RNNLM의 개선
LSTM 코드 구현
base_model
이 클래스는 파라미터를 저장하고 로드하는 메소드를 매번 모델을 만들 때마다 지정하지 않도록 만들어준 클래스이다. 모델을 만들때 이 클래스를 상속 받도록 하면 편하다.
from np import *
from util import to_gpu, to_cpu
class BaseModel:
def __init__(self):
self.params, self.grads = None, None
def forward(self, *args):
raise NotImplementedError
def backward(self, *args):
raise NotImplementedError
def save_params(self, file_name=None):
if file_name is None:
file_name = self.__class__.__name__ + '.pkl'
params = [p.astype(np.float16) for p in self.params]
if GPU:
params = [to_cpu(p) for p in params]
with open(file_name, 'wb') as f:
# parameter들을 저장
pickle.dump(params, f)
def load_params(self, file_name=None):
if file_name is None:
file_name = self.__class__.__name__ + '.pkl'
if '/' in file_name:
file_name = file_name.replace('/', os.sep)
if not os.path.exists(file_name):
raise IOError('No file : ' + file_name)
with open(file_name, 'rb') as f:
params = pickle.load(f)
params = [p.astype('f') for p in parmas]
if GPU:
params = [to_cpu(p) for p in params]
for i, param in enumerate(self.params):
param[...] = params[i]rnnlm
가중치들을 초기화해주고 미리 만들어둔 layer들을 연결해준다.
from time_layers import *
from base_model import BaseModel
class Rnnlm(BaseModel):
def __init__(self, vocab_size=10000, wordvec_size=100, hidden_size=100):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
# 가중치 초기화
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4*H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4*H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4*H).astype('f')
affine_W = (rn(H, V) / np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
# 계층 생성
self.layers = [
TimeEmbedding(embed_W),
TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True),
TimeAffine(affine_W, affine_b)
]
self.loss_layer = TimeSoftmaxWithLoss()
self.lstm_layer = self.layers[1]
# 모든 가중치와 기울기를 리스트에 모은다.
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
def predict(self, xs):
for layer in self.layers:
xs = layer.forward(xs)
return xs
def forward(self, xs, ts):
score = self.predict(xs)
loss = self.loss_layer.forward(score, ts)
return loss
def backward(self, dout=1):
dout = self.loss_layer.backward(dout)
for layer in reversed(self.layers):
dout = layer.backward(dout)
return dout
def reset_state(self):
self.lstm_layer.reset_state()rnn trainer
학습을 위한 클래스도 따로 만들어준다.
class RnnlmTrainer:
def __init__(self, model, optimizer):
self.model = model
self.optimizer = optimizer
self.time_idx = None
self.ppl_list = None
self.eval_interval = None
self.current_epoch = 0
def get_batch(self, x, t, batch_size, time_size):
batch_x = np.empty((batch_size, time_size), dtype='i')
batch_t = np.empty((batch_size, time_size), dtype='i')
data_size = len(x)
jump = data_size // batch_size
offsets = [i * jump for i in range(batch_size)]
for time in range (time_size):
for i, offset in enumerate(offsets):
batch_x[i, time] = x[(offset + self.time_idx) % data_size]
batch_t[i, time] = t[(offset + self.time_idx) % data_size]
self.time_idx += 1
return batch_x, batch_t
def fit(self, xs, ts, max_epoch=10, batch_size=20, time_size=35,
max_grad = None, eval_interval=20):
data_size = len(xs)
max_iters = data_size // (batch_size * time_size)
self.time_idx = 0
self.ppl_list = []
self.eval_interval = eval_interval
model, optimizer = self.model, self.optimizer
total_loss = 0
loss_count = 0
start_time = time.time()
for epoch in range(max_epoch):
for iters in range(max_iters):
batch_x, batch_t = self.get_batch(xs, ts, batch_size, time_size)
# 기울기를 구해 매개변수 갱신
loss = model.forward(batch_x, batch_t)
model.backward()
params, grads = remove_duplicate(model.params, model.grads)
if max_grad is not None:
clip_grads(grads, max_grad)
optimizer.update(params, grads)
total_loss += loss
loss_count += 1
# perplexity
if (eval_interval is not None) and (iters % eval_interval) == 0:
ppl = np.exp(total_loss / loss_count)
elapsed_time = time.time() - start_time
print(f'| epoch {self.current_epoch + 1} | iters {(iters + 1) / max_iters} | time {elapsed_time} | perpelxity {ppl:.2f}')
total_loss, loss_count = 0,0
self.current_epoch += 1
def plot(self, ylim=None):
x = numpy.arange(len(self.ppl_list))
if ylim is not None:
plt.ylim(*ylim)
plt.plot(x, self.ppl_list, label='train')
pplt.xlabel('반복 (x' + str(self.eval_interval) + ')')
plt.ylabel('퍼플렉서티')
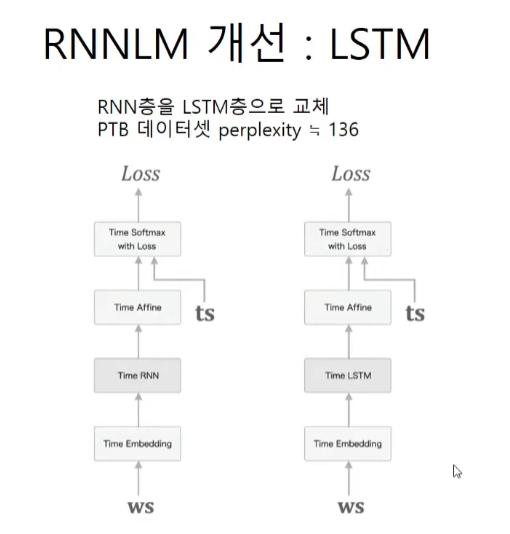
plt.show()LSTM을 교체한 것만으로 70점대도 가능하다.

추가적인 개선의 방법들
LSTM을 교체하는 것만으로도 좋은 성능이 나오지만 추가적인 방법을 알아보자.
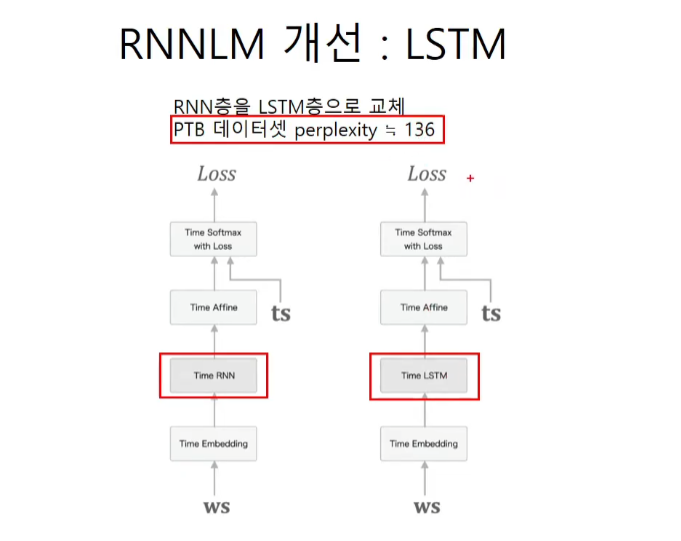
추가 LSTM layer

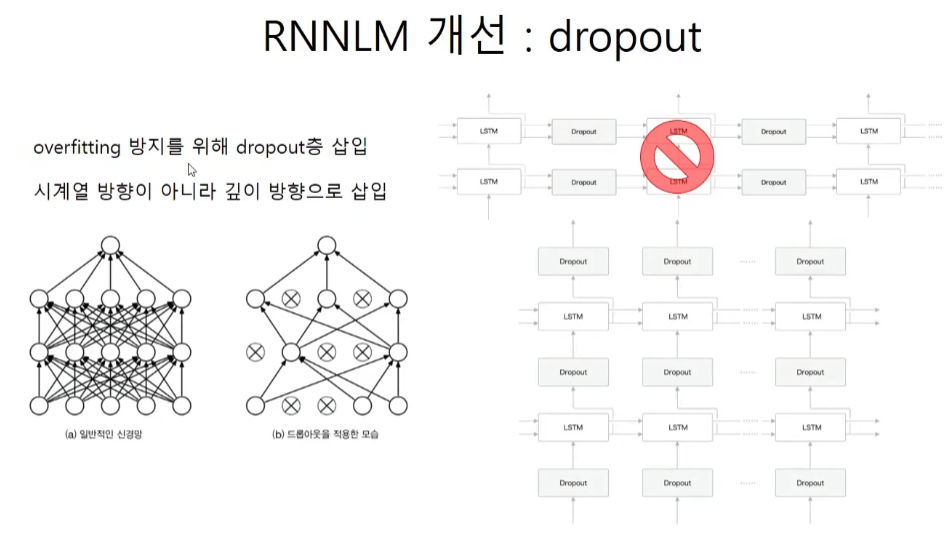
dropout
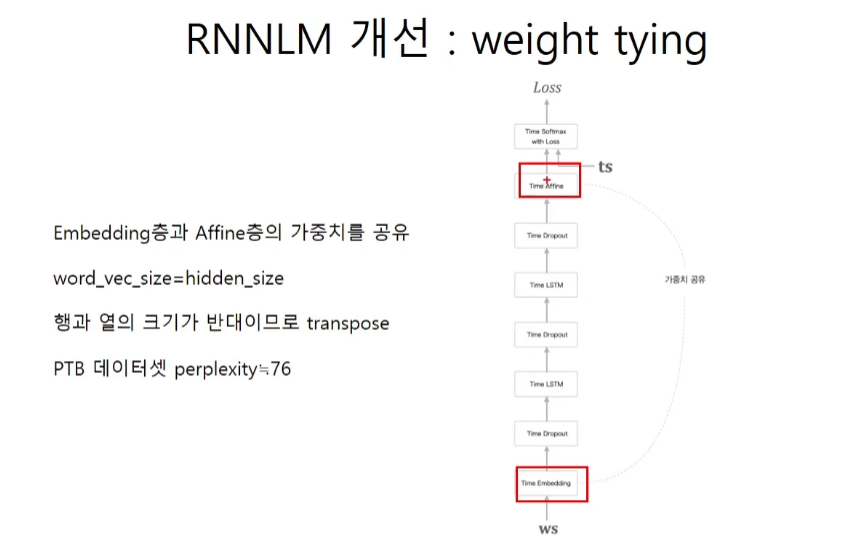
weight tying
구조를 보면 drop out -> timelstm -> dropout -> timelstm -> dropout으로 이루어져 있다.
코드구현
from time_layers import *
from base_model import BaseModel
class BetterRnnlm(BaseModel):
'''
LSTM layer를 2개 사용하고 각 층에 드롭아웃을 적용한 모델이다.
아래 [1]에서 제안한 모델을 기초로 하였고, [2]와 [3]의 가중치 공유(weight tying)를 적용했다.
[1] Recurrent Neural Network Regularization (https://arxiv.org/abs/1409.2329)
[2] Using the Output Embedding to Improve Language Models (https://arxiv.org/abs/1608.05859)
[3] Tying Word Vectors and Word Classifiers (https://arxiv.org/pdf/1611.01462.pdf)
'''
def __init__(self, vocab_size=10000, wordvec_size=650,
hidden_size=650, dropout_ratio=0.5):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx1 = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh1 = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b1 = np.zeros(4 * H).astype('f')
lstm_Wx2 = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_Wh2 = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b2 = np.zeros(4 * H).astype('f')
affine_b = np.zeros(V).astype('f')
self.layers = [
TimeEmbedding(embed_W),
TimeDropout(dropout_ratio),
TimeLSTM(lstm_Wx1, lstm_Wh1, lstm_b1, stateful=True),
TimeDropout(dropout_ratio),
TimeLSTM(lstm_Wx2, lstm_Wh2, lstm_b2, stateful=True),
TimeDropout(dropout_ratio),
TimeAffine(embed_W.T, affine_b) # weight tying!!
]
self.loss_layer = TimeSoftmaxWithLoss()
self.lstm_layers = [self.layers[2], self.layers[4]]
self.drop_layers = [self.layers[1], self.layers[3], self.layers[5]]
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
def predict(self, xs, train_flg=False):
for layer in self.drop_layers:
layer.train_flg = train_flg
for layer in self.layers:
xs = layer.forward(xs)
return xs
def forward(self, xs, ts, train_flg=True):
score = self.predict(xs, train_flg)
loss = self.loss_layer.forward(score, ts)
return loss
def backward(self, dout=1):
dout = self.loss_layer.backward(dout)
for layer in reversed(self.layers):
dout = layer.backward(dout)
return dout
def reset_state(self):
for layer in self.lstm_layers:
layer.reset_state()
chords & code // harmony with structure