5. 표본분포
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=baboedition&logNo=220916114770
강사님 설명에 부족한게 많아서 위 링크로 개념을 잡는 것을 추천.
표본 조사의 필요성과 표본 추출 방법
- 통계적 추론
표본 조사를 통해 모집단에 대한 해석을 진행
전수조사는 실질적으로 불가능한 경우가 많음 - 표본조사는 반드시 오차가 발생
적절한 표본 추출 방법이 필요
표본과 모집단 사이의 관계를 이해해야 함 - 단순랜덤추출법random sampling
난수표random number table 사용
랜덤넘버 생성기 사용
import random
[random.randint(1,1000) for i in range(10)]표본 분포sampling distribution
표본조사를 통해 파악하고자 하는 정보 : 모수parameter
모수의 종류 : 모평균, 모분산, 모비율 등이 있으며 모수를 추정하기 위해 표본을 선택하여 표본 평균이나 표본 분산등을 계산한다.
통계량statistic : 표본 평균이나 표본 분산과 같은 표본의 특성값
예시
50만명의 전국 고등학교 1학년 학생의 키를 조사하기 위해 1000명을 표본 조사함
표본의 평균 계산을 계산할때 표본의 평균은 표본의 선택에 따라 달라진다. 따라서 표본 평균은 확률변수라고 말할 수 있다.
표본 평균이 가질 수 있는 값도 하나의 확률분포를 가지며 그 분포가 무엇인지가 표본을 해석하는데 있어서 매우 중요함
통계량의 확률분포를 표본분포sampling distribution라 한다.
표본평균 : 모평균을 알아내는데 쓰이는 통계량
- 표본평균
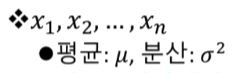
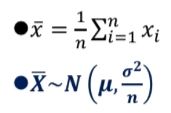
표본평균을 또하나의 확률변수로 보고 표본 평균의 집단을 만들어보면 이 집단은 정규분포를 이루며 그 평균(표본평균들의 평균)은 뮤, 그 분산은 모분산을 표본평균의 크기로 나눈 값이다.
표본평균집단의 정규분포 코드구현
import numpy as np
#정규분포 값을 size 10개로 뽑고 그것의 평균을 내는 작업(표본 평균)을 10000번 반복한다.(표본 평균 집단을 만든다.)
#np.random.normal(loc=평균, scale=표준편차, 생략하면 0과 1이 된다.)
xbars = [np.mean(np.random.normal(size=10)) for i in range(10000)]
print('mean %f, var %f %(np.mean(xbars)), np.var(xbars)')
return -> mean 0.002604, var 0.099187
retrun -> mean 0.001960, var 0.099321표본평균집단의 히스토그램 코드구현
xbars = [np.mean(np.random.normal(loc=10, scale=3, size=10)) for i in range(10000)]
print('mean %f, var %f %(np.mean(xbars)), np.var(xbars)')
return -> mean 10, var 0.9
import matplotlib as plt
#5에서 15사이를 x축으로하고 그 값들을 30개칸으로 쪼갠 히스토그램으로 그린다.
h=plt.pyplot.hist(xbars, range=(5,15), bins=30)중심극한정리Central Limit Theorem
모집단이 정규 모집단이 아닌경우의 표본에 대한 정리
크기n이 30이상인 경우에 표본편균집단은 정규분포를 따르며 그 평균은 모집단을 따르고 분산은 모분산을 크기로 나눈 값이 된다. 다만 표본의 크기를 충분히 늘릴 수 없는 경우에 중심극한정리를 사용할 수 없다.

중심극한정리 코드 구현
#random.rand() 함수는 0에서 1사이의 값들로 주어진 형태의 난수 어레이를 생성
#랜덤넘버 3개를 선택해서 10을 곱한뒤 그 평균을 구함 -> 그 표본평균의 집단을 생성
xbars = [np.mean(np.random.rand(3)*10) for i in range(10000)]
print('mean %f, var %f %(np.mean(xbars)), np.var(xbars)')
return -> mean 10, var 0.9
import matplotlib as plt
h=plt.pyplot.hist(xbars, range=(0,10), bins=100)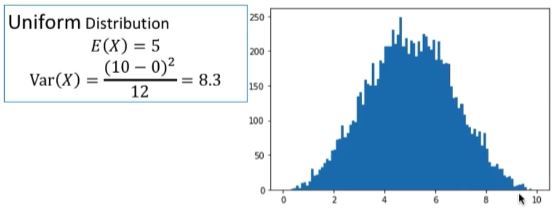
n이 3이기 때문에 정규분포의 형태를 갖추지는 못한다.
중심극한정리 코드 구현
#random.expoenetial 함수는 지수분포를 그린다.(scale=표준편차, n=크기)
xbars = [np.mean(np.random.exponential(scale=3, n=2)) for i in range(10000)]
print('mean %f, var %f %(np.mean(xbars)), np.var(xbars)')
return -> mean 2.9, var 4.3
import matplotlib as plt
h=plt.pyplot.hist(xbars, range=(0,10), bins=100)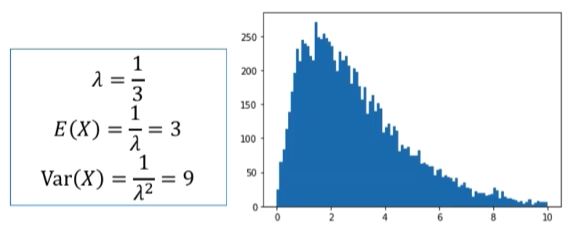
6. 추정
https://m.blog.naver.com/PostView.naver?blogId=baboedition&logNo=220916281966&navType=by
이번에도 강력 추천.
모평균의 추정
점추정 : 표본평균이 점 추정값(추정량)이 됨
당연히 표본평균이 모평균과 같을 확률은 낮다.
정규분포에서의 구간추정
모평균의 100(1-a)% 신뢰구간confidence interval
표본평균으로부터 모평균의 구간을 특정 신뢰도로 추정할 수 있다.
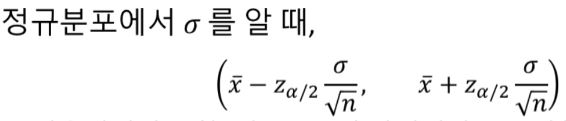
다만 이 방식은 정규분포가 아니거나 모표준편차를 모를경우 사용할 수가 없다.
표본의 크기가 클때 중심극한정리를 사용한 구간 추정
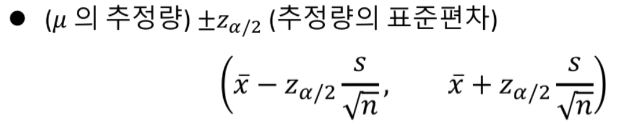
단, s = 표본표준편차
구간추정 예시
어떤 농장에서 계란 30개의 표본을 뽑았더니 그 무게가 아래와 같다.(생략) 이때 계란의 평균 무게에 대한 95% 신뢰 구간을 구하시오.
import numpy as np
#표본평균
xbar = np.mean(w)
#표본표준편차
sd=np.std(w, ddof=1)
import scipy.stats
alpha = 0.05
#표준정규분포에서 신뢰도에 해당하는 z값을 구하는 방법
zalpha = scipy.stats.norm.ppf(1-alpha/2)모비율의 추정
점 추정 : 확률변수가 x일때 p = x/n
당연히 표본비율과 모비율이 같을 확률은 낮다.
구간추정
n이 충분히 클때,
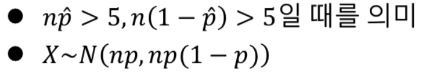
확률변수 X의 표준화

모비율의 구간추정 공식

공식으로 보면 굉장히 어려워보이지만 사실은 a가 1-신뢰도일때 z값을 구하는 과정이며, z 값은 95신뢰도일때, 1.96이고 99신뢰도 일때, 2.48이며, scipy를 이용해서 쉽게 구할 수 있다. z값을 알았으면 z값에 표본표준편차를 곱한 값으로 날개의 크기를 구하면 된다.
7. 검정
통계적 가설 검정(統計的假說檢定, 영어: statistical hypothesis test)은 통계적 추론의 하나로서, 모집단 실제의 값이 얼마가 된다는 주장과 관련해, 표본의 정보를 사용해서 가설의 합당성 여부를 판정하는 과정을 의미한다.
가설검정의 예
어떤 고등학교의 1학년 학생들의 평균키가 170.5cm으로 알려져 있었다. 올해 새로 들어온 1학년 학생들 중 30명을 랜덤하게 선택하여 키를 잰 후 평균을 계산했더니 171.3cm였다. 올해 신입생은 평균키가 170.5cm보다 더 크다고 할 수 있을까?
표본평균 X_가 알려진 평균보다 얼마나 커야 모평균이 알려진 평균보다 크다고 할 수 있을까?
가설검정
귀무가설 : 예측
대립가설 : 예측의 반론
귀무가설을 기각하기 위해서는 표본평균이 좀 큰 값이 나와야한다.
귀무가설이 참이라고 가정할 때, 랜덤하게 선택한 표본에서 지금의 표본평균이 나올 확률을 계산할 필요가 있다. 그리고 이 확률이 낮다면 귀무가설이 참이 아니라고 판단한다.
확률의 계산
유의수준 a의 도입, 신뢰도와 유사하다.
구간 추정과 유사하다. 표본평균을 표본평균집단의 정규분포에서 어느 위치를 갖는 지를 계산한다.
- 검정의 단계
H0, H1 설정
유의수준 a설정 ex)0.05 95프로
검정통계량 계산
기각역 또는 임계값 계산
주어진 데이터로부터 유의성 판정
대립가설
모평균이 가설보다 크다, 작다, 같지않다로 구분된다.
예시
어떤 농장에서 생산되는 계란의 평균 무게는 10.5그램으로 알려져 있다. 새로운 사료를 도입한 후에 생산된 계란 30개의 표본 평균을 계산했더니 11.4그램이 나왔다. 새로운 사료가 평균적으로 더 무거운 계란을 생산한다고 할 수 있는가?
H0 : u = 10.5
H1 : u > 10.5
예시
계란 30개의 표본을 뽑았더니 그 무게가 아래와 같다.(생략)
이 농장의 홍보가 맞는지 유의수준 5%로 검정하시오.
계산값
H0 : u = 10.5
H1 : u != 10.5
mu = 10.5
a = 0.05
표본평균 = 10.43
표본표준편차 = 1.11
검정통계량 = (표본평균 - 가설평균) / (표본표준편차/루트n)
표본평균의 검정통계량 -0.34 는 임계값 1.96보다 작기 때문에 귀무가설을 기각할 수 없다.
교차엔트로피
자기정보Self-information : i(A), A는 사건
확률이 높아지면 자기정보는 작아진다. A와 B가 동시에 일어났을 때의 계산을 위해서 로그함수를 사용한다.
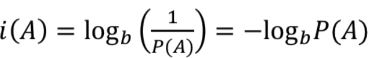
- 확률이 높은 사건 :
정보가 많지 않음, 도둑이 들었는데 개가 짖는 경우보다 도둑이 들었는데 개가 안 짖는경우 더 많은 정보를 포함하고 있음(개와 도둑이 안다거나) - 정보의 단위 :
b = 2:bits, e:nats, 10:hartleys
특징
두 개의 사건이 동시에 발생했을 때
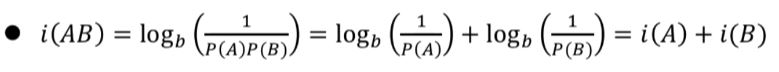
예시
모양이 이상한 동전을 던지면
P(H)=1/8, P(T)=7/8의 확률을 가질때
i(H)=3비트, i(T)=0.193비트의 정보를 가지고 있다.
엔트로피Entropy
엔트로피는 자기 정보를 확률 변수로 볼때 이 값의 평균이다.
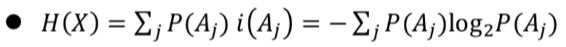
k가 사건의 수일때 엔트로피가 가질 수 있는 최대 값은 로그2의 k이다.
- 엔트로피의 활용
평균비트수를 표현
데이터 압축에 사용 가능
예시
4가지 정보를 표현하는 경우
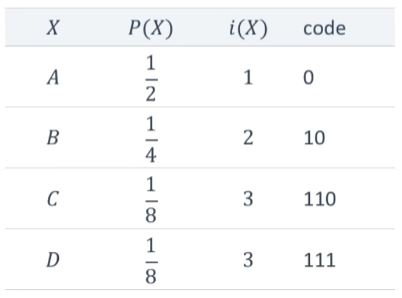
4가지 정보를 코드로 표현한다면 자기정보는 이 정보를 표현하는데 필요한 최소한의 비트수가 된다. 그리고 각각의 정보를 보낼때 필요한 평균 비트수를 구할 수가 있다.
교차 엔트로피
확률분포 P와 Q
S = {Aj} S라는 전체 사건이 있다.
P(Aj) : 확률분포 P에서 사건이 발생할 확률
Q(Aj) : 확률분포 Q에서 사건이 발생할 확률
i(Aj) : 확률분포 Q에서 사건의 자기정보
자기 정보는 Aj를 표현하는 비트수
잘못된 확률분포 Q를 사용하게 되면, 실제 최적의 비트수를 사용하지 못하게 됨
- H(P,Q) : 집합 S상에서 확률분포 P에 대한 확률분포 Q의 교차 엔트로피
확률분포 P에서 i(Aj)의 평균
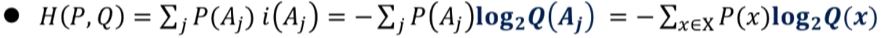
이 값은 정확한 확률분포 P를 사용했을 때의 비트수보다 크게된다.
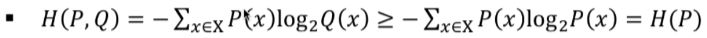
따라서 이 비교값은 P와 Q가 얼마나 비슷한지를 표현할 수 있다.
두 값이 같다면 H(P,Q) = H(P)
두 값이 다르다면 H(P,Q) > H(P)
예시
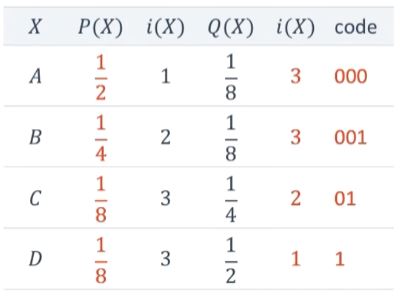
Q(X)를 가정하고 코드를 부여하면 1.5배나 더 많은 비트를 사용하게 된다.
교차 엔트로피를 사용하면 두 확률분포가 얼마나 비슷한지를 알 수 있게 된다.
분류 문제에서의 손실함수
주어진 대상이 A인지 아닌지를 판단하는 경우
주어진 대상이 A B C중 어느 것인지를 판단하는 경우
결과가 0.8, 0.2라면 정답인 1.0, 0.0과 얼마나 다른지 측정이 필요하다.
그것을 측정하는 함수가 손실함수이다.
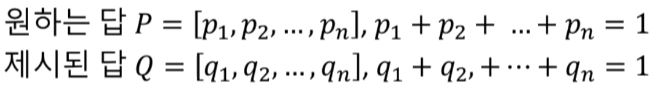
-
제곱합
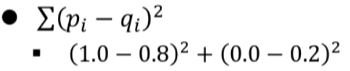
확률이 다를 수록 큰 값을 가진다.
학습 속도가 느리다. -
교차엔트로피 H(P,Q)
확률이 다를 수록 큰 값을 가진다.
학습 속도가 빠르다. 따라서 분류문제에서 주로 사용된다.
기계학습을 발전하던 과정 중에서 교차 엔트로피라는 알고리즘을 사용하게 되었다. -
머신러닝에서의 적용
일반적으로 분류 문제에서 원하는 답은 하나만 확률이 1이고 나머지는 다 0이 되는 것이다. 곧 엔트로피가 0이게 된다. 그러므로 교차 엔트로피를 계산하게 되면 마찬가지로 pk에 해당하는 qk에 해당하는 값이 최대한 커질 수 있도록 학습을 시키게 된다.
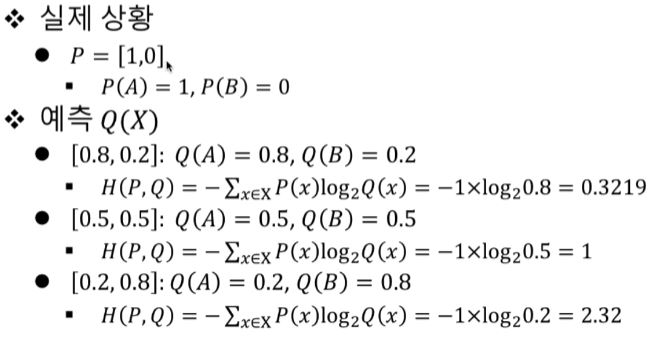
교차엔트로피의 값이 커질수록 예측은 틀리게 되고, 학습의 방향을 고칠 필요를 알 수 있게 된다.
교차 엔트로피 코드 구현
import numpy as np
def crossentropy(P, Q):
return sum([-P[i]*np.log2(Q[i]) for i in range(len(P))])