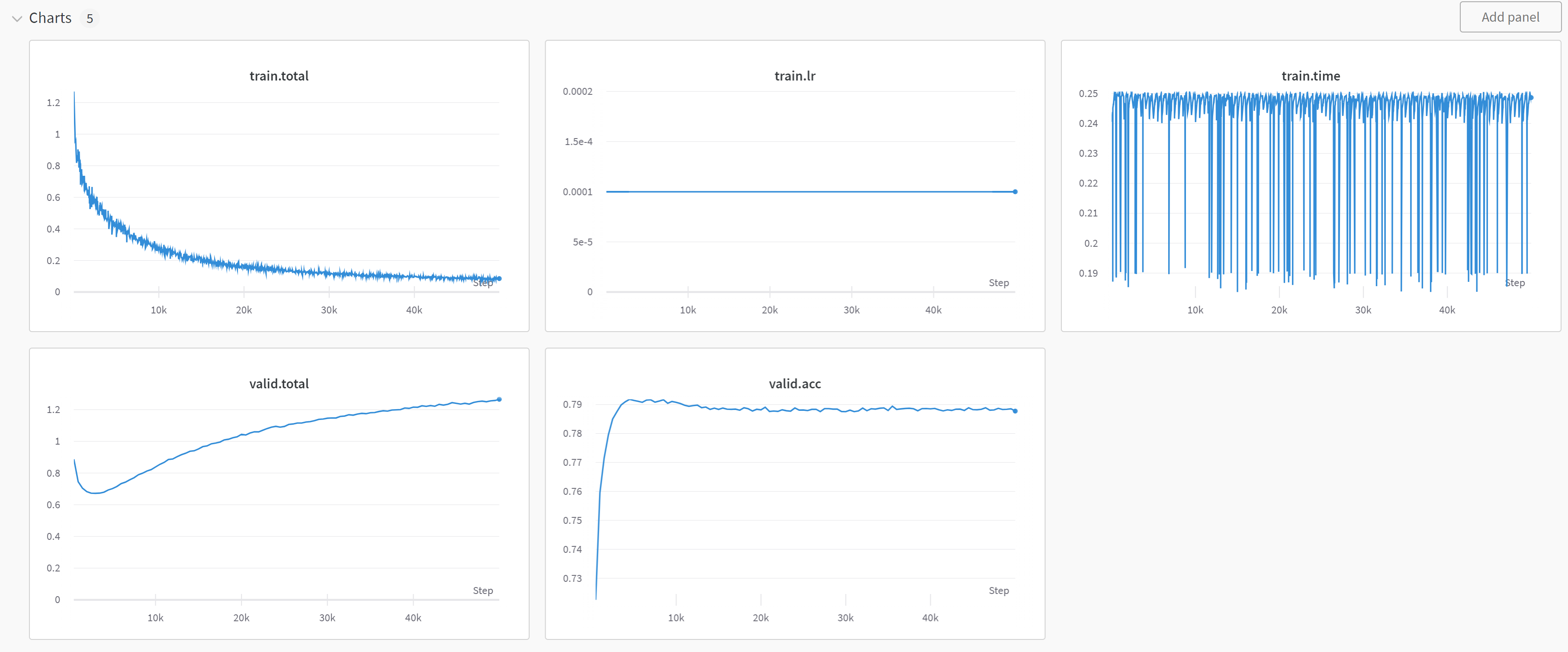
Generated Outputs
I recontructed the overwhole codes(cp style) with encoding midi into tokens, and decoding generated tokens into midi with vanilla transformer. You can check our generated outputs from following links.
https://youtu.be/l6MQhMDSYns?si=BXk3DnfBcH38ZvJN
Check points
- using CONTI
- predict each types sequentially (not only type token)
- calculating loss with more detail (differently by token types)
- other evaluation methods (especially to apply for ours)
- about changing dataset
- 4 beats only, homophonic vs. adding 3 beats, polyphonic
