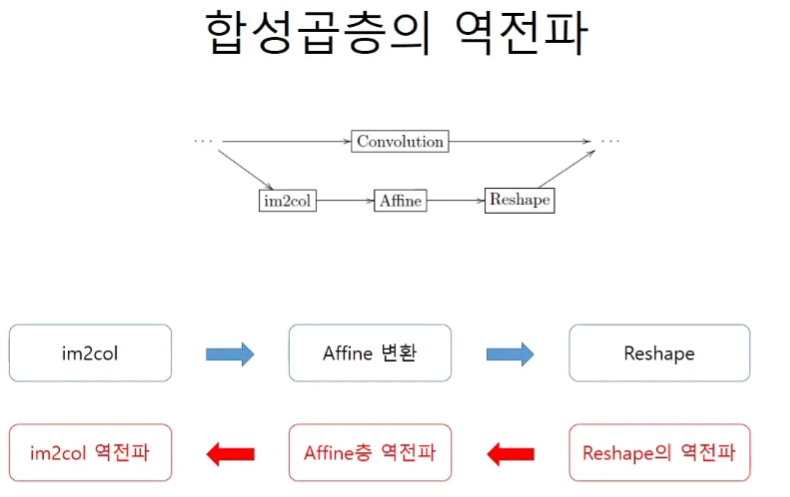
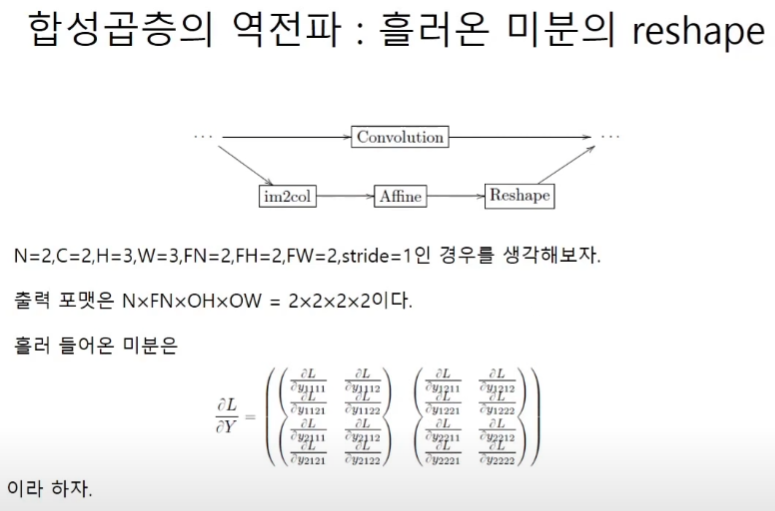
합성곱층의 역전파
fully connected vs. partially connected
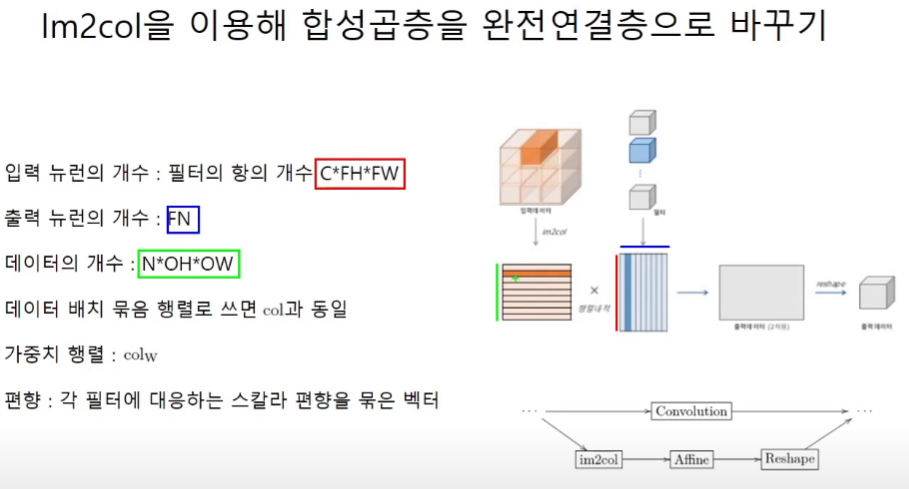
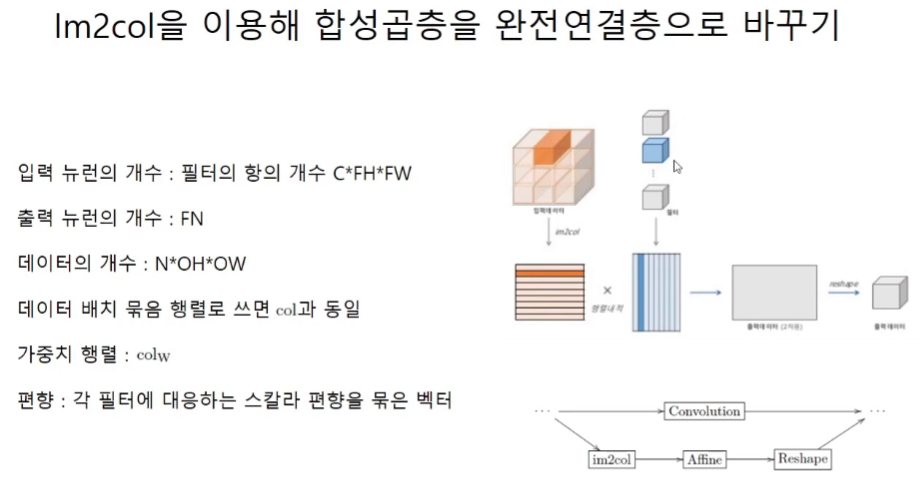
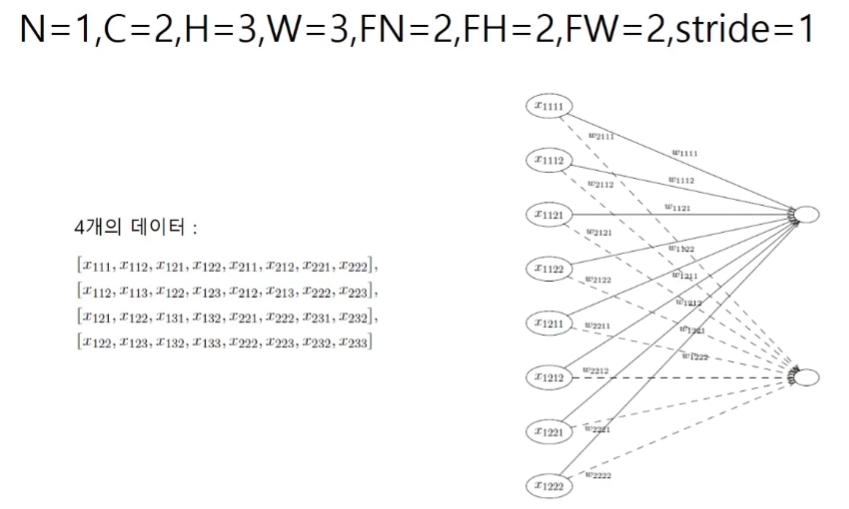
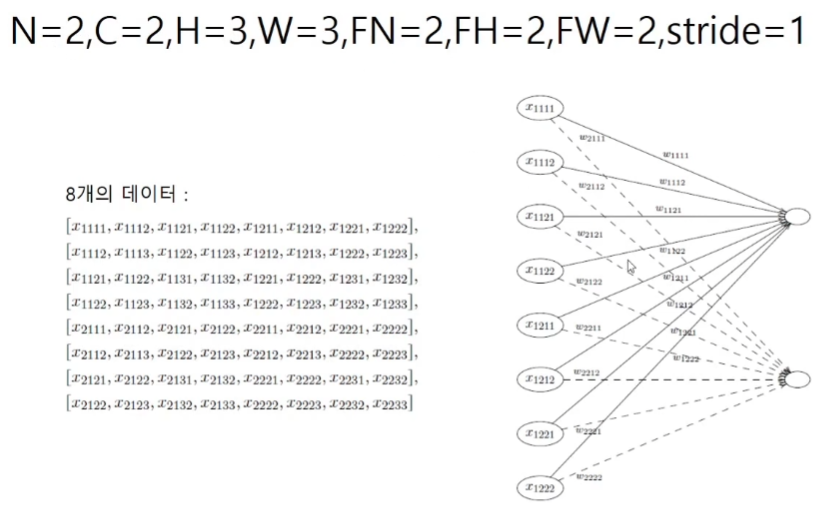
합성곱을 Affine층으로
weight matrix : 행(각 필터의 가중치의 개수, 채널순서로) x 열(사용한 필터의 개수)
input matrix : 행(input의 연산의 횟수, conv된 layer 픽셀의 크기와 동일)
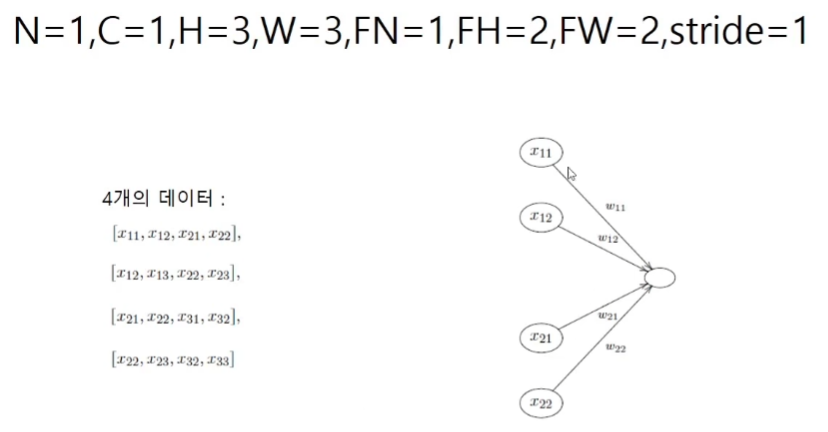
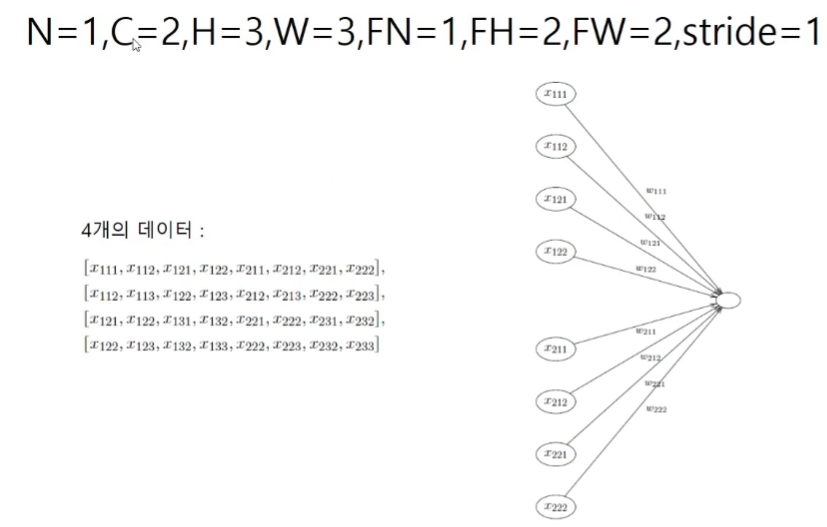
합성곱층의 역전파
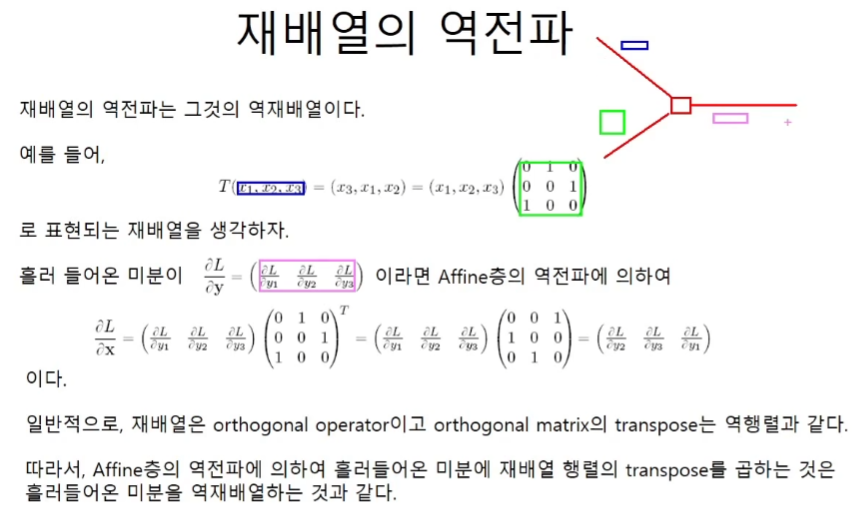
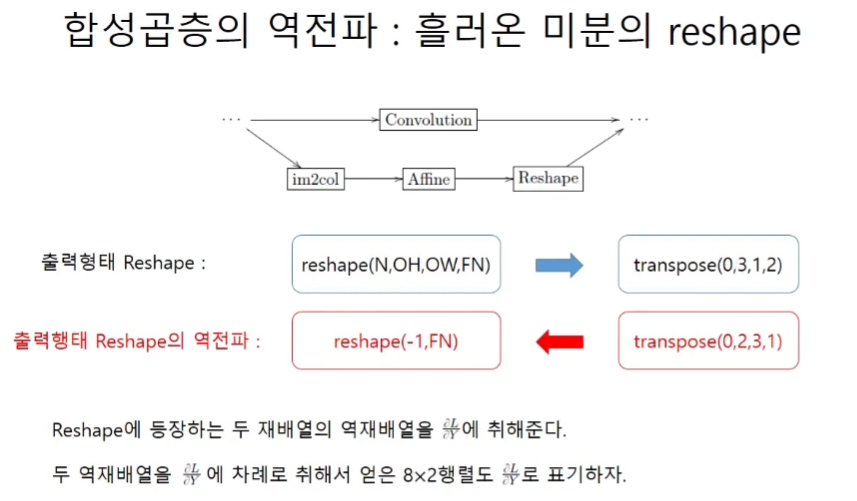
재배열의 역전파 = dout의 역재배열
재배열은 행렬을 곱하는 선형변환으로 해석할 수 있다.
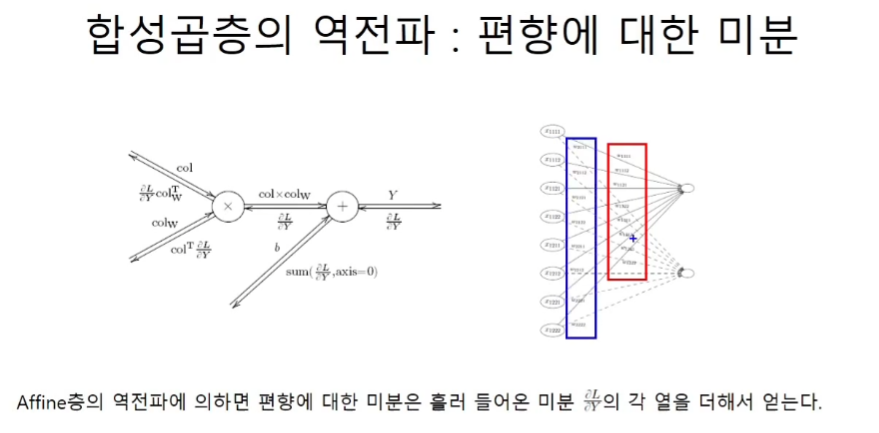
따라서 이 연산은 input x matrix이며 이것은 Affine층에서 bias연산이 빠진 계산과 같다.
역재배열은 말이 어렵지 그냥 원래의 shape으로 되돌려주면 된다.
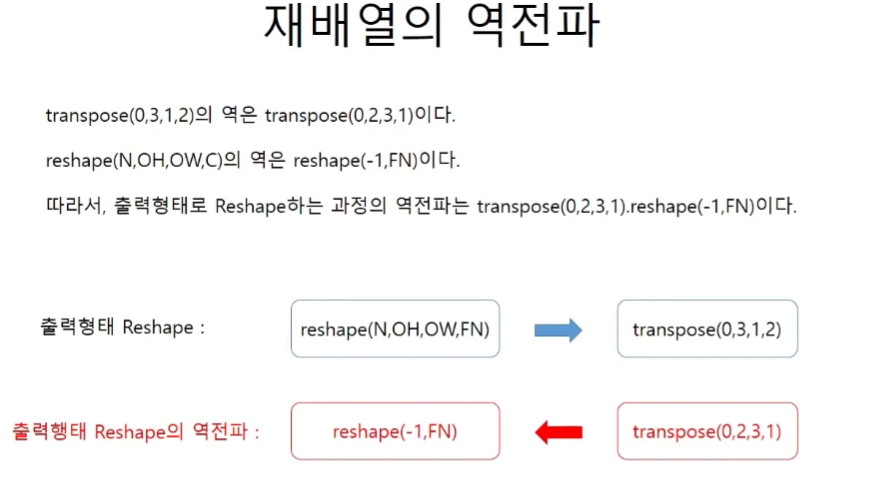
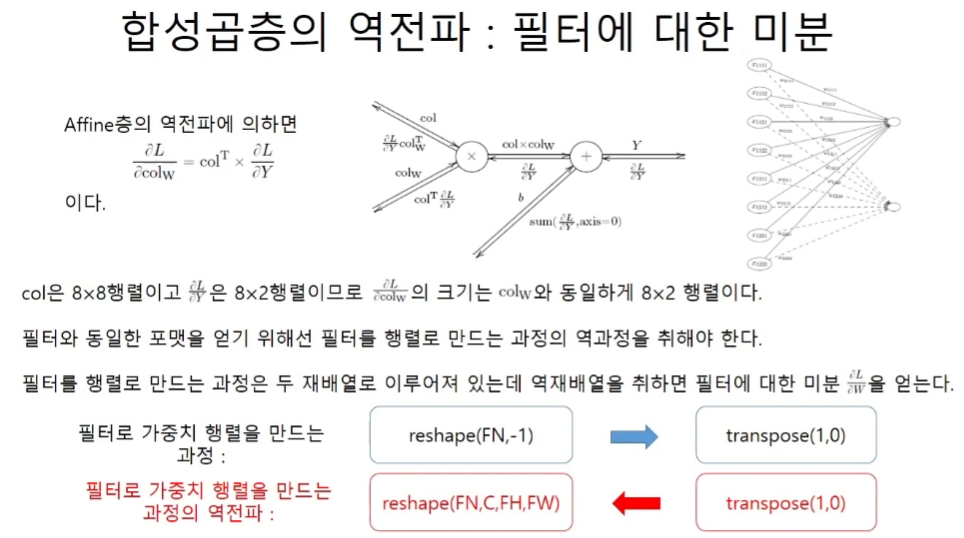
필터를 2차원 행렬로 만들어주는 과정의 역전파
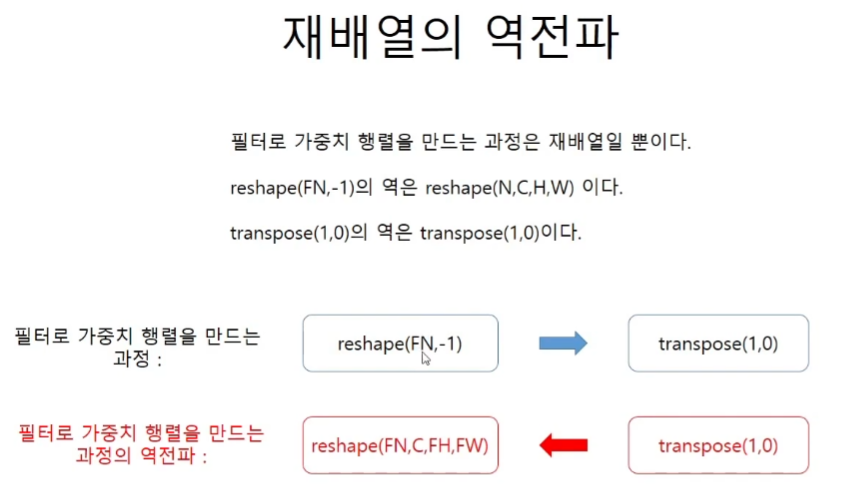
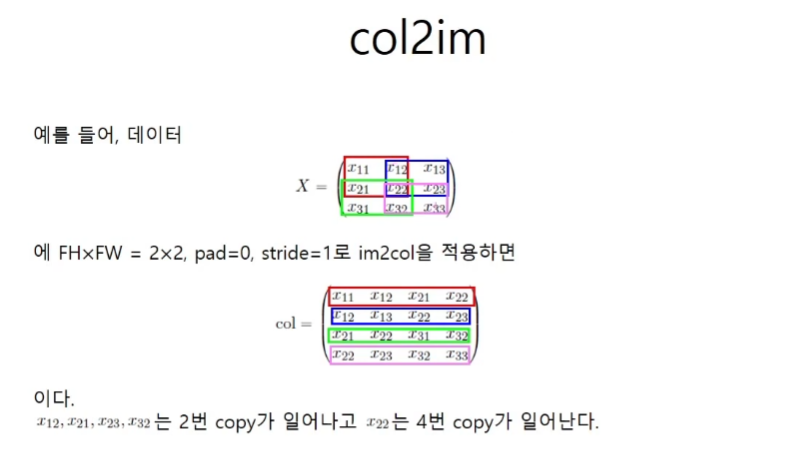
col2im
인풋을 2차원 행렬로 만들어주는 im2col의 역전파

복잡해보이지만 input이 3 x 3이기 때문에 dinput도 3 x 3여야 한다.
그리고 repeat node의 역전파는 sum이기 때문에 여러번 쓰인 원소들은 쓰인 만큼 더해주면 된다.



col2im 코드구현
def col2im(col, input_shape, filter_h, filter_w, stride=1, pad=0):
'''
col : 2차원 배열, 흘러들어온 미분
input_shape : 원래 이미지 데이터의 shape(10, 1, 28, 28)
'''
N, C, H, W = input_shape
out_h = (H + 2*pad - filter_h) // stride + 1
out_w = (W + 2*pad - filter_w) // stride + 1
col = col.reshape(N, out_h, out_w, C, filter_h, filter_w).transpose(0, 3, 4, 5, 1, 2)
img = np.zeros((N, C, H + 2*pad + stride - 1, W + 2*pad + stride - 1))
for y in range(filter_h):
y_max = y + stride*out_h
for x in range(filter_w):
x_max = x + stride*out_w
img[:, :, y:y_max:stride, x:x_max:stride] += col[:, :, y, x, :, :]
return img[:, :, pad:H + pad, pad:W + pad]합성곱층의 역전파 코드구현
합성곱의 결과인 텐서와 같은 형태를 가진 dout이 흘러들어온다.
class Convolution:
def __init__(self, W, b, stride=1, pad=0):
self.W = W
self.b =b
self.stride = stride
self.pad = pad
self.x = None
self.col = None
self.col_W = None
self.dw = None
self.db = None
def forward(self, x):
FN, C, FH, FW = self.W.shape
N, C, H, W = x.shape
out_h = int((H + 2*self.pad - FH) / self.stride) + 1
out_w = int((W + 2*self.pad - FW) / self.stride) + 1
col = im2col(x, FH, FW, self.stride, self.pad)
col_W = self.W.reshape(FN, -1).T
out = np.dot(col, col_W) + self.b
out = out.reshape(N, out_h, out_w, -1).transpose(0, 3, 1, 2)
self.x = x
self.col = col
self.col_W = col_W
return out
def backward(self, dout):
FN, C, FH, FW = self.W.shape
dout = dout.transpose(0,2,3,1).reshape(-1, FN)
self.db = np.sum(dout, axis=0)
self.dW = np.dot(self.col.T, dout)
# 필터가 행렬이 되는 과정을 역재배열해준다.
self.dW = self.dW.transpose(1,0).reshape(FN, C, FH, FW)
dcol = np.dot(dout, self.col_W.T)
# 4차원 인풋이 2차원 행렬이 된 im2col의 역전파 과정
dx = col2im(dcol, self.x.shape, FH, FW, self.stride, self.pad)
return dxMax Pooling층의 역전파
forward
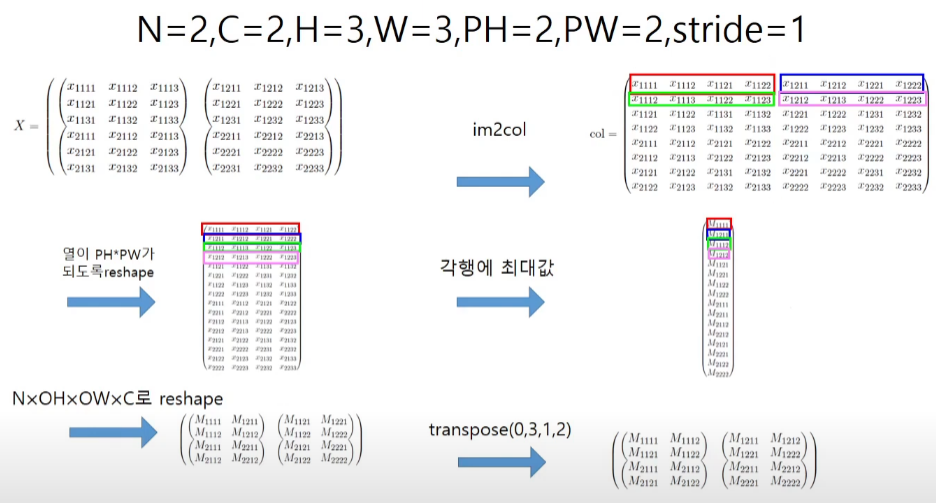
구현을 생각해보면 im2col로 만든 행렬들을 필터 각각의 가중치의 개수의 크기인 열 값으로 reshape해주면 나머지는 np.max를 하고 그것을 필터가 통과한 layer로 reshape해주기만 하면 된다. im2col의 변환에서 원소들을 넣어주는 순서가 N, H, W, C이기 때문에 reshape을 해주고 transpose를 해주게 된다.

backward
f(x11, x12, x21, x22) = x11이라면 이를 편미분하면 오직 x11 자리만 1로 미분이되고 나머지 자리는 0이된다.
local gradient가 구해졌으므로 upstream gradient만 신경쓰면 된다.

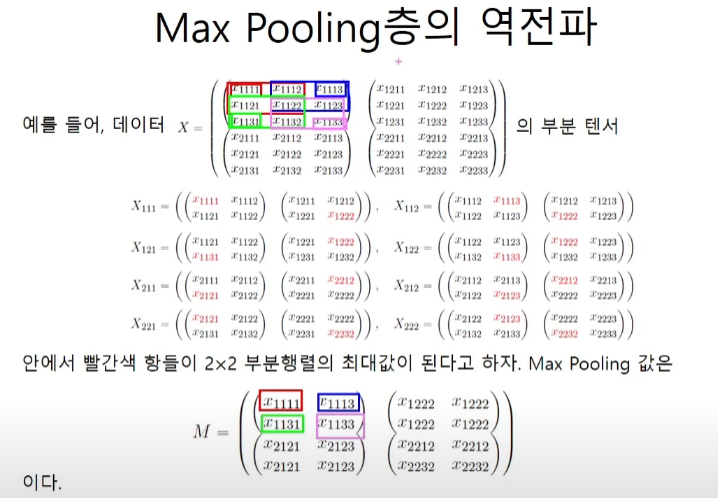
하지만 아래와 같이 max pooling이 copy가 일어나는 상황이 되면 역전파가 조금 어려워진다. 원소가 겹치지 않는 상황에서 local gradient와 upstream gradient의 곱은 최대가 된 자리에 u.g의 값을 넣어주기만 하면 된다.
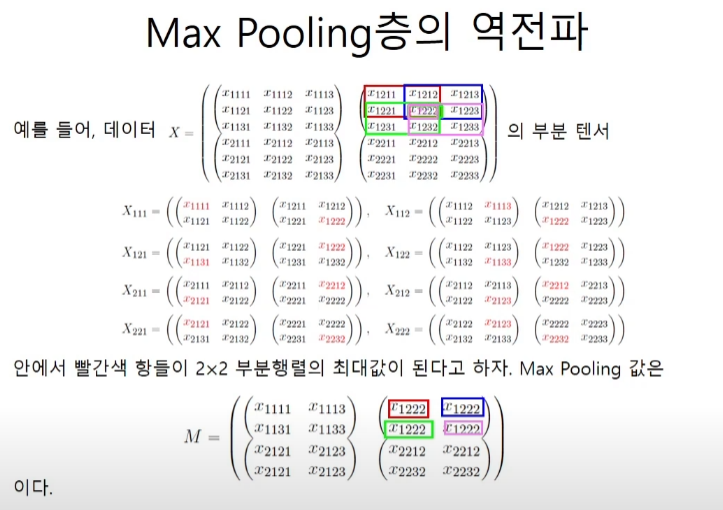
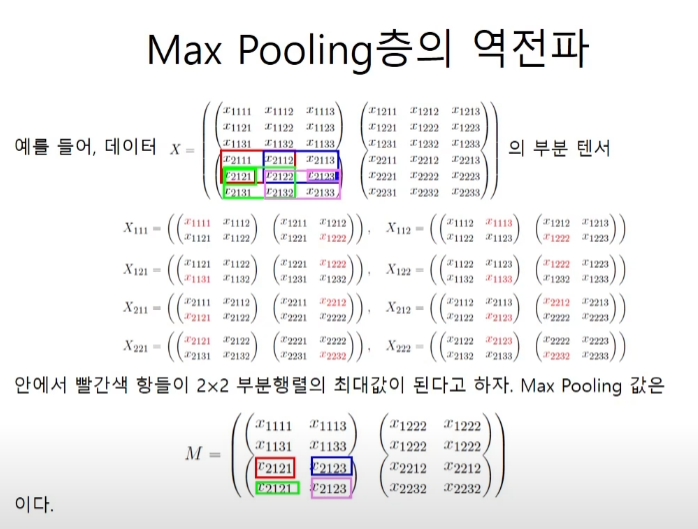
하지만 원소가 copy가 되었다면 repeat node의 역전파인 sum을 해주어야 한다. 하지만 또 어렵게 생각할 것 없이 각 자리에서 최대가 된 자리에 upstream의 값을 넣어주고 자리가 겹치면 더해주기만 하면 된다.


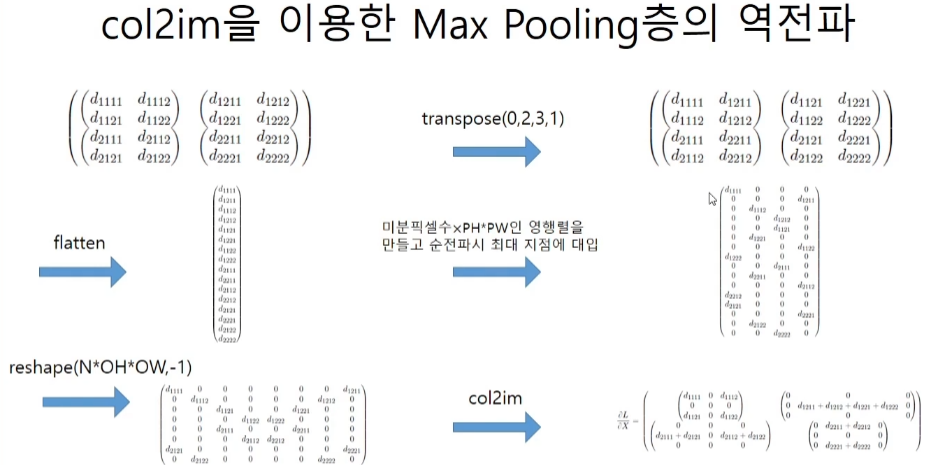
코드 구현

max method의 미분이 헷갈릴 수 있는데 최대가 되는 자리에 미분 값을 넣어주면 된다. 다만 이렇게 되면 (x,1)로 flatten된 upstream gradient가 하나의 값만 살아있고 나머지 값은 0인 행들로 이루어진 행이 된다. 이 행렬의 크기는 (x, pool_h x pool_w)가 된다.
class Pooling:
def __init__(self, pool_h, pool_w, stride=1, pad=0):
self.pool_h = pool_h
self.pool_w = pool_w
self.stride = stride
sefl.pad = pad
self.x = None
self.arg_max = None
def forward(self, x):
N, C, H, W = x.shape
out_h = int((H + 2*self.pad - FH) / self.stride) + 1
out_w = int((W + 2*self.pad - FW) / self.stride) + 1
col = im2col(x, self.pool_h, self.pool_w, self.stride, self.pad)
col = col.reshape(-1, self.pool_h * self.pool_w)
arg_max = np.argmax(col, axis=1)
out = np.max(col, axis=1)
out = out.reshape(N, out_h, out_w, C).transpose(0, 3, 1, 2)
self.x = x
self.arg_max = arg_max
return out
def backward(self, dout):
# N x OH x OW x C
dout = dout.reshape(0, 2, 3, 1)
pool_size = self.pool_h * self.pool_w
# 살아남은 친구들의 개수 16 x 4 원래 있던 친구들의 개수
dmax = np.zeros((dout.size, pool_size))
# 슬라이싱에 리스트와 리스트를 넣어주면 각 리스트 원소의 좌표에 들어간다.
dmax[np.arange(self.arg_max.size), self.arg_max.flatten()] = dout.flatten()
# 튜플 덧셈이므로 (2, 2, 2, 2, 4)
dmax = dmax.reshape(dout.shape + (pool_size,))
dcol = dmax.reshape(dmax.shape[0] * dmax.shape[1] * dmax.shape[2], -1)
dx = col2im(dcol, self.x.shape, self.pool_h, self.pool_w, self.stride, self.pad)
return dx