Batch Normalization
forward
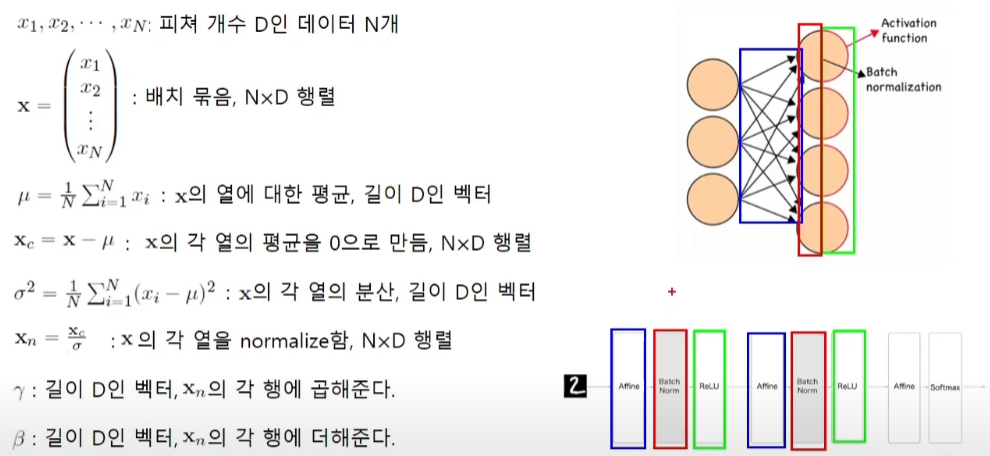
u값과 sigma 값을 구해서 데이터의 값을 normalize를 해주고 이를 gamma값을 확대를 하고, beta값으로 이동시킨 값이 배치 정규화 값이다.
gamma beta를 쓰는 이유는 평균이 0이고 표준편차가 1인 분포가 학습에 유리한 값이 아니기 때문이다. 머신은 학습시에 최적의 gamma beta값을 찾게 된다.
backward
Repeat 노드와 Sum 노드
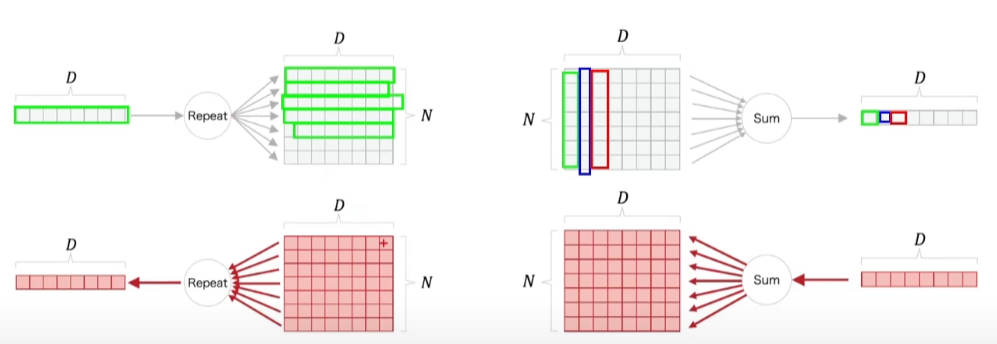
역전파 과정
초록색은 broad casting 계산이 이루어지는 Repeat 노드이다.
따라서 dout이 초록색을 지날때는 Sum을 해주어야 한다.
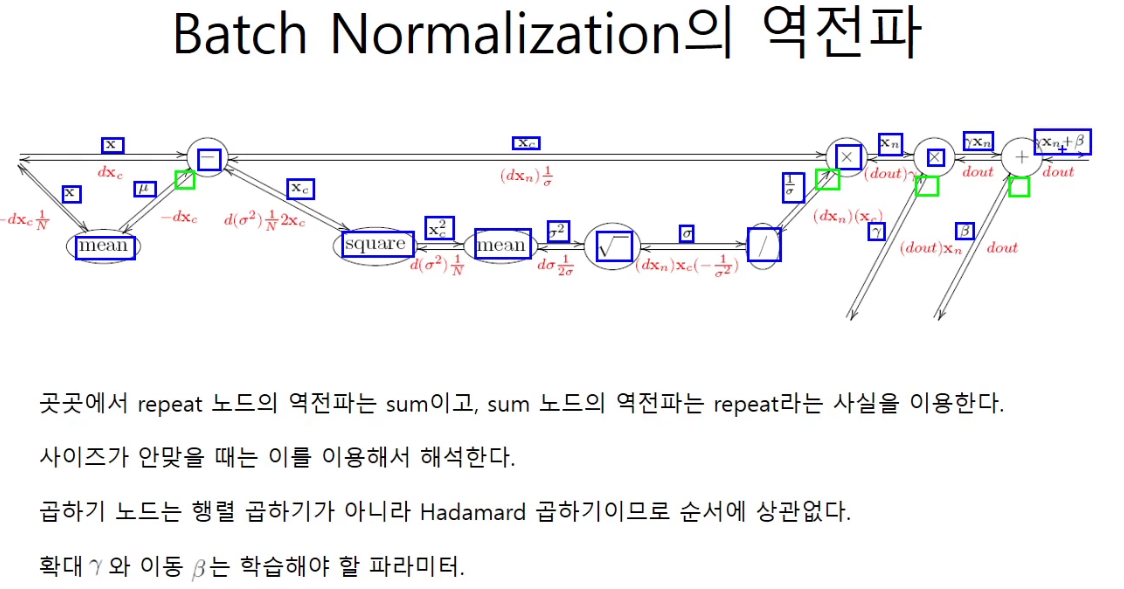
normalize 부분의 역전파
다시 한번 역전파를 정리해보자. 흘러들어온 dout은 그 자리의 변수로 f(x,y,z,n,t,...)을 미분한 값과 동일하다.
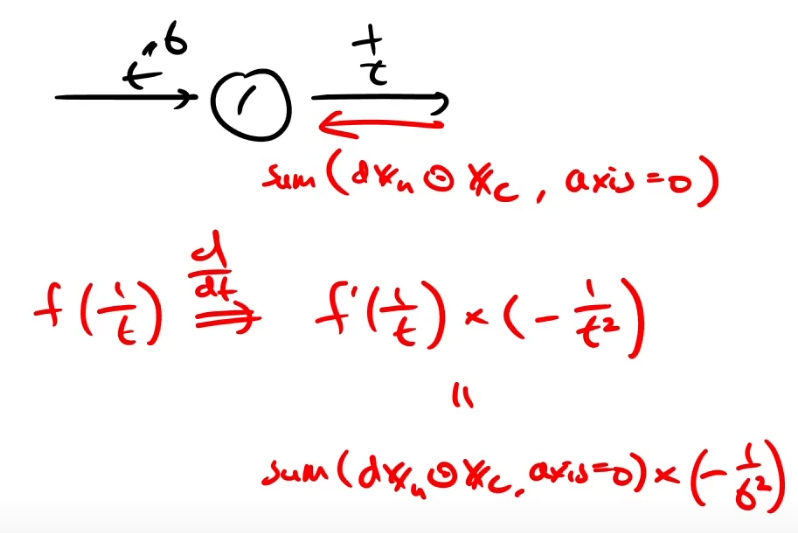
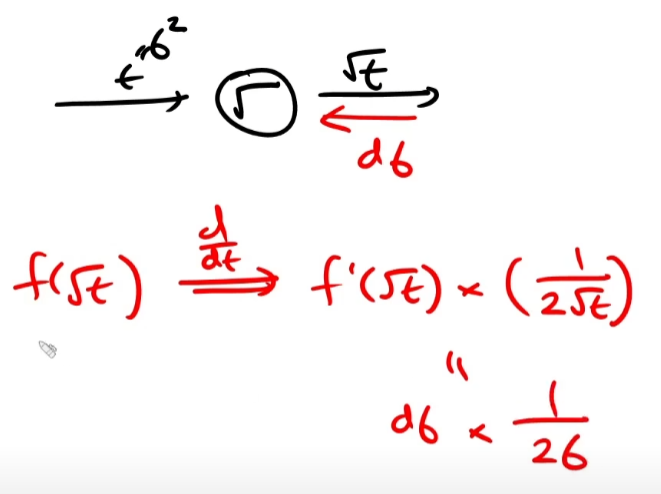
mean 노드는 sum 노드이므로 미분하게 되면 repeat노드가 된다.
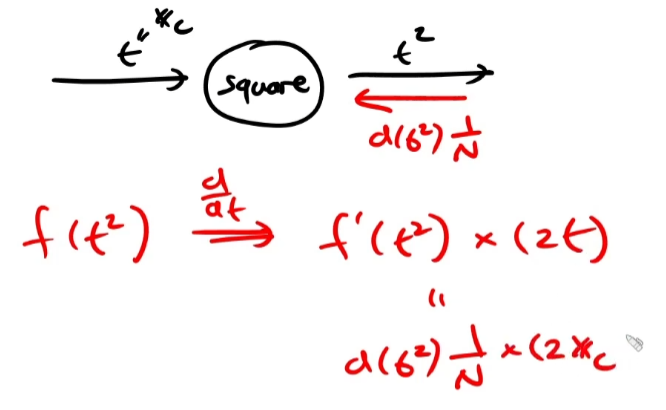
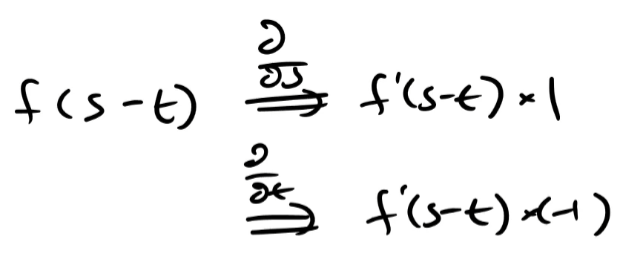
연습문제
repeat node를 역전파시에 sum하는 것이 핵심이다.
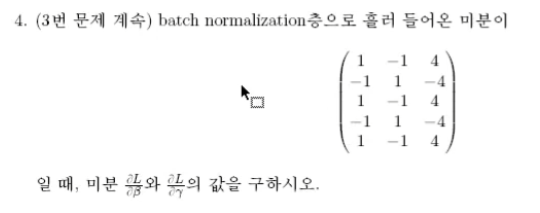
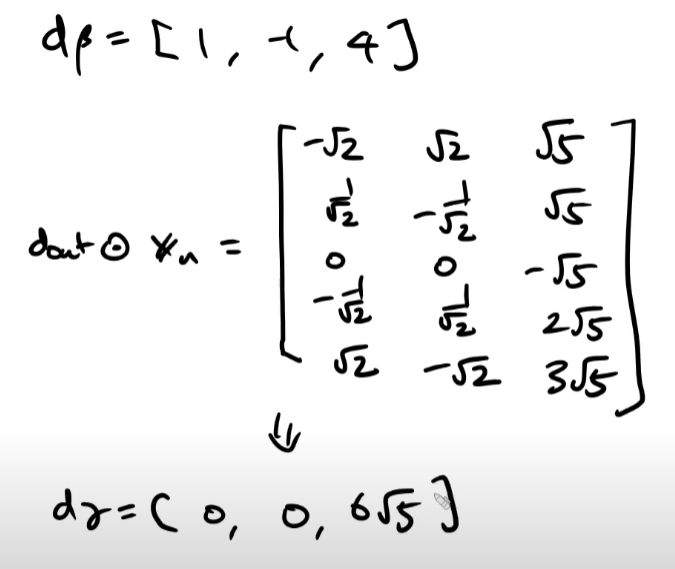
코드 구현
class BatchNormalization:
def __init__(self, gamma, beta, momentum=0.9, running_mean=None, running_var=None):
self.gamma = gamma
self.beta = beta
self.momentum = momentum
self.input_shape = None
self.running_mean = running_mean
self.running_var = running_var
self.batch_size = None
self.xc = None
self.std = None
self.dgamma = None
self.dbeta = None
def forward(self, x, train_flg=True):
self.input_shape = x.shape
if x.ndim !=2:
N, C, H, W = x.shape
x = x.reshape(N, -1)
out = self.__forward(x, train_flg)
# *는 괄호를 떼라는 의미이다.
return out.reshape(*self.input_shape)
def __forward(self, x, train_flg):
if self.running_mean is None:
N, D = x.shape
self.running_mean = np.zeros(D)
self.running_var = np.zeros(D)
if train_flg:
mu = x.mean(axis=0)
xc = x - mu
var = np.mean(xc**2, axis=0)
std = np.sqrt(var + 10e-7)
xn = xc / std
self.batch_size = x.shape[0]
self.xc = xc
self.xn = xn
self.std = std
# 매 배치마다 구해지는 mu와 이전에 구해졌던 running_mean을 내분해서 새로운
# running_mean을 구한다.
self.running_mean = self.momentum * self.running_mean + (1-self.momentum) * mu
self.running_var = self.momentum * self.running_var + (1-self.momentum) * var
else:
xc = x - self.running_mean
sn = sc / ((np.sqrt(self.running_var + 10e-7)))
out = self.gamma * xn + self.beta
return out
def backward(self, dout):
if dout.ndim != 2:
N, C, H, W = dout.shape
dout = dout.reshape(N, -1)
dx = self.__backward(dout)
dx = dx.reshape(*self.input_shape)
return dx
def __backward(self, dout):
dbeta = dout.sum(axis=0)
dgamma = np.sum(self.xn * dout, axis=0)
dxn = self.gamma * dout
dxc = dxn / self.std
dstd = -np.sum((dxn * self.xc) / (self.std * self.std), axis=0)
dvar = 0.5 * dstd / self.std
# 위쪽에서 구한 dxc와 아래의 dxc가 합류를 하기 때문에 더해준다.
dxc += (2.0 / self.batch_size) * self.xc * dvar
dmu = np.sum(dxc, axis=0)
dx = dxc - dmu / self.batch_size
self.dgamma = dgamma
self.dbeta = dbeta
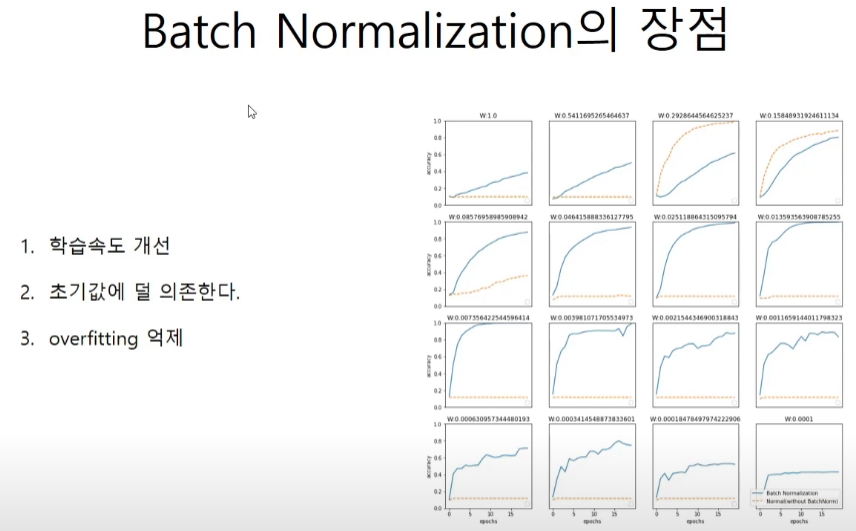
return dxbatch normalization의 장점
그래프에서 파란색이 batch normalization을 사용한 경우의 accuracy 그래프이고, 주황 점선이 사용하지 않은 경우의 accuracy 그래프이다. 그래프를 보면 파란색 그래프가 안정적인 것을 알 수 있다.

chords & code // harmony with structure