도메인 지식이 있어야 이 자료가 validate한지를 알 수 있다.
데이터 사이즈 체크
엑셀, pandas, SQL, Spark
df.shape()
기술통계량
df.describe()
데이터 전처리
-
column
df[['city','country']] = df['address'].split(',', expand=True) -
데이터중복처리
- unique Column이어야하는경우, 중복값이 있을경우
df.Player.value_counts() - 얼마나 중복
df[df.Player == "Ersan"] - 판다스 기능으로 drop하기
df = df.drop_duplicates("Player", keep="first")
df = df.reset_indes(drop=True)
SQL
structured querry Language
데이터베이스 시스템에서 자료를 처리하는 용도로 사용되는 구조적 데이터 질의 언어
SQL은
정형데이터를
RDB relation databases
OSQL은
비정형데이터를
Json, 이미지, 문장
규약을 지킨 여러 DB
MySQL, MariaDB, Oracle DB
DB마다 쿼리를 날리는 방법이 조금씩 다르다.
SQL을 크게 3개로 나누면
DDL : 데이터 구조를 정의define하는 명령어
DML : 데이터를 조회하거나 조작manipulate하는 명령어
DCL : 데이터베이스 접근 권한을 관리control하는 명령어
DML의 예시
CRUD
가져오기, 추가하기, 갱신하기, 삭제하기
Flask
MySQL이라면 pymysql모듈을 이용해서 접근
import pymysql
# 다른 컴퓨터의 주소
# 혹은 다른 인스턴스(in cloud)
# DB를 정의
db = pymysql.connect("127.0.0.1:3306
")
try :
with db.cursor() as cursor
# you라고 하는 테이블에서 모든걸 가져와!
sql = 'SELECT * FROM you'
# 인자로 SQL 문자열을 전달
# f’SELECT {target} FROM you'
# SELECT name, breed FROM you
# SELECT name FROM you WHERE id == 10;
cursor.execute(sql)
# 특정 부분을 가져올 수 있게 함
result = cursor.fetchall()
finally :
db.close()
cursor = db.cursor()위의 방법은 깡 SQL
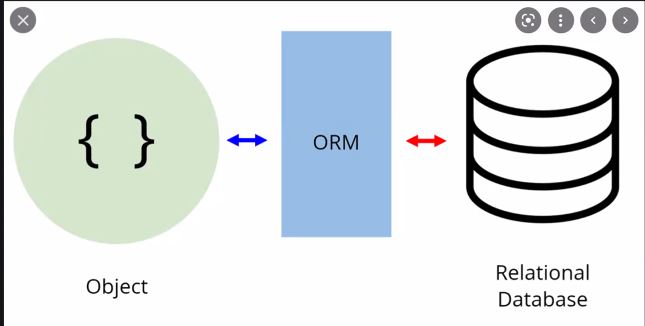
ORM 정의
Object Related Model
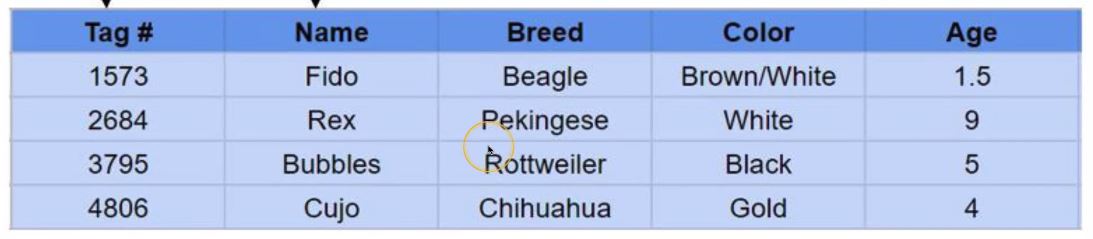
Tag = 1573, Name = Fido, Breed = Beagle, Color = Brown/White, Age = 1.5
Class Dog
데이터 만들기
class Coffe(Base):
# 대응되는 데이터베이스 테이블의 이름
__tablename__='coffee'
id = Column(Integer, primary_key=True)
# 새로운 열을 만듦
name = Column(String(20))
price = Column(Integer)create와 동일한 역할을 한다.
id는 pk=True라면 auto_increment가 지정
데이터 추가하기
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
session = Session()
new_coffee = Coffee(name="Dolce Latte", price=6000)
session.add(new_coffee)
session.commit()insert와 동일한 역할을 하는데 훨씬 직관적임
데이터 가져오기
#.filter()로 조건 검색
result = session.query(Coffee).all()
for row in result:
print(row.name, row.price)
chords & code // harmony with structure