
#데이터 분석 파이썬 종합반 5강
#알면 유용한 파이썬 문법들
#파일 불러오기 및 저장하기
-
파일 확장자
- CSV 파일 (.csv)
Comma Separated Values 의 약자, 데이터를 쉼표로 구분해 저장하는 형식 - Excel 파일 (.xls , .xlsx)
표 형태로 데이터를 저장하는 MS Excel 형식 - JSON 파일 (.json)
JavaScript Object Natation 의 약자, 데이터를 저장하는 간단한 형식 - 텍스트 파일 (.txt , .dat, 등)
일반 텍스트로 된 데이터를 저장하는 파일
- CSV 파일 (.csv)
-
확장자에 따른 파일 불러오는 함수
#CSV 파일 import pandas as pd df = pd.read_csv('file.csv') #Excel 파일 import pandas as pd df = pd.read_excel('file.xlsx') #JSON 파일 import pandas as pd df = pd.read_json('file.json') #텍스트 파일 import pandas as pd df = pd.read_csv('file.txt', delimiter='\t') # 만약 탭으로 구분되어 있다면 delimiter='\t'를 사용합니다.+) 내가 가지고 있는 데이터 파일을 구글 코랩에 읽어들이기
'드라이브 마운트'를 해준 후 구글드라이브에 내가 넣고 싶은 파일을 업로드해야 함from google.colab import drive drive.mount('/content/drive') -
파일 저장하기
#CSV 파일 import pandas as pd data = { 'Name': ['John', 'Emily', 'Michael'], 'Age': [30, 25, 35], 'City': ['New York', 'Los Angeles', 'Chicago'] } df = pd.DataFrame(data) excel_file_path = '/content/sample_data/data.csv' df.to_csv(excel_file_path, index = False) print("csv 파일이 생성되었습니다.") --- #Excel 파일 import pandas as pd data = { 'Name': ['John', 'Emily', 'Michael'], 'Age': [30, 25, 35], 'City': ['New York', 'Los Angeles', 'Chicago'] } df = pd.DataFrame(data) excel_file_path = '/content/sample_data/data.xlsx' df.to_excel(excel_file_path, index = False) print("Excel 파일이 생성되었습니다.") --- #JSON 파일 import json data = { 'Name': ['John', 'Emily', 'Michael'], 'Age': [30, 25, 35], 'City': ['New York', 'Los Angeles', 'Chicago'] } json_file_path = '/content/sample_data/data.json' # json 파일을 쓰기모드로 열어서 data를 거기에 덮어씌우게 됩니다. with open(json_file_path, 'w') as jsonfile: json.dump(data, jsonfile, indent=4) print("JSON 파일이 생성되었습니다.") --- #텍스트 파일 data = { 'Name': ['John', 'Emily', 'Michael'], 'Age': [30, 25, 35], 'City': ['New York', 'Los Angeles', 'Chicago'] } text_file_path = '/content/sample_data/data.txt' with open(text_file_path, 'w') as textfile: for key, item in data.items(): textfile.write(str(key) + " : " + str(item) + '\n') print("텍스트 파일이 생성되었습니다.")
#패키지(라이브러리) 사용
-
패키지란?
- 관련된 여러 개의 모듈을 포함하는 디렉토리
일반적으로 라이브러리나 다른 패키지가 포함될 수 있음 - 예로,
numpy와matplotlib는 여러 모듈을 포함하는 패키지 - 데이터 분석을 위한 파이썬 패키지들은 다양한 작업을 수행하는 데 필수적임
- 파이썬을 사용할 때 필요한 패키지들을 맨 위에 한번에 불러놓고 사용하면 편리!
# 아래와 같이 보통은 필요한 패키지를 한번에 다 불러온 다음 코딩을 진행합니다 import pandas as pd import numpy as np import tensorflow as tf import matplotlib.pyplot as plt import seaborn as sns - 관련된 여러 개의 모듈을 포함하는 디렉토리
-
다양한 종류의 패키지
-
pandas
데이터 조작과 분석을 위한 라이브러리,
데이터를 효과적으로 조작하고 분석할 수 있도록 도와줌

-
numpy
과학적 계한을 위한 핵심 라이브러리,
다차원 배열과 행렬 연산 지원

-
matplotlib
데이터 시각화를 위한 라이브러리,
다양한 그래프와 플롯 생성 가능

-
seaborn
matplotlib을 기반으로 한 통계용 데이터 시각화 라이브러리,
보다 간편하고 아름다운 시각화를 제공

-
scikit-learn
머신러닝 알고리즘을 사용할 수 있는 라이브러리,
분류, 회귀, 군집화, 차원 축소 등 다양한 머신러닝 기법 제공

-
statsmodels
통계 분석을 위한 라이브러리,
회귀분석, 시계열분석, 비모수통계 등 다양한 통계 기법 제공

-
scipy
과학기술 및 수학적 연산을 위한 라이브러리,
다양한 과학 및 공학 분야에서 활용, 선형대수, 최적화, 신호 처리, 통계 분석 등 기능 제공

-
tensorflow
딥러닝 및 기계학습을 위한 오픈소스 라이브러리, 구글에서 개발,
그래프 기반의 계산을 통해 수치 계산을 수행, 신경망을 구축하고 학습할 수 있음

-
pytorch
딥러닝을 위한 오픈소스 라이브러리, 페이스북에서 개발,
동적 계산 그래프를 사용해 신경망을 구축하고 학습할 수 있음

- 위 패키지들은 각각 고유한 기능과 장점을 가지고 있으며,
데이터 분석 및 머신러닝, 딥러닝 작업을 위해 널리 사용됨 - 데이터 분석 프로젝트나 머신러닝/딥러닝 모델 구축 시 데이터의 특성과 목표에 맞게
적절한 패키지를 선택해 활용하는 것이 중요
- 위 패키지들은 각각 고유한 기능과 장점을 가지고 있으며,
-
#포맷팅 사용
- 포맷팅(formatting)이란?
- f-string을 활용한 방법

- f-string 포맷팅은 문자열 맨 앞에
f를 집어넣고,
내가 놓고자 하는 변수의 위치에 중괄호{ }를 사용해 변수와 함께 기입- 활용 예시

- 활용 예시
- f-string을 활용한 방법
#리스트 컴프리헨션
-
리스트 컴프리헨션은 파이썬에서 리스트를 간결하게 생성하는 방법 중 하나
-
보통 반복문과 조건문을 사용해 리스트를 생성할 때 사용
-
코드를 간결하고 가독성있게 만들어 줌
-
기본 구조

-
활용 예시

-
#람다 사용
- 람다 (lambda) 란?
- 람다 함수는 익명 함수로, 이름 없이 정의되는 간단한 함수
- 주로 한 줄로 표현, 일반적인 함수 정의와 달리
def키워드를 사용하지 않고
lambda키워드를 사용해 정의- 주로 함수를 매개변수로 전달하는 함수형 프로그래밍에서 유용하게 활용
- 람다와 함수의 차이점
- 정의 방식
- 일반 함수는
def키워드로 명시적인 함수를 정의 - 람다 함수는
lambda키워드로 익명 함수를 간단히 정의
- 일반 함수는
- 구조
- 일반 함수는 여러 줄의 코드 블록을 가질 수 있음
- 람다 함수는 주로 한 줄로 표현되는 간단한 표현식만을 포함
- 이름
- 일반 함수는 함수의 이름을 지정하여 호출할 수 있음
- 람다 함수는 이름이 없어 한 번만 사용되거나 임시로 필요한 경우에 사용
- 사용
- 일반 함수는 어떤 경우에도 사용 가능
- 람다 함수는 주로 함수를 매개변수로 받거나 함수를 반환하는 고차 함수,
즉 함수형 프로그램에서 사용
- 정의 방식
- 람다를 쓰는 이유
- 간결성
- 람다 함수는 코드를 더 간결하게 만듦,
특히 간단한 연산이나 조작이 필요할 경우 유용
- 람다 함수는 코드를 더 간결하게 만듦,
- 익명성
- 이름이 없어 임시로 필요한 경우에 사용 가능,
정렬이나 필터링과 같은 함수의 매개변수로 전달할 때 많이 사용
- 이름이 없어 임시로 필요한 경우에 사용 가능,
- 함수형 프로그래밍
- 함수를 값으로 취금하고 함수를 다루는 함수형 프로그래밍 패러다임에서
람다 함수가 필요
함수를 매개변수로 받는 고차 함수를 작성하거나 함수를 반환하는 경우
람다 함수가 효과적으로 사용
- 함수를 값으로 취금하고 함수를 다루는 함수형 프로그래밍 패러다임에서
- 가독성
- 람다 함수는 간단한 표현식을 사용해 코드를 작성해 가독성이 향상됨
함수가 짧고 명확한 경우에 유용
- 람다 함수는 간단한 표현식을 사용해 코드를 작성해 가독성이 향상됨
- 람다 함수는 모든 상황에 적합하지는 않음
- 복잡한 기능을 가진 함수나 여러 줄의 코드가 필요한 경우 일반함수를 사용하는게 나음
- 간결성
- 람다 함수 예시
- 간단한 덧셈
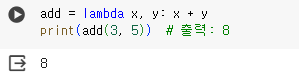
- 제곱
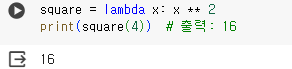
- 리스트 요소 중 짝수 필터링

- 리스트의 각 요소에 대한 제곱
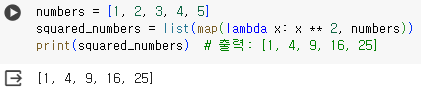
- 참고


- 간단한 덧셈
#glob 사용
-
glob 이란?
-
glob함수는 파일 시스템에서 파일을 찾을 때 사용되는 유용한 도구 -
파일 이름의 패턴 매칭을 통해 파일을 검색하고,
일치하는 파일들의 리스트를 반환 -
주로 파일 이름이나 확장자에 따라 파일을 필터링하는 데 사용
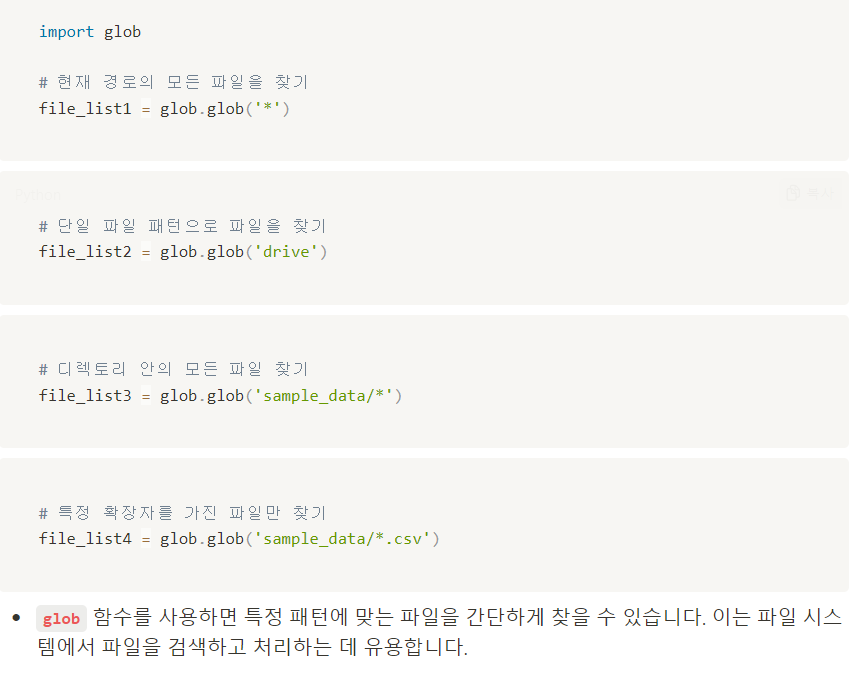
-

#os 사용하기
-
os란?
os모듈은 운영 체제와 상호 작용하기 위한 다양한 함수 제공
파일 시스템을 관리하고, 디렉토리를 탐색하고, 파일을 조작하는데 사용
-
주요 기능과 예시
-
파일 디렉토리 관리:
- 파일 생성, 이름 변경, 삭제 등의 작업 수행 가능
- 디렉토리 생성, 탐색, 삭제 등의 작업 수행 가능


-
경로 관리:
- 절대 경로, 상대 경로, 현재 작업 디렉토리 등의 경로 관리 가능
- 경로 구성 요소를 조작하고, 경로를 연결하고, 경로를 정규화할 수 있음

-
환경 변수 관리:
- 시스템의 환경 변수를 가져오거나 설정할 수 있음
-
실행 관리:
- 외부 프로그램을 실행하거나, 현재 프로세스의 종료 등의 작업 수행 가능
-
#split 사용
-
split 이란?
- 리스트의 split 메서드를 활용하면 문자열을 여러개로 쪼개는 데 활용 가능
문자열로 되어있는 파일 경로로부터 파일 제목을 추출하는 등의 상황에 유용
- 리스트의 split 메서드를 활용하면 문자열을 여러개로 쪼개는 데 활용 가능
-
문자열을 공백 기준으로 분할하여 리스트로 변환

-
특정 구분자를 기준으로 문자열을 분할하여 리스트로 변환

-
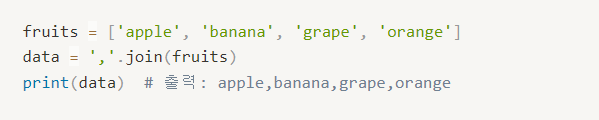
리스트의 각 항목을 문자열로 결합하기 (split은 아니지만 참고)

-
리스트의 각 항목을 문자열로 결합하되, 특정 구분자를 사용해 결합
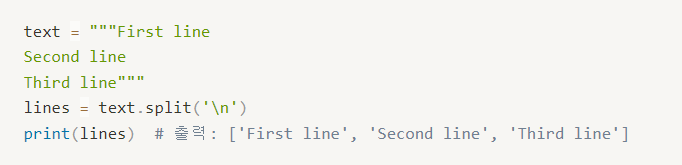
-
여러 줄로 이루어진 문자열을 줄 단위로 분할하여 리스트로 변환 (줄 구분
\n)
-
문자열을 공백으로 분할한 후 특정 개수의 항목만 가져오기

-
문자열에서 공백을 제거한 후 문자열을 리스트로 변환 (
.strip( )은 좌우 공백 제거)

-
split이 실전 사용 예) : 데이터 불러올 때 경로 처리할 때


-
#클래스
-
클래스(Class)는 객체 지향 프로그래밍(OOP)의 중요한 개념 중 하나
객체 지향 프로그래밍은 현실 세계의 사물을 모델링하여 프로그래밍하는 방법 -
코드의 재사용성과 유지보수성 향상 가능
-
클래스의 기본 구조
__int__메서드는 클래스의 생성자고, 객체가 생성될 때 호출되며 초기화 작업 수행- 클래스 내부의 메서드들은 클래스의 동작을 정의하는 함수
- 메서드의 첫 번째 매개변수로
self를 반드시 사용해야 함.

-
클래스와 객체의 관계
- 클래스는 객체를 만들기 위한 틀 또는 설계도, 객체는 이런 클래스를 이용해 생성
예로, Person 클래스를 정의하면 이 클래스를 사용해 여러 사람 객체를 만들 수 있음

- 클래스는 객체를 만들기 위한 틀 또는 설계도, 객체는 이런 클래스를 이용해 생성
-
다형성(Polymorphism)
- 다형성은 같은 이름의 메서드가 서로 다른 클래스에서 다른 기능을 수행하도록 하는 개념
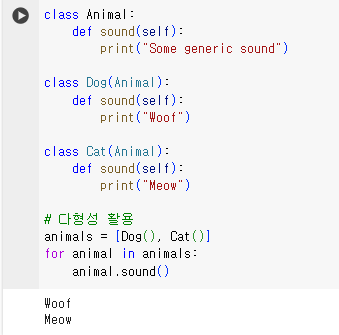
- 다형성은 같은 이름의 메서드가 서로 다른 클래스에서 다른 기능을 수행하도록 하는 개념
-
클래스와 함수의 차이점
- 클래스와 함수는 모두 파이썬에서 코드를 조직화하고 재사용성을 높이는 데 사용
- 함수(Function)
함수는 일련의 작업을 수행하는 블록
일반적으로 입력(매개변수)를 받아들이고 그에 따른 결과를 반환
특정한 작업을 수행하는 독립적인 코드 블록으로, 재사용성을 높이고 가독성을 개선
클래스와 상관없이 독립적으로 정의될 수 있음 - 클래스(Class)
데이터와 해당 데이터를 처리하는 메서드(함수)를 함께 묶어놓은 것
객체 지향 프로그래밍의 핵심 개념,
데이터와 데이터를 다루는 코드를 함께 묶어 객체 생성 가능
객체의 상태(속성)와 행위(메서드)를 정의,
이를 캡슐화하여 객체를 생성하고 다룰 수 있게 함
상속을 통해 기존 클래스를 확장하고 다형성을 지원하여,
유연한 코드 구조를 구현할 수 있음.
클래스는 여러 객체를 생성하고 관리함으로써
코드의 구조를 향상시키고 재사용성을 높입니다.
- 함수(Function)
- 클래스와 속성과 메서드
- 클래스는 객채를 생성하기 위한 템플릿이며,
메서드와 속성을 가질 수 있다. - 메서드와 속성은 클래스의 행동과 상태를 정의하는 데 사용
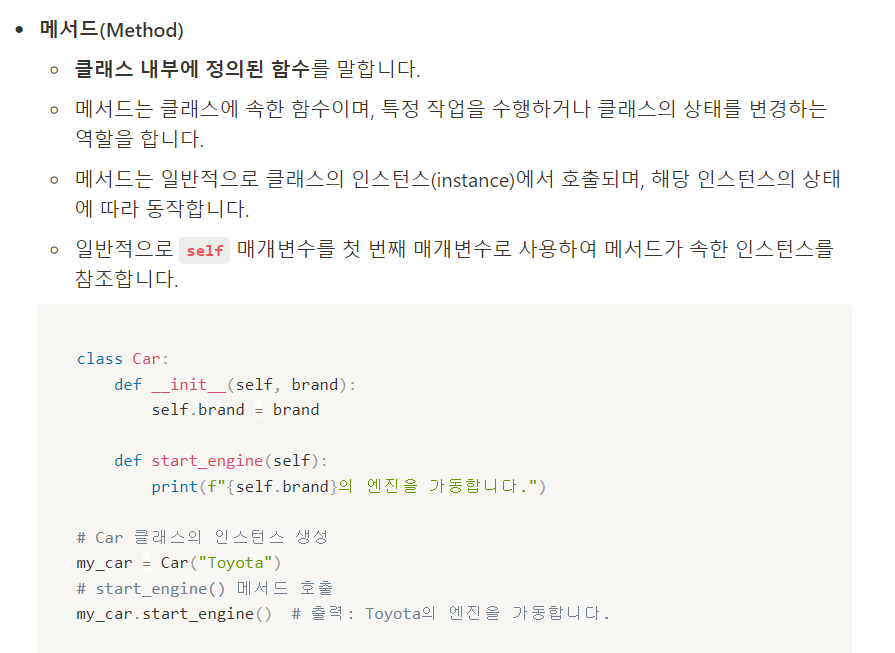
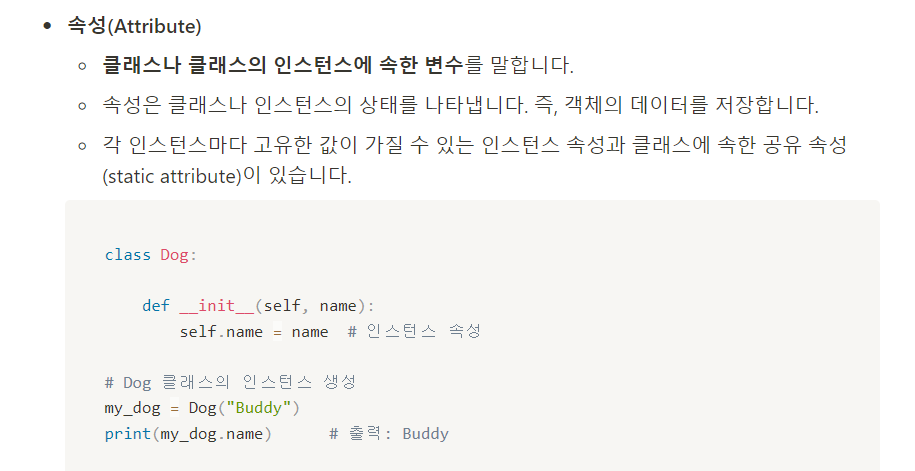
- 클래스는 객채를 생성하기 위한 템플릿이며,
- 클래스와 함수는 모두 파이썬에서 코드를 조직화하고 재사용성을 높이는 데 사용
-
클래스가 데이터 분석에서 사용되는 예시)
주로 데이터의 구조화, 모델링, 분석 작업의 모듈화, 코드의 재사용성 등을 위해 클래스 활용
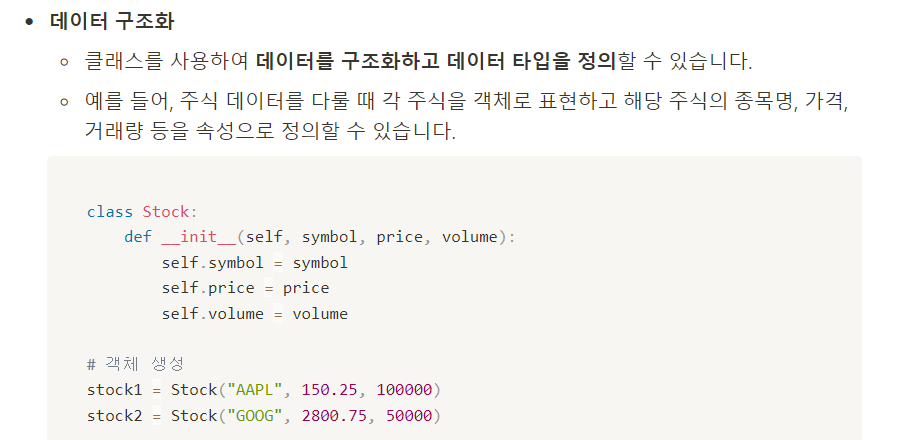
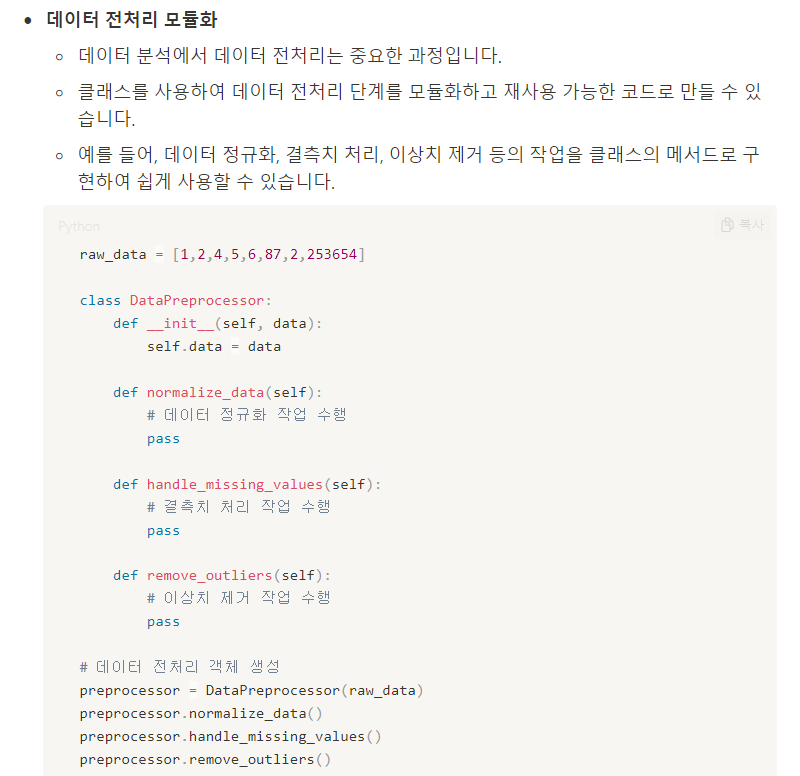

#불리언 인덱싱
- 불리언 인덱싱(Boolean indexing)은 조건에 따라 요소를 선택하는 방법 중 하나
- 주어진 조건에 따라 배열이나 리스트에서 요소를 선택할 수 있게 해주는 강력한 도구
- 파이썬에서는 NumPy를 사용하여 불리언 인덱싱을 수행할 수 있고,
Pandas에서 데이터를 조건에 맞게 선택할 때 많이 사용
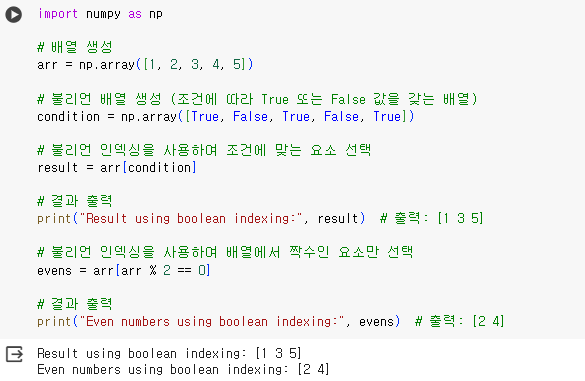
#데코레이션 사용
- 데코레이터(Decorator)는 파이썬에서 함수나 메서드의 기능을 확장하거나 수정하는 도구
- 데코레이터는 함수나 메서드를 인자로 받아 해당 함수나 메서드를 변경하거나, 래핑함
- 즉, 기존의 함수를 따로 수정하지 않고도 추가 기능을 넣고 싶을 때 사용

- 데코레이션 사용 예시


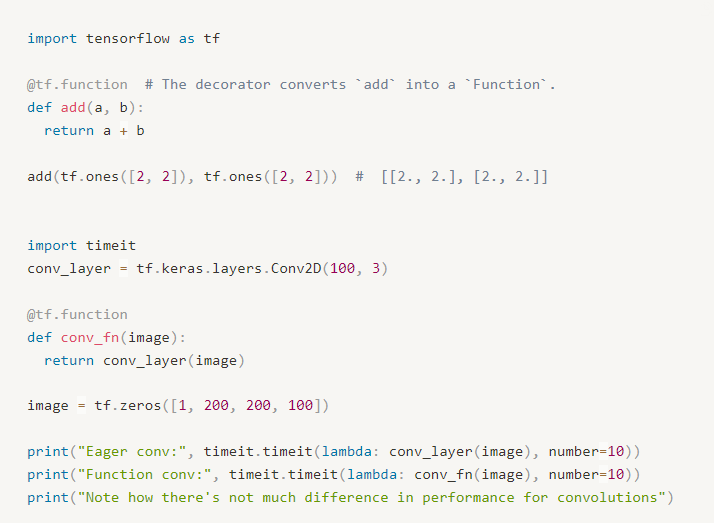
- 참고) 파이썬의 즉시 실행모드와 그래프 모드
- 즉시 실행 모드 (Eager Execution)
- 즉시 실행 모드는 파이썬 코드를 순차적으로 실행하면서 연산을 즉시 평가하는 방식입니다.
- 각각의 연산은 실행될 때마다 결과가 즉시 반환되어 사용자가 바로 확인할 수 있습니다.
- 파이썬의 일반적인 제어 흐름과 함께 사용되며, 디버깅 및 코드 작성이 용이합니다.
- TensorFlow 2.0부터는 즉시 실행 모드가 기본적으로 활성화되어 있습니다.
- 그래프 모드 (Graph Mode)
- 그래프 모드는 파이썬 코드를 그래프로 변환하고, 이를 최적화한 후에 실행하는 방식입니다.
- 먼저 그래프를 정의하고, 그래프를 실행하기 위해 세션을 통해 입력을 제공해야 합니다.
- 그래프는 연산의 순서와 의존성을 명확하게 표현하므로, 병렬 실행과 하드웨어 가속화에 최적화되어 있습니다.
- TensorFlow 1.x에서는 주로 그래프 모드를 사용했으나, TensorFlow 2.0부터는 즉시 실행 모드가 기본으로 제공되어 그래프 모드를 명시적으로 사용하지 않아도 됩니다.
- 차이점
- 즉시 실행 모드는 파이썬 코드를 사용하여 연산을 즉시 평가하고 결과를 반환합니다. 반면에, 그래프 모드는 그래프를 먼저 정의하고 세션을 통해 실행해야 합니다.
- 즉시 실행 모드는 디버깅과 코드 작성이 용이하지만, 그래프 모드는 병렬 실행과 하드웨어 가속화에 최적화되어 있습니다.
- 즉시 실행 모드는 각각의 연산을 바로 평가하기 때문에 코드를 작성하고 실행하는 데에 편리합니다. 반면에, 그래프 모드는 전체 그래프를 먼저 정의하고 실행해야 하므로 초기 설정이 더 복잡할 수 있습니다.
- 그래프 모드는 동일한 그래프를 여러번 실행할 때 재사용할 수 있어서 효율적인 반복 작업에 유용합니다.
#파이썬 에러 대처법
- 파이썬 에러 확인법
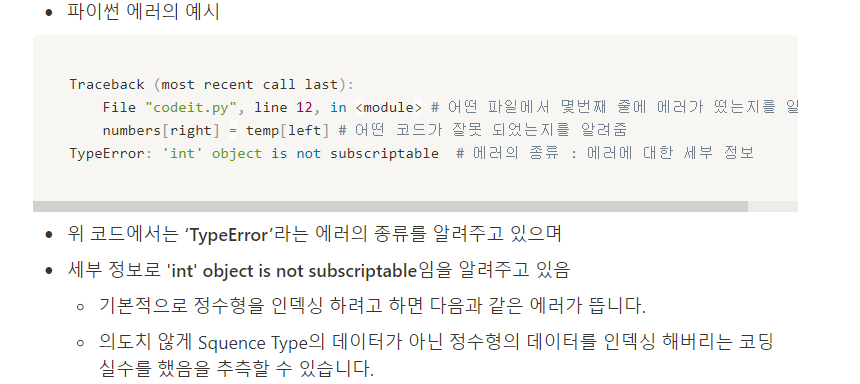
- 대표적인 에러들
- 위 예시들에도 없는 문제 발생?
- 무조건 구글링 : )
- 에러에 대한 세부정보 검색
- 무조건 구글링 : )


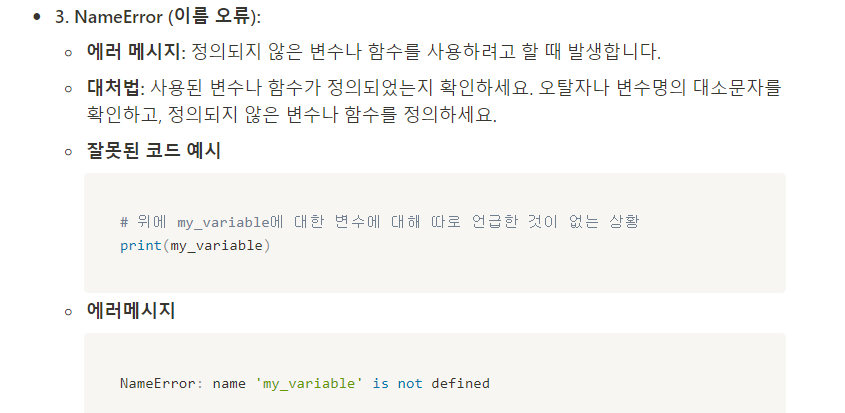
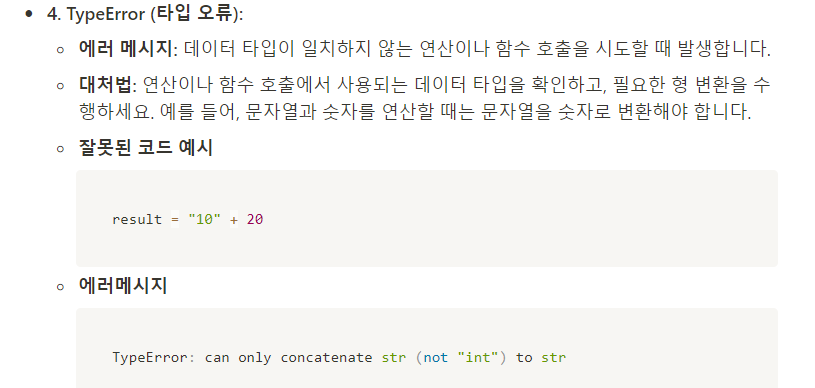
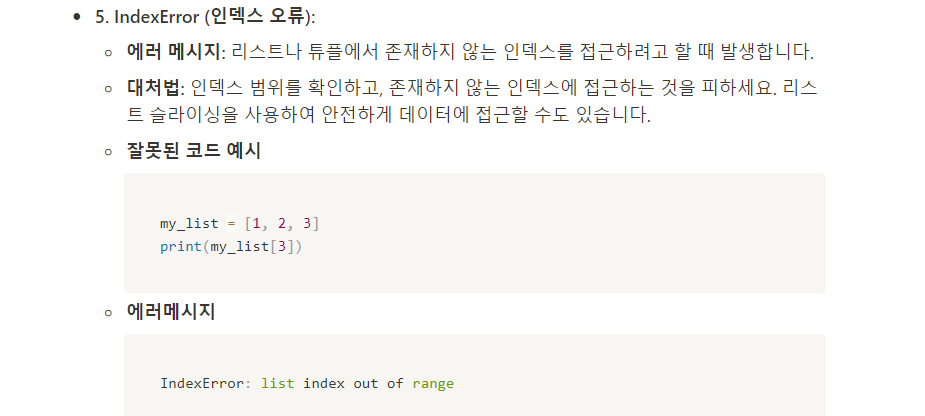

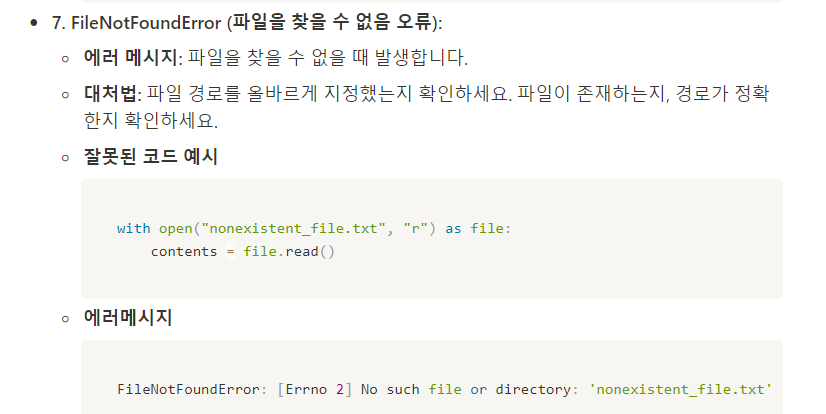
#QUIZ
- 파일 불러오기
import pandas as pd
df = pd.read_csv('/content/sample_data/data.csv')
import pandas as pd
df = pd.read_excel('/content/sample_data/data.xlsx')
import pandas as pd
df = pd.read_json('/content/sample_data/data.json')
import pandas as pd
df = pd.read_csv('/content/sample_data/data.txt')-
리스트 컴프리헨션

- 내 답안
1부터 5까지 제곱을 리스트 > a) - 정답

- 내 답안
-
패키지

- 내 답안
코드의 재사용성을 높임 > b) - 정답

- 내 답안
-
glob

- 내 답안
파일 검색 및 패턴 매칭 > c) - 정답

- 내 답안
-
클래스
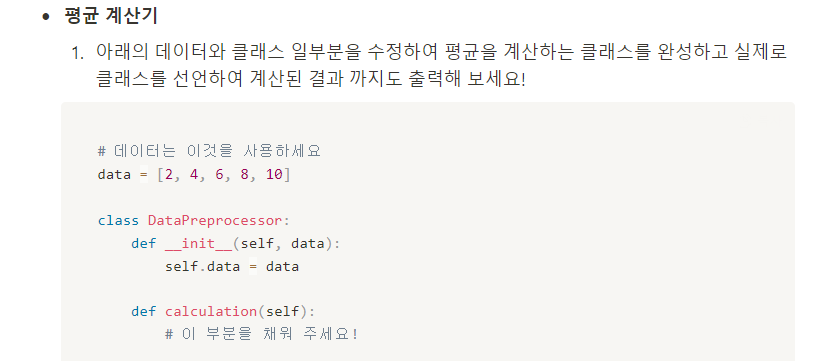
- 내 답안
sum(self.data) / len(self.data) ...공부가 더 필요하다. - 정답

- 내 답안
