Kaggle을 써보는게 처음이라 아래의 튜토리얼을 참고 했다.
https://kaggle-kr.tistory.com/18?category=868316
다만 중요한 내용이나 앞으로 자주 사용할 것 같은 내용들은 따로 정리해보려고한다.
Kaggle에서 데이터 셋을 받아와서 EDA를 통해 target label과 관련이 있을법한 feature들을 알아보고 그 후에 feature의 실제 데이터들에 결함이 없는지를 보완하는 과정이었다. 이 데이터 전처리의 과정이 상당히 오래걸려서 그런지 실제 모델의 학습과 예측은 컴퓨터에 모든걸 맡기는 편한(?) 과정으로 느껴졌다.
과정
1. 준비하기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('seaborn')
sns.set(font_scale=2.5)
import missingno as msno
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
df_train = pd.read_csv('train.csv')
df_test = pd.read_csv('test.csv')2. 데이터 톺아보기
.head()는 생략
2-1.Null데이터
msno.bar(df=df_train.iloc[:,:], figsize=(8,8), color=(0.8,0.5,0.2))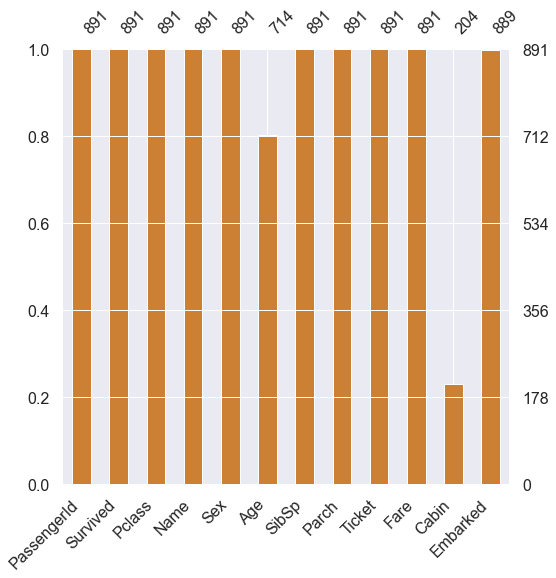
msno.bar(df=df_test.iloc[:,:], figsize=(8,8), color=(0.8,0.5,0.2))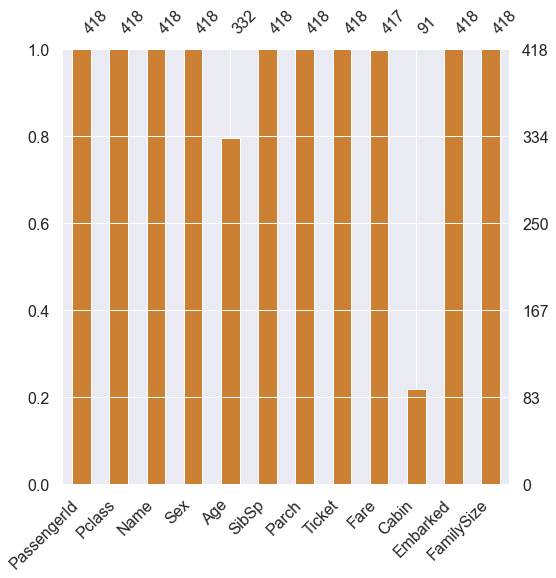
2-2.Target label
df_train['Survived'].value_counts()
sns.countplot('Survived',data=df_train)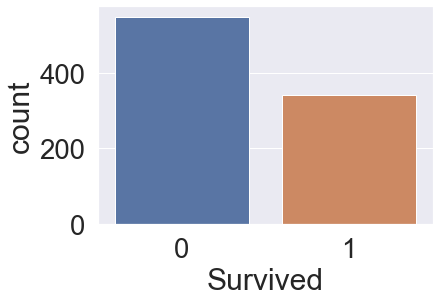
3. Exploratory Data Analysis
f, ax = plt.subplots(1, 2, figsize=(18, 8))
sns.countplot('Pclass', data=df_train, ax=ax[0])
sns.countplot('Pclass', hue='Survived', data=df_train, ax=ax[1])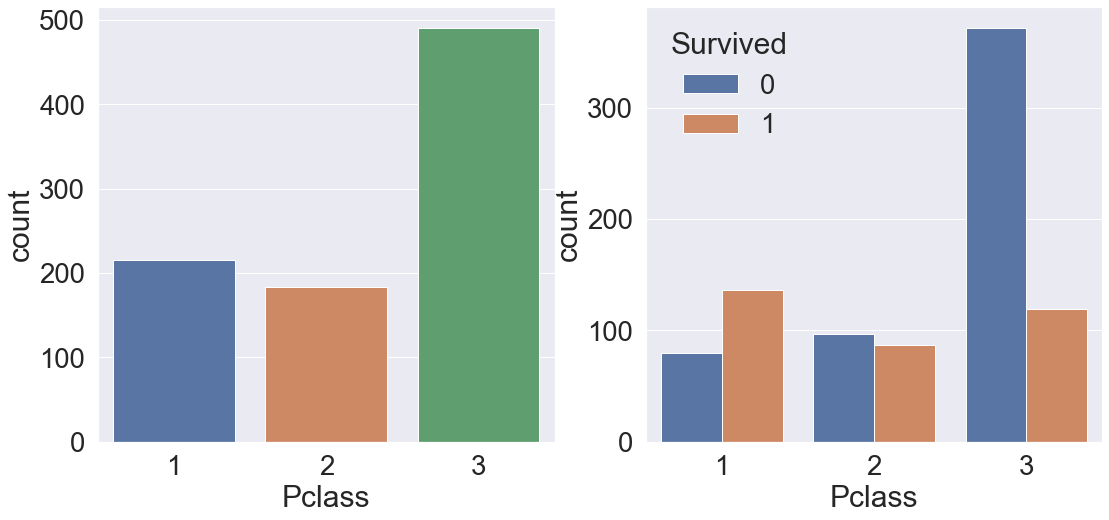
sns.factorplot('Pclass','Survived',hue='Sex',data=df_train, aspect=1.5)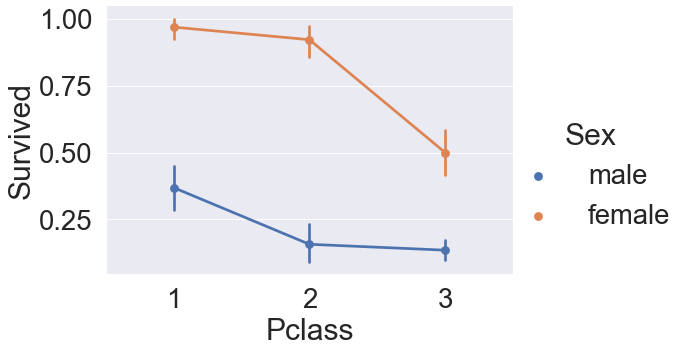
f, ax = plt.subplots(1,1, figsize=(9,5))
sns.kdeplot(df_train[df_train['Survived']==1]['Age'], ax=ax)
sns.kdeplot(df_train[df_train['Survived']==0]['Age'], ax=ax)
plt.legend(['Survived==1','Survived==0'])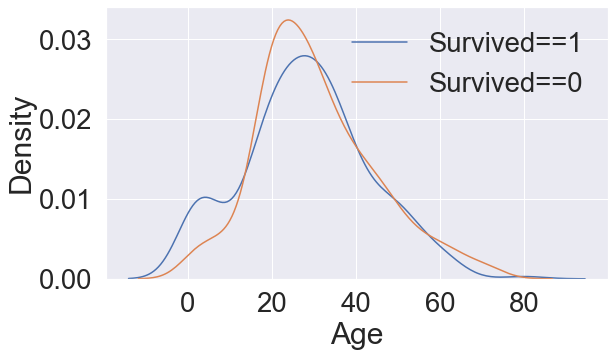
4. Null
4-1.fare Null 값 채우기
df_test.loc[df_test.Fare.isnull()]
#Pclass 3의 평균값을 대입
df_test.loc[df_test.Fare.isnull(), 'Fare'] = 124-2.outlier dkew 정도 조정
df_train['Fare'].skew() # 4.78
df_train['Fare'].sort_values()
df_train['Fare'] = df_train['Fare'].map(lambda i : np.log(i) if i > 0 else 0)
df_test['Fare'] = df_test['Fare'].map(lambda i : np.log(i) if i > 0 else 0)4-3.Fill null in age
정규표현식의 사용
df_train['Initial'] = df_train.Name.str.extract('([A-Za-z]+)\.')
df_test['Initial']= df_test.Name.str.extract('([A-Za-z]+)\.') #lets extract the Salutations
# 이름에 들어가는 호칭을 따로 만들어주고
df_train[['Initial', 'Sex']].value_counts()
df_train['Initial'].replace(['Mlle','Mme','Ms','Dr','Major','Lady','Countess','Jonkheer','Col','Rev','Capt','Sir','Don', 'Dona'],
['Miss','Miss','Miss','Mr','Mr','Mrs','Mrs','Other','Other','Other','Mr','Mr','Mr', 'Mr'],inplace=True)
# 호칭에 따른 평균 나이대를 계산한뒤
df_train.groupby('Initial').mean()
# 호칭에 따라 비어있는 age에 평균 나이대를 넣어준다.
df_train.loc[(df_train.Age.isnull())&(df_train.Initial=='Mr'), 'Age'] = 33
df_train.loc[(df_train.Age.isnull())&(df_train.Initial=='Mrs'),'Age'] = 36
df_train.loc[(df_train.Age.isnull())&(df_train.Initial=='Master'),'Age'] = 5
df_train.loc[(df_train.Age.isnull())&(df_train.Initial=='Miss'),'Age'] = 22
df_train.loc[(df_train.Age.isnull())&(df_train.Initial=='Other'),'Age'] = 46
df_test.loc[(df_test.Age.isnull())&(df_test.Initial=='Mr'),'Age'] = 33
df_test.loc[(df_test.Age.isnull())&(df_test.Initial=='Mrs'),'Age'] = 36
df_test.loc[(df_test.Age.isnull())&(df_test.Initial=='Master'),'Age'] = 5
df_test.loc[(df_test.Age.isnull())&(df_test.Initial=='Miss'),'Age'] = 22
df_test.loc[(df_test.Age.isnull())&(df_test.Initial=='Other'),'Age'] = 464-4.Fill Null in Embarked
df_train['Embarked'].isnull().sum()
# S가 제일 많으니까..
df_train['Embarked'].fillna('S', inplace=True)5. 데이터 전처리
5-1.Change Age(Continuous to categorical)
- df.drop
사실 이건 없는게 더 좋을지도 모르겠다.
df_test['Age_cat'] = 0
df_test.loc[df_test['Age'] < 10, 'Age_cat'] = 0
df_test.loc[(10 <= df_test['Age']) & (df_test['Age'] < 20), 'Age_cat'] = 1
df_test.loc[(20 <= df_test['Age']) & (df_test['Age'] < 30), 'Age_cat'] = 2
df_test.loc[(30 <= df_test['Age']) & (df_test['Age'] < 40), 'Age_cat'] = 3
df_test.loc[(40 <= df_test['Age']) & (df_test['Age'] < 50), 'Age_cat'] = 4
df_test.loc[(50 <= df_test['Age']) & (df_test['Age'] < 60), 'Age_cat'] = 5
df_test.loc[(60 <= df_test['Age']) & (df_test['Age'] < 70), 'Age_cat'] = 6
df_test.loc[70 <= df_test['Age'], 'Age_cat'] = 7def category_age(x):
if x < 10:
return 0
elif x < 20:
return 1
elif x < 30:
return 2
elif x < 40:
return 3
elif x < 50:
return 4
elif x < 60:
return 5
elif x < 70:
return 6
else:
return 7
df_train['Age_cat'] = df_train['Age'].apply(category_age)df_train.drop(['Age'], axis=1, inplace=True)
df_test.drop(['Age'], axis=1, inplace=True)5-2.Initial, Embarked, Sex를 string to numerical
- df.map
df_train['Initial'] = df_train['Initial'].map({'Master':0, 'Miss':1, 'Mr':2, 'Mrs':3, 'Other':4})
df_test['Initial'] = df_test['Initial'].map({'Master':0, 'Miss':1, 'Mr':2, 'Mrs':3, 'Other':4})df_train['Embarked'] = df_train['Embarked'].map({'C':0,'Q':1,'S':2})
df_test['Embarked'] = df_test['Embarked'].map({'C':0,'Q':1,'S':2})df_train['Sex'] = df_train['Sex'].map({'female': 0, 'male': 1})
df_test['Sex'] = df_test['Sex'].map({'female': 0, 'male': 1})5-3.corr
heatmap_data = df_train[['Survived', 'Pclass', 'Sex', 'Fare', 'Embarked', 'FamilySize', 'Initial', 'Age_cat']]
colormap = plt.cm.RdBu
plt.figure(figsize=(14,12))
plt.title('Pearson Correlation of Features', y=1.05, size=15)
sns.heatmap(heatmap_data.astype(float).corr())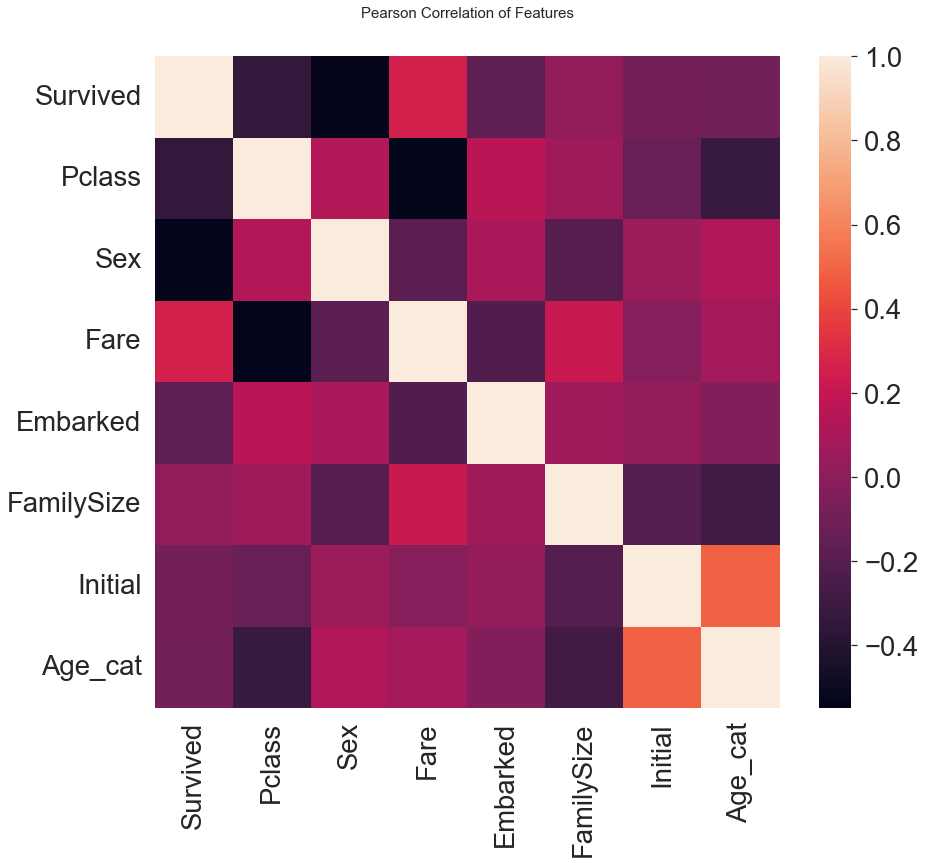
6. One-hot encoding
- df.get_dummies
df_train = pd.get_dummies(df_train, columns=['Initial'], prefix='Initial')
df_test = pd.get_dummies(df_test, columns=['Initial'], prefix='Initial')
df_train = pd.get_dummies(df_train, columns=['Embarked'], prefix='Embarked')
df_test = pd.get_dummies(df_test, columns=['Embarked'], prefix='Embarked')7. Model
7-1. drop으로 데이터 정리
df_train.drop(['PassengerId', 'Name', 'SibSp', 'Parch', 'Ticket', 'Cabin'], axis=1, inplace=True)from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
from sklearn.model_selection import train_test_split
target_label = df_train['Survived'].values
X_train = df_train.drop('Survived', axis=1).values
X_test = df_test.values7-2. train_test_split
X_tr, X_vld, y_tr, y_vld = train_test_split(X_train, target_label, test_size=0.3, random_state=2018)7-3. model generation
model = RandomForestClassifier()
model.fit(X_tr, y_tr)
prediction = model.predict(X_vld)
print('총 {}명 중 {:.2f}% 정확도로 생존을 맞춤'.format(y_vld.shape[0], 100 * metrics.accuracy_score(prediction, y_vld)))8. Prediction on Test set
submission = pd.read_csv('gender_submission.csv')
prediction = model.predict(X_test)
submission.to_csv('./my_first_submission.csv', index=False)
chords & code // harmony with structure