ML 기초 실습 과제를 토요일에.. 풀어보는 시간을 가졌다. 내용은 아래와 같다.
1.이번 과제를 통해 여러분은 음식배달 서비스(배민, 쿠팡이츠 등)를 위한 예측모델을 만들게 될 것입니다! 이 모델이 예측하는 값은 “음식배달에 걸리는 시간"입니다. 배달시간을 정확하게 예측하는 것은 사용자의 경험에 많은 영향을 미치게 됩니다.
2.예측된 배달시간보다 실제 배달시간이 더 걸린 경우(under-prediction)가 반대의 경우(over-prediction)보다 두 배로 사용자의 경험에 안 좋은 영향을 준다고 알려져 있습니다.
3.가능한 실제 배달시간과 가까운 값을 예측하되 동시에 under-prediction을 최소화하는 것이 좋은 예측모델입니다.
데이터(delivery_raw.csv)에서 랜덤하게 10%를 추출해서 테스트 데이터로 사용하고 나머지는 학습데이터로 사용하세요.
데이터 처리
df_train.head(5)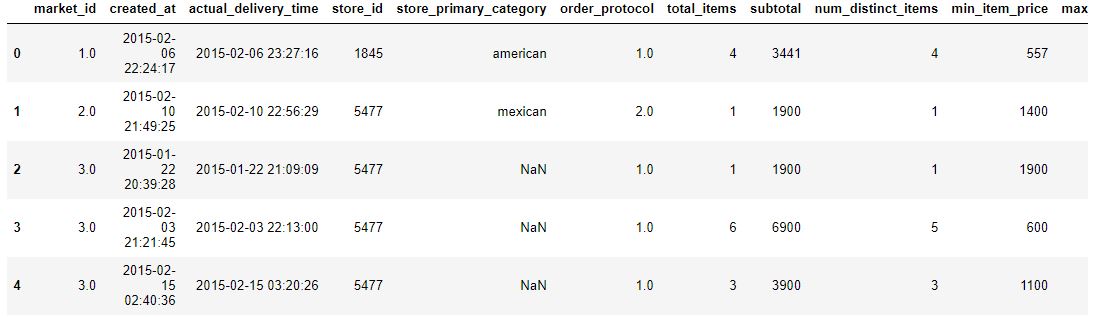
우선 created_at과 actual_delivery_time이 object dtype이기에 이 둘을 time으로 바꾸어주고 빼주었다.
df_train['created_at_time'] = pd.to_datetime(df_train['created_at'])
df_train['actual_delivery_time_time'] = pd.to_datetime(df_train['actual_delivery_time'])
df_train['diff'] = df_train['actual_delivery_time_time'] - df_train['created_at_time']
df_train['delivery_seconds'] = df_train['diff'].dt.total_seconds()그리고 시간 중에서 NaN인 값이 있는 데이터들을 정리하고 7200초 즉 2시간이 넘는 데이터(배달이 2시간이 넘는다면 흠...)도 정리해주었다.
df_train2 = df_train[df_train['delivery_seconds']<=7200]
df_train2 = df_train2[df_train2['delivery_seconds']!='NaN']다음으로 이를 생성하는데 만들어진 필요가 없는 feature의 열들을 정리해주었다.
df_train2.drop(['created_at','actual_delivery_time','created_at_time','actual_delivery_time_time','diff'], axis=1, inplace=True)그리고 사실 이게 좀 실수였는데 어떤 종류의 음식을 만드는지가 배달 시간에 중요한 요소임에도 데이터 처리가 귀찮아서... store_primary_category를 정리해주었다. 아마 모델의 예측률이 떨어졌을 것이다. 하지만 괜찮다 나의 주말은 소중하니까!
df_train2.drop(['store_primary_category'], axis=1, inplace=True)
# 부가적으로 전혀 필요없는 feature도 정리
df_train2.drop(['store_id'], axis=1, inplace=True)시각화를 통한 상관관계 파악
heatmap으로 덜 중요한 feature를 확인후 정리해주었다.
heatmap_data = df_train2
colormap = plt.cm.RdBu
plt.figure(figsize=(28,18))
plt.title('Pearson Correlation of Features', y=1.05, size=15)
sns.heatmap(heatmap_data.astype(float).corr(), annot=True)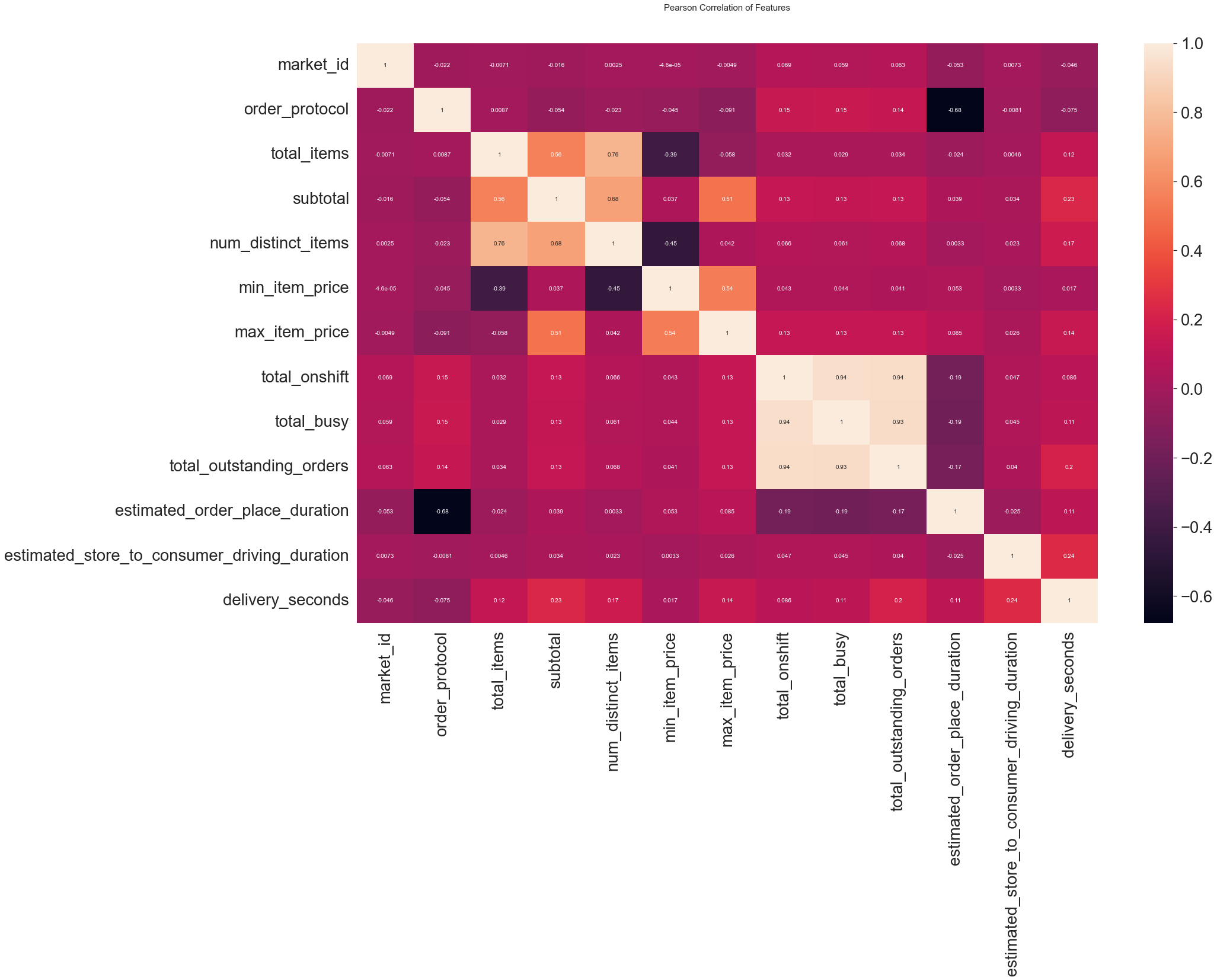
df_train2.drop(['market_id','order_protocol',], axis=1, inplace=True)NaN데이터 처리
상대적으로 중요한 feature들의 NaN값을 채워주기 위해 imputer를 사용했다. 그런데 다시 생각해보니 데이터가 엄청나게 많으니까 다 날려버리는 것도 괜찮았을 거 같다.
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='median')
# imputer를 처음 쓰는지라 백업을 했다.
df_train3 = df_train2.copy()
imputer.fit(df_train3)
# print(imputer.statistics_)
output = imputer.transform(df_train3)
output = pd.DataFrame(output, columns=df_train3.columns, index=list(df_train3.index.values))
output.describe()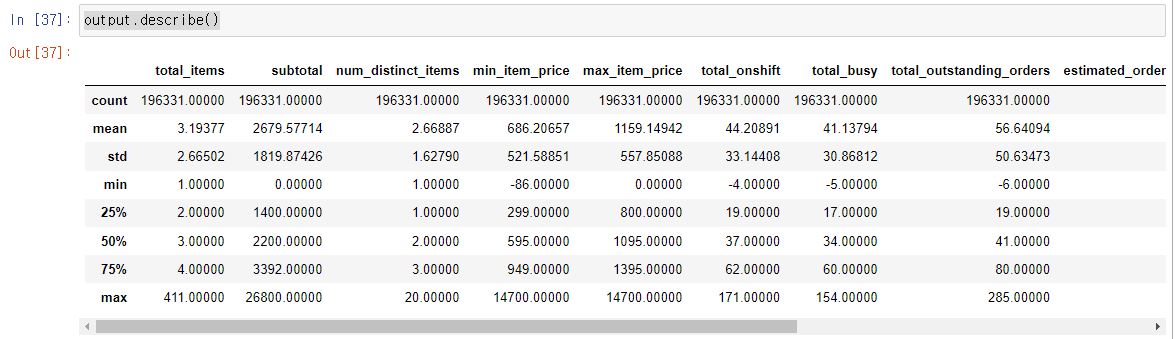
샘플링
이후에 테스트를 위한 데이터를 20프로정도 샘플링했다.
사용할 일은 없었다.
output0 = output.sample(frac=0.8, random_state=99)
output_test = output.drop(output0.index)모델링
LinearRegression을 사용하지만
from sklearn.linear_model import LinearRegression
from sklearn import metrics
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
target_label = output0['delivery_seconds'].values
X_train = output0.drop('delivery_seconds', axis=1).values
x_train, x_test, y_train, y_test = train_test_split(X_train, target_label, test_size=0.1, random_state=99)다른 모델들도 불러오고
from sklearn.linear_model import ElasticNet
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PolynomialFeatures모델의 성능을 확인하기 위한 함수도 불러왔다.
https://teddylee777.github.io/scikit-learn/scikit-learn-ensemble 참고
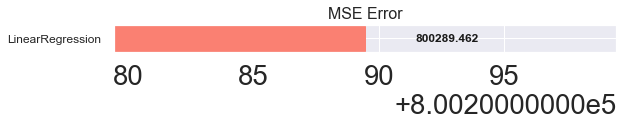
LinearRegression
800289라는 mse를 기록 이게 맞는건가 싶다.
linear_reg = LinearRegression()
linear_reg.fit(x_train, y_train)
pred = linear_reg.predict(x_test)
mse_eval('LinearRegression', pred, y_test)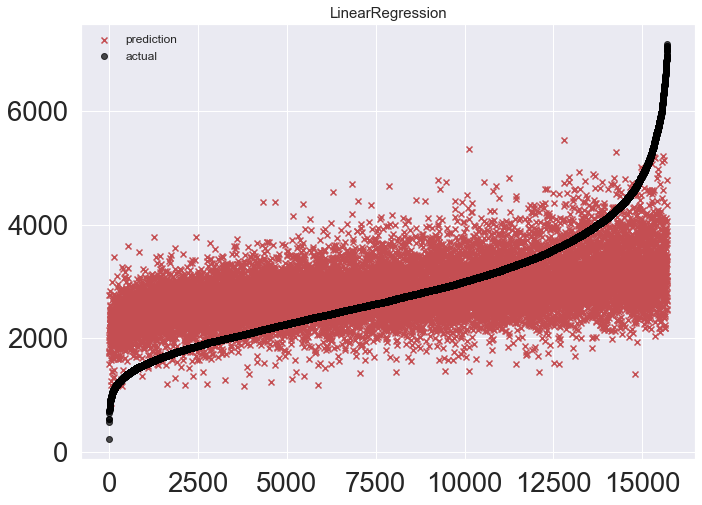
Poly ElasticNet
Ridge, Lasso, ElasticNet은 생략하고 이게 젤 성능이 좋았다.
poly_pipeline = make_pipeline(
PolynomialFeatures(degree=2, include_bias=False),
ElasticNet(alpha=0.1, l1_ratio=0.2)
)
poly_pipeline.fit(x_train, y_train)
poly_pred = poly_pipeline.predict(x_test)
mse_eval('Poly ElasticNet', poly_pred, y_test)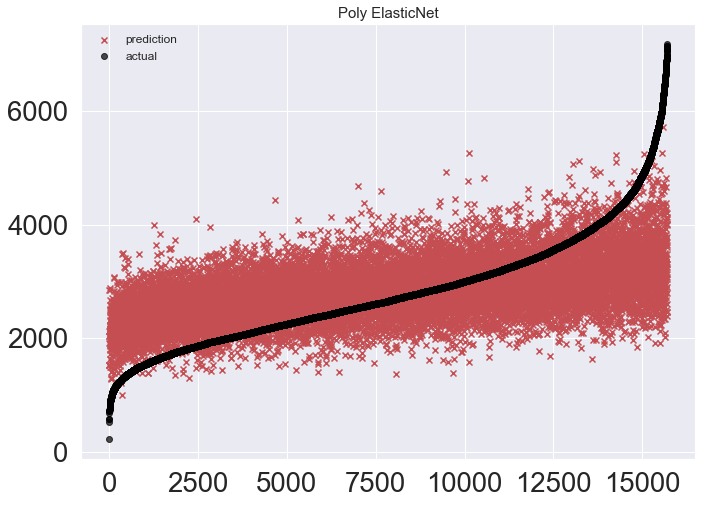

RandomForestRegressor
RFR 모델의 튜닝모델을 먼저 시도 했지만 참패... 오리지날이 더 좋았다.
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier
rfr_origin = RandomForestRegressor()
rfr_origin.fit(x_train, y_train)
rfr_origin_pred = rfr_origin.predict(x_test)
mse_eval('RandomForest', rfr_origin_pred, y_test)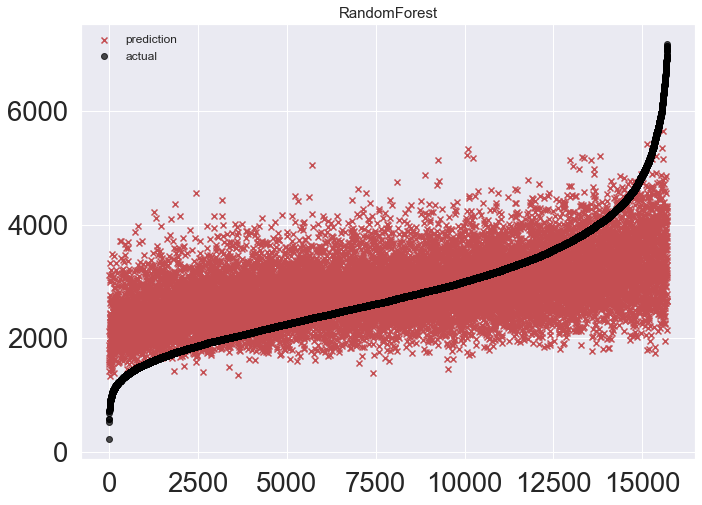
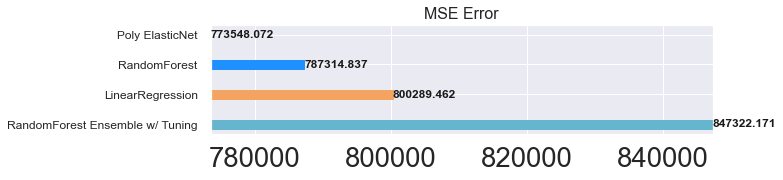
RandomForestRegressor tuning
오우 인위적이다.
rfr = RandomForestRegressor(random_state=99, n_estimators=180, max_depth=7, max_features=7)
rfr.fit(x_train, y_train)
rfr_pred = rfr.predict(x_test)
mse_eval('RandomForest Ensemble w/ Tuning', rfr_pred, y_test)

Analyze feature coefficients
어떤 feature의 영향력이 가장 클까?
train_features = [
'total_items',
'subtotal',
'num_distinct_items',
'min_item_price',
'max_item_price',
'total_onshift',
'total_busy',
'total_outstanding_orders',
'estimated_order_place_duration',
'estimated_store_to_consumer_driving_duration']features_scored = []
for feature, coef in zip(train_features, linear_reg.coef_):
features_scored.append((feature, coef))
features_scored.sort(key = lambda x: -abs(x[1]))
for feature, coef in features_scored:
print("{:50}: {:.2f}".format(feature, coef))
역시 빨리 먹고 싶으면 메뉴는 통일일까?
Under Prediction & RMSE
LinearRegression
count = 0
for gt, pr in zip(y_test, pred):
if gt > pr:
count += 1
print(count/len(y_test))
# Under prediction 0.42503342458776344
# RMSE: 894.5890Poly ElasticNet
count = 0
for gt, pr in zip(y_test, poly_pred):
if gt > pr:
count += 1
print(count/len(y_test))
# Under prediction 0.42579741516521297
# RMSE 879.5158168447RandomForestRegressor
count = 0
for gt, pr in zip(y_test, rfr_origin_pred):
if gt > pr:
count += 1
print(count/len(y_test))
# Under prediction 0.4152288788438276
# RMSE 887.3076338733935총평
어제 캐글 경진대회의 여파가 남아있다. 오늘의 공부는 여러 모델을 시도해본 것으로 만족해야할 것 같다. 특히 RFR모델의 parameter를 RandomizedSearchCV를 활용해서 찾아보려고 했는데 시간이 너무 오래걸려서 일단 보류했다. 사실 데이터 전처리부터 다시 하는게 맞는 것 같은데 하하... 아무튼 모델의 가치는 RFR이 Poly ElasticNet보다 더 나을 거 같기도 하다. Under Prediction을 낮추기 위해서 예측값에 임의로 5분 정도를 더해주고 싶긴한데 그래도 될런지 모르겠다.
reference
https://teddylee777.github.io/scikit-learn/scikit-learn-ensemble
https://teddylee777.github.io/scikit-learn/grid-search-%EB%A1%9C-hyperparameter%EC%B5%9C%EC%A0%81%ED%99%94
https://velog.io/@wbsl0427/%EC%9D%8C%EC%8B%9D-%EB%B0%B0%EB%8B%AC-%EC%84%9C%EB%B9%84%EC%8A%A4-%EB%B0%B0%EB%8B%AC%EC%8B%9C%EA%B0%84-%EC%98%88%EC%B8%A1
https://stackoverflow.com/questions/40992976/python-convert-datetime-column-into-seconds
https://github.com/dengl11/Doordash-DataSicence-Project/blob/master/src/main.ipynb
