문장생성
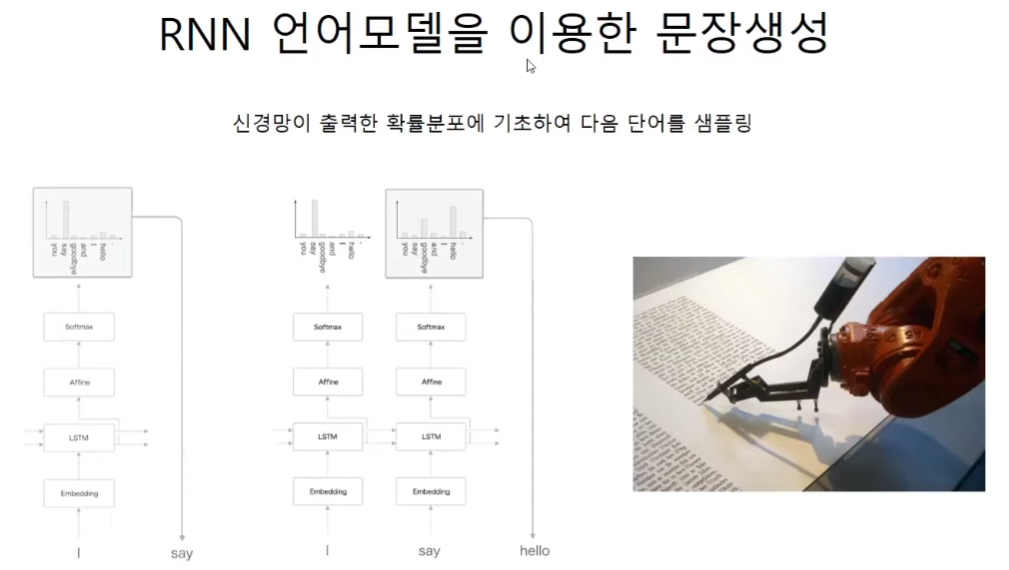
언어모델을 통한 문장의 생성의 특징은 결정론적으로 문장을 만드는 것과는 다르게 단어의 반복이 아니라 확률론적 선택에 기반한다. 그래서 자연스러운 문장이지만 이전에는 없던 문장이 나올 수도 있다.
선생님은 이 모델은 점화식과 비슷하다고 하신다. 또한 조건부 확률과 같이 앞에 나온 조건에 따라 다음에 나올 확률이 변한다고 하신다.
코드 구현
rnnlm_gen
import sys
import numpy as np
from functions import softmax
from rnnlm import Rnnlm
from better_rnnlm import BetterRnnlm
class RnnlmGen(Rnnlm):
def generate(self, start_id, skip_ids=None, sample_size=100):
word_ids = [start_id]
x = start_id
while len(word_ids) < sample_size:
# scalar값을 넣으면 안된다. rnnlm은 input을 행렬로 받기 때문이다.
# batch 1, time_size 1인 행렬이다.
x = np.array(x).reshape(1,1)
score = self.predict(x)
# batch_size 1, time_size 1, score_vector의 3차원 텐서를 벡터로 만들어준다.
p = softmax(score.flatten())
# p의 개수중에서 1개를 뽑되, p라는 확률분포를 따라서 선택한다.
sampled = np.random.choice(len(p), size=1, p=p)
# skip_ids는 skip할 단어의 목록이다.
if (skip_ids is None) or (sampled not in skip_ids):
x = sampled
word_ids.append(int(x))
return word_ids
def get_state(self):
return self.lstm_layer.h, self.lstm_layer.c
def set_state(self, state):
self.lstm_layer.set_state(*state)
class BetterRnnlmGen(BetterRnnlm):
def generate(self, start_id, skip_ids=None, sample_size=100):
word_ids = [start_id]
x = start_id
while len(word_ids) < sample_size:
# scalar값을 넣으면 안된다. rnnlm은 input을 행렬로 받기 때문이다.
# batch 1, time_size 1인 행렬이다.
x = np.array(x).reshape(1,1)
score = self.predict(x)
# batch_size 1, time_size 1, score_vector의 3차원 텐서를 벡터로 만들어준다.
p = softmax(score.flatten())
# p의 개수중에서 1개를 뽑되, p라는 확률분포를 따라서 선택한다.
sampled = np.random.choice(len(p), size=1, p=p)
# skip_ids는 skip할 단어의 목록이다.
if (skip_ids is None) or (sampled not in skip_ids):
x = sampled
word_ids.append(int(x))
return word_ids
def get_state(self):
return self.lstm_layer.h, self.lstm_layer.c
def set_state(self, state):
self.lstm_layer.set_state(*state)문장생성 코드 구현
그냥 rnnlm은 전혀 말이 되지 않는다.
corpus, word_to_id, id_to_word = ptb.load_data('train')
vocab_size = len(word_to_id)
corpus_size = len(corpus)
model = RnnlmGen()
model.load_params('Rnnlm.pkl')
start_word = 'you'
start_id = word_to_id[start_word]
skip_words = ['N', '<unk>', '$']
skip_ids = [word_to_id[w] for w in skip_words]
word_ids = model.generate(start_id, skip_ids)
txt = ' '.join(id_to_word[i] for i in word_ids)
txt = txt.replace(' <eos>', '.\n')
print(txt)
'''
you give chains kill hurricane exterior birmingham nyse ohbayashi trusts day-to-day month charles achenbaum unlike items ironically salesmen can waiver whittle literary championship educators uncertainties cathcart daimler-benz flaws sending networks brought against obligations command integrity platinum resemble mellon arise c.d.s disks unix customers strictly machines foreigners placement rooted directs cox sun facilities regarded facsimile prosperity tactics trinova withstand exposures absorbed average catalyst owed strikes machinery personal magnified budgets event song rear deeply maine kronor tracks wash playing urge defer leaping maturities upbeat necessity ample laboratories honduras gillette mather oak disciplinary title recorders performed component leads stripped calif. fiercely fha nature
'''better rnnlm을 사용하니 확실히 좋아진다.
model2 = BetterRnnlmGen()
model2.load_params('BetterRnnlm.pkl')
word_ids = model2.generate(start_id, skip_ids)
txt = ' '.join(id_to_word[i] for i in word_ids)
txt = txt.replace(' <eos>', '.\n')
print(txt)
'''
you ready to deliver the political movement.
in amex stock prices soared most of the rise in equities.
they have recovered to top in the numbers in priorities and thus connected to players he says the ratio of of banks a furniture and steel concern has engineered for an participant in its real-estate society.
assessment is clear the problem must be a wider trade important it will continue to be damaging on town the mines and only anticipate racial spare.
mr. alexander adds that the supply tiny financial markets apparently not contributed to the move freeze
'''문장을 시작으로 끊고 싶다면 아래와 같이 코딩한다.
import numpy as np
model2.reset_state()
start_words = 'the meaning of life is'
start_ids = [word_to_id[w] for w in start_words.split(' ')]
for x in start_ids[:-1]:
x = np.array(x).reshape(1, 1)
model.predict(x)
word_ids = model2.generate(start_ids[-1], skip_ids)
word_ids = start_ids[:-1] + word_ids
txt = ' '.join([id_to_word[i] for i in word_ids])
txt = txt.replace(' <eos>', '.\n')
print('-' * 50)
print(txt)
'''
the meaning of life is the general principles of the frustration of the own institutions.
the two soviet democrats are on the heels of mr. gorbachev 's long-awaited speech and liberals the china task force as an effort a single political voice predicted was being named.
senior long suggests mr. gelbart has studied the the liberal 's most ambitious political and scrap a revolution moves open after intended to grant the prominent contra committee.
if the u.s. president gives mr. krenz the borough president torrijos 's lead for this multibillion-dollar power the news u.s. ministries pulled out of the french speech
'''
chords & code // harmony with structure