CBOW 모델 완전판
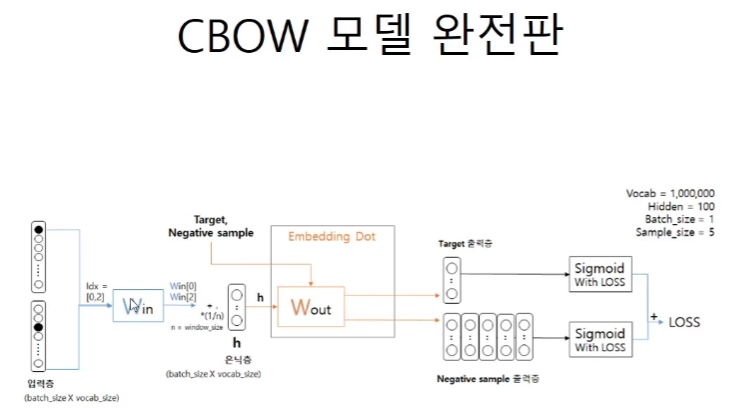
모델의 구조를 차근차근 살펴보자.
1.target을 중심으로 한 context가 n개의 인풋으로 들어온다.
2.Win은 1백만개의 단어의 embedding vector가 담긴 행렬(특정한 값의 차원의 크기를 가지는 은닉층)이므로 idx를 따로 넣어서 슬라이싱을 해서 사용한다.
3.n개의 입력층은 n개의 벡터이므로 이를 평균해준다.
4.활성화가 없다.
5.Wout은 특정 차원으로 줄여진 vector를 다시 1백만개로 돌려주는 행렬이다. 그 형태는 100 x 1백만으로 전체를 행렬곱을 해버리면 계산 비용이 너무 커지므로 특정 target과 negative sampling을 활용한 가짜값들을 slicing해서 사용한다.
6.sigmoid를 거쳐서 확률로 바꿔주고 각자의 label에 맞게 loss를 비교한다.
코드구현
class CBOW:
def __init__(self, vocab_size, hidden_size, window_size, corpus):
'''
vocab_size : 입력층의 뉴런의 개수,
hidden_size : 은닉층의 차원의 크기
window_size : 입력층의 개수
'''
V, H = vocab_size, hidden_size
# 가중치 초기화
W_in = 0.01 * np.random.randn(V, H).astype('f')
W_out = 0.01 * np.random.randn(V, H).astype('f')
# 계층 생성
self.in_layers = []
for i in range(2 * window_size):
layer = Embedding(W_in)
self.in_layers.append(layer)
self.ns_loss = NegativeSamplingLoss(W_out, corpus, power=0.75, sample_size=5)
# 모든 가중치와 기울기를 배열에 모은다.
layers = self.in_layers + [self.ns_loss]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
# 인스턴스 변수에 단어의 분산 표현을 저장한다.
self.word_vecs = W_in
# contexts는 문맥으로 target을 예측하기 위한 단어들이다.
# contexts는 열로서 나열이 된다. window크기가 1이면 2개가 된다.
def forward(self, contexts, target):
h = 0
for i, layer in enumerate(self.in_layers):
h += layer.forward(contexts[:, i])
h *= 1 / len(self.in_layers)
loss = self.ns_loss.forward(h, target)
return loss
def backward(self, dout=1):
dout = self.ns_loss.backward(dout)
dout *= 1 / len(self.in_layers)
for layer in self.in_layers:
layer.backward(dout)
return NonePTB 데이터 셋에 적용

학습코드
# coding: utf-8
import sys
sys.path.append('..')
import numpy as np
import config
# GPU에서 실행하려면 아래 주석을 해제하세요(CuPy 필요).
# ===============================================
# config.GPU = True
# ===============================================
import pickle
from trainer import Trainer
from optimizer import Adam
#from cbow import CBOW
#from skip_gram import SkipGram
from util import create_contexts_target, to_cpu, to_gpu
import ptb
# 하이퍼파라미터 설정
window_size = 5
hidden_size = 100
batch_size = 100
max_epoch = 10
# 데이터 읽기
corpus, word_to_id, id_to_word = ptb.load_data('train')
vocab_size = len(word_to_id)
contexts, target = create_contexts_target(corpus, window_size)
if config.GPU:
contexts, target = to_gpu(contexts), to_gpu(target)
# 모델 등 생성
model = CBOW(vocab_size, hidden_size, window_size, corpus)
# model = SkipGram(vocab_size, hidden_size, window_size, corpus)
optimizer = Adam()
trainer = Trainer(model, optimizer)
# 학습 시작
trainer.fit(contexts, target, max_epoch, batch_size)
trainer.plot()
# 나중에 사용할 수 있도록 필요한 데이터 저장
word_vecs = model.word_vecs
if config.GPU:
word_vecs = to_cpu(word_vecs)
params = {}
params['word_vecs'] = word_vecs.astype(np.float16)
params['word_to_id'] = word_to_id
params['id_to_word'] = id_to_word
pkl_file = 'cbow_params.pkl' # or 'skipgram_params.pkl'
with open(pkl_file, 'wb') as f:
pickle.dump(params, f, -1)analogy
코드구현
def analogy(a, b, c, word_to_id, id_to_word, word_matrix, top=5, answer=None):
for word in (a, b, c):
if word not in word_to_id:
print('%s(을)를 찾을 수 없습니다.' % word)
return
print('\n[analogy] ' + a + ':' + b + ' = ' + c + ':?')
a_vec, b_vec, c_vec = word_matrix[word_to_id[a]], word_matrix[word_to_id[b]], word_matrix[word_to_id[c]]
query_vec = b_vec - a_vec + c_vec
query_vec = normalize(query_vec)
similarity = np.dot(word_matrix, query_vec)
if answer is not None:
print("==>" + answer + ":" + str(np.dot(word_matrix[word_to_id[answer]], query_vec)))
count = 0
for i in (-1 * similarity).argsort():
if np.isnan(similarity[i]):
continue
if id_to_word[i] in (a, b, c):
continue
print(' {0}: {1}'.format(id_to_word[i], similarity[i]))
count += 1
if count >= top:
returnfrom util import most_similar, analogy
import pickle
pkl_file = 'cbow_params.pkl'
# pkl_file = 'skipgram_params.pkl'
with open(pkl_file, 'rb') as f:
params = pickle.load(f)
word_vecs = params['word_vecs']
word_to_id = params['word_to_id']
id_to_word = params['id_to_word']
# 가장 비슷한(most similar) 단어 뽑기
querys = ['you', 'year', 'car', 'toyota']
for query in querys:
most_similar(query, word_to_id, id_to_word, word_vecs, top=5)
# 유추(analogy) 작업
print('-'*50)
analogy('king', 'man', 'queen', word_to_id, id_to_word, word_vecs)
analogy('take', 'took', 'go', word_to_id, id_to_word, word_vecs)
analogy('car', 'cars', 'child', word_to_id, id_to_word, word_vecs)
analogy('good', 'better', 'bad', word_to_id, id_to_word, word_vecs)# 결과값은 3 에포크에서 학습을 멈추었기 때문에
# 그리 좋지는 않다.
[query]you
we : 0.93505859375
i : 0.89794921875
why : 0.869140625
else : 0.8681640625
maybe : 0.8583984375
[query]year
month : 0.94140625
week : 0.888671875
summer : 0.8310546875
spring : 0.80029296875
decade : 0.689453125
[query]car
truck : 0.763671875
vehicle : 0.7626953125
penny : 0.76123046875
load : 0.7607421875
machine : 0.75732421875
[query]toyota
packaging : 0.8486328125
occidental : 0.82666015625
supermarkets : 0.8212890625
renault : 0.81494140625
z : 0.81396484375
--------------------------------------------------
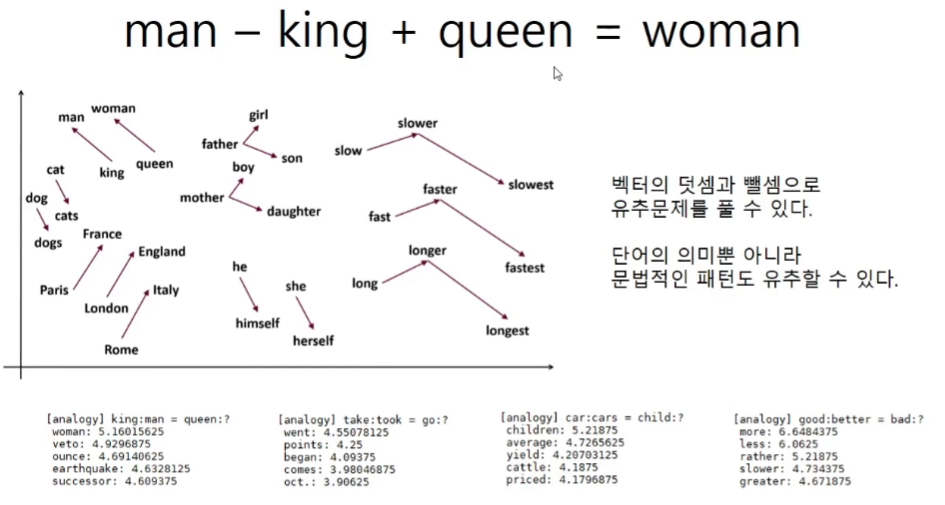
[analogy] king:man = queen:?
woman: 5.4296875
amendment: 4.546875
thing: 4.53515625
lot: 4.53125
veto: 4.51953125
[analogy] take:took = go:?
was: 4.15625
a.m: 4.0625
're: 4.0078125
are: 3.9453125
were: 3.7890625
[analogy] car:cars = child:?
a.m: 4.78515625
incest: 4.35546875
plenty: 4.28125
her: 4.26953125
i: 4.26171875
[analogy] good:better = bad:?
more: 5.00390625
rather: 4.265625
less: 3.951171875
far: 2.794921875
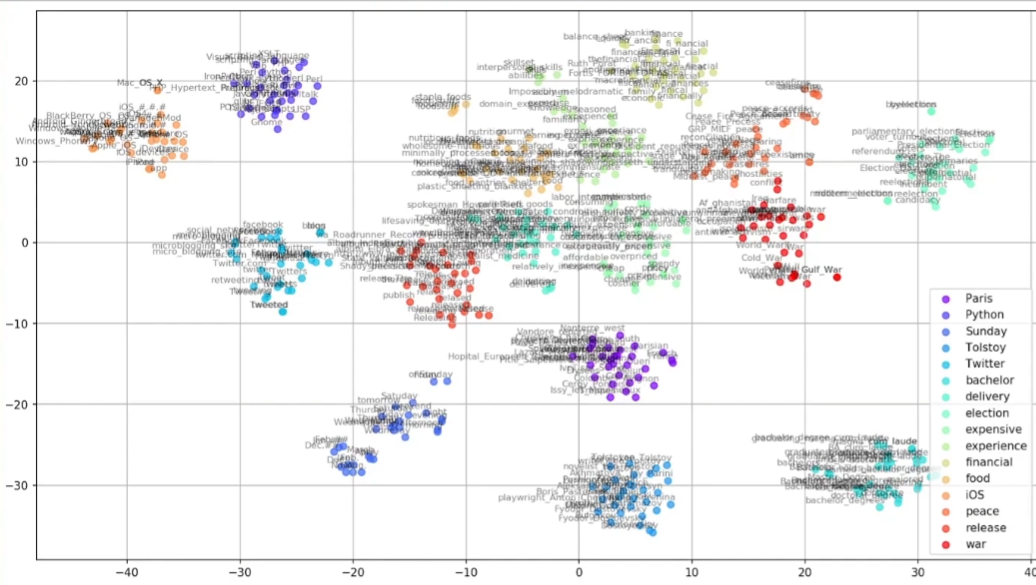
than: 2.765625word2vec


chords & code // harmony with structure