
#PYTHON 개인 과제
#베이직 문항 (3개)
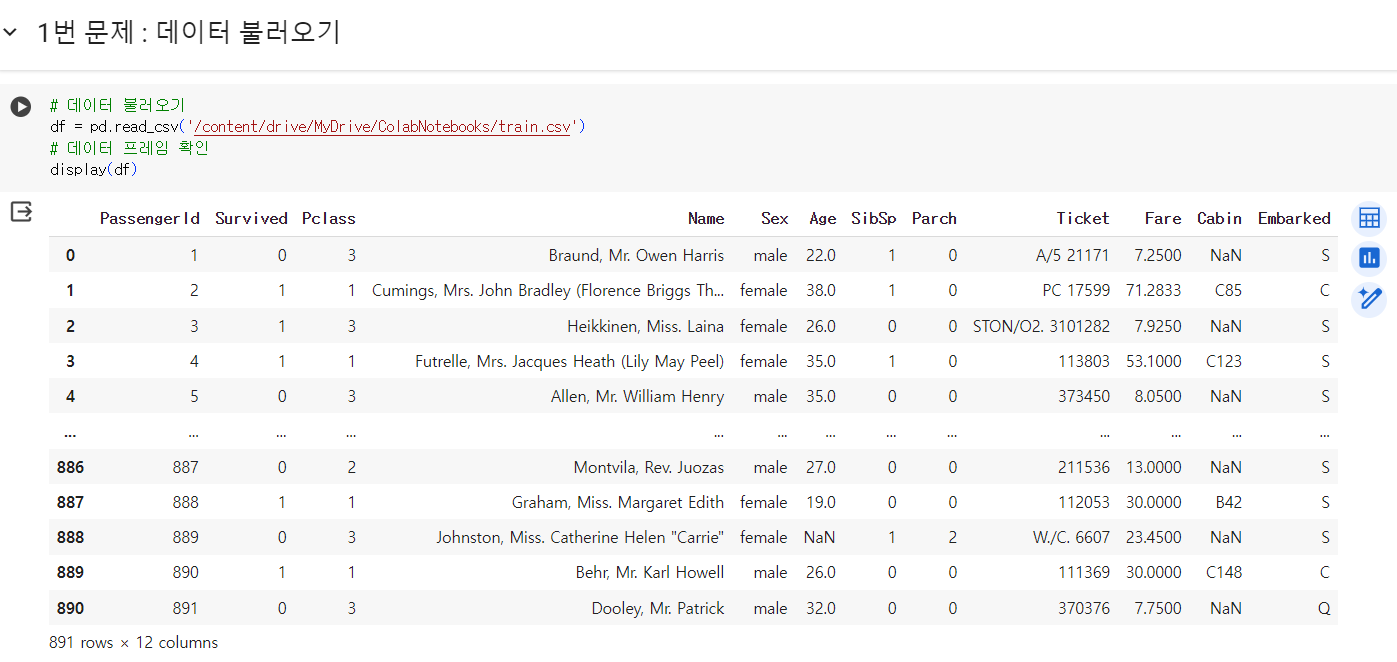
#1번 문제 : 데이터 불러오기
- 문제) 타이타닉 데이터를 불러온 다음 df라는 변수에 담고 데이터의 내용을 확인하세요.
- pandas 패키지의 read_csv 함수 사용
- 참고, read_csv 함수는 csv 파일을 pandas의 dataframe 타입으로 만들어 줌
- df 라는 이름의 변수를 만들고 변수에 담기
- 데이터 > https://www.kaggle.com/competitions/titanic/data?select=train.csv
- test.csv 파일과 train.csv 파일 중 train 파일 사용!
- 환경에 맞게 경로를 설정
- dataframe을 확인하려면 print함수 대신에 display 함수 사용
# 구글 드라이브 마운트 from google.colab import drive drive.mount('/content/drive') # 판다스 라이브러리 import pandas as pd

# 데이터 불러오기 df = pd.read_csv('/content/drive/MyDrive/ColabNotebooks/train.csv') # 데이터 프레임 확인 display(df)
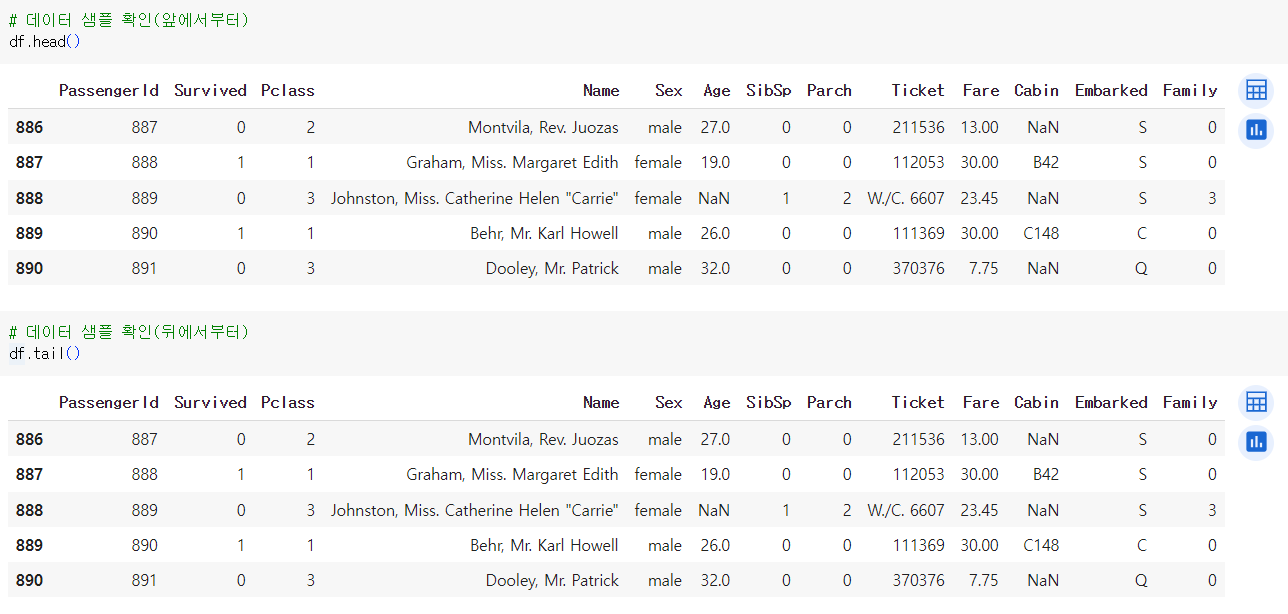
# 데이터 샘플 확인(앞에서부터) df.head() # 데이터 샘플 확인(뒤에서부터) df.tail()
#2번 문제 : 생존자 수 계산
- 문제) 타이타닉 전체 생존자 수와 사망자 수를 계산하고 출력하세요.
# df['컬럼']
- pandas dataframe에서 column(열)만 추출하는 방법
> '컬럼'을 pandas의 series 타입으로 반환, 이는 반복할 수 있는 것(iterable)
# df['Survived']
- 'Survived' 컬럼은 승객마다 생존 시 1, 사망 시 0의 값이 담겨 있는 column
# 항목별 개수 (Survived) survived = df[df['Survived']==1] survivor = len(survived) print(f'생존자 수는 {survivor} 입니다.') #0 = 549, 1 = 342 #생존자 342

3번 문제 : 평균 연령 계산
- 문제) 타이타닉 승객의 평균 연령을 계산하고 출력하세요.
타이타닉 데이터의 ‘Age’ column에 연령 데이터
‘Age’ column에는 결측값이 있음!
결측값이 있는 경우 수학 연산이 이루어지지 않기 때문에 처리가 필요함
pandas의 isnull() 함수 안에 결측값이 있는지 알고 싶은 데이터를 집어 넣으면
결측값인지 아닌지를 True, False로 반환되어 알 수 있다.
ex)
pd.isnull('Age')
# 연령 칼럼 결측값 확인 pd.isnull(df['Age']) # 결측값 제거 df['Age'] = df['Age'].dropna() # Age 칼럼 합계 df['Age'].sum() # Age 칼럼 갯수 # len(df['Age']) df['Age'].count() # AvgAge 평균 연령 계산 후 변수 부 AvgAge = df['Age'].sum() / df['Age'].count() # AvgAge = df['Age'].sum() / len(df['Age']) # 평균연령 조회 print(f'평균 연령은 {AvgAge} 세 입니다.')

#스탠다드 문항 (3개)
4번 문제 : 여성 생존자 수 계산
- 문제) 타이타닉 승객의 생존자 중 여성 생존자의 수를 계산하고 출력하세요.
- 성별 정보는 ‘Sex’ Columns에 존재하며 여성은 ‘female’, 남성은 ‘male’로 정의
- zip 함수를 이용하면 2개 이상의 반복할 것을 동시에 반복할 수 있음
# 행 : 성별 컬럼의 값이 female 이고 생존 컬럼의 값이 1인 경우 # 열 : 성별, 생존 컬럼 condition = (df['Sex'] == 'female') & (df['Survived'] == 1) df.loc[condition, ['Sex','Survived']] # 여성 생존자 수 = 233명 ws = df.loc[condition, ['Sex','Survived']] wsn = len(ws) print(f'여성 생존자 수는 {wsn}명 입니다.')

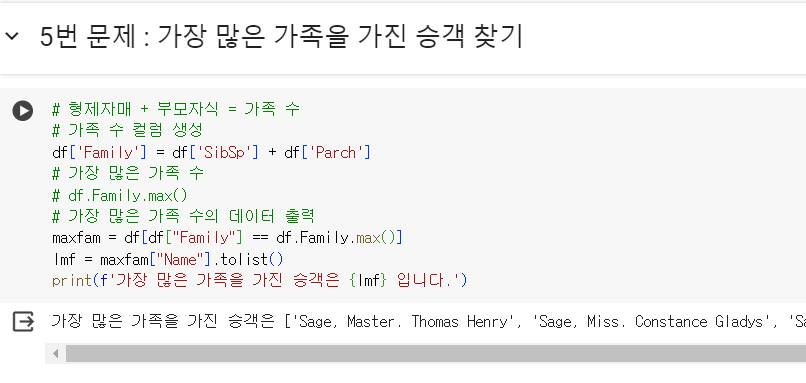
5번 문제 : 가장 많은 가족을 가진 승객 찾기
- 문제) 가족을 가진 승객들 중에서 가장 많은 가족을 가진 승객을 찾으세요.
- 타이타닉 데이터에 가족 수에 대한 column은 없음
- 각각 형제자매 수(’SibSp’)와 부모자식 수(’Parch’)에 대한 column만 존재,
(형제자매 + 부모자식)의 수 = 가족 수
- 이름은 ‘Name’ column에 있음
# 형제자매 + 부모자식 = 가족 수 # 가족 수 컬럼 생성 df['Family'] = df['SibSp'] + df['Parch'] # 가장 많은 가족 수 # df.Family.max() # 가장 많은 가족 수의 데이터 출력 maxfam = df[df["Family"] == df.Family.max()] lmf = maxfam["Name"].tolist() print(f'가장 많은 가족을 가진 승객은 {lmf} 입니다.')
6번 문제 : 특정 연령대 승객 추출
- 문제) 20세 이하의 승객의 이름들을 추출 하여 승객의 이름을 key로, 승객의 나이를 value로 하는 딕셔너리를 완성하세요.
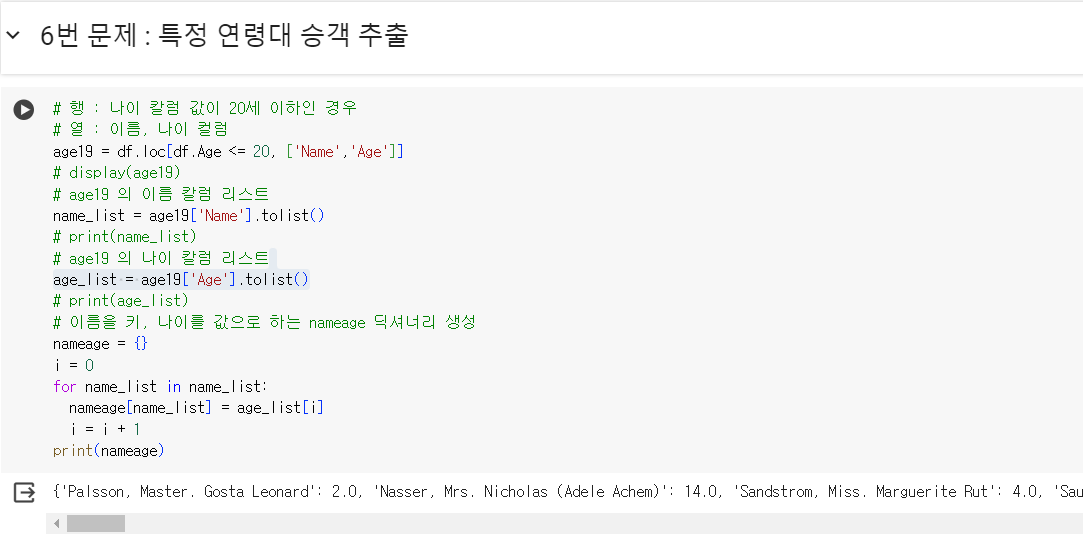
# 행 : 나이 칼럼 값이 20세 이하인 경우
# 열 : 이름, 나이 컬럼
age19 = df.loc[df.Age <= 20, ['Name','Age']]
# display(age19)
# age19 의 이름 칼럼 리스트
name_list = age19['Name'].tolist()
# print(name_list)
# age19 의 나이 칼럼 리스트
age_list = age19['Age'].tolist()
# print(age_list)
# 이름을 키, 나이를 값으로 하는 nameage 딕셔너리 생성
nameage = {}
i = 0
for name_list in name_list:
nameage[name_list] = age_list[i]
i = i + 1
print(nameage)#챌린지 문항 (4개)
7번 문제 : 가장 많은 탑승객 수를 가진 선실 등급 찾기
- 문제) 타이타닉의 선실 등급 중에서 가장 많은 탑승객이 이용한 선실 등급을 찾으세요
선실 등급은 ‘Pclass’ column에 있으며 1,2,3 등급으로 이루어져 있음
# 선실 등급 기준으로 그룹바이, 각 그룹별 갯수 조회
pc = df.groupby('Pclass').count()
# 그룹별 갯수 데이터프레임 딕셔너리화
pcd = pc.to_dict()
# 딕셔너리 중 PassengerId가 최대값인 값 찾기
mpcd = max(pcd["PassengerId"])
print(f'가장 많은 탑승객 수를 가진 선실 등급은 {mpcd} 등급 입니다.')
# 가장 많은 탑승객 수를 가진 선실 등급 = 38번 문제 : 가장 많은 요금을 낸 승객 정보 출력
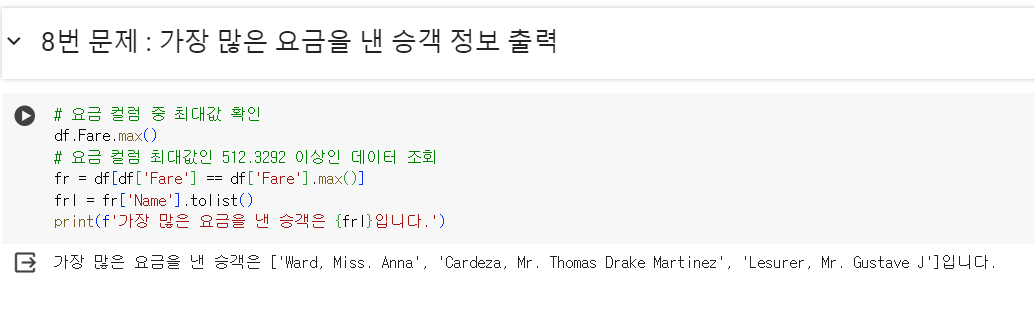
- 문제) 타이타닉의 승객 중 가장 많은 요금을 낸 승객을 찾으세요
요금 정보는 ‘Fare’ column에 있음
# 요금 컬럼 중 최대값 확인 df.Fare.max() # 요금 컬럼 최대값인 512.3292 이상인 데이터 조회 fr = df[df['Fare'] == df['Fare'].max()] frl = fr['Name'].tolist() print(f'가장 많은 요금을 낸 승객은 {frl}입니다.')
9번 문제 : 각 성별의 생존율 계산
- 문제) 타이타닉 각 성별 (남성/여성) 각각의 생존율을 계산하세요

# 남성 생존율 계산 = 남성 생존자 수 / 전체 남성 수
# 전체 남성 수
men = len(df[df['Sex']=='male'])
# 남성 생존자 수
smen = len(df[(df['Sex']=='male') & (df['Survived']==1)])
# 남성 생존율 (men survived rate)
msr = smen / men * 100
print(f'남성 생존율은 {msr} % 입니다')
# 여성 생존율 계산 = 여성 생존자 수 / 전체 여성 수
# 전체 여성 수
women = len(df[df['Sex']=='female'])
# 여성 생존자 수
swomen = len(df[(df['Sex']=='female') & (df['Survived']==1)])
# 여성 생존율 (women survived rate)
wsr = swomen / women * 100
print(f'여성 생존율은 {wsr} % 입니다')10번 문제 : 가장 많은 출발 항구 찾기
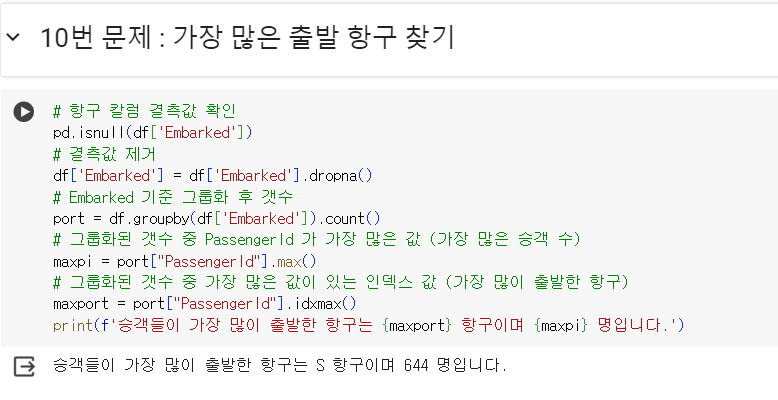
- 문제) 승객들이 출발한 항구 중에서 가장 많은 항구를 찾고 그 항구를 출발한 승객 수를 출력하세요.
- 출발 항구에 대한 정보는 ‘Embarked’ column에 C, Q, S로 정의되어 있음
- ‘Embarked’ column에는 결측값이 일부 존재
코드가 결측값으로 인한 문제가 발생하는 코드인지 확인!
# 항구 칼럼 결측값 확인 pd.isnull(df['Embarked']) # 결측값 제거 df['Embarked'] = df['Embarked'].dropna() # Embarked 기준 그룹화 후 갯수출력 port = df.groupby(df['Embarked']).count() # 그룹화된 갯수 중 PassengerId 가 가장 많은 값 (가장 많은 승객 수) maxpi = port["PassengerId"].max() # 그룹화된 갯수 중 가장 많은 값이 있는 인덱스 값 (가장 많이 출발한 항구) maxport = port["PassengerId"].idxmax() print(f'승객들이 가장 많이 출발한 항구는 {maxport} 항구이며 {maxpi} 명입니다.')
#챌린지 ++ 문항 (2개)
11번 문제 : 함수로 만들어 정리하기
- 문제) 2번문제 부터 10번 문제까지 작성했던 코드들을 함수로 만드세요.
- 함수를 만들 때 dataframe에서 각 문제의 요구에 따라
특정 column이 선택된 series를 인수로 받을 수 있도록 매개변수로 설정
- 각 문제에서 출력해야 하는 값을 함수에서 반환되는 값으로 설정
- 만들어진 함수를 사용하여 2번문제 부터 10번 문제까지 결과 출력# 2번 문제 함수로 만들기
def question2 (series):
survived = df[series==1]
survivor = len(survived)
return survivor
survivor = question2 (df['Survived'])
print("Q2,"f'생존자 수는 {survivor} 입니다.\n')# 3번 문제 함수로 만들기
def question3 (series):
series = series.dropna()
series.sum()
series.count()
AvgAge = series.sum() / series.count()
return AvgAge
AvgAge = question3 (df['Age'])
print("Q3,"f'평균 연령은 {AvgAge} 세 입니다.\n')# 4번 문제 함수로 만들기
def question4 (series1, series2):
condition = (series1 == 'female') & (series2 == 1)
df.loc[condition, ['Sex','Survived']]
ws = df.loc[condition, ['Sex','Survived']]
wsn = len(ws)
return wsn
wsn = question4 (df['Sex'],df['Survived'])
print("Q4,"f'여성 생존자 수는 {wsn}명 입니다.\n')# 5번 문제 함수로 만들기
def question5 (series1, series2):
df['Family'] = series1 + series2
maxfam = df[df["Family"] == df.Family.max()]
lmf = maxfam["Name"].tolist()
return lmf
lmf = question5 (df['SibSp'],df['Parch'])
print("Q5,"f'가장 많은 가족을 가진 승객은 {lmf} 입니다.\n')# 6번 문제 함수로 만들기
def question6 (series):
age20 = df[series<=20]
name2age = {age20.loc[i,'Name'] : age20.loc[i,'Age'] for i in age20.index}
return name2age
name2age = question6 (df['Age'])
print("Q6,",name2age,"\n")# 7번 문제 함수로 만들기
def question7 (col):
pc = df.groupby(col).count()
pcd = pc.to_dict()
mpcd = max(pcd["PassengerId"])
return mpcd
mpcd = question7 ('Pclass')
print("Q7,"f'가장 많은 탑승객 수를 가진 선실 등급은 {mpcd} 등급 입니다.\n')# 8번 문제 함수로 만들기
def question8 (series):
fr = df[series == series.max()]
frl = fr['Name'].tolist()
return frl
frl = question8 (df['Fare'])
print("Q8,"f'가장 많은 요금을 낸 승객은 {frl}입니다.\n')# 9번 문제 함수로 만들기
def question9 (series1, series2):
men = len(df[series1=='male'])
smen = len(df[(series1=='male') & (series2==1)])
msr = smen / men * 100
women = len(df[series1=='female'])
swomen = len(df[(series1=='female') & (series2==1)])
wsr = swomen / women * 100
return msr, wsr
msr, wsr = question9 (df['Sex'],df['Survived'])
print("Q9,"f'남성 생존율은 {msr} %, 여성 생존율은 {wsr} % 입니다.\n')# 10번 문제 함수로 만들기
def question10 (series):
pd.isnull(series)
series = series.dropna()
port = df.groupby(series).count()
maxpi = port["PassengerId"].max()
maxport = port["PassengerId"].idxmax()
return maxpi, maxport
maxpi, maxport = question10 (df['Embarked'])
print("Q10,"f'승객들이 가장 많이 출발한 항구는 {maxport} 항구이며 {maxpi} 명입니다.\n')
12번 문제 : 함수의 기능 사용하기
- 문제) 4번문제와 6번문제 각각 조건문에 있는 성별(’female’, ‘male’)과 나이를 매개변수를 사용할 수 있도록 설정하고 각각의 함수에서 성별과 나이를 인수로 받아올 수 있도록 함수를 수정하세요.
- 단, 키워드 인수를 사용할 수 있도록 하고 매개변수에 기본값을 설정
(4번 성별의 기본값은 ‘female’, 6번 나이의 기본값은 20)
- 4번 문제의 성별 인수를 넣지 않고 결과 출력
- 4번 문제의 성별 인수를 ‘male’이라고 설정하고 결과 출력
- 6번 문제의 나이 인수를 넣지 않고 결과 출력
- 6번 문제의 나이 인수를 30, 40, 50 각각 바꾸어 보며 결과 출력# 4번 문제 함수로 만들기
def question4 (sex = 'female'):
condition = (df['Sex'] == sex) & (df['Survived'] == 1)
df.loc[condition, ['Sex','Survived']]
ws = df.loc[condition, ['Sex','Survived']]
wsn = len(ws)
mw = sex
return mw, wsn
# 성별 인수를 넣지 않았을 때
mw, wsn = question4 ()
print("Q4,"f'{mw} 생존자 수는 {wsn}명 입니다.\n')
# 성별 인수를 'male'로 설정했을 때
mw, wsn = question4 ('male')
print("Q4,"f'{mw} 생존자 수는 {wsn}명 입니다.\n')
# 6번 문제 함수로 만들기
def question6 (age = 20):
n_age = df[df['Age']<= age]
name2age = {n_age.loc[i,'Name'] : n_age.loc[i,'Age'] for i in n_age.index}
return name2age
# 나이 인수를 넣지 않았을 때
name2age = question6 ()
print("Q6,",name2age, "\n")
# 나이 30일 때
name2age = question6 (30)
print("Q6,",name2age, "\n")
# 나이 40일 때
name2age = question6 (40)
print("Q6,",name2age, "\n")
# 나이 50일 때
name2age = question6 (50)
print("Q6,",name2age, "\n")

커피 좋아하는 데이터 꿈나무