혁펜하임님의 강화학습 강의를 정리한 내용입니다.
https://www.youtube.com/watch?v=cvctS4xWSaU&list=PL_iJu012NOxehE8fdF9me4TLfbdv3ZW8g&index=1
개요
연속된 액션들의 모임으로 보상과 목표를 최대화 하는 학습
deep learning과는 뿌리가 다르다.
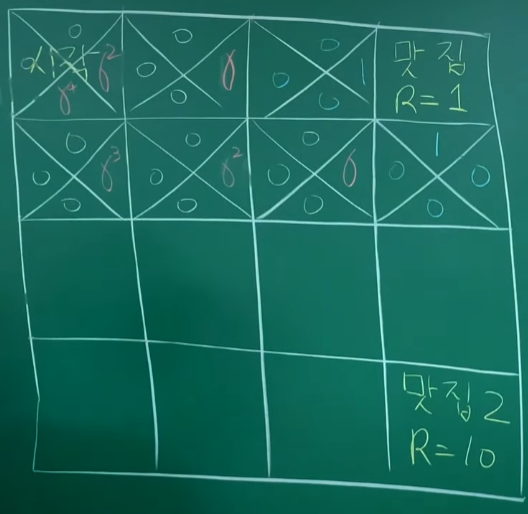
맛집찾기와 Q-learning
맛집까지 가는 길을 모르기 때문에 하나하나 탐색해나가야 한다.
Greedy Action
episode가 끝나려면 맛집에 들어가야 한다. 다음 episode를 위해서 기록을 남긴다.
모든 판에 대한 Q값을 update하는 것이 목적이다.
episode 1 : 모든 state의 모든 action이 0이다. 랜덤하게 움직이다가 맛집에 도달하기 직전의 state의 action에 reward를 update한다.
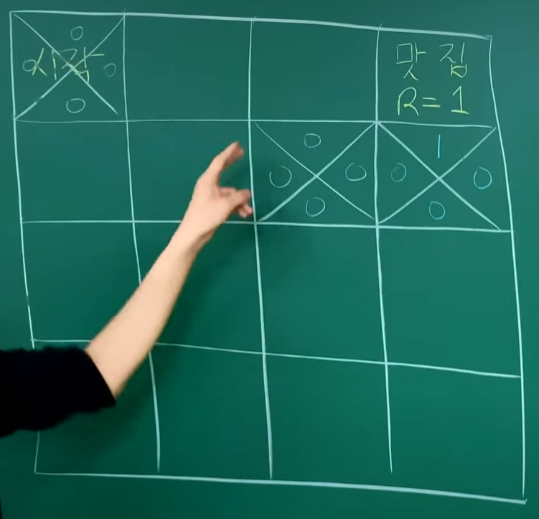
episode 2 : 우연히 들어간 오른쪽에 Q값이 있기 때문에 오른쪽 방향에 1이 update가 된다.
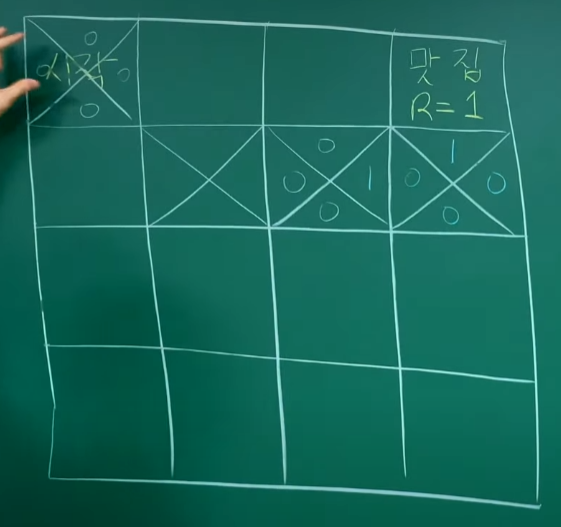
episode 3 :
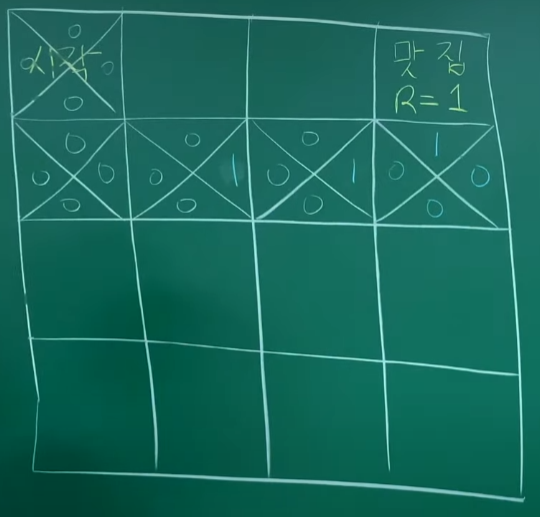
episode 5 :

Exploration & Exploitation
epsilon Greedy(e : 0~1)
1.새로운 path, 2.새로운 맛집
새로운 길 혹은 새로운 맛집이 없는 지를 탐험하는 것 vs. 판의 Q값대로 움직이는 것
둘 사이는 trade-off의 관계이다.


Decaying e - Greedy
e를 0.9로 주면 탐험하는 방향으로 움직이지만 episode가 늘어남에 따라 그 값을 줄여서 나중에는 최적의 값을 찾는 방향으로 바꿔준다.
시작점에서 e값에 따라 오른쪽으로 경로를 잡았을 경우 새로운 경로를 찾게 된다.
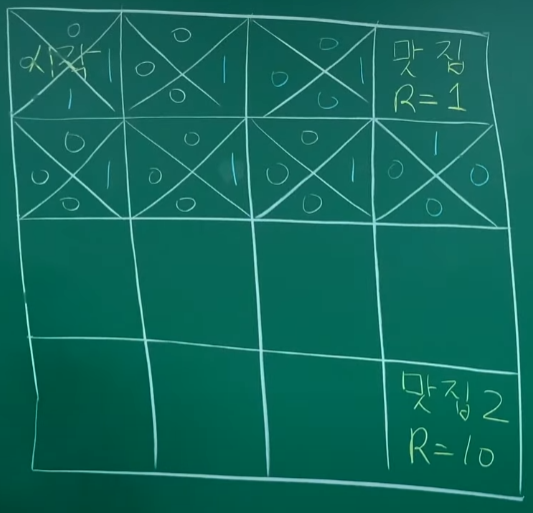
Discout Factor
ramma : 0~1
앞선 state에서 Q값을 가져올때 r만큼 값을 곱해서 가져온다. 이 과정을 통해서 좀더 좋은 경로를 찾을 수 있게 된다.
1.효율적 path, 2.현재와 미래 사이의 reward 가치를 조절(r이 작아지면 지금 state에 대한 가치가 그리 좋지 못하므로 다른 path를 선택할 가능성이 커진다?)
Q-update
Q learning에서는 부드럽게 Q값을 가져온다.
alpha : 0~1, 원래 가지고 있던 값과 새로운 값 사이를 내분하는 비율이다. 커질수록 새로운 것에 더 비중을 둔다.
Rt : at를 했을 때 받는 reward
alpha가 1이라면
1.맛집 직전 state가 t시점일때 : t+1은 없기 때문에 Q값은 a x Rt = 1이된다.
2.맛직 전전 state가 t시점일때 : reward가 없으므로 Rt = 0, t+1시점에서 Q를 가장 크게 만드는 at+1의 값에 gamma를 곱한 값 1 x r
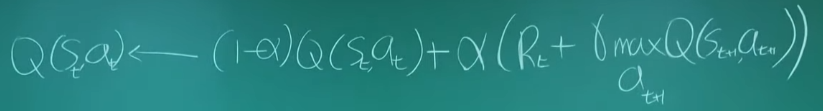
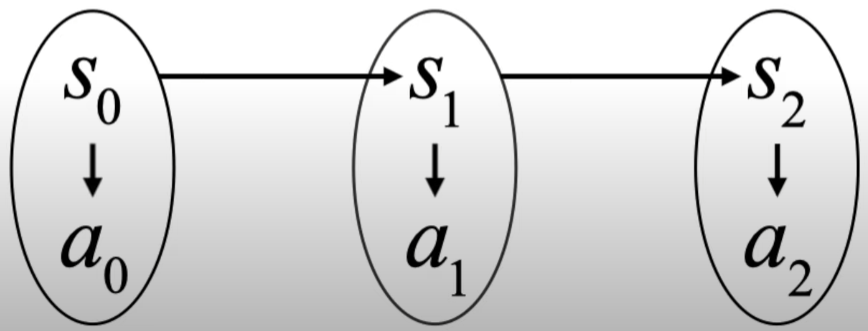
Markov Decision Process
decision = action
확률분포는 이산이면 PMF 연속이면 PDF이다.
1.P(a1|s0,a0,s1) = Policy : s0에서 a0로 s1으로 넘어온 상황에서 a1의 확률 =>
P(a1 | s1)는 s0, a0와 상관 없다. 왜냐하면 s0, a0는 s1에 모두 담겨 있기 때문
2.P(s2 | s0,a0,s1,a1) = transition probability => P(s2 | s1, a1)
Reward = Expected Return
return goal은 reward의 합이다.
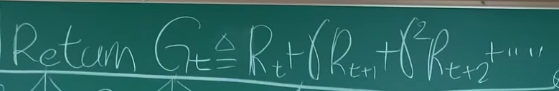
Gt = Rt + rRt+1 + r^2Rt+2 + ...
s0에서 오른쪽으로 이동한 s1에서의 오른쪽 Q gamma가 reward가 될 수 있는 이유는 Rt에 reward는 0이지만 오른쪽으로 한번 더 간 Rt+1에는 reward가 1이므로 이 값에 gamma값을 곱하면 리턴 값이 생기기 때문이다.
action이 랜덤이기 때문에 reward도 랜덤이라 기대값일 계산하게 된다.
결국 강화학습은 expected return을 최대화 하는 것이 목표이고 이 expectation 값을 maximize하는 policy를 찾는 것 즉 적합한 action을 찾는 것이 목표이다.
