
1. 로지스틱 회귀란?
- 로지스틱 회귀(Logistic Regression)는 회귀를 사용하여 데이터가 어떤 범주에 속할 확률을 0에서 1 사이의 값으로 예측하고 그 확률에 따라 가능성이 더 높은 범주에 속하는 것으로 분류해주는 지도 학습 알고리즘이다. 예를 들어 시험을 봤는데 이 시험 점수가 합격인지 불합격인지가 궁금할 수도 있고, 어떤 메일을 받았을 때 이게 정상 메일인지 스팸 메일인지를 분류하는 문제도 그렇다. 이렇게 둘 중 하나를 결정하는 문제를 이진 분류(Binary Classification)라 한다.
Logistic Regression = Classfication을 위한 알고리즘
2. 이진분류(Binary Classification)
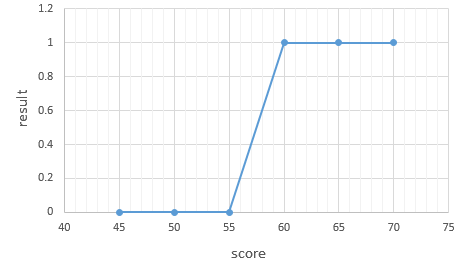
위 그래프에서 60점 이상은 합격(1), 그 미만은 불합격(0)이라고 했을때 그래프를 보면 S자 형태를 가지게 된다. 그래서 linear한 함수가 아니라 S자 형태로 표현할 수 있는 함수가 필요하다.왜냐하면 선형회귀를 한다면 음과 양으로 무한대의 값이 나올 수 있기 때문이다. 그래서 최종 예측값을 0~1사이의 값으로 나오게 한다면 0.5보다 작으면 0으로 예측했고, 0.5보다 크면 1로 예측했다라고 판단할 수 있기 때문에 문제를 풀기에 더 용이하다. 그래서 사용하는 함수가 바로 'Sigmoid function' 이다.
3. 시그모이드 함수(Sigmoid function)
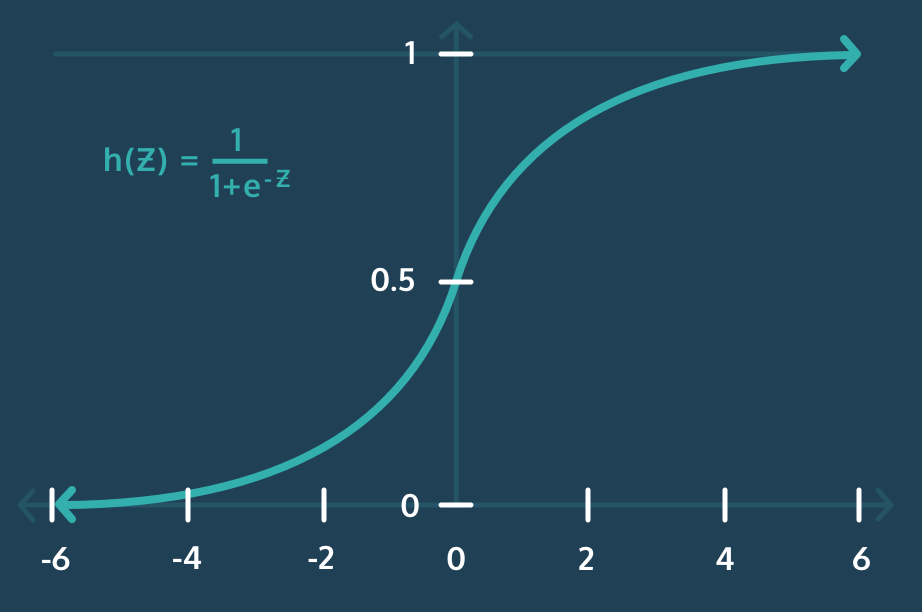
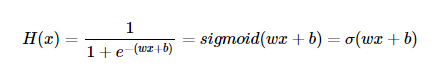
Sigmoid function은 다음과 같이 나타내질 수 있으며, 종종 σ로 축약해서 표현하기도 한다.
결국 위 Hypothesis에서도 궁극적으로 해야하는 목적은 우리 데이터에 적합한 가중치 w와 b를 구하는 것이다.
4. 비용 함수(Cost function)
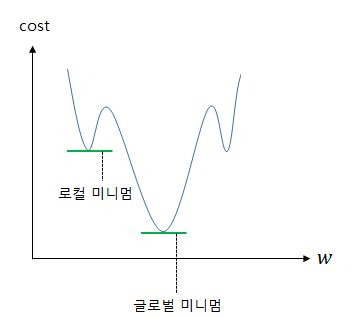
로지스틱 회귀에서 평균 제곱 오차를 비용 함수로 사용하면, Gradient Descent을 사용하였을때 찾고자 하는 최소값이 아닌 잘못된 최소값에 빠질 가능성이 매우 높다. 이를 전체 함수에 걸쳐 최소값인 글로벌 미니멈(Global Minimum)이 아닌 특정 구역에서의 최소값인 로컬 미니멈(Local Minimum)에 도달했다고 한다면 우리가 원하는 최적의 w 값을 찾는데는 좋지 않을 수가 있기 때문이다.
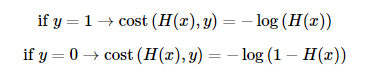
그래서 시그모이드 함수는 0과 1사이의 값을 반환하기 때문에, 이는 실제값이 0일 때 값이 1에 가까워지면 오차가 커지며 실제값이 1일 때 값이 0에 가까워지면 오차가 커짐을 의미한다. 그리고 이를 반영할 수 있는 함수는 위처럼 로그 함수를 통해 표현이 가능하다.
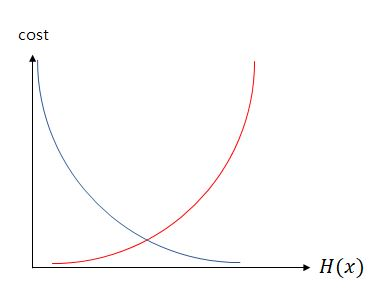
그래프를 그리면 다음과 같이 나타낼 수 있는데 실제값이 1일때를 파란색, 실제값이 0일떄를 빨간색으로 나타내었을 때, 실제값이 1일 때, 예측값인 의 값이 1이면 오차가 0이므로 당연히 cost는 0이 된다. 반면, 실제값이 1일 때, 가 0으로 수렴하면 cost는 무한대로 발산한다. 실제값이 0인 경우는 그 반대로 이해하면 된다. 이는 다음과 같이 하나의 식으로 cost function을 표현할 수 있다.
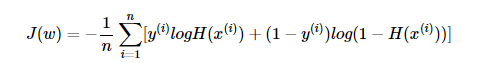
참고자료
- <딥 러닝을 이용한 자연어 처리 입문> https://wikidocs.net/22881
- https://hleecaster.com/ml-logistic-regression-concept/
