오늘은 강의 대신 과제를 해결하면서 새로운 기술과 이전에 배운 것들을 복습하는 시간을 가졌다.
Swagger 사용법 정리
https://www.youtube.com/watch?v=akbdsrOpQ60 참고
서버 개발자가 API를 개발 후 클라이언트 개발자에게 어떤 방식으로 API를 사용할 수 있는지를 알려준다고 생각해보자.
엑셀로 URL과 필요한 파라미터를 알려줄 수 있는등 명세를 작성하는 방법은 다양하다.
하지만 API 명세는 관리가 어렵기 때문에 API 명세를 위한 도구로 Swagger를 쓰게 된다.
Swagger는 특정한 프로그램에 존재하는 API의 기능을 명세하고 API의 기능을 바로 테스트 하도록 도와주는 프로그램이다.
Swagger hub를 이용해서 API 명세를 작성하거나
자체적인 서버에서 스웨거 모듈을 탑재해서 그것으로 API를 명세할 수 있다.
모바일 개발에서 더욱 사용 빈도가 높다.
Swagger hub는 그 번거로운 작업을 덜 번거롭게 만들어 준다. 그 과정을 한번에 쉽고 빠르게 할 수 있다.
설계와 기획을 빠르게 하고 개발은 빠르게!
Swagger는 기본적으로 REST API를 채택한다.
Open API는 RESTapi를 위한 표준 명세 규격이다.
요청, 응답, 접근경로 등 전체 명세 경로의 방법을 규정한다. Yam, Json형식을 지원한다.
Swagger를 이용하는 방식은 2가지
특정한 서버 프로그래밍언어를 사용해서 종속적으로 사용
서버 프로그래밍 언어를 거치지 않고 독립적으로 이용
구체적인 사용법은 위의 링크 참조
Query string 값에 따른 html 렌더링
https://2dowon.netlify.app/python/flask-query-string/ 참고
#/echo?string=anything(number, str)의 url값은
#request.args.get()을 사용해서 key값을 불러온다.
#value는 하나의 str이 된다.
@app.route('/echo')
def get_value():
value = request.args.get('string')
return jsonify({"value" : value})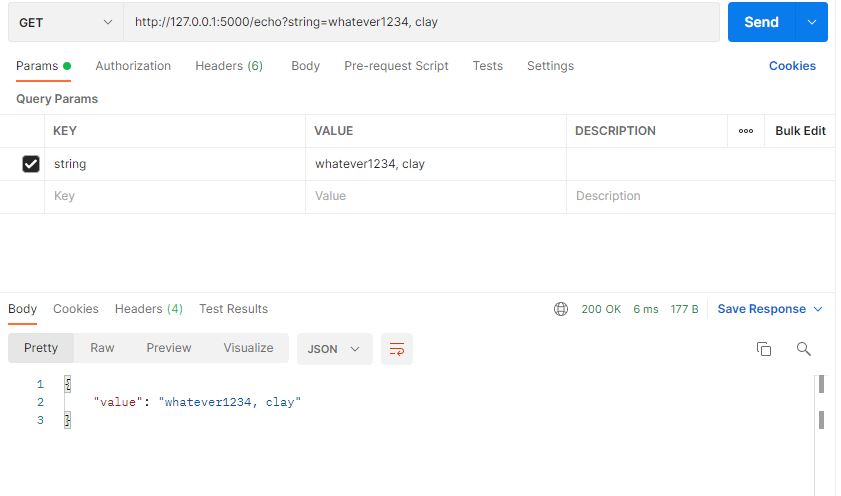
Mission 1. My New Assistant
서울에 사는 호주니는 영화 <브론즈 맨>을 보고 감동을 받았다. 특히 브론즈 맨 슈트를 장착했을 때 나오는 어시스턴트 빅수비의 성능에 금치 못했다. 이를 통해 우리의 매일매일의 생활을 윤택하게 만들어 줄 나만의 빅수비를 만들어보면 좋겠다는 생각을 했다. 호주니를 도와 한국형 자비스, 빅수비를 만들어보자.
#coffee menu를 그대로 활용했다.
from flask import Flask, jsonify, request
app = Flask(__name__)
#자원
weapons = [
{'id':0,'name':'missile','stock':1000}
]
count=1
# 여러분의 github id를 반환합니다.
@app.route('/whoami')
def get_id():
return jsonify({"name" : "Ryu Jiwoo"})
# Key와 Value
@app.route('/echo')
def get_string():
string_value = request.args.get('string')
return jsonify({"value" : string_value})
# Read
@app.route('/weapon')
def get_weapon():
return jsonify(weapons)
# Create
@app.route('/weapon', methods=['POST'])
def create_weapon():
request_data = request.get_json()
global count
new_weapon = {
'id' : count,
'name' : request_data['name'],
'stock' : request_data['stock']
}
count += 1
weapons.append(new_weapon)
return jsonify(new_weapon)
# Update
@app.route('/weapon/<int:id>', methods=['PUT'])
def update_weapons(id):
request_data = request.get_json()
update_weapon = {
'id' : id,
'name' : request_data['name'],
'stock' : request_data['stock']
}
weapons[id] = update_weapon
return jsonify(update_weapon)
# Delete
@app.route('/weapon/<int:id>', methods=['DELETE'])
def delete_weapon(id):
del weapons[id]
return {
'delete' : 'seccess'
}
if __name__ == '__main__':
app.run()Mission 2. My New Assistant
캐릭터는 저마다 지능, 힘, ... 등 다양한 수치를 지니고 있다. 이러한 수치의 합이 가장 큰 캐릭터는 누구인가? 이를 보이기 위한 과정을 보여라.
좋은 캐릭터와 나쁜 캐릭터의 능력치들의 수치 분포를 알고 싶다. 이를 표현하기 위한 적절한 그래프를 선택해서 이를 위한 전처리를 진행하고, 시각화하여라.
기본 문제는 그간 배운 데이터의 정렬 및 시각화 방법을 이용하면 된다.
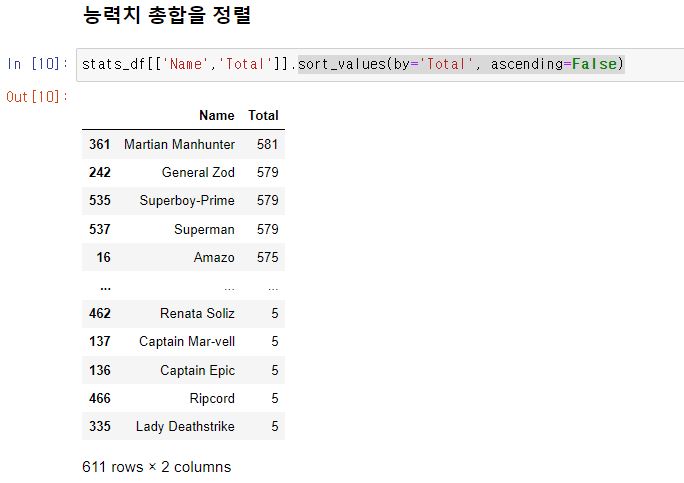
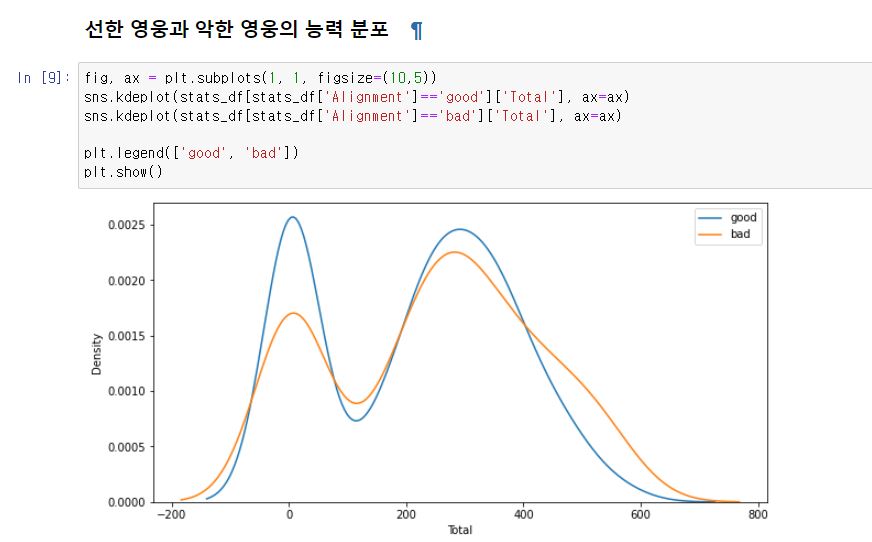
데이터 합치기 (Merge)
https://pandas.pydata.org/pandas-docs/stable/user_guide/merging.html#merging-join
참고
판다스는 Series와 DataFrame 간에 쉽게 데이터를 합칠 수 있도록 join과 merge와 같은 연산을 제공한다.
Extra Mission
1.캐릭터는 저마다 지능, 힘, ... 등 다양한 수치를 지니고 있다. 또한 각 캐릭터는 DC, 마블 등 다양한 코믹스 회사를 바탕으로 하고 있다. 어떤 코믹스 회사의 캐릭터들이 능력치 합의 평균이 가장 큰가? 이를 보이기 위한 과정을 보여라.
2.좋은 캐릭터와 나쁜 캐릭터가 격돌한다고 한다. 격돌하는 경우 캐릭터들의 능력치의 합의 평균이 큰 팀이 이긴다고 한다. 단, 불의를 못참는 중립 캐릭터들은 중립캐릭터가 없었을 당시에 열세인 팀에 가담한다. 이러한 상황일때 결과적으로 어떤 캐릭터 진영이 승리할 것인가? 이를 보이기 위한 과정을 보여라.
추가 과제는 두 가지 데이터(stats만을 가진 데이터와 publisher만을 가진 데이터)를 합쳐주어야 했다.
#on: Column or index level names to join on.
#Must be found in both the left and right DataFrame and/or Series objects.
#If not passed and left_index and right_index are False,
#the intersection of the columns in the DataFrames and/or Series will be inferred to be the join keys.
newstats_df = pd.merge(stats_df, info_df, on='Name')
newstats_df