확률Probablility
-
상대 도수에 의한 정의
똑같은 실험을 무수히 많이 반복할 때 어떤 일이 일어나는 비율, 상대 도수의 극한
ex)몇백년 간의 기록을 바탕으로 비가 오는 비율을 계산 -
고전적 정의
표본공간sample space : 모든 가능한 실험 결과들의 집합
사건 : 관심 있는 실험 결과들의 집합, 표본 공간의 부분집합
어떤 사건이 일어날 확률 : 표본 공간의 모든 원소가 일어날 확률이 같은 경우 사건의 원소의 수 / 표본 공간의 원소의 수
고전적 정의의 예시
주사위를 2번 던졌을 때 합이 10일 확률
표본 공간 : 36개의 언소
합이 10일 사건 : {(4,6), (5,5), (6,4)}
확률 = 3/36
확률의 정리
어떤 사건 A에 대해서 A가 일어날 확률은 P(A)으로
확률 1 : 반드시 그 사건이 일어남
확률 0 : 사건이 절대로 일어나지 않음
확률은 0에서 1사이의 값을 가짐
고전적 확률
표본 공간의 원소의 수를 세야함
사건의 원소의 수를 세야 함
따라서 경우의 수를 쉽게 셀 수 있는 방법이 필요
조합combination
어떤 집합에서 순서에 상관없이 뽑은 원소의 집합

순열이 r만큼 뽑아서(조합) 다시 배치하는 것(r!)을 의미하기에 조합은 순열에 r!을 나누어주면 된다.
고전적 확률의 계산 예시
검은공 3개 흰공 4개에서 2개의 공을 무작위로 뽑을 때, 둘다 흰공이 나올 확률은?
표본공간 7C2 = 21
사건의 경우의 수 = 4C2 = 6
확률 = 6/21
검은공 3개 흰공 4개에서 3개의 공을 무작위로 뽑을 때, 흰공 1개, 검은 공 2개가 나올 확률은?
표본공간 7C3 = 35
사건의 경우의 수 = 4C1 x 3C2 = 12
확률 = 12/35
덧셈 법칙Addition Law
확률의 계산에 덧셈과 뺄셈을 적용하는 방법
덧셈 법칙의 예시
주사위를 던지는 실험
표본 공간 : S = {1,2,3,4,5,6}
사건 A, 주사위의 숫자가 짝수인 사건, P(A) = 1/2
사건 B, 주사위의 크기사 4이상인 사건, P(B) = 1/2
사건 A나 사건 B가 일어날 확률 = 4/6
사건 A와 사건 B가 동시에 일어날 확률 = 2/6
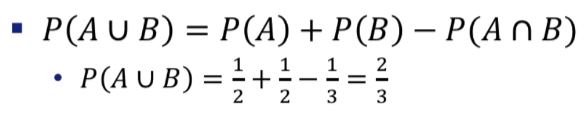
덧셈 법칙의 예시2
1000명의 사림이 있는데, 남자의 비율이 40%, 20세 미만의 비율이 43%, 20세 미만이면서 남자인 사람의 비율이 15%라고 한다.
한 명의 사람을 랜덤하게 뽑을 때 남자이거나 20세 미만일 확률은?
A : 남자일 사건, P(A) = 0.4
B : 20세 미만일 사건, P(B) = 0.43
P(AnB) = 0.15
P(AUB) = P(A) + P(B) - P(AnB) = 0.68
서로 배반Mutually Exclusive
두 사건의 교집합이 공집합일 경우(P(AnB)=0)에 두 사건은 서로 배반이라고 한다.
따라서 P(AUB) = P(A) + P(B)
조건부 확률Conditional Probability
어떤 사건 A가 일어났을 때, 다른 사건 B가 일어날 확률
P(B|A) = P(AnB)/P(B) 단, P(A) > 0
조건부 확률의 예시
주사위 하나를 던졌는데, 4이상의 수가 나왔다. 그때 그 수가 짝수일 확률은?
사건 A : 4이상의 수가 나오는 사건, P(A) = 1/2
사건 B : 짝수가 나오는 사건, P(AnB) = 2/6
P(B|A) = 1/3 / 1/2 = 2/3
곱셈법칙
조건부 확률을 이용해서 P(AnB) = P(B|A)P(A)임을 알 수 있다.
어떤 학교에서 60%의 학생이 남학생이다. P(A) = 0.6
그 학교 남학생의 경우 80%는 축구를 좋아한다. (B|A) = 0.8
그 학교에서 학생 1명을 랜덤하게 뽑았을 때 축구를 좋아하는 남학생일 확률은? P(AnB) = P(B|A)P(A) = 0.48
서로 독립
P(B|A) = P(B)인 경우에 두 사건을 서로 독립한다고 말한다.
P(AnB) = P(A)P(B)가 성립한다.
여사건
사건 A의 여사건 : A^c
사건 A가 일어나지 않을 사건
어떤 사건과 그 여사건은 서로 배반이다. 둘 중 하나는 반드시 일어난다.
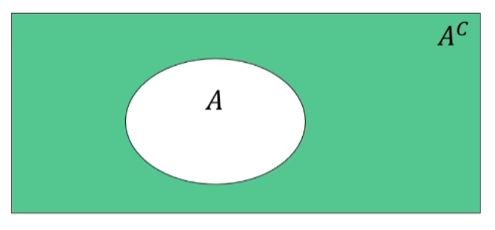
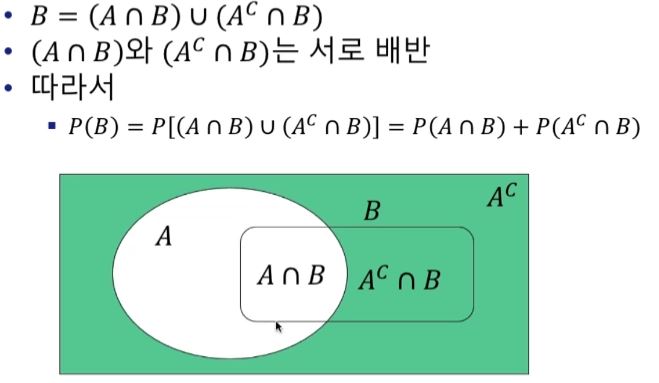
확률의 분할 법칙
사건 B는 다음과 같이 나누어진다.
확률의 분할 법칙의 예시
어떤 사파리에서는 70%가 사자이고, 나머지가 호랑이이다. P(A) = 0.7
사자는 60%가 2살 이상이고, 호랑이는 40%가 2살 이상이다. P(B|A) = 0.6, P(B|A^c) = 0.4
전체 동물 중 2살 이상인 동물의 비율은?
P(B) = P(BnA) + P(BnA^c) = 0.6x0.7 + 0.4x0.3 = 0.54
동물 한마리를 선택했는데, 이 동물이 2살 이상이었다.
이 동물이 사자일 확률은? P(A|B)
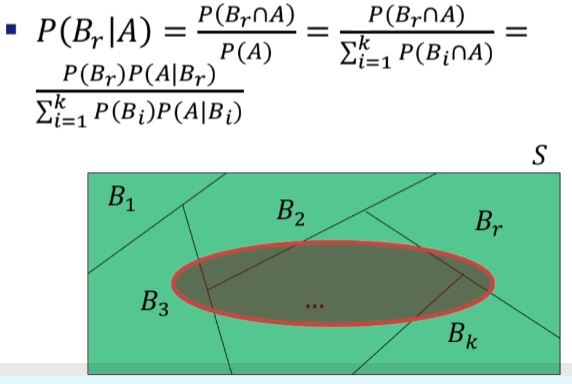
베이즈 정리
P(A|B)를 P(A)만을 이용해서 정리하는 방법
처음의 확률 : 사전 확률prior probability
수정된 확률 : 사후 확률posterior probability
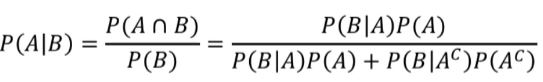
베이즈 정리의 예시
어떤 사람이 검은색과 흰색의 셔츠를 가지고 있는데, 매일 아침 3/4정도는 검은색 셔츠를 입고, 1/4정도는 흰색 셔츠를 입는다. P(A) = 3/4
이 사람이 검은색 셔츠를 입었을 때는 3/4정도 넥타이를 매고, 흰색 셔츠를 입었을 때는 1/2정도 넥탁이를 맨다고 하자. P(B|A) = 3/4, P(B|A^c) = 1/2
어느날 이사람이 넥타이를 맸다면, 이 사람이 검은색 셔츠를 입었을 확률을 구하시오.P(A|B)
확률분포
확률변수Random Variable
랜덤한 실험 결과에 의존하는 실수 즉, 표본 공간의 부분 집합에 대응하는 실수
X나 Y 같은 대문자로 표시되는, 표본 공간에서 실수로 대응되는 함수로 정의
- 주사위 2개를 던지는 실험
주사위 숫자의 합 - 하나의 확률변수
주사위 숫자의 차 - 하나의 확률변수
두 주사위 숫자 중 같거나 큰 수 - 하나의 확률변수 - 동전 10개를 던지는 실험
동전의 앞면의 수
첫번째 앞면이 나올 때까지 던진 횟수
이산확률변수discrete random variable
확률변수가 취할 수 있는 모든 수 값들을 하나씩 셀 수 있는 경우
주사위, 동전 등
연속확률변수continuous random variable
셀수 없는 경우
랜덤하게 선택된 학생의 키
확률분포Probability Distribution
확률변수가 가질 수 있는 값에 대해 확률을 대응시켜주는 관계
어떤 확률 변수 X가 가질 수 있는 값이 0,1,3,8일때
각 값이 나올 확률을 P(X=0) = 0.2, P(X=1) = 0.1, P(X=3) = 0.5, P(X=8) = 0.2으로 대응 시켜주는 것
확률분포의 표현은 표, 그래프, 함수 등으로 매우 다양하다.
확률분포의 예
주사위 2개를 던지는 실험
- 확률변수 X : 주사위 숫자의 합
X = {2,3,4,...,12}
P(X=12) = 1/36 - 확률변수 Y : 주사위 숫자의 차이
Y = {0,1,2,...,5}
P(Y=5) = 2/36
주사위를 던질 때마다 X의 값이 달라질 수 있다. n번 실험하면, n개의 숫자가 나온다. 이 n개의 숫자의 평균과 분산을 계산할 수 있다.
따라서 확률 변수 X도 평균과 분산을 가진다. 이 평균과 분산을 모집단의 평균과 분산이라 할 수 있다.
이산확률변수의 확률분포
보통 함수로 주어짐
P(X=x) = f(x), 확률질량함수
많은 경우에 확률분포가 함수로 주어진다.
이산확률변수의 평균
기대값expected value라고도 함
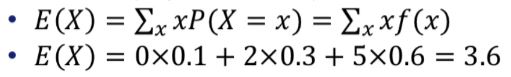
이산확률변수의 분산
실험을 할 때마다 확률변수의 값이 달라질 수 있음, 따라서 그 변동의 정도인 분산을 계산할 수 있다.
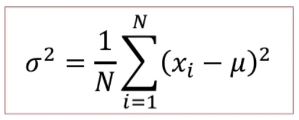
편차의 제곱의 평균이다. Var(X)라고도 한다.
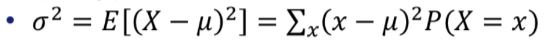
분산은 제곱의 평균에서 평균의 제곱을 빼면 쉽게 구할 수 있다.
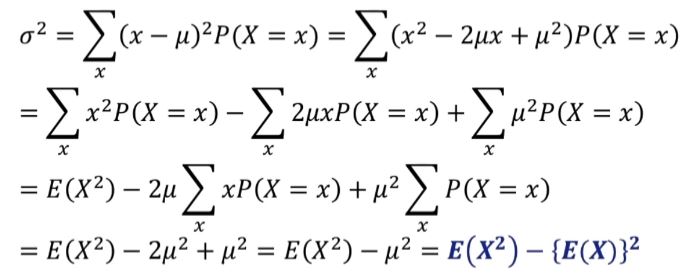
이산확률변수의 표준편차
분산의 양의제곱근이다. SD(X)
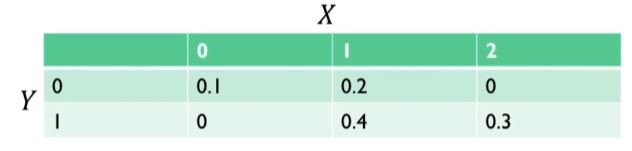
결합확률 분포joint probability distrubution
두개 이상의 확률변수가 동시에 취하는 값들에 대해 확률을 대응시켜주는 관계
확률변수 X : 학 학생이 가지는 휴대폰의 수
확률변수 Y : 한 학생이 가지는 노트북의 수
주변확률분포marginal probability distribution
결합확률분포를 통해 각 확률변수의 확률분포를 도출 할 수 있음
P(X=0,1,2) = 0.1, 0.2, 0.3
P(Y=0,1) = 0.3, 0.7
공분산Covariance
두 확률변수 사이의 관계를 알기 위해서 계산한다.
고등학교 1학년 학생들에 대해서
확률변수 X : 키
확률변수 Y : 몸무게
확률변수 Z : 수학성적
A = (X - ux)(Y - uy) : 양이 될 가능성이 높음, 키가 크면 몸무게가 높을 가능성이 높기 때문
B = (X - ux)(Z - uz) : 양과 음이 될 가능성이 비슷하다
A, B를 확률변수(랜덤하게 추출된 값으로부터 도출 되는 실수 값이기에)로 보고 평균과 분산을 구할 수 있다.
확률변수 X와 Y의 공분산 : (X - ux)(Y - uy)의 평균
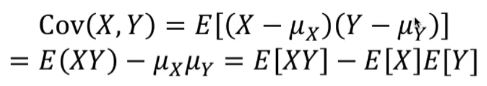
XY의 기댓값을 계산해서 X와 Y의 기댓값을 곱한것을 빼준다.
상관계수correlation coefficient
1에 가까울 수록 두 값의 관계가 크다고 말할 수 있다.
공분산은 각 확률변수의 절대적인 크기에 영향을 받는다.
단위에 의한 영향을 없앨 필요로 사용한다.
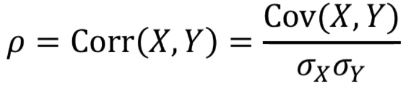
예시
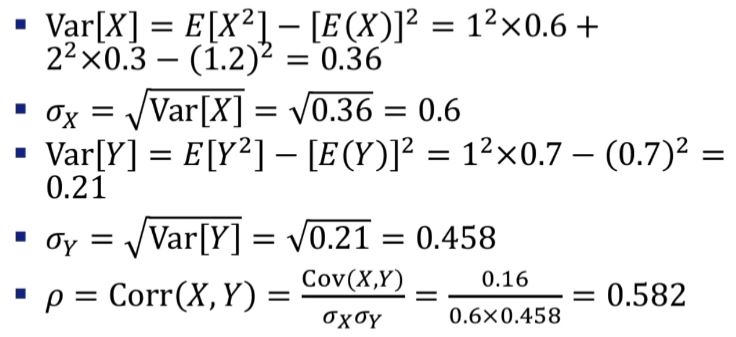
몇가지 확률분포
이항분포
베르누이 시행Bernoulli trials
정확하게 2개의 결과만을 가지는 실험, ex)동전 던지기
일반적으로 성공과 실패로 결과를 구분
성공의 확률 : p
확률변수 X : n번의 베르누이 시행에서 성공의 횟수, 이항확률변수라고 함
이항분포binormal distribution : 이항확률변수의 확률분포
이항확률변수 X의 확률분포
n번의 시행에서 x번을 성공한 확률은 성공은 x번, 실패는 n-x번을 할 확률에 그 사건이 발생하는 경우의 수인 nCx를 곱하는 것과 같다. nCx * p^x(1-p)^(n-x)
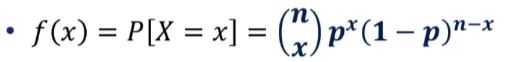
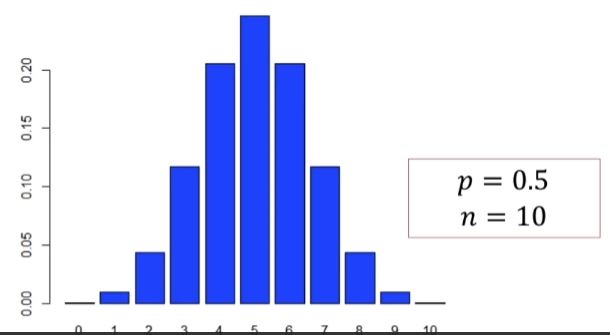
scipy로 구현
from scipy import stats
#binom이항분포 cdf는 (0)보다 같거나 작은 확률을 계산해줌
1 - stats.binom.cdf(0, n=3, p=0.2)평균, 분산, 표준편차
평균 : E(X) = np
분산 : Var(X) = np(1-p)
표준편차 : 분산의 양의제곱근
1 - stats.binom.stats(n=3, p=0.2)
#return -> array(0.6), array(0.48)정규분포
연속확률 변수의 확률분포
숫자가 무수히 많기 때문에 특정 확률변수 X의 확률은 0이 된다.
확률밀도함수probability desity function, f(x)
f(x)의 값이 큰 곳에 x의 값들이 밀집되어 있다.
p[a<=X<=b] = f(x)를 a부터 b까지 적분한 값이 된다.
정규분포의 확률밀도 함수
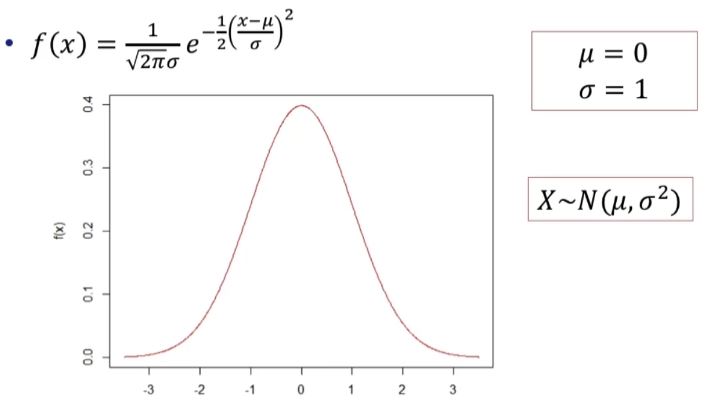
함수 자체는 수많은 데이터들로부터 일반화한 것이다.
표준정규확률변수standard normal random variable
임의의 정규확률분포는 계산이 어렵기 때문에 표준정규확률분포로 바꾸어준다.
X가 정규분포를 따르는 확률변수일 경우
Z = (X - U) / 표준편차
표준정규분포standard normal distribution
Z~N(0,1)
표준 정규분포표 P[Z <= z]
이미 계산되어진 표준정규확률분포표를 바탕으로 쉽게 확률을 구할 수 있게 된다.
예시
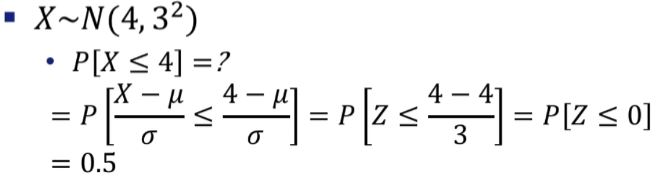
#4보다 작을 확률, location은 평균, scale이 표준편차이다.
stats.norm.cdf(4, loc=4, scale=3)예시2
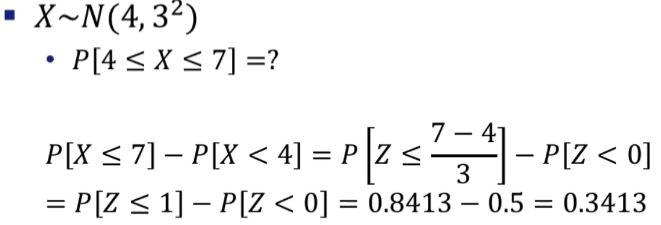
stats.norm.cdf(7, loc=4, scale=3) - stats.norm.cdf(4, loc=4, scale=3)예시3
어떤 종목의 주가는 전날 종가를 평균으로 하고, 표준편차가 50인 정규분포를 따른다고 한다. 오늘 종가가 1,000원일 때, 내일 주가가 1,100원 이상이 될 확률은?
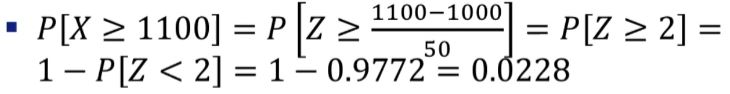
1 - stats.norm.cdf(1100, loc=1000, scale=50)포아송 분포Poisson Distribution
일정한 시간단위 또는 공간단위에서 발생하는 이벤트의 수의 확률분포
- 하루동안 어떤 웹사이트를 방문하는 방문자의 수
어떤 미용실에 한 시간동안 방문하는 손님의 수
어떤 전기선 100미터당 발생하는 결함의 수
이런 종류의 문제는 포아송 분포를 사용하는 잘 맞을 가능성이 높다.
확률분포함수(확률질량함수)
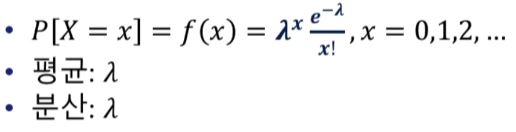
예시
어느 웹사이트에 시간당 접속자 수는 평균이 3인 포아송 분포를 따른다고 한다.
앞으로 1시간 동안 접속자 수가 2명 이하일 확률은?
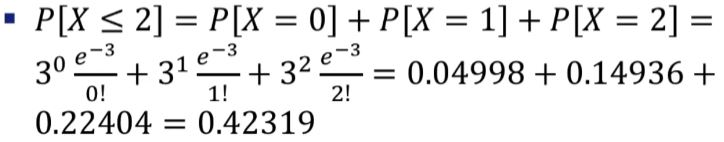
#람다만 정해지면 함수가 정해진다.
stats.poisson.cdf(2, mu=3)지수분포Exponential Distribution
포아송 분포에 의해 어떤 사건이 발생할 때, 어느 한 시점으로부터 이 사건이 발생할 때까지 걸리는 시간에 대한 확률 분포, 확률 밀도 함수로서 적분을 필요로 한다.

평균 시간은 포아송분포의 평균으로 시간을 나눈 값이므로 상식적으로 이해가 된다.
예시
어느 웹사이트에 시간당 접속자 수는 평균이 3인 포아송 분포를 따른다고 한다.
지금부터 시작하여 첫번째 접속자가 30분 이내에 올 확률은? T는 시간단위이다.
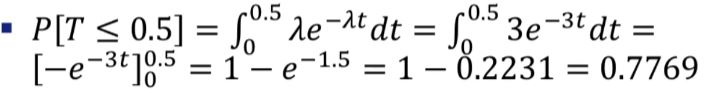
lam = 3
stats.expon.cdf(0.5, scale=1/lam)