Sigmoid with loss 층
softmax with loss는 각각을 미분하기 보다는 합성을 해서 미분을 하는 것이 훨씬 깔끔하기 때문에 한꺼번에 사용을 했다. sigmoid with loss도 마찬가지이다.
가볍게 sigmoid의 미분을 보고
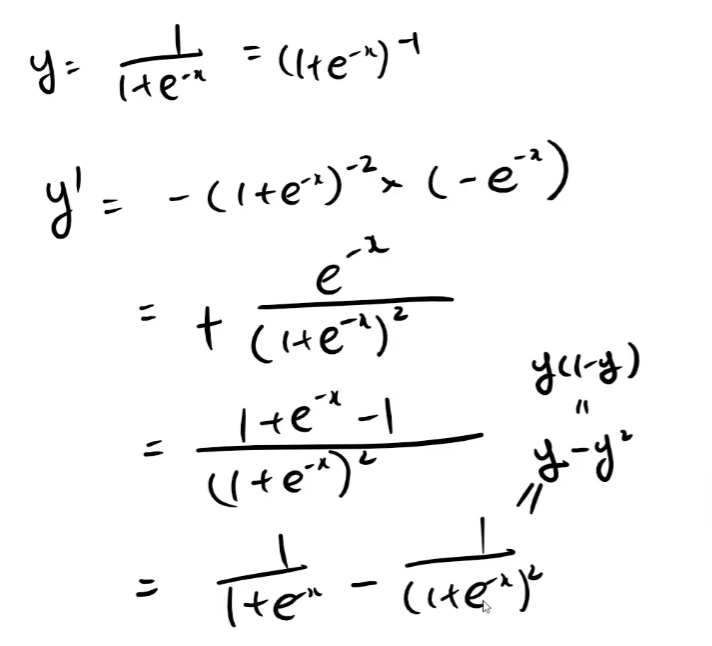
softmax with loss와 마찬가지로 미분함수는 y - t이다.
하지만 y는 예측값으로 scalar이고 t는 1 또는 0인 scalar값이다.

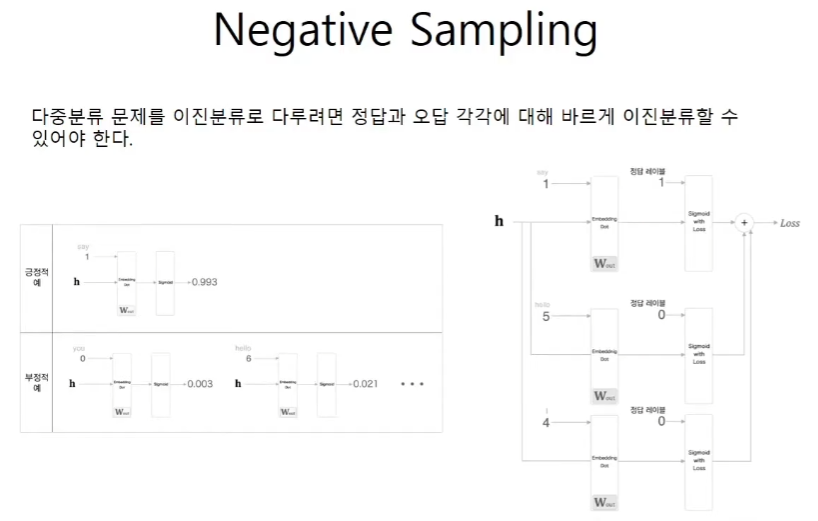
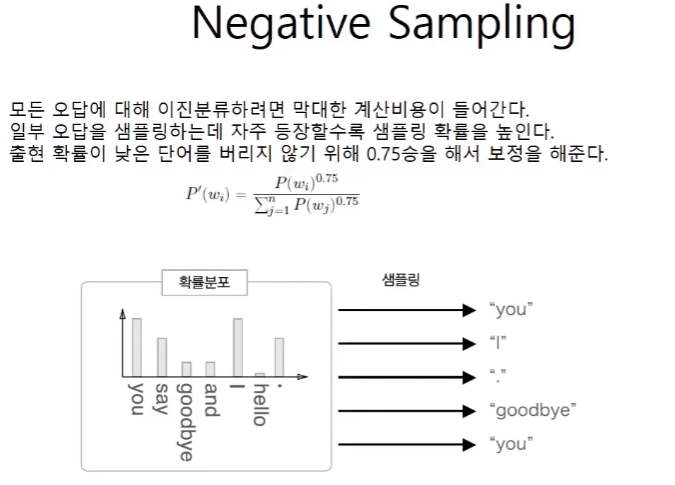
Negative Sampling
백만지선다의 문제를 이지선다 문제로 바꾸었다. 하지만 틀린 경우도 학습을 하지 않으면 test case를 inference 할 때 이를 올바르게 예측을 하지못한다. 예시를 보면 정답이 say인 경우에 틀린 답인 hello, I를 넣어준 경우를 보여준다. embedding dot의 경우는 embedding층을 통해 100 x 1백만의 wout에서 슬라이싱을 한다는 것을 볼 수 있다.
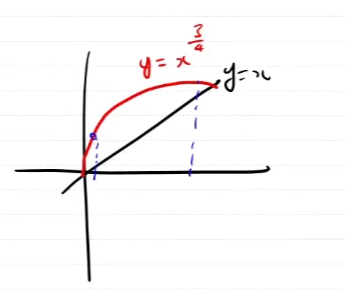
P(wi)이 단어의 확률분포이기 때문에 0.75제곱을 해주면 0에 가까운 확률이 1에 가까운 확률보다 더 커지게 된다. P'(wi)는 결국 normalize를 해주는 것이다.
class UnigramSampler:
# power는 0에 가까울 수록 보정작업이 더 dramatic해진다.
# sampler_size는 negative sampling을 몇개를 하느냐이다.
def __init__(self, corpus, power, sample_size):
self. sample_size = sample_size
self.vocab_size = None
self.worp_p = None
counts = collections.Counter()
# word_id가 corpus에서 몇번 등장했는지를 count해준다.
for word_id in corpus:
counts[word_id] += 1
vocab_size = len(counts)
self.vocab_size = vocab_size
self.word_p = np.zeros(vocab_size)
for i in range(vocab_size):
self.word_p[i] = counts[i]
self.word_p = np.power(self.word_p, power)
self.word_p /= np.sum(self.word_p)
# you goodbye가 context라면 target은 say가 된다.
def get_negative_sample(self, target):
batch_size = target.shape[0]
if not GPU:
negative_sample = np.zeros((batch_size, self.sample_size), dtype=np.int32)
for i in range(batch_size):
p = self.word_p.copy()
# target의 idx를 찾아내서 sampling되지 않도록 확률분포의 값을 0으로 만들어준다.
target_idx = target[i]
p[target_idx] = 0
p /= p.sum()
negative_sample[i, :] = random.choice(self.vocab_size, size=sample_size, replace=False, p = p)
else:
# GPU(cupy)로 계산할 때는 속도를 우선한다.
# 부정적 예에 타깃이 포함될 수 있다.
negative_sample = np.random.choice(self.vocab_size, size=(batch_size, self.sample_size),
replace=True, p=self.word_p)
return negative_sample
class NegativeSamplingLoss:
def __init__(self, W, corpus, power=0.75, sample_size=5):
self.sample_size = sample_size
self.sampler = UnigramSampler(corpus, power, sample_size)
# 층을 쌓을 때는 정답 1개에 sample_size의 개수를 더한만큼의 층이 필요하다.
self.loss_layers = [SigmoidWithLoss() for _ in range(sample_size + 1) ]
self.embed_dot_layers = [EmbeddingDot(W) for _ in range(sample_size + 1) ]
self.params, self.grads = [], []
for layer in self.embed_dot_layers:
self.params += layer.params
self.grads += layer.grads
def forward(self, h, target):
batch_size = target.shape[0]
# target의 idx를 넘겨주면 sample_size에 맞춰서 임의의 행렬을 만들어준다.
negative_sample = self.sampler.get_negative_sample(target)
# 긍정적 예 순전파
# 0번째를 정답인 경우의 상황으로 만들어준다.
# 알아두어야 할 것은 target은 정답의 idx가 일렬로 쭉 서있는 형태라는 것이다.
score = self.embed_dot_layers[0].forward(h, target)
correct_label = np.ones(batch_size, dtype=np.int32)
loss = self.loss_layers[0].forward(score, correct_label)
# 부정적 예 순전파
negative_label = np.zeros(batch_size, dtype=np.int32)
for i in range(self.sample_size):
# negative_sample은 모두 오답이므로 열별로 일렬로 떼어와서 쓰면 된다.
negative_target = negative_sample[:, i]
score = self.embed_dot_layers[1+i].forward(h, negative_target)
loss += self.loss_layers[1 + i].forward(score, negative_label)
return loss
def backward(self, dout=1):
dh = 0
# 이미지를 보면 h는 repeat으로 진행이 되었기 때문에
# 역전파를 하게 되면 sum을 해주어야 한다.
for l0, l1 in zip(self.loss_layers, self.embed_dot_layers):
dscore = l0.backward(dout)
dh += l1.backward(dscore)
return dh

chords & code // harmony with structure