지금까지의 수업은 얕은 신경망으로 MNIST를 구분하는 Neural Network였다. 층을 깊게 쌓는 데에는 여러 문제들이 발생한다. 이를 해결하는 방법을 알아보자.
Optimizer
입력층은 784개, 은닉층은 50개, 출력층은 10개의 뉴런을 가진다. 따라서 가중치는 39760개가 되었다.
최소점 혹은 최소점에 가까운 위치를 찾는 문제가 된다.
그 값은 gradient가 0이 되는 값을 연립방정식으로 풀어내거나 경사하강법을 통해 찾아가는 방식으로 알 수 있다.
차원이 엄청나게 많아지면 그 차원을 우리는 이해할 수가 없기 때문에 결국에는 눈을 감고 산을 내려가는 방식이 된다.
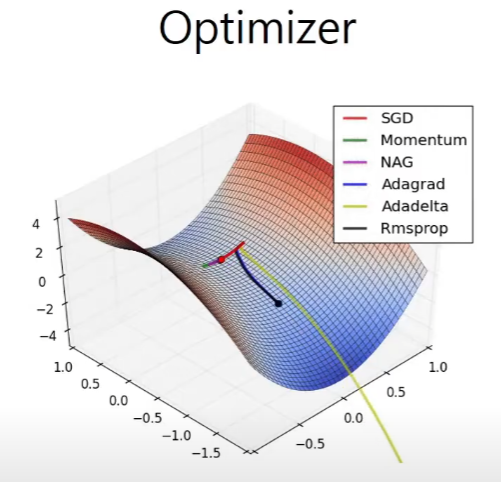
Optimizer는 어떻게 산을 타고 내려갈 것인지를 정하는 방법이다.
Stochastic Gradient Descent
확률론적인 접근으로 무작위로 샘플링한 샘플들로부터 gradient를 구해서 방향을 정한다.
연습문제 풀이
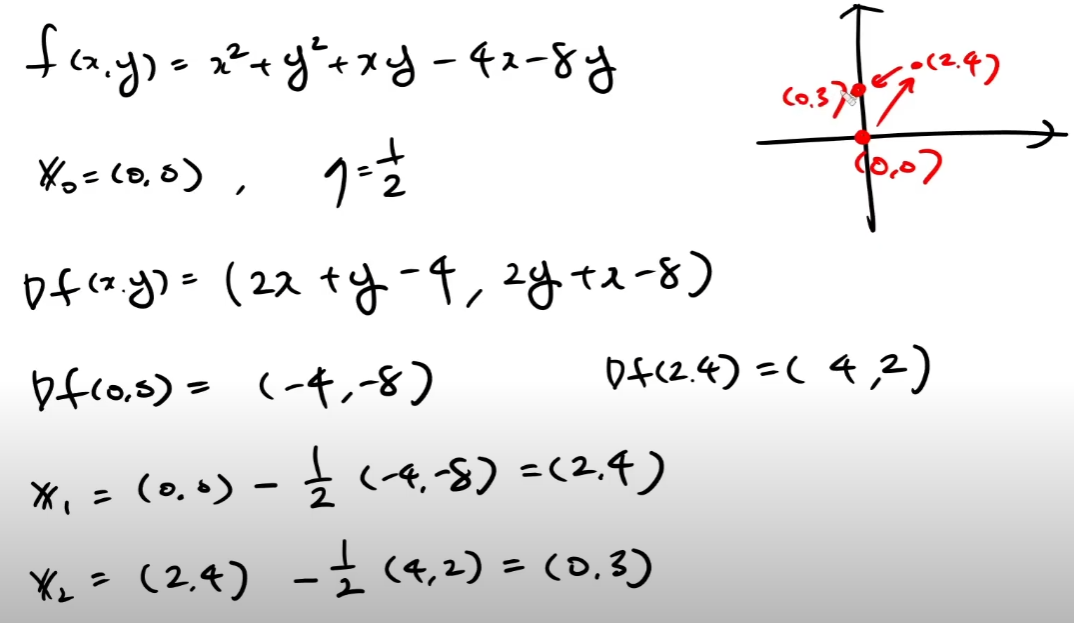
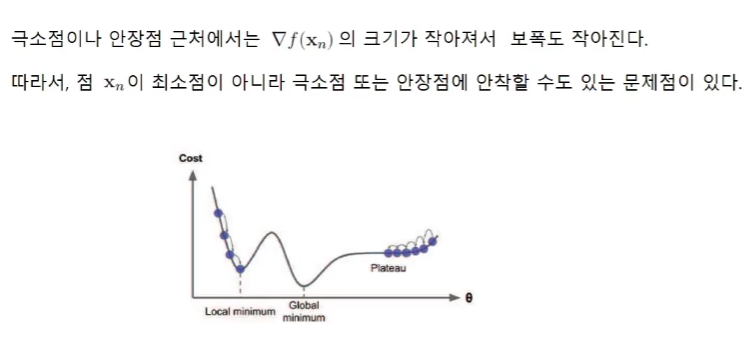
극소점과 안장점의 문제
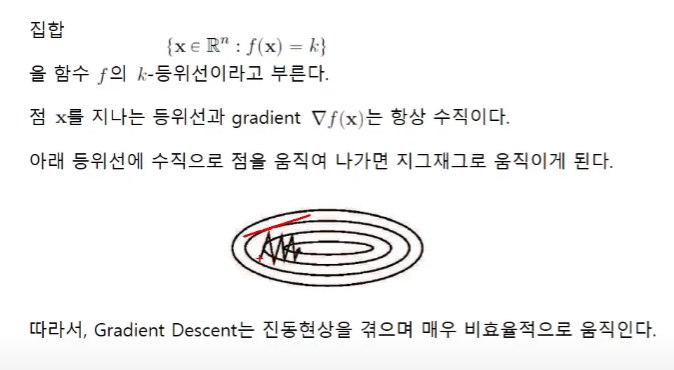
진동현상의 문제
포물선의 경우에 등위선에 수직인 -gradient의 방향은 목적으로 향하지가 않는다. 층을 깊게 쌓아서 변수가 많아지면 이런 현상들이 생긴다.
코드구현
class SGD:
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]Momentum

1.극소점local minimum 또는 안장점plateau에 안착하는 문제를 해결할 수 있다.
2.진동방향을 상쇄하고 진행방향은 관성을 통해 더 효율적으로 움직인다.
예제문제
이변수 함수 f(x,y) = xy에 대하여 learning rate = 1, momentum alpha = 1을 적용하려 한다. 초기 위치 x0 = (1,2)에서 출발할때 세걸음 x1, x2, x3를 계산하시오.
x1 = (-1,1) x2 = (-4,1) x3 = (-8,5)
코드구현
class Momentum:
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]
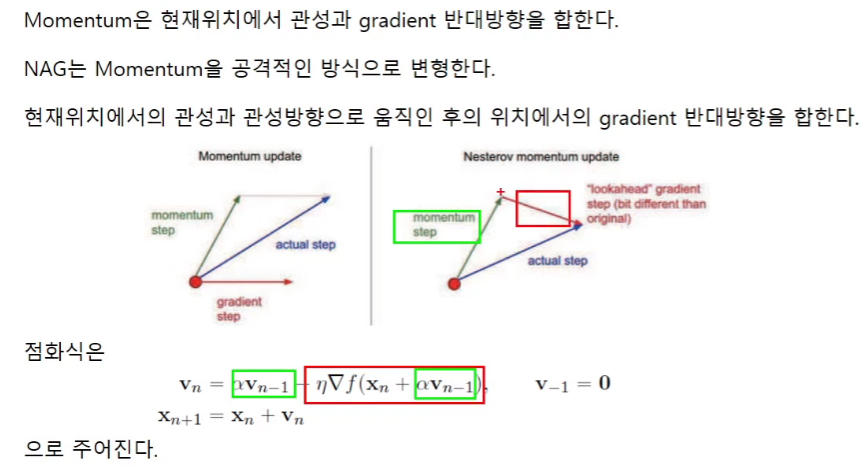
params[key] += self.v[key]NAG(Nesterov Accelated Gradient)
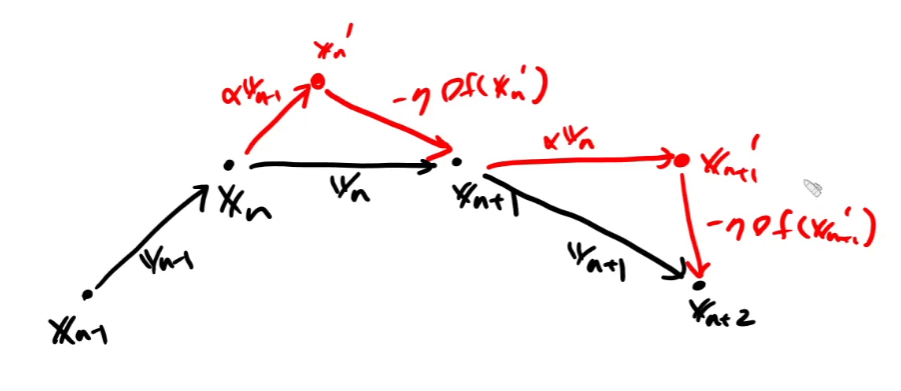
momentum과의 차이는 gradient step을 구하는 위치가 바뀐다는 것이다.
지금 위치에서 gradient step을 구해서 v에 더해주면(러닝레이트를 곱해주고 빼주면) momentum이고
지금 위치에서 관성만큼 움직인 다음의 위치에서 gradient step을 구해서 v에 더해주면 NAG이다.
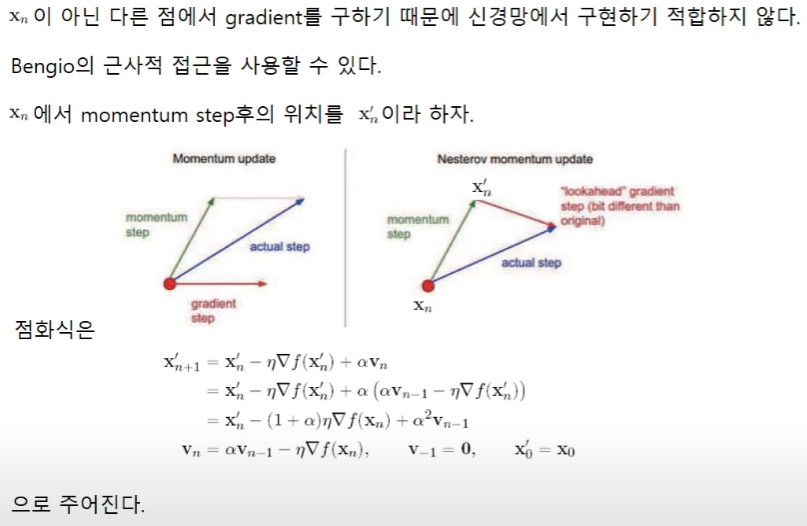
Begio의 근사적 접근
이렇게 식을 근사하는 이유는 다음 step을 추가해서 계산하는 것은 복잡하기 때문에 이전 step까지 나와 있는 값들로만 계산할 수 있도록 하는 것이다.
이렇게 식을 바꿔주어야 역전파를 통한 학습이 더 쉽다고 한다.
코드 구현
class Nesterov:
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] *= self.momentum
sefl.v[key] -= self.lr * grads[key]
params[key] += self.momentum * self.momentum * self.v[key]
params[key] -= (1 + self.momentum) * self.lr * grads[key]