참고: https://dining-developer.tistory.com/30
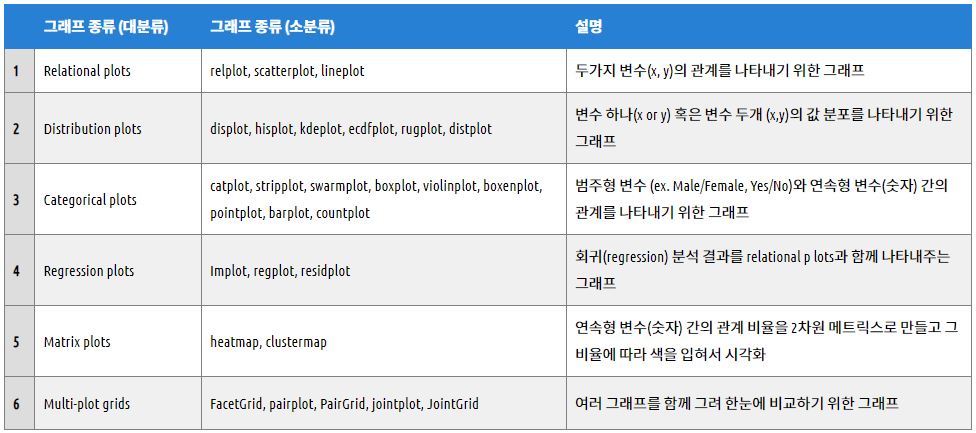
Seaborn
Seaborn은 matplotlib 기반의 시각화 라이브러리이다. 유익한 통계 그래픽을 그리기 위한 고급 인터페이스를 제공한다. seaborn에서 기본으로 제공하는 dataset으로 그래프를 그려보자.
출처 : https://coding-kindergarten.tistory.com/129?category=1003348
데이터셋 불러오기
import seaborn as sns
df = sns.load_dataset('tips')
df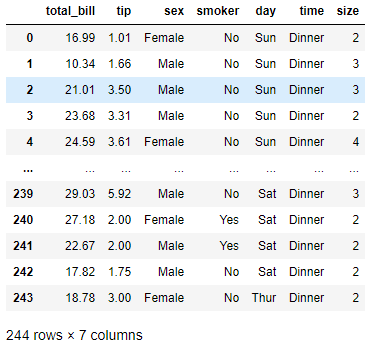
Distruibution Plot
Distribution Plot은 데이터의 분포를 시각화하는데 도움이 된다. 이 그래프를 사용하여 데이터의 평균(mean), 중위수(median), 범위(range), 분산(variance), 편차(deviation) 등을 이해할 수 있다.
1.Hist Plot
변수에 대한 히스토그램을 표시한다.
하나 혹은 두 개의 변수 분포를 나타내는 전형적인 시각화 도구로 범위에 포함되는 관측수를 세어 표시한다.
#total_bill에 대한 질량분포
sns.histplot(x=df['total_bill'])
# sns.displot(x=df['total_bill'], kind='hist')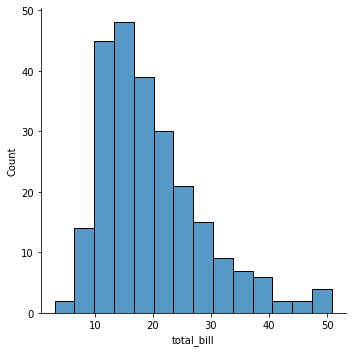
#total_bill과 tip에 관한 질량 분포
sns.histplot(x=df['total_bill'], y=df['tip'])
#displot은 Distribution plot의 인터페이스로
#적당한 plot 종류를 인자로 줌으로써
#여러 가지 그래프를 시각화해준다.
# sns.displot(x=df['total_bill'], y=df['tip'], kind='hist')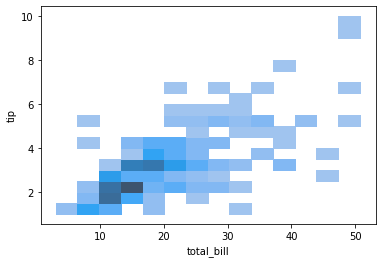
2.KDE Plot
하나 혹은 두 개의 변수에 대한 분포를 그린다.
histplot은 절대량이라면 kdeplot은 밀도 추정치를 시각화한다.
그래서 결과물로는 연속된 곡선의 그래프를 얻을 수 있다.
# 단일 변수에 대한 질량 밀도(추정) 그래프
sns.kdeplot(x=df['total_bill'])
# sns.displot(x=df['total_bill'], kind='kde')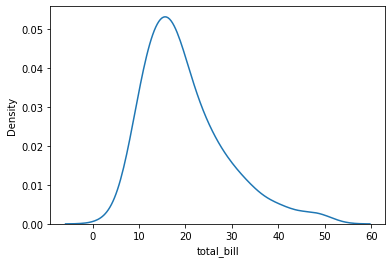
# 두개의 변수에 대한 질량 밀도(추정) 그래프
sns.kdeplot(x=df['total_bill'], y=df['tip'])
# sns.displot(x=df['total_bill'], y=df['tip'], kind='kde')
3.ECDF Plot
누적 분포를 시각화해준다.
실제 관측치의 비율을 시각화한다는 장점이 있다.
# 단일 변수에 대한 ecdf plot
sns.ecdfplot(x=df['total_bill'])
# sns.displot(x=df['total_bill'], kind='ecdf')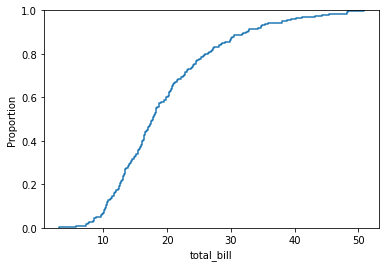
4.Rug Plot
x축과 y축을 따라 눈금을 그려서 주변 분포도를 표시한다.
개발 관측치에 대한 위치를 보여줌으로써 다른 그림들을 보완하는데 주로 쓰인다.(즉, 이 그래프만 단일로 잘 쓰지는 않는다.)
# 주황색 선이 rugplot, 파란색 선이 kdeplot이다. rugplot은 보조 그래프 정도로 참고용 이라보면 된다
sns.kdeplot(x=df["total_bill"])
sns.rugplot(x=df["total_bill"])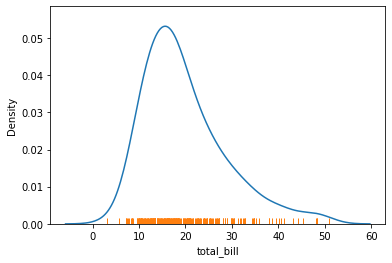
Categorical Plot
지금부터 설명하는 plot은 범주형(categorical) 변수를 이해하는데 도움이 된다. 일변량(univariate) 혹은 이변량(bivariate) 분석에 사용된다.
5.Bar Plot
이변량(bivariate) 분석을 위한 plot이다.
x축에는 범주형 변수, y축에는 연속형 변수를 넣는다.
sns.barplot(x = df['sex'], y = df['tip'])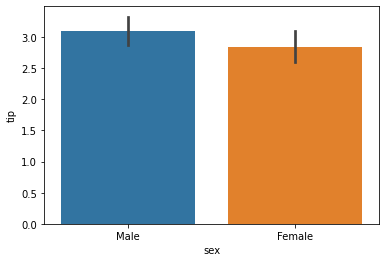
6.Count Plot
범주형 변수의 발생 횟수를 샌다.
일변량(univariate) 분석이다.
sns.countplot(x = df['sex'])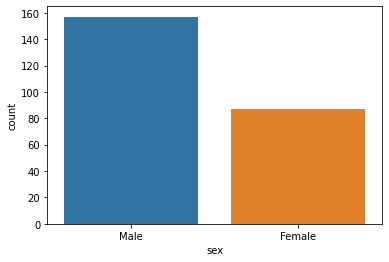
7.Box Plot
최대(maximum), 최소(minimum), mean(평균), 1 사분위수(first quartile), 3 사분위수(third quartile)를 보기 위한 그래프
특이치(outliar)를 발견하기에도 좋다.
단일 연속형 변수에 대해 수치를 표시하거나, 연속형 변수를 기반으로 서로 다른 범주현 변수를 분석할 수 있다.
sns.boxplot(x = df['total_bill'])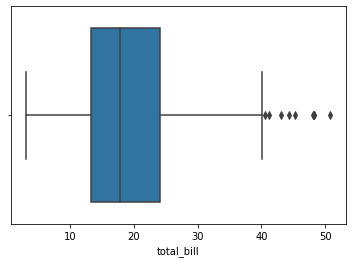
sns.boxplot(y = df['total_bill'], x = df['smoker'])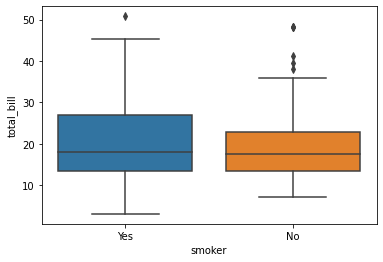
8.Violin Plot
Box Plot과 비슷하지만 분포에 대한 보충 정보가 제공된다.
sns.violinplot(y = df['total_bill'], x = df['smoker'])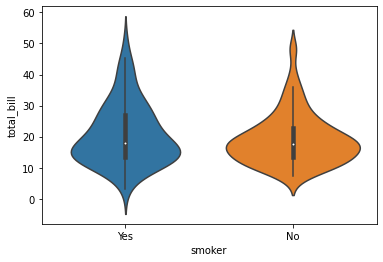
9.Strip Plot
연속형 변수와 범주형 변수 사이의 그래프이다.
산점도(scatter plot)로 표시되는데, 범주형 변수의 인코딩을 추가로 사용한다.
sns.stripplot(y = df['total_bill'], x = df['smoker'])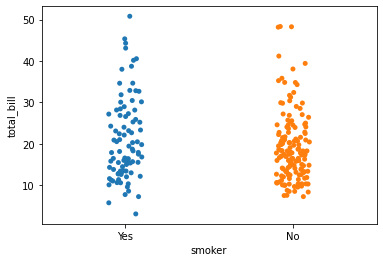
10.Swarm Plot
Strip plot과 violin plot의 조합이다.
데이터 포인트 수와 함께 각 데이터의 분포도 제공한다.
sns.swarmplot(y = df['total_bill'], x = df['smoker'])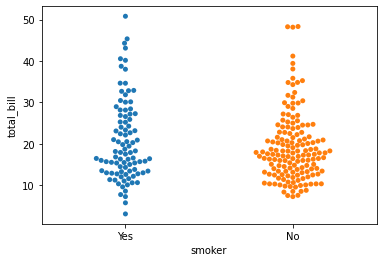
Matrix Plot
시각화를 위해 2차원 행렬 데이터를 사용하는 특별한 유형의 plot이다. 매트릭스 데이터에서는 사이즈가 크기 때문에 패턴을 분석하고 생성하기 어렵다. 다음에 오는 plot은 매트릭스 데이터에 색상을 제공함으로써 조금 더 분석하기 쉽게 도와준다.
Multi-plot Grid
Grid plot은 시각화에 대한 제어력을 높이고 코드 한 줄로 다양한 그래프를 표시한다.
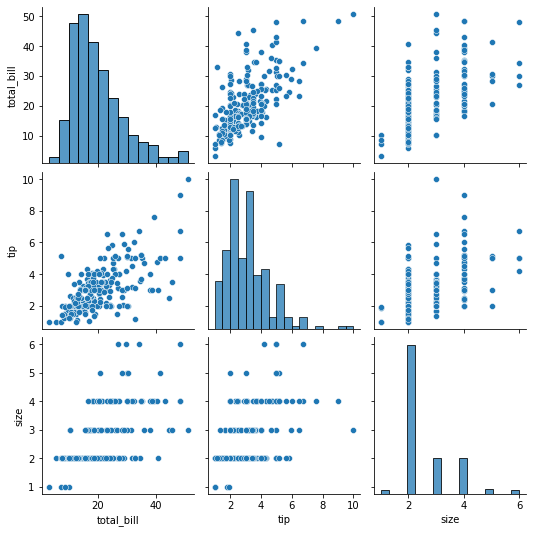
15. Pair Plot
데이터셋을 통째로 넣으면 숫자형 특성에 대하여 각각에 대한 히스토그램과 두 변수 사이의 scatter plot을 그린다.
이 한 줄이면 데이터를 한눈에 보기 쉬워서 애용한다.
다른 기능이나 유연성이 더 필요하다면 pairgrid를 사용하면 된다.
sns.pairplot(df)