two_layer_net 구현
OrderedDict()
dictionary는 순서에 구애를 받지 않는다. 하지만 순서가 중요한 경우 ordereddict를 써주면 된다.
a==b # True
c = OrderedDict(a)
d = OrderedDict(b)
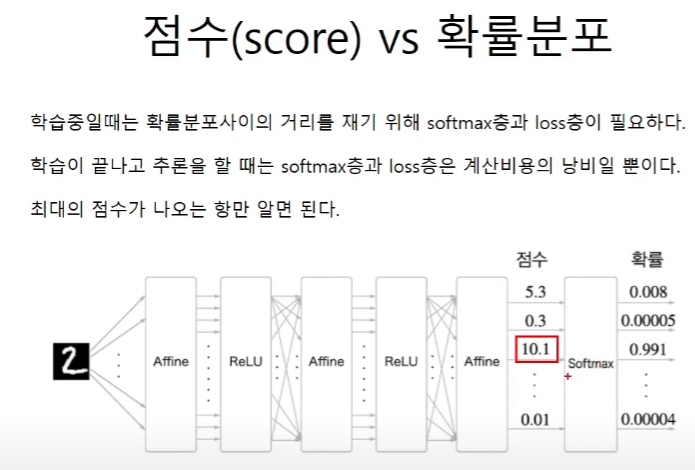
c==d # False계산 비용의 낭비
학습이 끝난 이후에 softmax with loss층은 사용하지 않기 때문에 계산 비용의 효율을 위해서
predict와 loss를 따로 구현한다.
two_layer_net 코드 구현
import numpy as np
from layers import *
from gradient_2d import numerical_gradient
from collections import OrderedDictclass twolayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std = 0.01):
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
self.layers = OrderedDict()
self.layers['Affine1'] = Affine(self.params['W1'], self.params['b1'])
self.layers['Relu1'] = Relu()
self.layers['Affine2'] = Affine(self.params['W2'], self.params['b2'])
self.lastlayer = SoftmaxwithLoss()
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
y = self.predict(x)
return self.lastlayer.forward(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
if t.ndim != 1 :
t = np.argmax(t, axis=1)
accuracy = np.sum(t == y) / len(t)
return accuracy
def numerical_gradient(self, x, t):
loss_W = lambda W : self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
def gradient(self, x, t):
self.loss(x, t)
dout=1
dout = self.lastlayer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layers in layers:
dout = layers.backward(dout)
grads = {}
grads['W1'], grads['b1'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W2'], grads['b2'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads학습 코드 구현
import sys, os
sys.path.append("./dataset")
import numpy as np
from dataset.mnist import load_mnist
import import_ipynb
from two_layer_net import twolayerNet(x_train, y_train), (x_test, y_test) = load_mnist(normalize=True, one_hot_label=True) # flatten default T
network = twolayerNet(input_size=784, hidden_size=50, output_size=10)
iter_num = 10000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
train_loss_list = []
train_acc_list = []
test_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1) # 600번의 학습for i in range(iter_num):
batch_mask = np.random.choice(train_size, batch_size) # 데이터가 중복 사용 된다는 문제가 있다.
x_batch = x_train[batch_mask]
y_batch = y_train[batch_mask]
grad = network.gradient(x_batch, y_batch)
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
loss = network.loss(x_batch, y_batch)
train_loss_list.append(loss)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, y_train)
test_acc = network.accuracy(x_test, y_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print(i, '번째acc', train_acc, test_acc)결과
0 번째acc 0.1107 0.1107
600 번째acc 0.9046166666666666 0.9075
1200 번째acc 0.92505 0.9249
1800 번째acc 0.9366666666666666 0.9386
2400 번째acc 0.9454166666666667 0.9455
3000 번째acc 0.95215 0.9495
3600 번째acc 0.9577833333333333 0.9552
4200 번째acc 0.9618166666666667 0.9588
4800 번째acc 0.96435 0.9611
5400 번째acc 0.9664333333333334 0.9622
6000 번째acc 0.96995 0.9647
6600 번째acc 0.9705666666666667 0.9654
7200 번째acc 0.97305 0.9674
7800 번째acc 0.9724 0.9663
8400 번째acc 0.97645 0.9692
9000 번째acc 0.97615 0.9682
9600 번째acc 0.97845 0.97Confusion Matrix
def predict(network, x):
W1, W2 = network.params['W1'], network.params['W2']
b1, b2 = network.params['b1'], network.params['b2']
a1 = np.dot(x, W1) + b1
z1 = relu(a1)
a2 = np.dot(z1, W2) + b2
return a2confusion = np.zeros((10,10), dtype=int)
for k in range(len(x_test)):
i = int(np.argmax(y_test[k]))
y = predict(network, x_test[k])
j = np.argmax(y)
confusion[i][j] += 1
print(confusion)[[ 969 0 0 3 0 2 1 1 3 1]
[ 0 1118 3 1 0 1 3 1 8 0]
[ 6 5 995 5 3 1 1 8 8 0]
[ 0 0 4 990 1 0 0 8 3 4]
[ 1 0 7 0 962 0 1 1 2 8]
[ 5 1 1 13 3 850 8 0 7 4]
[ 8 3 0 0 7 9 923 1 7 0]
[ 0 7 10 3 2 0 0 999 0 7]
[ 4 2 4 9 3 4 4 9 933 2]
[ 5 5 0 9 19 0 0 11 4 956]]
chords & code // harmony with structure