과적합
과적합은 파라미터의 개수가 상대적으로 학습용 데이터의 개수보다 많을 때 일어난다.
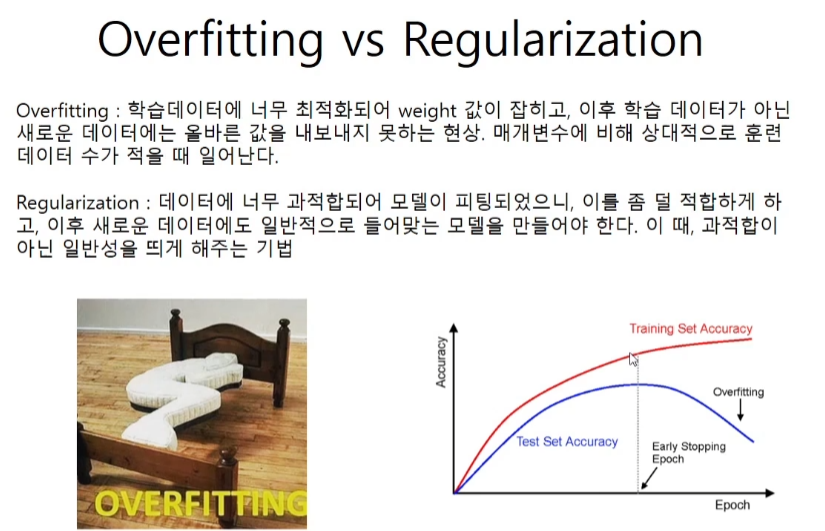
Regularization
NN가 training data의 중요한 정보만 담고, 부수적, 우연적, 특수한 정보를 담지 않게 하는 방법
Weight Decay
penalty는 가중치의 값들의 합이기 때문에 학습시에 penalty를 낮추는 것은 정보를 잃게 만드는 역할을 한다. 다만 덜 중요한(적은) 정보는 결과적으로 더 중요한(많은) 정보에 비해서 더 남지 못하게 될 것이다.

연습문제1

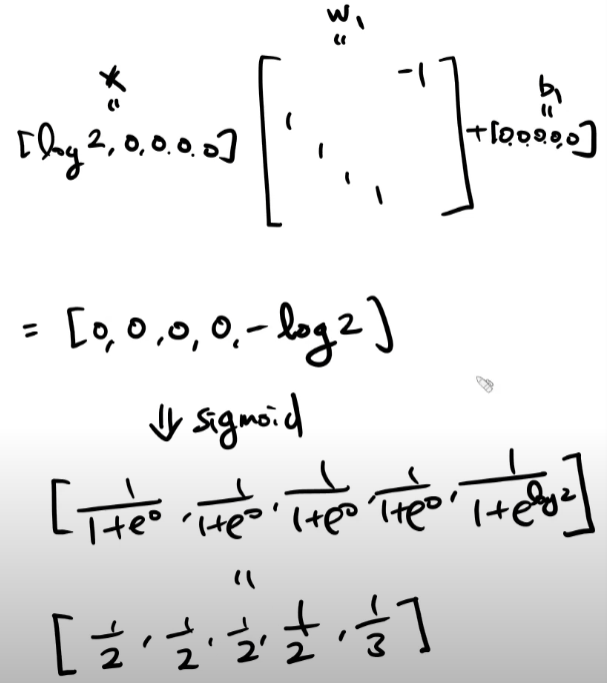
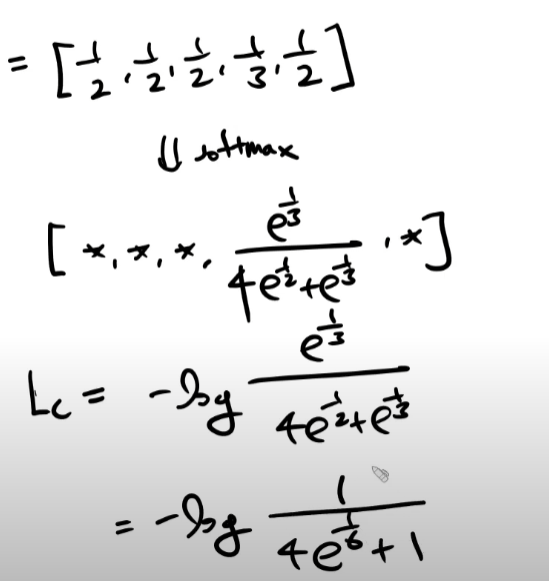
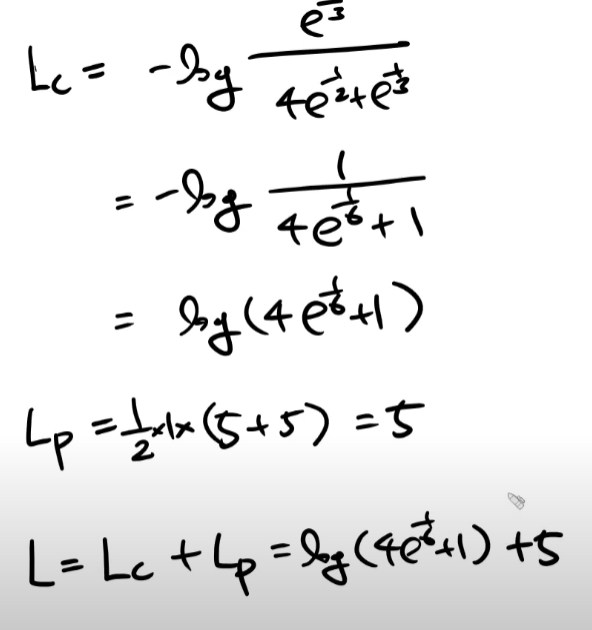
연습문제2
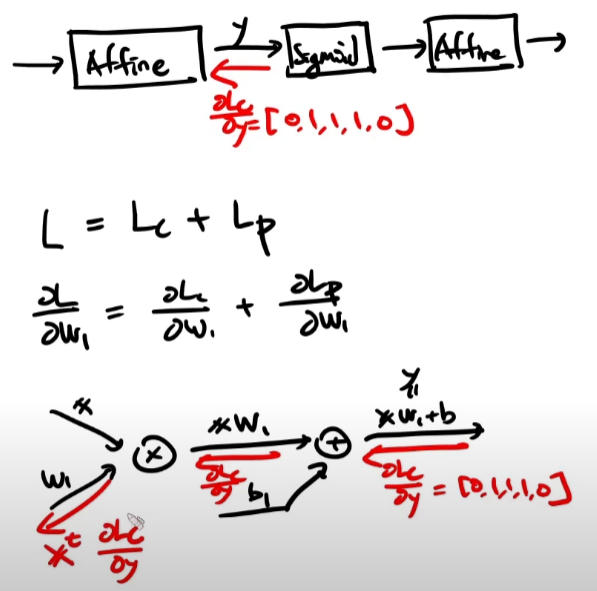
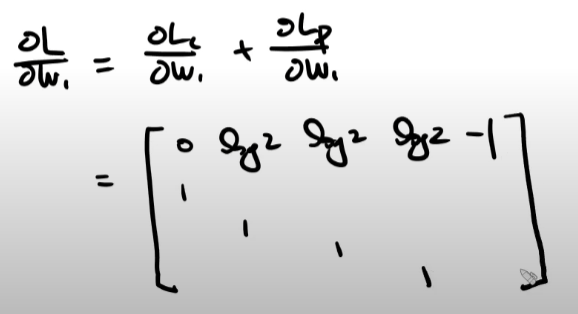
L = Lc + Lp라는 것을 이해하고 이를 w1으로 미분해야 한다.
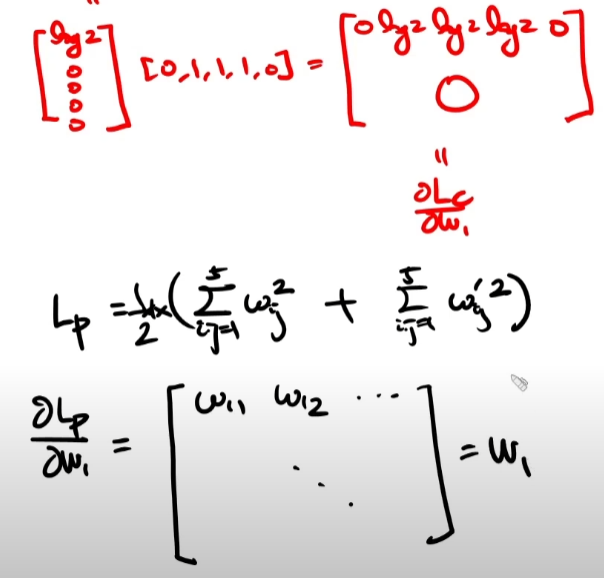
Lp를 w1으로 미분해주어야 하는게 까다롭다.
다만 수식적으로 Lp를 w로 미분해준 값은 w 그자체로 나온다는 것을 외워둘 필요가 있다. 또한 Lp를 b로 미분해봤자 변수가 없어서 0이 된다는 것 또한 알아두면 좋다.

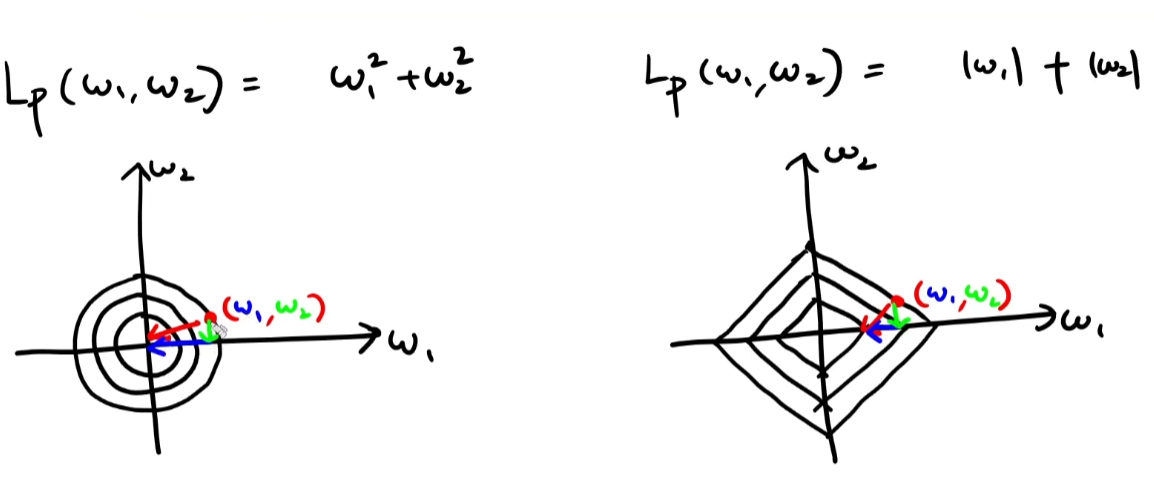
기하학적인 분석
L2 reg의 등위선을 평면에 그려보면 원이다.
L1 reg의 등위선을 평면에 그려보면 사각형이다.
붉은색 선은 gradient의 반대 방향이다.
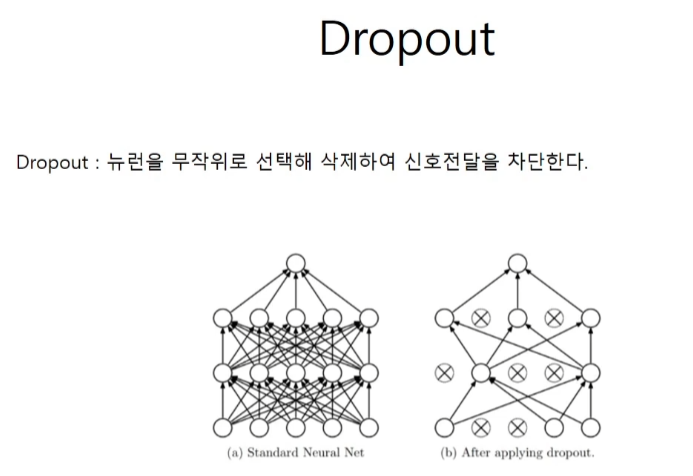
Dropout
학습과 관련한 parameter가 없다. ReLU, softmax with loss도 없다.
Affine, Batch normalization(gamma, beta)은 학습할 parameter가 있다.
랜덤하게 뉴런이 꺼지므로 계속해서 새로운 모델을 사용하는 것과 같이 Ensemble과 같은 효과를 낼 수 있다.
Neural Network의 cheating을 방지하기 위해 관계를 끊는 방법을 사용한다.
코드구현
class Dropout:
def __init__(self, dropout_ratio = 0.5):
self.dropout_ratio = dropout_ratio
self.mask = None
def forward(self, x, train_flg=True):
if train_flg:
# dropout_ratio와 행렬의 원소를 비교해서 True, False로 이루어진 행렬을 만든다.
# rand는 0~1의 값이다.
self.mask = np.random.rand(*x.shape) > self.dropout_ratio
# 인풋에 mask를 씌워준다.
return x * self.mask
else:
# 전체적인 feature의 스케일을 학습시와 맞춰주기 위해서 사용한다.
# rescaling이다.
return x * (1.0 - self.dropout_ratio)
def backward(self, dout):
# 순전파에서 죽인 자리에 맞춰서, 흘러 들어온 미분을 죽인다.
# ReLU층의 역전파와 threshold 빼곤 동일하다.
return dout * self.mask
chords & code // harmony with structure