개요
심화 프로젝트
- 부트캠프 시작 10주차 !
지식의 홍수에 빠져 머신러닝 기법들을 학습한 결과물을 만들어 낼 시간이 되었다.
-
"ON AIR 분석 절차를 기반으로한 프로젝트" + ML(머신러닝)
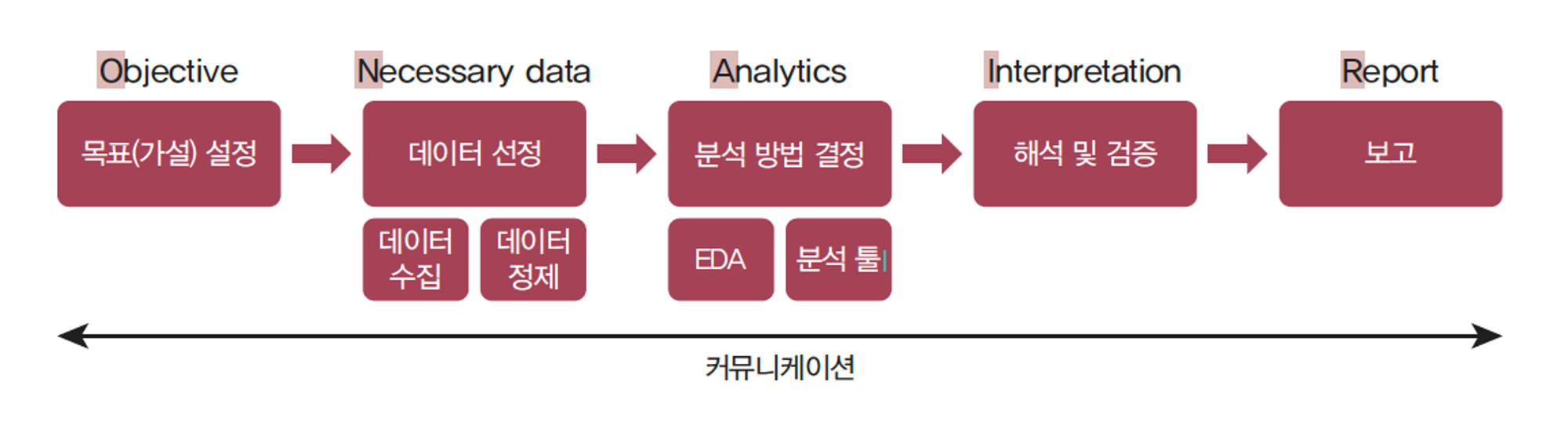
Objective (목표)- 프로젝트 목표 : 프로젝트의 주요 목표를 명확히 기술,
어떤 문제를 해결하고자 하는지, 어떤 비즈니스 목표를 달성하려는지 설명 - 예상 결과물 : 프로젝트를 통해 기대되는 결과물과 도출하고자 하는 인사이트 명시
- 프로젝트 목표 : 프로젝트의 주요 목표를 명확히 기술,
Necessary Data (데이터)- 데이터 소스 : 사용할 데이터의 출처를 설명하고, 필요한 데이터 유형과 범위 명시
- 데이터 수집 계획 : 데이터를 수집하기 위한 계획과 방법 기술,
데이터 수집의 정확성과 완전성을 보장하기 위한 조치 고려
Analytics (분석)- 분석 방법 : 사용할 데이터 분석 기법과 모델을 선정하고 분석을 위한 절차 설명
- 데이터 처리 : 데이터를 정제하고 전처리하는 방법 기술, 분석에 필요한 데이터의 품질 확인
- 시각화 계획 : 데이터를 시각적으로 표현하여 인사이트를 도출하는 계획 제시
- Machine Learning (머신러닝)
- 모델 학습 : 다양한 머신러닝 알고리즘을 사용해 모델 학습
- 모델 평가 및 선택 :
- 교차 검증 : 데이터를 여러 번 나누어 학습, 평가하여 모델의 일반화 성능 확인
- 평가 지표 : 정확도, 정밀도, 재현율 , F1 점수, AUC 등을 사용해 모델 성능 평가
Interpretation (해석)- 분석 결과 해석 : 분석 결과를 해석하고, 비즈니스에 어떻게 적용할 수 있는지를 설명
- 인사이트 도출: 데이터에서 도출된 인사이트와 향후 전략 수립을 위한 제언을 제시
Report (보고)- 보고서 구조: 보고서의 구조와 형식을 정의하고, 어떤 정보를 포함할 것인지를 설명
- 시각화 활용: 보고서에 사용할 시각화 도구 및 방법을 결정하고, 강조할 요소를 구체화
- 보고서 작성 일정: 보고서 작성 및 발표 일정을 계획하고, 이를 관리할 방법을 기술
- What to do: 통계와 머신러닝 기법을 활용한 분석 프로젝트

📌 1일차
📌 주제 선정
나의 의견
프로젝트 중점 > 어떤 역량을 가진 데이터 분석가인가
-
주제 선정 관련
-
머신러닝 알고리즘 선호도(경험하고 싶은) : 군집 - 분류 - 회귀 순
-
하고 싶은 주제
-
마케팅데이터 - 고객 클러스터링 :
현업에서 사용할 법한 고객 분류에 대한 내용이고,
클러스터링을 통해 고객을 특정 기준에 따라 군집화하고,
군집별 인사이트를 도출하는 프로세스에 대한 경험을 해보고 싶어서. -
트위터 사용자 성별 분류 프로젝트 :
사용자의 정형, 비정형 데이터 특성들을 분석하여
성별과 같은 특성을 분류 & 예측하는 프로세스에 대한 경험을 해보고 싶어서.
-
팀원들과 회의 결과,
주제별 선호도에 대한 투표 + 각자의 데이터 분석 역량을 고려하여
스포티파이 데이터를 활용한 음원 클러스터링 주제를 선택하게 되었다.

- 프로젝트 개요
프로젝트 주제 선정
1. 주제 선정 이유 :
플랫폼에서 활용되는 추천 시스템을 이해하고,
군집 분석과 대규모 데이터 처리의 기술적 도전을 통해
음원 클러스터링을 통한 추천 시스템 구축 경험
2. 프로젝트명 :
추천 시스템 성능 향상을 위한 음원 군집분석
3. 프로젝트 목표 :
Spotify 음원 데이터를 클러스터링(군집) 기법을 사용해 유사성에 따라 분류하고,
그 과정 및 기준을 분석하여 추천 시스템 구축
4. 프로젝트 핵심 내용 :
1) 추천 시스템 이해 :
플랫폼에서 사용되는 추천 시스템의 운영 방식 학습
2) 음원 간 유사성 파악에 주요한 특징 선정 :
음원 간 유사성을 파악하기 위해 주요한 특징 선정
3) 군집 분석 적용 :
대규모 데이터를 클러스터링 기법을 사용해 처리하고 유사성 분석,
단순 군집 분석과 주요 특징 기반의 군집 분석 결과 비교📌 데이터 살펴보기
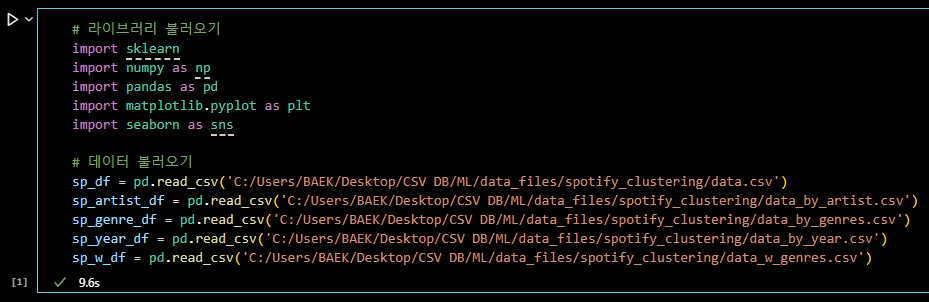
# 라이브러리 불러오기 import sklearn import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # 데이터 불러오기 sp_df = pd.read_csv('C:/Users/BAEK/Desktop/CSV DB/ML/data_files/spotify_clustering/data.csv') sp_artist_df = pd.read_csv('C:/Users/BAEK/Desktop/CSV DB/ML/data_files/spotify_clustering/data_by_artist.csv') sp_genre_df = pd.read_csv('C:/Users/BAEK/Desktop/CSV DB/ML/data_files/spotify_clustering/data_by_genres.csv') sp_year_df = pd.read_csv('C:/Users/BAEK/Desktop/CSV DB/ML/data_files/spotify_clustering/data_by_year.csv') sp_w_df = pd.read_csv('C:/Users/BAEK/Desktop/CSV DB/ML/data_files/spotify_clustering/data_w_genres.csv')
# 데이터 살펴보기 sp_df.head()
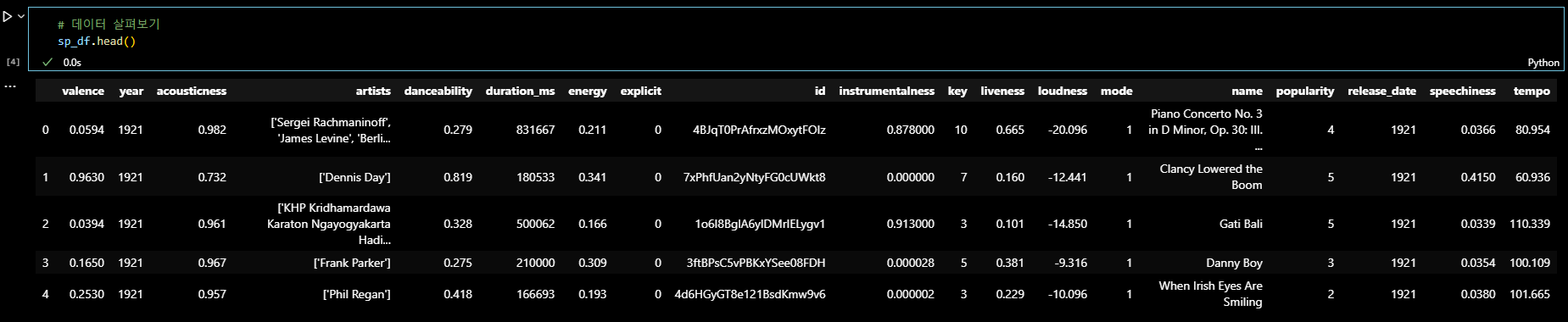
sp_artist_df.head()

sp_genre_df.head()

sp_year_df.head()
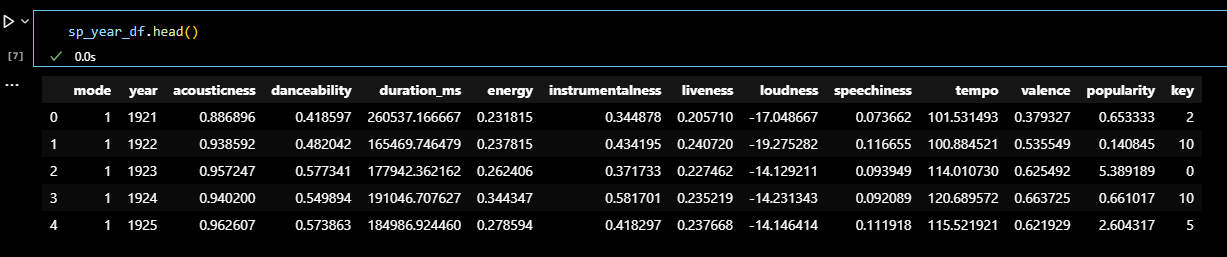
sp_w_df.head()

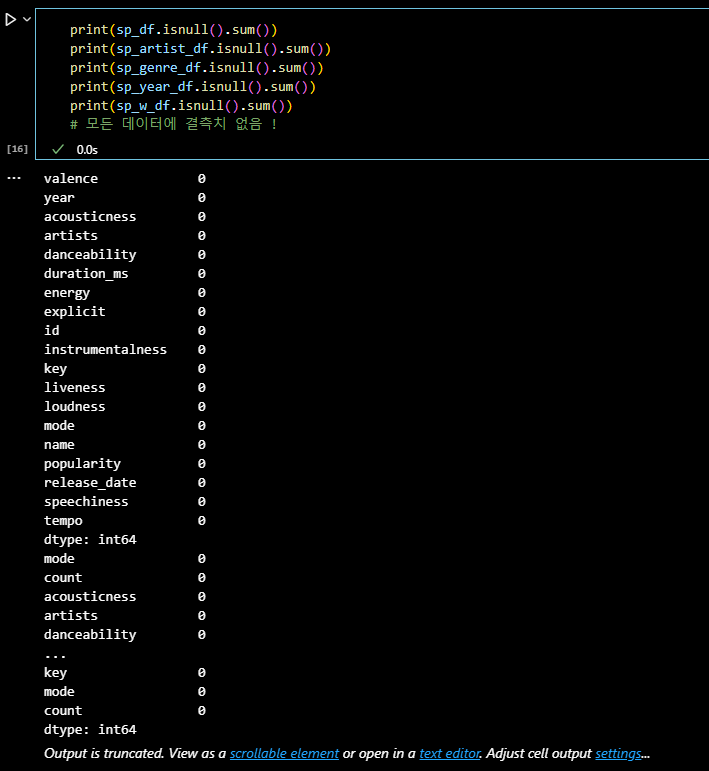
print(sp_df.isnull().sum()) print(sp_artist_df.isnull().sum()) print(sp_genre_df.isnull().sum()) print(sp_year_df.isnull().sum()) print(sp_w_df.isnull().sum()) # 모든 데이터에 결측치 없음 !
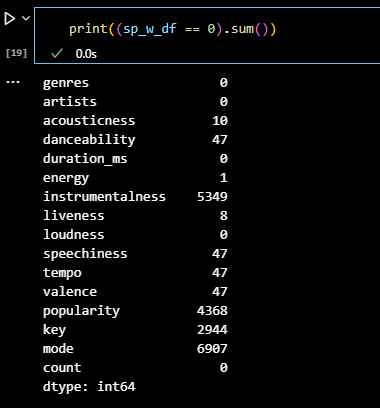
# 데이터 값이 0인 갯수 확인 print((sp_w_df == 0).sum())
# 각 컬럼의 분포 확인 sp_w_df.hist(bins=50, figsize=(20, 15)) plt.show()
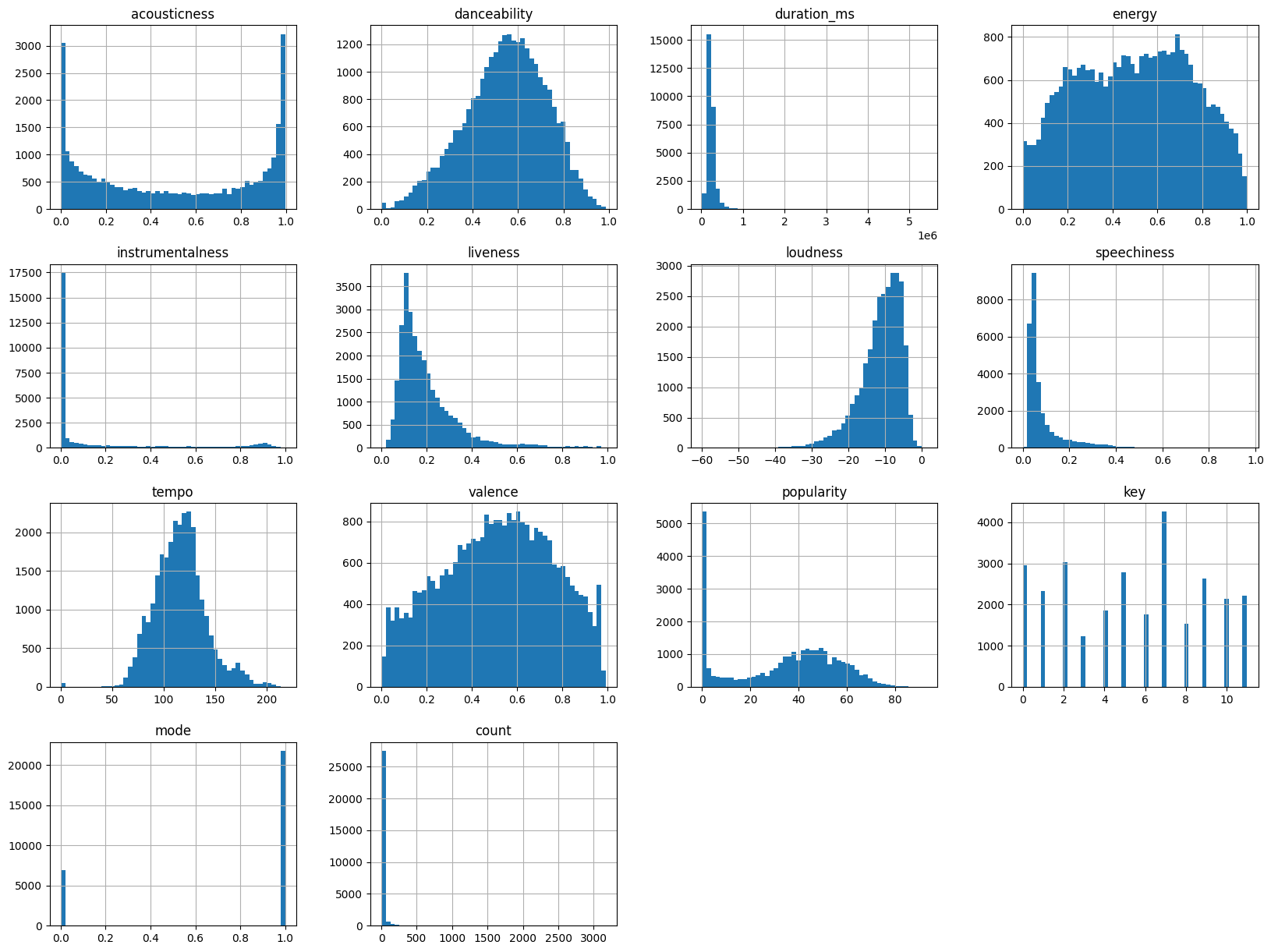
첫번째 데이터셋은 데이터의 결측치도 없고
음악 장르별로 군집화하여 특성을 분류한 후,
추천 시스템에 도입하는 등의 분석이 가능할 것으로 보였으나
데이터 행이 20만개 정도인 것이 쟁점이 되었다.
팀원들과 다른 데이터셋을 들여다 보다가
100만개 이상의 행을 가진 데이터셋을 확인하였고,
비지도학습을 위해 많은 양의 데이터셋을 선택하게 되었다.
# 라이브러리 불러오기
import sklearn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 다른 데이터 불러오기
# 행이 100만개 이상의 음원 데이터;
# 비지도 학습에 적용하기 유리할 것 같아서 선택
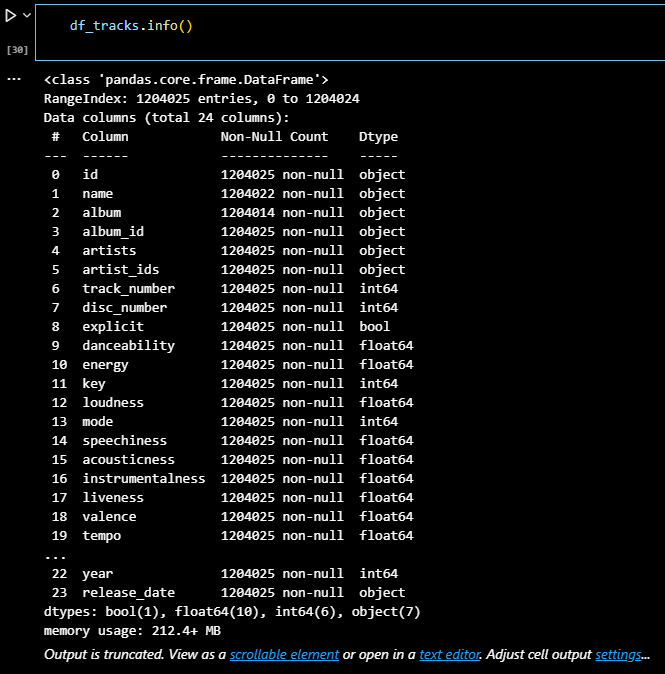
df_tracks = pd.read_csv('C:/Users/BAEK/Desktop/CSV DB/ML/data_files/spotify_clustering/tracks_features.csv')
df_tracks.info()
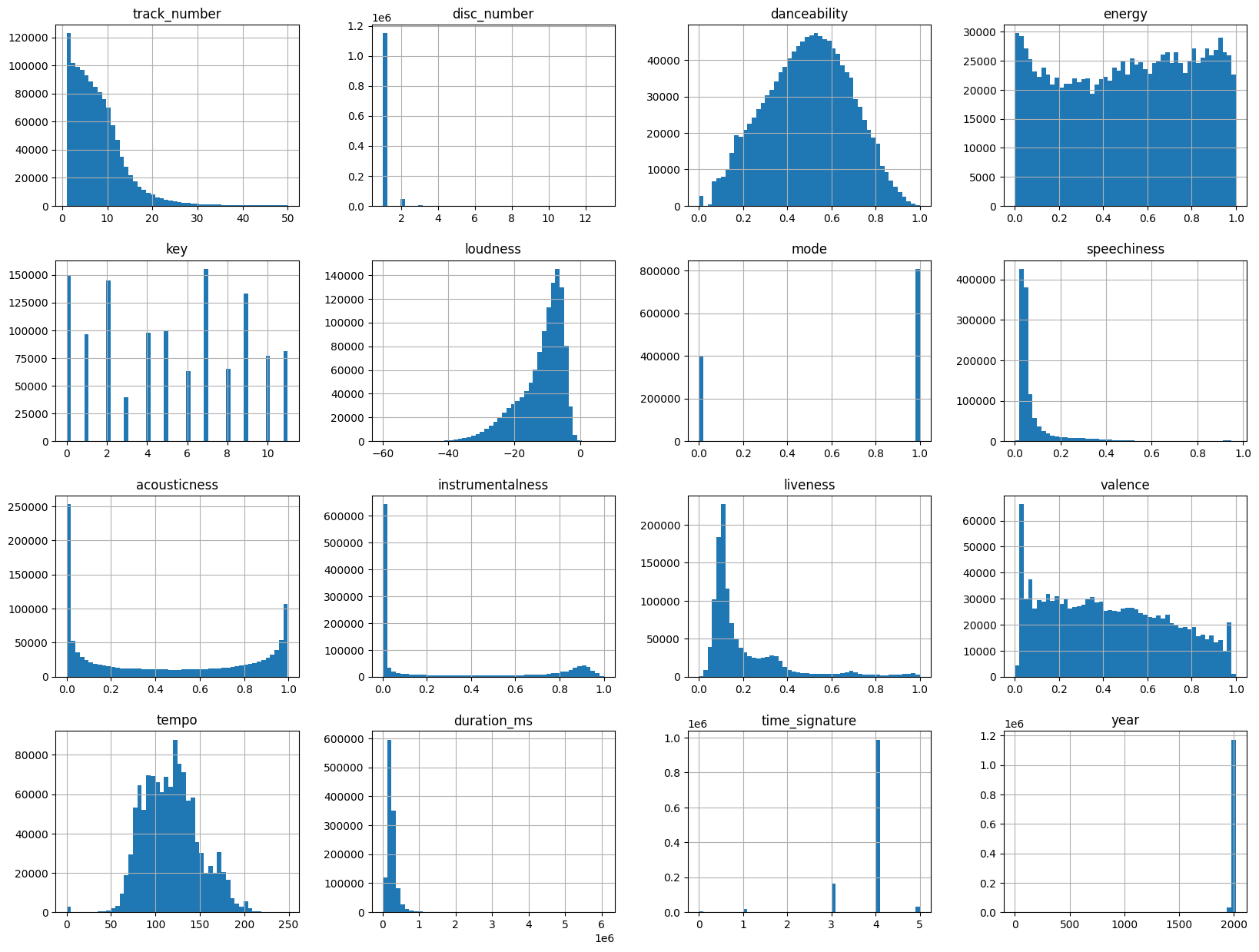
# 각 컬럼의 분포 확인 df_tracks.hist(bins=50, figsize=(20, 15)) plt.show()
📌 1일차 스크럼 정리
프로젝트 주제 선정 : 스포티파이 데이터를 활용한 음원 클러스터링
활용 데이터 선정 :
- Spotify 1.2M+ Songs
https://www.kaggle.com/datasets/rodolfofigueroa/spotify-12m-songs
데이터 선정 이유 :
- 비지도학습을 위해 양이 많은 데이터 선정
내일 오전 스크럼까지 해야할 내용 :
- 데이터 특성 파악
📌 2일차
📌 군집 분석 시도
- 목표 : 약 120만 개의 행을 가진 데이터로 군집 분석의 전체 사이클 돌려보기
# 음악의 특징을 반영할 수 있는 컬럼 선택 cols = ['danceability', 'energy', 'loudness', 'acousticness', 'instrumentalness', 'liveness', 'valence', 'tempo'] # 결측치 확인 = 없음 df_tracks[cols].isnull().sum()
RobustScaler:
데이터의 중앙값을 기준으로 사분범위 내 값으로 스케일링하여
이상치에 덜 영향을 받는 표준화 방법
# 데이터 스케일링 (로버스트) from sklearn.preprocessing import RobustScaler rs = RobustScaler() display(df_tracks[cols].head(3)) df_tracks[cols] = rs.fit_transform(df_tracks[cols]) display(df_tracks[cols].head(3)) df_scaled = df_tracks[cols]
# 주성분 개수를 판단하기 위한 pca 임의 시행 pca = PCA(n_components = 3) pca.fit(df_scaled) # 설정한 주성분의 갯수로 전체 데이터 분산을 얼만큼 설명 가능한지 print(pca.explained_variance_ratio_) print(pca.explained_variance_ratio_.sum())

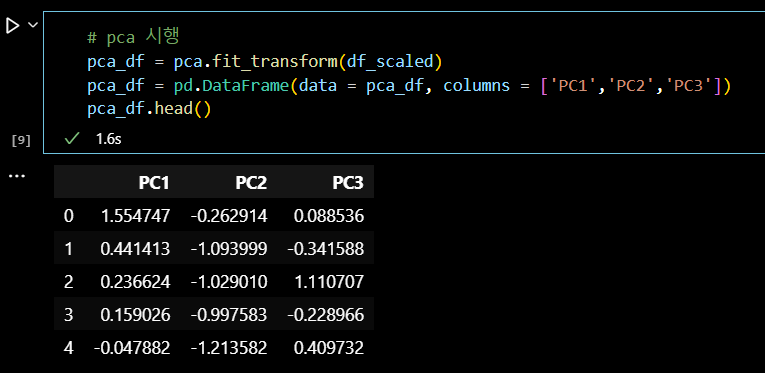
# pca 시행 pca_df = pca.fit_transform(df_scaled) pca_df = pd.DataFrame(data = pca_df, columns = ['PC1','PC2','PC3']) pca_df.head()
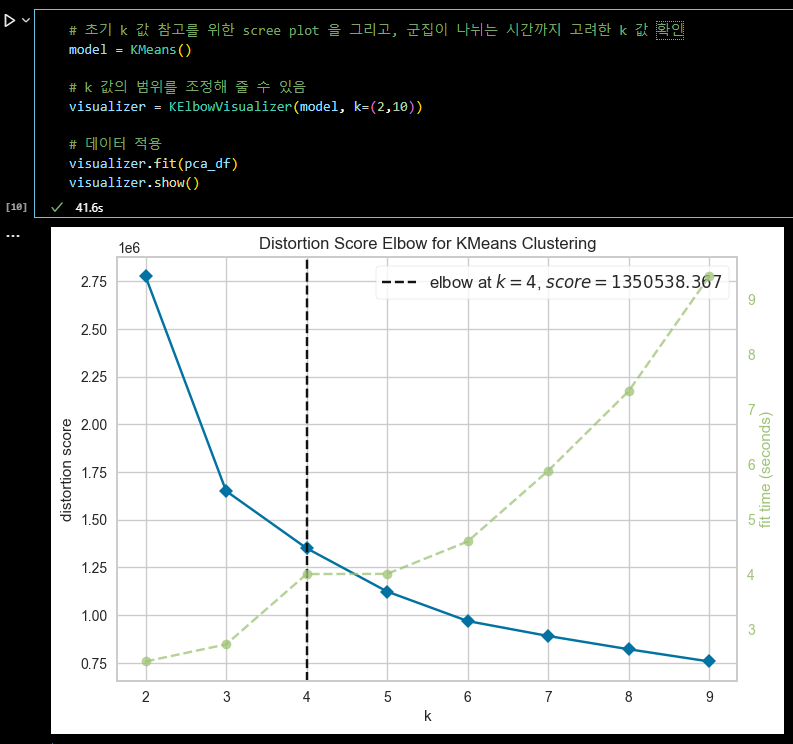
# 초기 k 값 참고를 위한 scree plot 을 그리고, 군집이 나뉘는 시간까지 고려한 k 값 확인 model = KMeans() # k 값의 범위를 조정해 줄 수 있음 visualizer = KElbowVisualizer(model, k=(2,10)) # 데이터 적용 visualizer.fit(pca_df) visualizer.show()
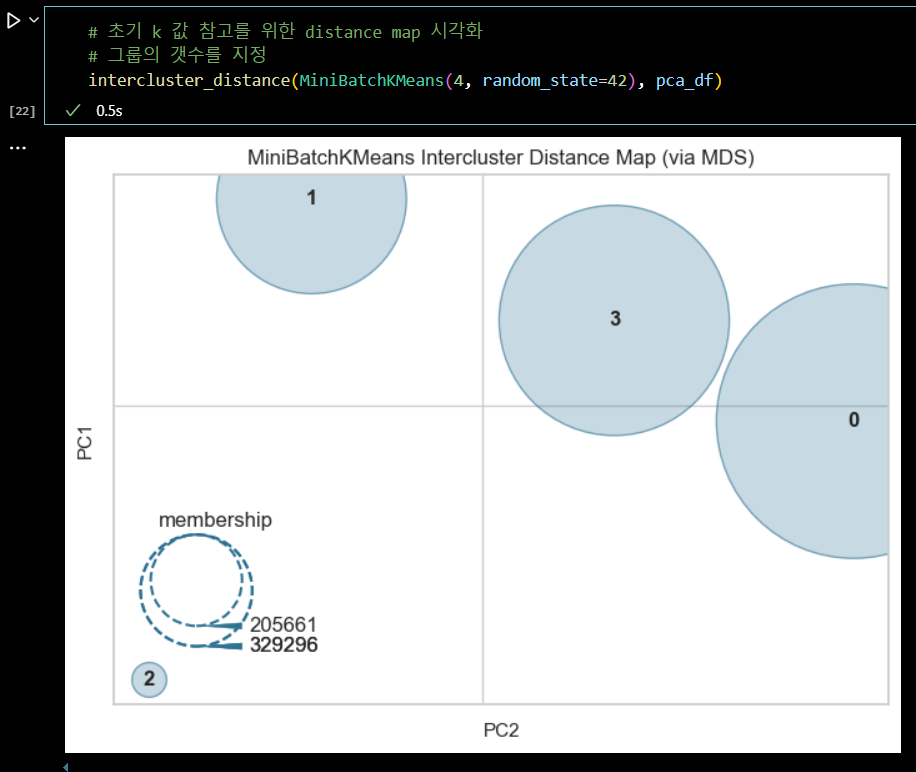
# 초기 k 값 참고를 위한 distance map 시각화 # 그룹의 갯수를 지정 intercluster_distance(MiniBatchKMeans(4, random_state=42), pca_df)
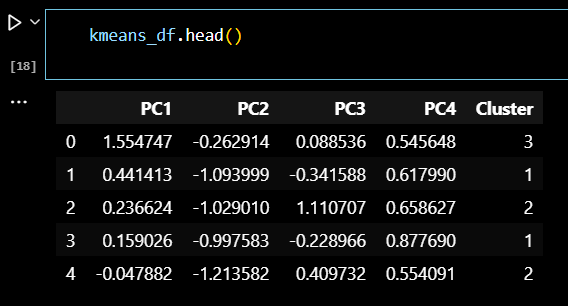
# K - MEANS # 군집개수(n_cluster) 4, 초기 중심 설정방식 랜덤 optimal_k = 4 kmeans = KMeans(n_clusters = optimal_k, random_state = 42, init = 'random') # pca df 를 이용한 kmeans 알고리즘 적용 kmeans.fit(pca_df) clusters = kmeans.fit_predict(pca_df) # 클러스터 번호 가져오기 labels = kmeans.labels_ # 클러스터 번호가 할당된 데이터셋 생성 kmeans_df = pd.concat([pca_df, pd.DataFrame({'Cluster' : labels})], axis = 1)
# 클러스터링 데이터셋 확인 kmeans_df.head()
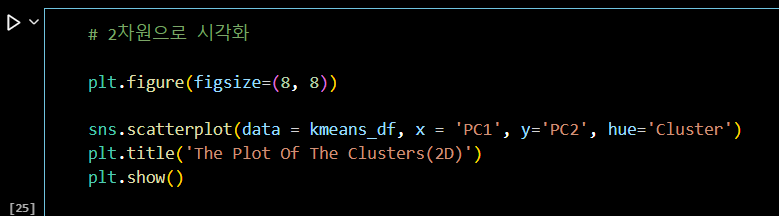
# 2차원으로 시각화
plt.figure(figsize=(8, 8))
sns.scatterplot(data = kmeans_df, x = 'PC1', y='PC2', hue='Cluster')
plt.title('The Plot Of The Clusters(2D)')
plt.show()
# 전체 데이터셋에서 샘플링 (10000개 샘플) import random sample_size = 10000 if len(df_scaled) > sample_size: sample_indices = random.sample(range(len(df_scaled)), sample_size) df_sample = df_scaled.iloc[sample_indices] clusters_sample = clusters[sample_indices] else: df_sample = df_scaled clusters_sample = clusters # 실루엣 계수 계산 (샘플 데이터셋 사용) from sklearn.metrics import silhouette_score, silhouette_samples silhouette_avg = silhouette_score(df_sample, clusters_sample) silhouette_values = silhouette_samples(df_sample, clusters_sample) # 클러스터별 실루엣 플롯 생성하기 fig, ax = plt.subplots(figsize = (10, 6)) y_lower = 10 for i in range(optimal_k): ith_cluster_silhouette_values = silhouette_values[clusters_sample == i] ith_cluster_silhouette_values.sort() size_cluster_i = ith_cluster_silhouette_values.shape[0] y_upper = y_lower + size_cluster_i color = plt.cm.nipy_spectral(float(i) / optimal_k) ax.fill_betweenx(np.arange(y_lower, y_upper), 0, ith_cluster_silhouette_values, facecolor=color, edgecolor=color, alpha=0.7) ax.text(-0.05, y_lower + 0.5 * size_cluster_i, str(i)) y_lower = y_upper + 10 ax.set_title('silhouette plot') ax.set_xlabel('silhouette_values') ax.set_ylabel('cluster label') ax.axvline(x=silhouette_avg, color="red", linestyle="--") ax.set_yticks([]) ax.set_xticks(np.arange(-0.1, 1.1, 0.2)) plt.show()

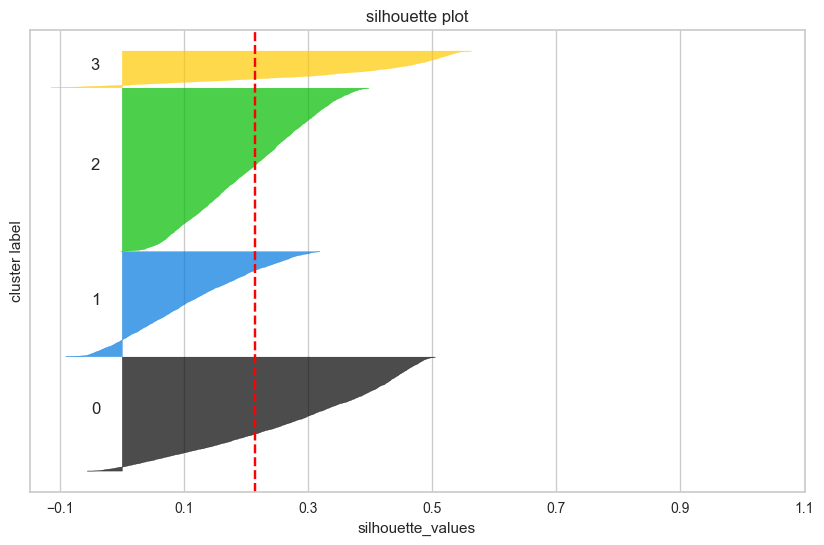
📌 2일차 스크럼 정리
비지도학습에 많은 데이터양이 무조건 좋은 것은 아니었다.
코드를 한 번 돌릴 때, 1시간이 넘어가고,
샘플 데이터셋을 만들어 시간을 단축시켰으나,
유의미한 결과를 내지 못하는 경우도 생겼다.-
팀원들도 2번 데이터셋으로 분석을 진행한 결과,
전처리, 군집 분석, 실루엣 계수 계산 과정에서 시간이 너무 오래 걸리는 문제가 있었다. -
팀 회의 결과, 1번 데이터셋 (17만 개) 으로 분석을 진행한 후,
군집화가 잘 이루어지고 실루엣 계수가 가장 높은 모델을 선택하여
같은 방식의 전처리와 알고리즘 과정을 2번 데이터셋 (120만 개)에 적용해보기로 했다.
- 역할 분담
-
계획 : 데이터셋 1번으로 모델링 후 데이터셋 2번에 적용
이상치 제거
백: RobustScaler 스케일링 후 군집 분석
김: Z-score 이상치 제거 후 군집 분석
이: Isolation 이상치 제거 후 군집 분석
강: DBSCAN or (Z-score) 이상치 제거 후 군집 분석
진: IQR 이상치 제거 후 군집 분석적용 가능한 클러스터링 모델
- K-Means
- 계층적 클러스터링
- DBSCAN
- 가우시안 혼합 모델 (GMM)
-
평가 : 모델 적용 후 실루엣 계수 확인
-
📌 3일차
📌 군집 분석 시도
- 목표 : 17만 개 데이터셋으로 군집 분석 후 군집 결과가 좋은 모델 찾기
- 수치형 데이터들을 로버스트(ROBUST SCALER) 스케일링 후
K-MEANS 알고리즘으로 군집화 및 평가
# 기본 라이브러리 import import pandas as pd import numpy as np # 시각화 라이브러리 import import seaborn as sns import matplotlib.pyplot as plt # 표준화 라이브러리 import from sklearn.preprocessing import StandardScaler # k 값 참고: scree plot을 통한 k 값 확인을 위한 라이브러리 import from yellowbrick.cluster import KElbowVisualizer # k 값 참고: distance map 라이브러리 import from yellowbrick.cluster import intercluster_distance from sklearn.cluster import MiniBatchKMeans # k 값 참고: 실루엣 계수 확인을 위한 라이브러리 import from sklearn.metrics import silhouette_score # 데이터셋 주성분 분석중 하나인 pca 를 수행하기 위한 라이브러리 import from sklearn.decomposition import PCA # k-means 알고리즘 활용을 위한 라이브러리 import from sklearn.cluster import KMeans import warnings warnings.filterwarnings('ignore') # 데이터 불러오기 sp_w_df = pd.read_csv('C:/Users/BAEK/Desktop/CSV DB/ML/data_files/spotify_clustering/data_w_genres.csv') # 음악 특징과 관련이 있는 수치형 컬럼 선택 cols = ['acousticness', 'danceability', 'energy', 'instrumentalness', 'liveness', 'loudness', 'valence', 'tempo', 'popularity', 'key'] scale_cols = ['tempo', 'popularity', 'key'] # 데이터 스케일링 (로버스트) from sklearn.preprocessing import RobustScaler rs = RobustScaler() display(sp_w_df[cols].head(3)) # sp_w_df[scale_cols] = sd.fit_transform(sp_w_df[scale_cols]) sp_w_df[scale_cols] = rs.fit_transform(sp_w_df[scale_cols]) display(sp_w_df[cols].head(3)) df_scaled = sp_w_df[cols]
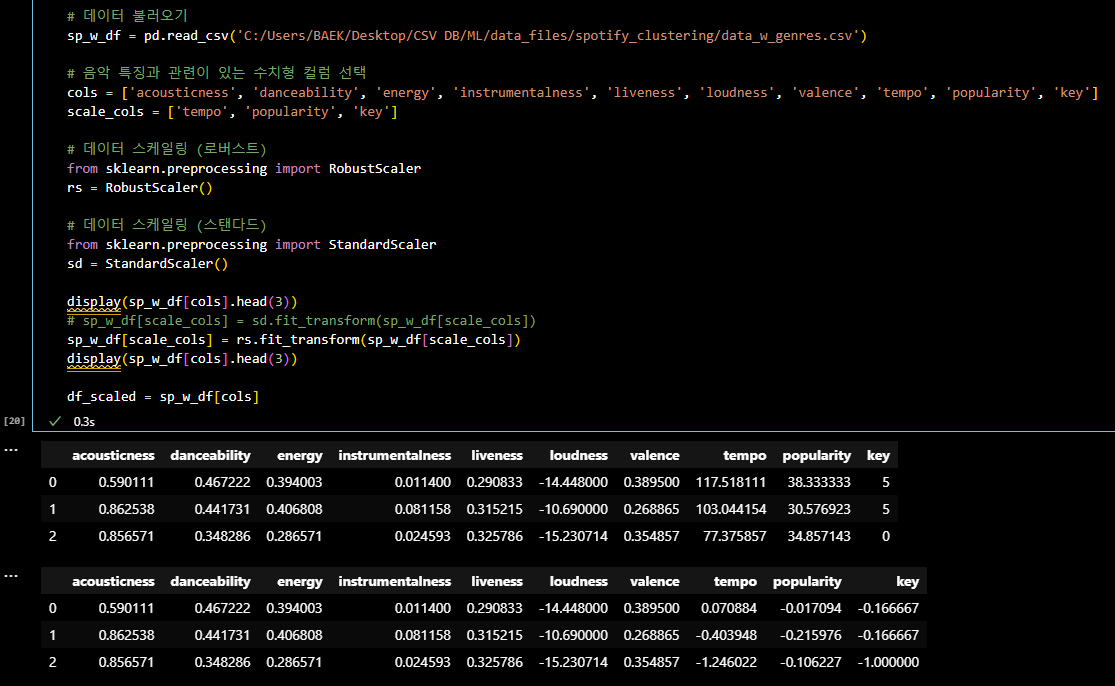
# 주성분 개수를 판단하기 위한 pca 임의 시행 pca = PCA(n_components = 3) pca.fit(df_scaled) # 설정한 주성분의 갯수로 전체 데이터 분산을 얼만큼 설명 가능한지 print(pca.explained_variance_ratio_) # pca 시행 pca_df = pca.fit_transform(df_scaled) pca_df = pd.DataFrame(data = pca_df, columns = ['PC1','PC2','PC3']) pca_df.head() # PC1 : 95 % 설명력에 대한 회의가 필요 # 주성분 나누는 컬럼 기준?
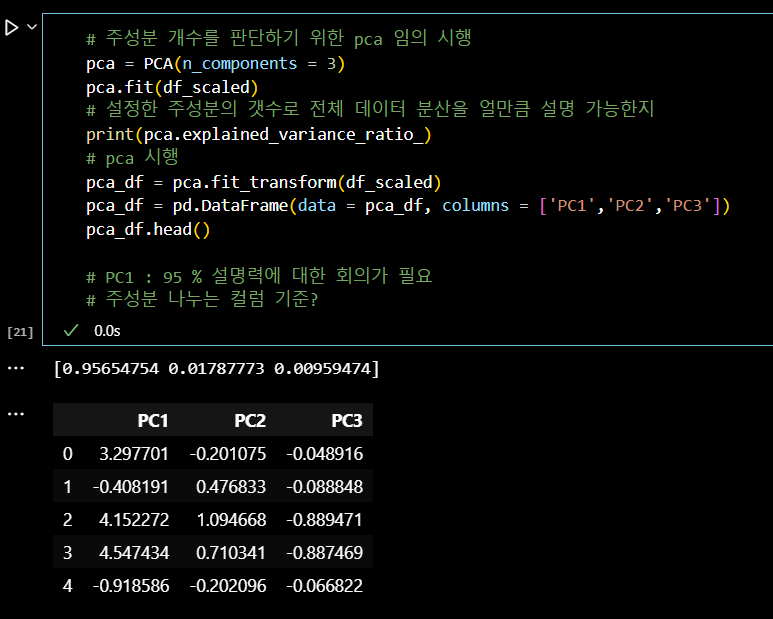
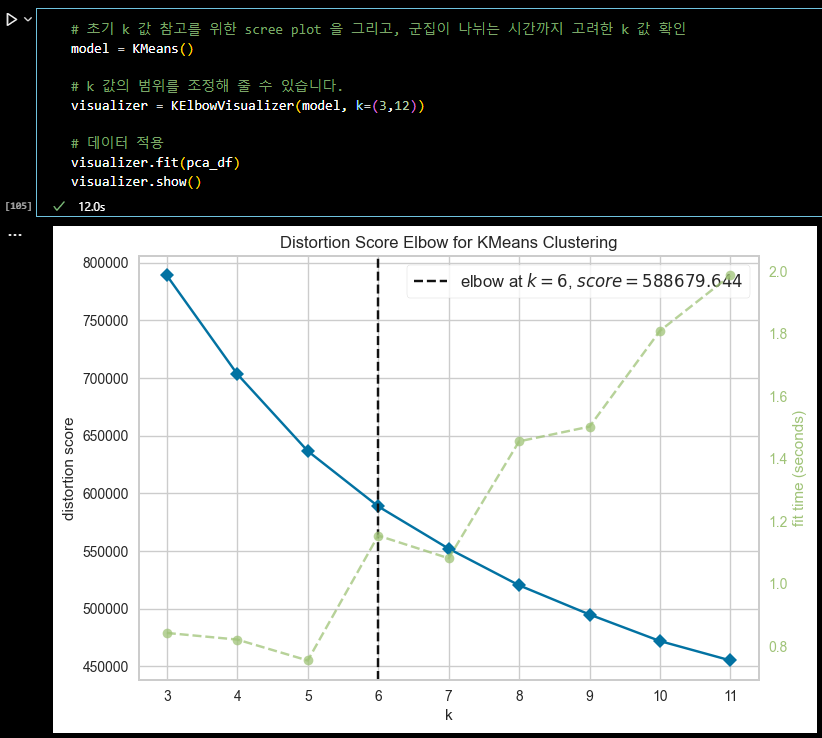
# 초기 k 값 참고를 위한 scree plot 을 그리고, 군집이 나뉘는 시간까지 고려한 k 값 확인 model = KMeans() # k 값의 범위를 조정해 줄 수 있습니다. visualizer = KElbowVisualizer(model, k=(3,12)) # 데이터 적용 visualizer.fit(pca_df) visualizer.show()
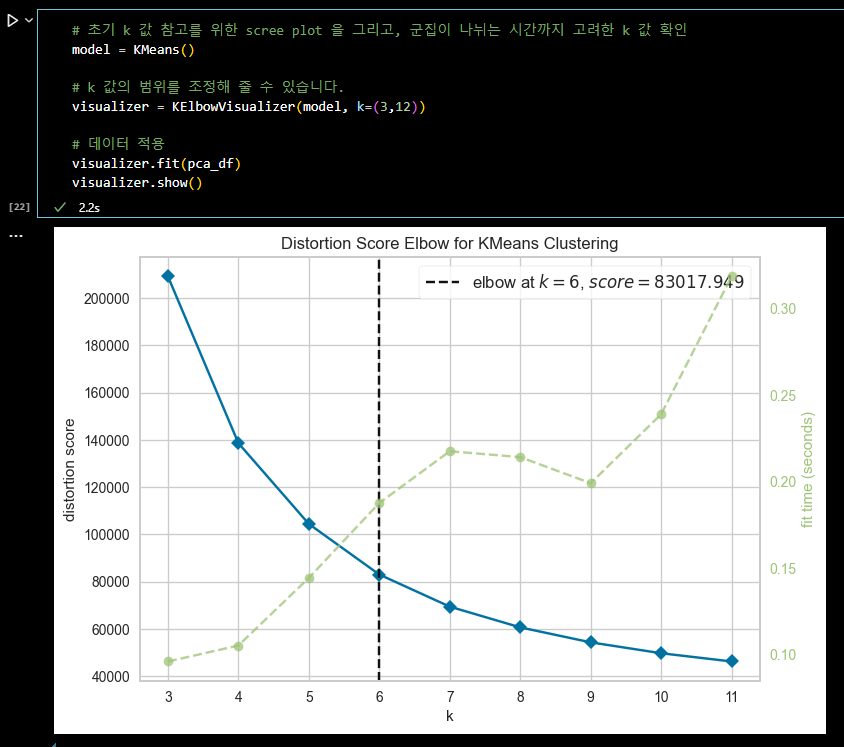
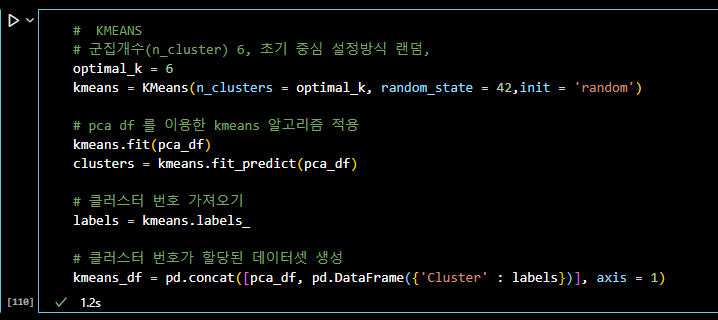
# KMEANS # 군집개수(n_cluster) 6, 초기 중심 설정방식 랜덤, optimal_k = 6 kmeans = KMeans(n_clusters = optimal_k, random_state = 42,init = 'random') # pca df 를 이용한 kmeans 알고리즘 적용 kmeans.fit(pca_df) clusters = kmeans.fit_predict(pca_df) # 클러스터 번호 가져오기 labels = kmeans.labels_ # 클러스터 번호가 할당된 데이터셋 생성 kmeans_df = pd.concat([pca_df, pd.DataFrame({'Cluster' : labels})], axis = 1)
# 2차원으로 시각화 plt.figure(figsize=(8, 8)) sns.scatterplot(data = kmeans_df, x = 'PC1', y='PC2', hue='Cluster') plt.title('The Plot Of The Clusters(2D)') plt.show()
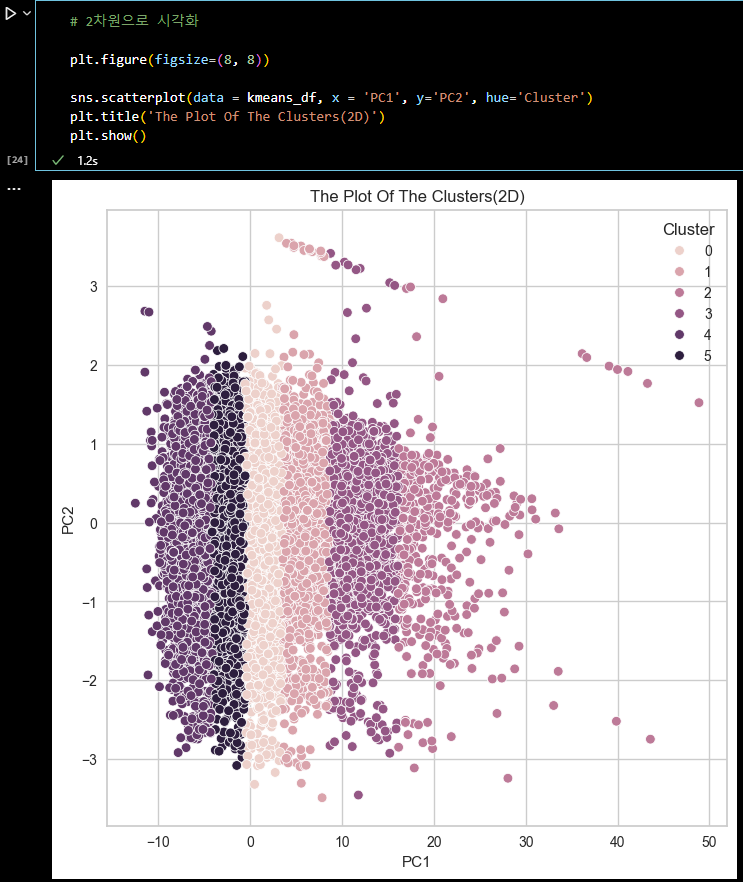
# 2차원으로 시각화 plt.figure(figsize=(8, 8)) sns.scatterplot(data = kmeans_df, x = 'PC1', y='PC3', hue='Cluster') plt.title('The Plot Of The Clusters(2D)') plt.show()
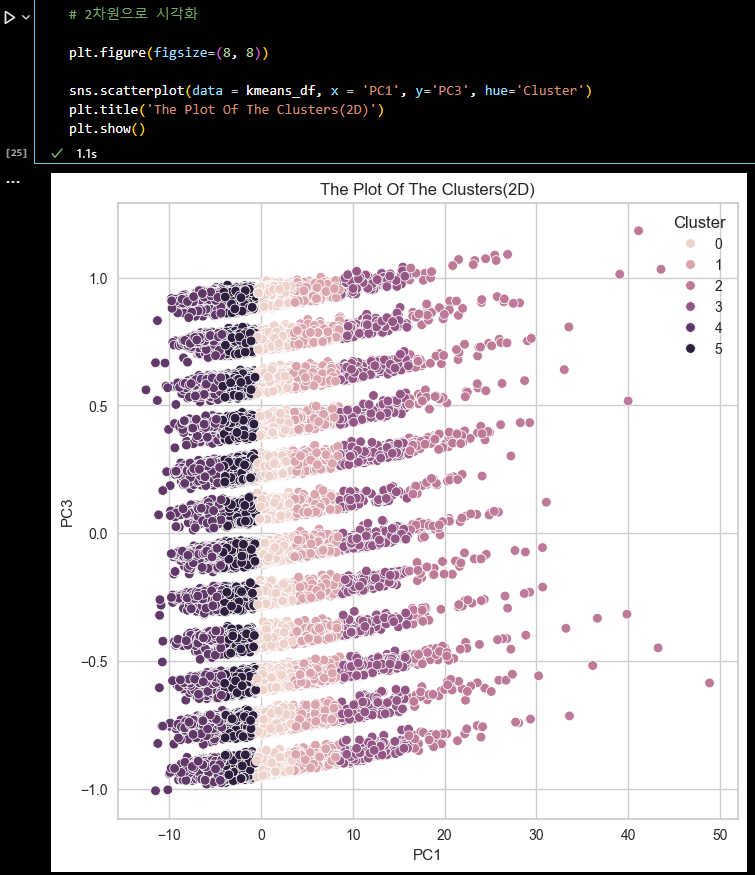
# 2차원으로 시각화 plt.figure(figsize=(8, 8)) sns.scatterplot(data = kmeans_df, x = 'PC2', y='PC3', hue='Cluster') plt.title('The Plot Of The Clusters(2D)') plt.show()
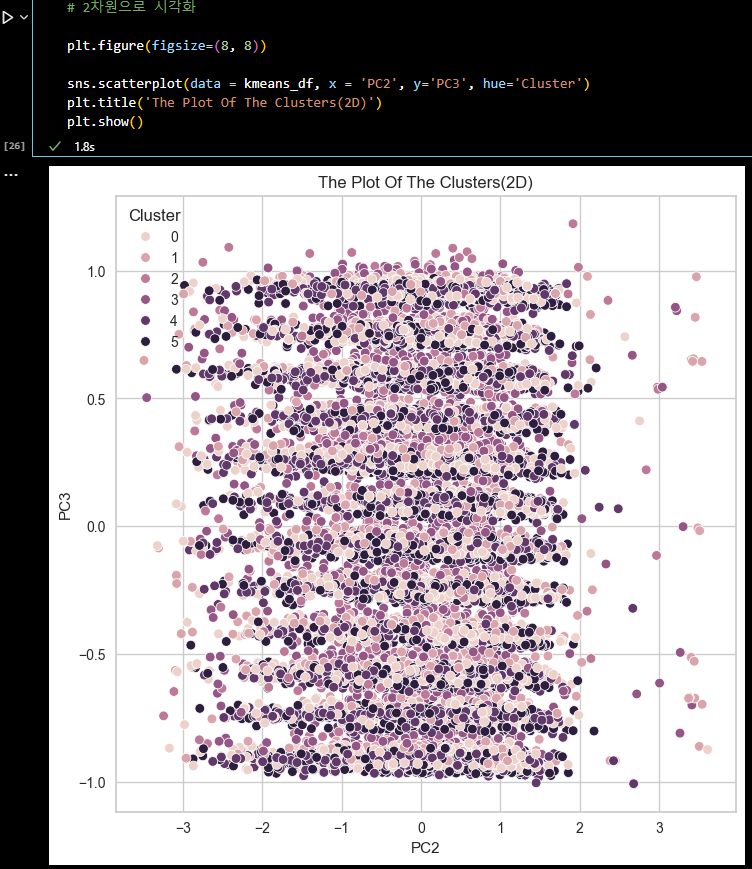
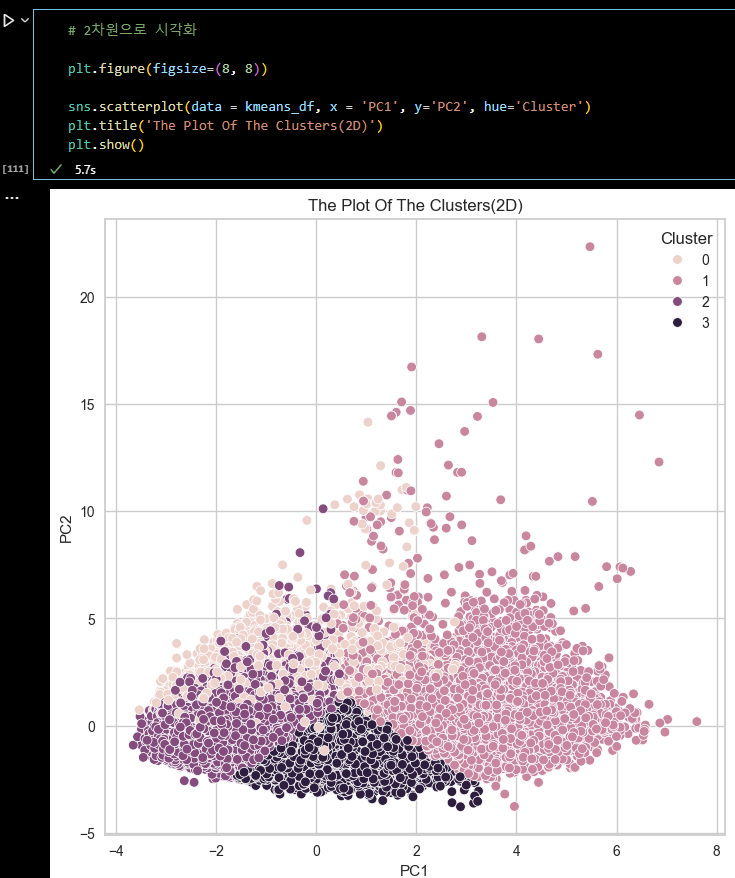
from sklearn.metrics import silhouette_score, silhouette_samples # 실루엣 계수 계산 silhouette_avg = silhouette_score(df_scaled, clusters) silhouette_values = silhouette_samples(df_scaled, clusters) silhouette_avg
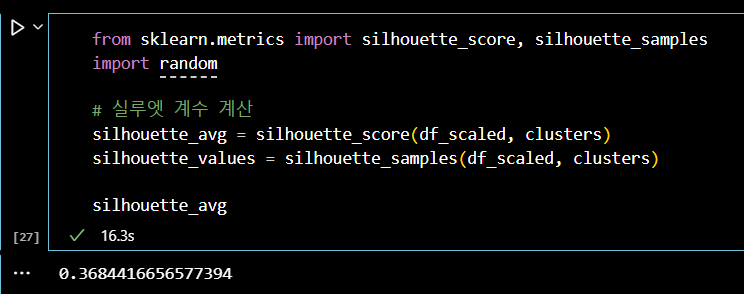
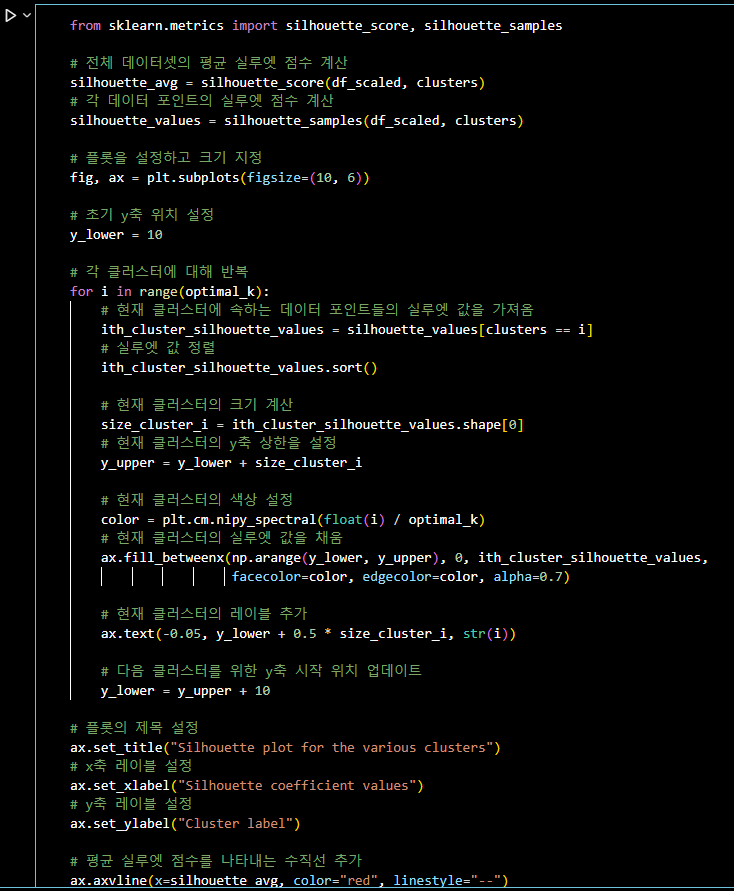
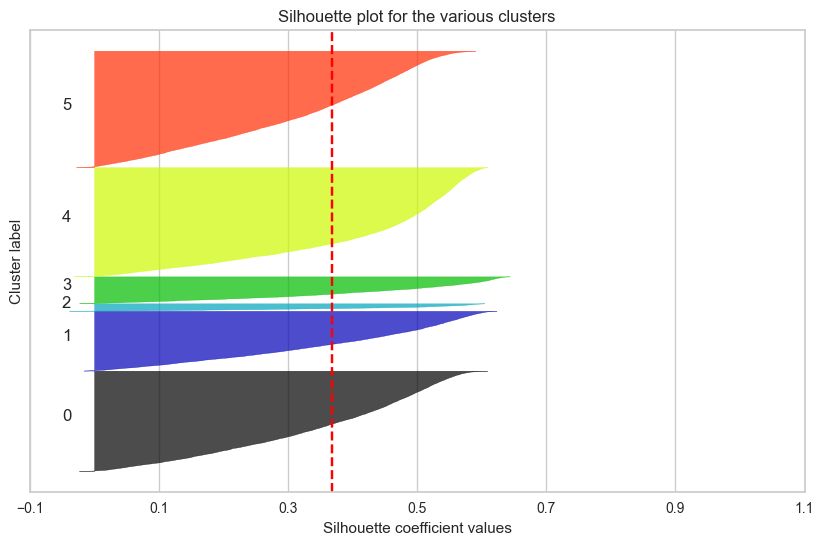
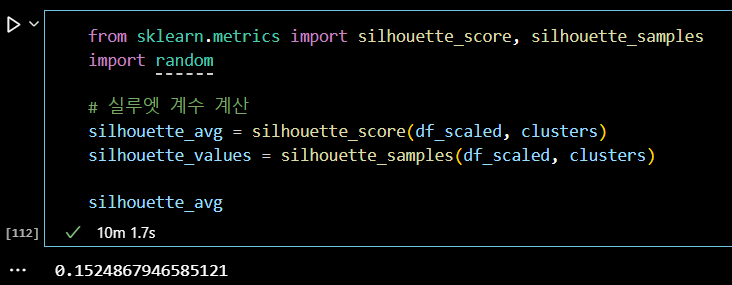
from sklearn.metrics import silhouette_score, silhouette_samples # 전체 데이터셋의 평균 실루엣 점수 계산 silhouette_avg = silhouette_score(df_scaled, clusters) # 각 데이터 포인트의 실루엣 점수 계산 silhouette_values = silhouette_samples(df_scaled, clusters) # 플롯을 설정하고 크기 지정 fig, ax = plt.subplots(figsize=(10, 6)) # 초기 y축 위치 설정 y_lower = 10 # 각 클러스터에 대해 반복 for i in range(optimal_k): # 현재 클러스터에 속하는 데이터 포인트들의 실루엣 값을 가져옴 ith_cluster_silhouette_values = silhouette_values[clusters == i] # 실루엣 값 정렬 ith_cluster_silhouette_values.sort() # 현재 클러스터의 크기 계산 size_cluster_i = ith_cluster_silhouette_values.shape[0] # 현재 클러스터의 y축 상한을 설정 y_upper = y_lower + size_cluster_i # 현재 클러스터의 색상 설정 color = plt.cm.nipy_spectral(float(i) / optimal_k) # 현재 클러스터의 실루엣 값을 채움 ax.fill_betweenx(np.arange(y_lower, y_upper), 0, ith_cluster_silhouette_values, facecolor=color, edgecolor=color, alpha=0.7) # 현재 클러스터의 레이블 추가 ax.text(-0.05, y_lower + 0.5 * size_cluster_i, str(i)) # 다음 클러스터를 위한 y축 시작 위치 업데이트 y_lower = y_upper + 10 # 플롯의 제목 설정 ax.set_title("Silhouette plot for the various clusters") # x축 레이블 설정 ax.set_xlabel("Silhouette coefficient values") # y축 레이블 설정 ax.set_ylabel("Cluster label") # 평균 실루엣 점수를 나타내는 수직선 추가 ax.axvline(x=silhouette_avg, color="red", linestyle="--") # y축의 티크 제거 ax.set_yticks([]) # x축의 티크 설정 ax.set_xticks(np.arange(-0.1, 1.1, 0.2)) plt.show()
- 수치형 데이터들을 스탠다드(STANDARD SCALER) 스케일링 후
K-MEANS 알고리즘으로 군집화 및 평가
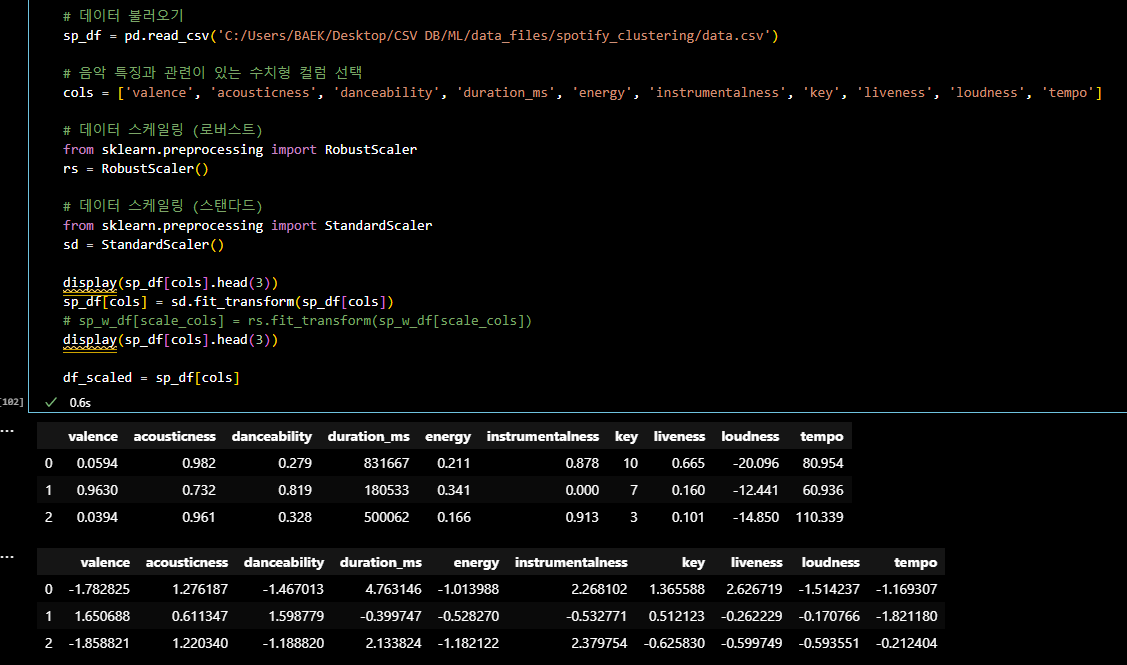
# 기본 라이브러리 import import pandas as pd import numpy as np # 시각화 라이브러리 import import seaborn as sns import matplotlib.pyplot as plt # 표준화 라이브러리 import from sklearn.preprocessing import StandardScaler # k 값 참고: scree plot을 통한 k 값 확인을 위한 라이브러리 import from yellowbrick.cluster import KElbowVisualizer # k 값 참고: distance map 라이브러리 import from yellowbrick.cluster import intercluster_distance from sklearn.cluster import MiniBatchKMeans # k 값 참고: 실루엣 계수 확인을 위한 라이브러리 import from sklearn.metrics import silhouette_score # 데이터셋 주성분 분석중 하나인 pca 를 수행하기 위한 라이브러리 import from sklearn.decomposition import PCA # k-means 알고리즘 활용을 위한 라이브러리 import from sklearn.cluster import KMeans import warnings warnings.filterwarnings('ignore') # 데이터 불러오기 sp_df = pd.read_csv('C:/Users/BAEK/Desktop/CSV DB/ML/data_files/spotify_clustering/data.csv') # 음악 특징과 관련이 있는 수치형 컬럼 선택 cols = ['valence', 'acousticness', 'danceability', 'duration_ms', 'energy', 'instrumentalness', 'key', 'liveness', 'loudness', 'tempo'] rs = RobustScaler() # 데이터 스케일링 (스탠다드) from sklearn.preprocessing import StandardScaler sd = StandardScaler() display(sp_df[cols].head(3)) sp_df[cols] = sd.fit_transform(sp_df[cols]) # sp_w_df[scale_cols] = rs.fit_transform(sp_w_df[scale_cols]) display(sp_df[cols].head(3)) df_scaled = sp_df[cols]
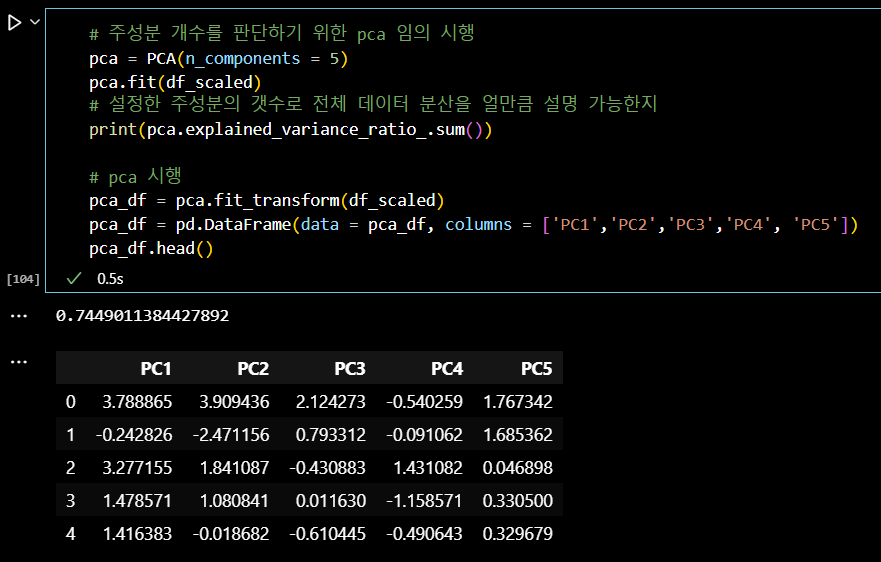
# 주성분 개수를 판단하기 위한 pca 임의 시행 pca = PCA(n_components = 5) pca.fit(df_scaled) # 설정한 주성분의 갯수로 전체 데이터 분산을 얼만큼 설명 가능한지 print(pca.explained_variance_ratio_.sum()) # pca 시행 pca_df = pca.fit_transform(df_scaled) pca_df = pd.DataFrame(data = pca_df, columns = ['PC1','PC2','PC3','PC4', 'PC5']) pca_df.head()
# 초기 k 값 참고를 위한 scree plot 을 그리고, 군집이 나뉘는 시간까지 고려한 k 값 확인 model = KMeans() # k 값의 범위를 조정해 줄 수 있습니다. visualizer = KElbowVisualizer(model, k=(3,12)) # 데이터 적용 visualizer.fit(pca_df) visualizer.show()
# KMEANS # 군집개수(n_cluster) 6, 초기 중심 설정방식 랜덤, optimal_k = 6 kmeans = KMeans(n_clusters = optimal_k, random_state = 42,init = 'random') # pca df 를 이용한 kmeans 알고리즘 적용 kmeans.fit(pca_df) clusters = kmeans.fit_predict(pca_df) # 클러스터 번호 가져오기 labels = kmeans.labels_ # 클러스터 번호가 할당된 데이터셋 생성 kmeans_df = pd.concat([pca_df, pd.DataFrame({'Cluster' : labels})], axis = 1)
# 2차원으로 시각화 plt.figure(figsize=(8, 8)) sns.scatterplot(data = kmeans_df, x = 'PC1', y='PC2', hue='Cluster') plt.title('The Plot Of The Clusters(2D)') plt.show()
from sklearn.metrics import silhouette_score, silhouette_samples # 실루엣 계수 계산 silhouette_avg = silhouette_score(df_scaled, clusters) silhouette_values = silhouette_samples(df_scaled, clusters) silhouette_avg
from sklearn.metrics import silhouette_score, silhouette_samples import random # 실루엣 계수 계산 silhouette_avg = silhouette_score(df_scaled, clusters) silhouette_values = silhouette_samples(df_scaled, clusters) # 클러스터별 실루엣 플롯 생성 fig, ax = plt.subplots(figsize=(10, 6)) y_lower = 10 for i in range(optimal_k): ith_cluster_silhouette_values = silhouette_values[clusters == i] ith_cluster_silhouette_values.sort() size_cluster_i = ith_cluster_silhouette_values.shape[0] y_upper = y_lower + size_cluster_i color = plt.cm.nipy_spectral(float(i) / optimal_k) ax.fill_betweenx(np.arange(y_lower, y_upper), 0, ith_cluster_silhouette_values, facecolor=color, edgecolor=color, alpha=0.7) ax.text(-0.05, y_lower + 0.5 * size_cluster_i, str(i)) y_lower = y_upper + 10 ax.set_title("Silhouette plot for the various clusters") ax.set_xlabel("Silhouette coefficient values") ax.set_ylabel("Cluster label") ax.axvline(x=silhouette_avg, color="red", linestyle="--") ax.set_yticks([]) ax.set_xticks(np.arange(-0.1, 1.1, 0.2)) plt.show()
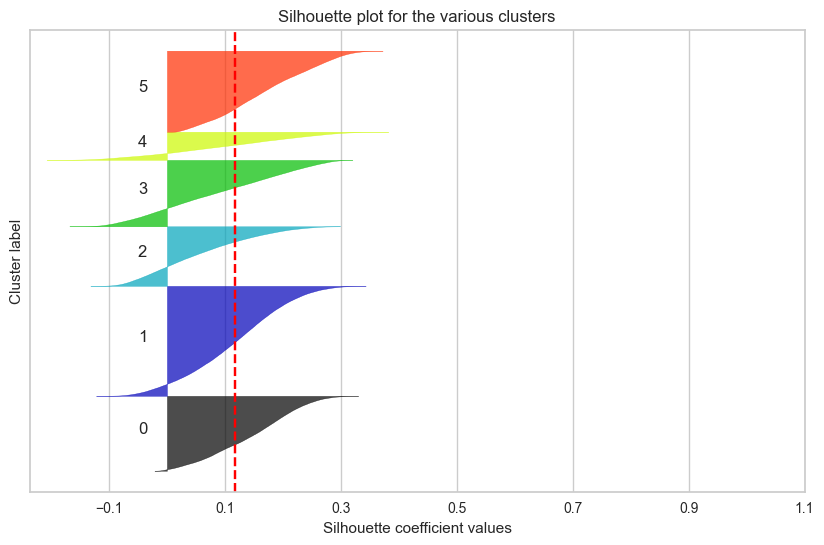
📌 3일차 스크럼 정리
17만 개의 데이터셋으로 군집화하는 것까지는 크게 어려움이 없었으나,
그 군집화의 결과를 평가하기 위해 진행하는 실루엣 계수 계산에
많은 시간이 소요되었다.
결국 실루엣 계수가 높고 군집화가 잘 되었다고 평가할 수 있는 모델을
만들어내지 못했다.
방향성을 찾기 위해 튜터님께 질문,
군집화에 영향을 주는 주성분의 갯수와 K 값을 바꿔가면서
그 실루엣 계수들을 시각화하고 비교하면서 제일 군집화가 잘된
(실루엣 계수의 면적이 넓고 비슷하며, 평균값이 높은)
모델을 찾을 때까지 군집분석을 시도해야 한다. 는 결론을 내렸다.-
팀 회의 결과 :
-
튜터님께 조언 받은 내용 중 전처리(표준화)는 StandardScaler 로 통일하기.
-
주성분 분석과 K 값을 자유롭게 변화해보며 K-means 분석을 진행하기.
-
주성분과 K값의 변화마다 실루엣 계수 계산하고 시각화하여 기록하기.
실루엣 계수의 면적이 넓고 균등하며, 평균값이 가장 높은 모델 선택하기.
-
-
내일까지 해야할 내용 :
-
주성분 : 3 ~ 5개 (설명력 65% ~ 85% 사이)
-
K 값 : 3 ~ 6개 (군집화 갯수)
목표 : 실루엣 계수 0.5 이상, 면적이 넓고 균등한 모델 찾기
-
📌 4일차
📌 군집 분석 시도
- 목표 : 17만 개 데이터셋으로 군집 분석 후 군집 결과가 좋은 모델 찾기
군집 분석에 대한 코드와 방법은 어느정도 정리가 된 것 같다.
하지만 17만 개 데이터셋으로 실루엣 계수가 높은 군집을 찾아내는 것..
반복적인 시도에도 원하는 결과를 얻어낼 수 없었다.
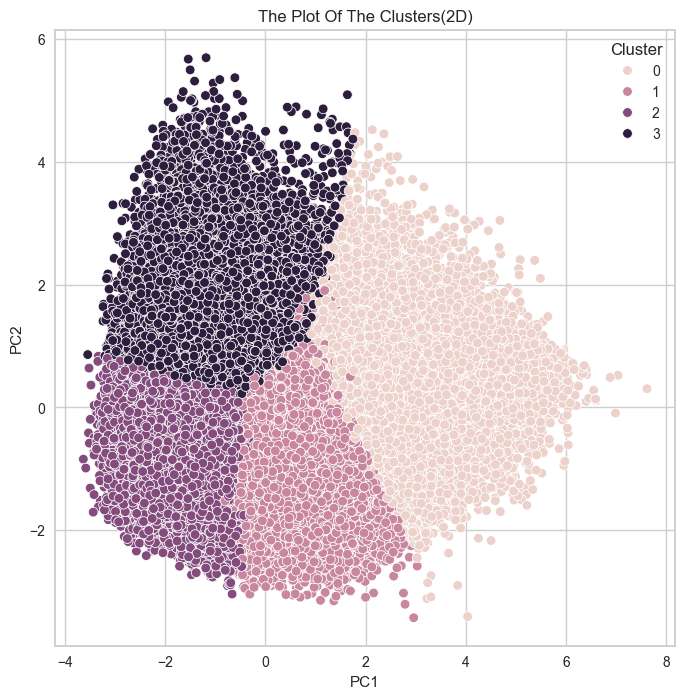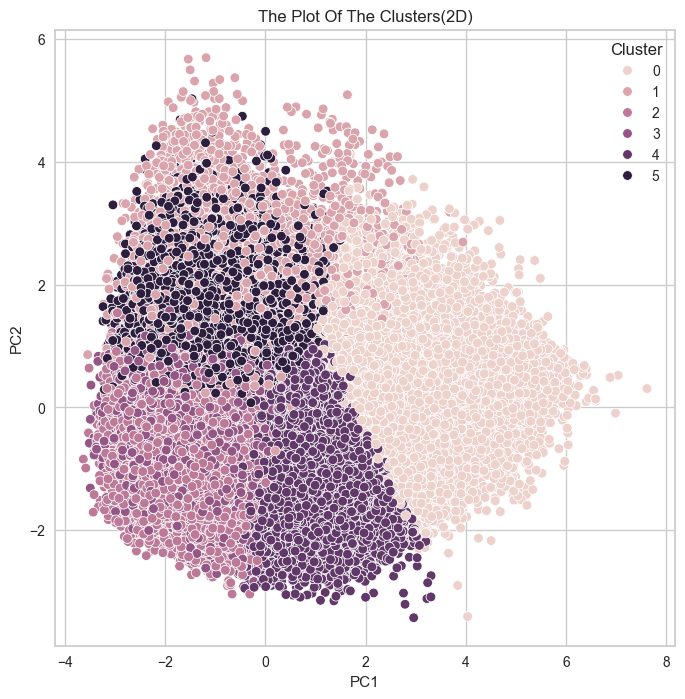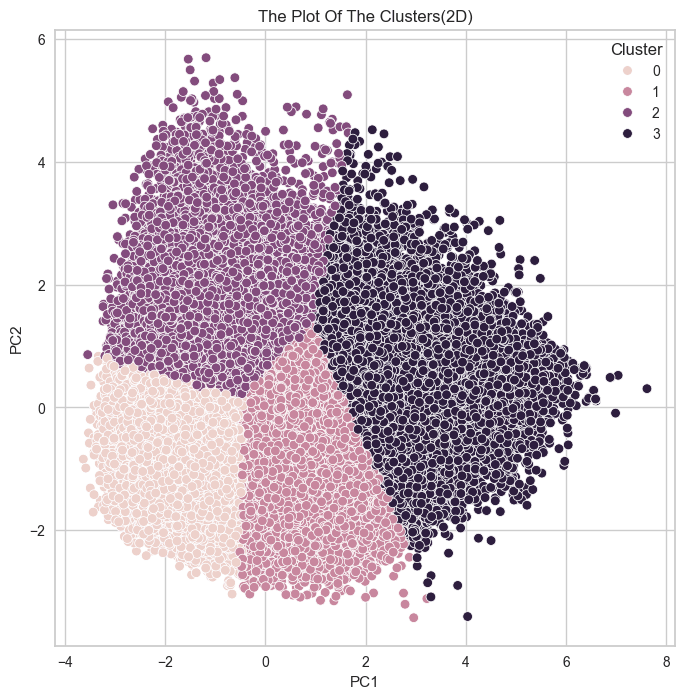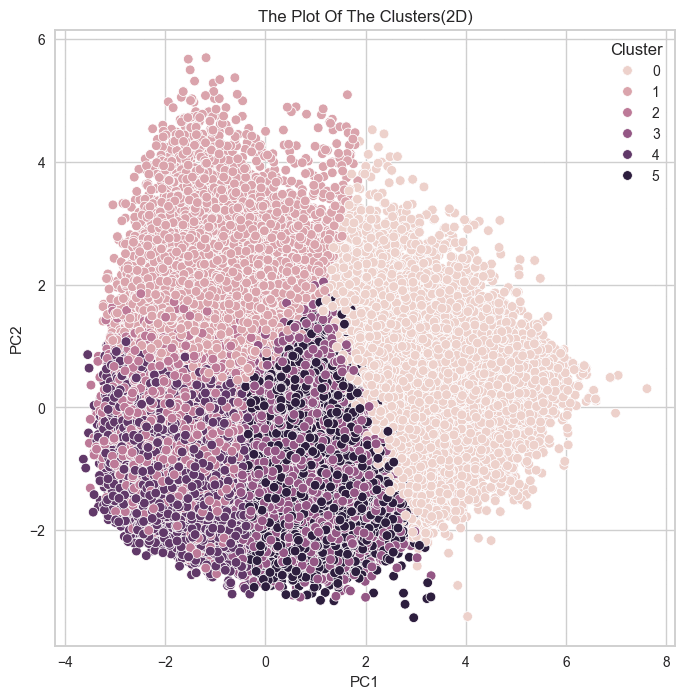
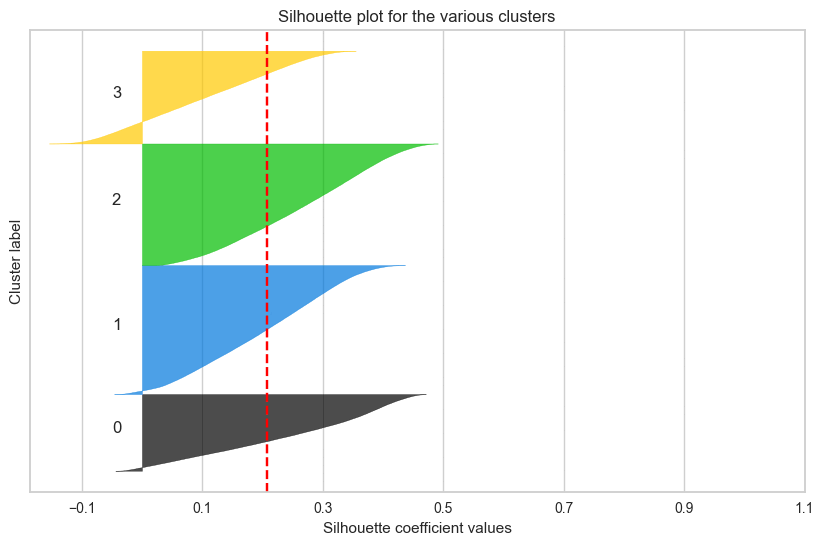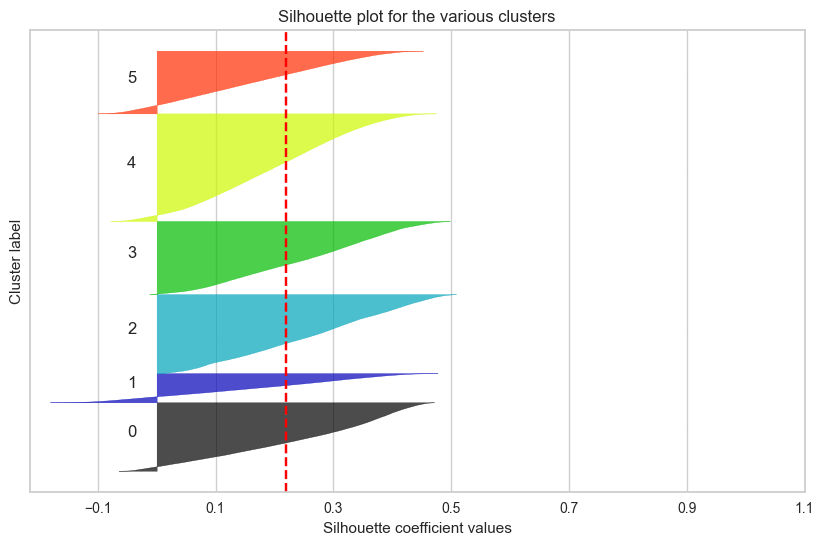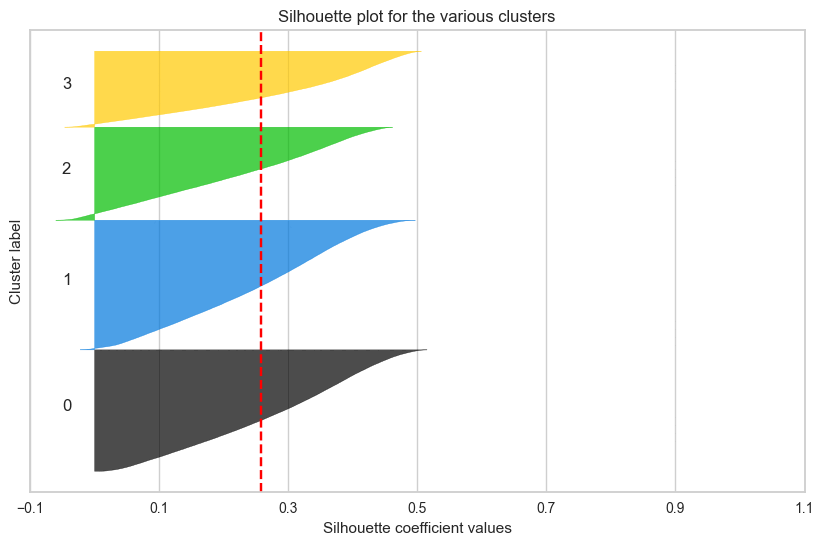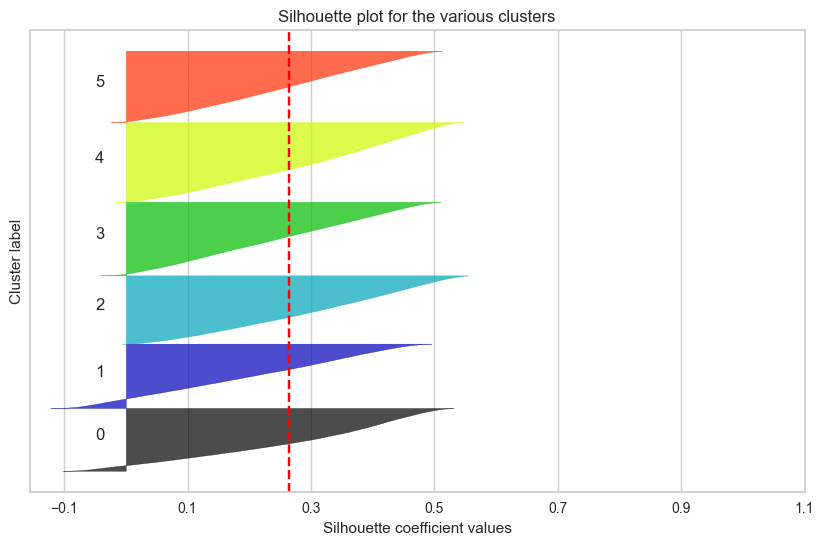
군집 결과를 실루엣 계수로만 확인했던 것이 옳은 방향이 아니었다는 것을 깨닳았다.
정리하자면, 우리가 지금 하려고 하는 군집 분석의 목적은
음원들을 우리가 알지 못하는 어떤 특성들끼리 묶이는 (군집 되는) 그룹들을 발견하고
그 군집들의 특성을 파악하여 서비스에 (추천 시스템) 적용하는 것인데,
실루엣 계수가 높다는 것은 각 데이터 간의 거리가 밀도있게 응집되어 있다는 뜻이고,
군집별로 실루엣 계수가 높아서 잘 뭉쳐져 있다면,
음악이라는 특성상 같은 노래? 같은 느낌? 을 나타내는 음악이 될 것이고,
추천 서비스에서 추천을 받는 고객 입장에서 비슷한 음악 추천을 받는 것이
어떤 의미인지에 대해 다시 고민해볼 필요가 있다는 것이었다.
(비슷하지만 새로운 음악을 추천 받고 싶지 않을까?)
따라서 단순히 실루엣 계수가 높은 군집을 찾기보다는
음악의 특성을 잘 나타낼 수 있는 변수들을 잘 선택하고,
그 변수들을 최대한 효율적으로 전처리, 군집화하여
그 군집들의 특성을 정성적으로 평가하는 것이 중요할 것이다. 라는 결론.📌 4일차 스크럼 정리
튜터님의 튜터링 후 방향성을 다시 잡았다.
서비스에 필요한 군집이 무엇인지 다시 고민,
음악의 특성을 나타내는 변수(컬럼)들을 추가하고 제거해보면서,
이상치 제거, 표준화 등의 전처리를 수행하고,
PCA 분석을 통한 차원 축소로 효율을 높이고,
K-means, 계층 군집, GWMM(가우시안혼합모델), DBSCAN 등의 군집 알고리즘을 활용해서
최대한 잘 군집화가 된 군집을 찾아낸 후,
군집 간의 특성을 확인 !
(군집 간의 특성을 정성적으로 평가하면서, 음악을 잘 묶어낼 수 있는지를 확인)
- 내일까지 해야할 내용 :
군집화 시도, 군집 간 특성 확인, 유의미한 군집 찾아내기
📌 5일차
📌 결과 정리
- 목표 : 여러 군집 분석 방법을 적용하고 최적의 군집 선택하기
여러 변수들의 추가, 삭제 / 주성분 갯수 조절 / K 값 조절 등
한 데이터로 전처리 ~ 군집 분석까지 해볼 수 있는 것은 거의 다 해본 것 같다..
무언가 이미 전처리가 되어 있는 듯한 (0~1값을 가진) 데이터의 특성과
표준화만 진행하고 군집화를 하는 것으로는
군집 성능 (실루엣 계수)을 높이는 데 한계가 있다고 판단했다.
- 사용 컬럼 :
cols = ['valence', 'acousticness', 'danceability',
'energy', 'instrumentalness', 'key', 'liveness',
'loudness', 'tempo', 'mode']
- 제거 컬럼 :
1. year (발매 연도)
음악의 발매 연도는 군집분석에서 음악의 특성보다는 시간적 흐름을 반영하는 변수
군집을 형성할 때 음악의 내용보다는 시대적 배경에 따라 군집이 형성될 수 있어,
음원 자체의 특성을 파악하는 데 적합하지 않을 것으로 판단.
2. artists (아티스트 리스트)
아티스트의 이름은 범주형 데이터로, 군집분석의 수치적 분석에 적합하지 않음.
아티스트마다 다양한 스타일이 존재하므로,
개별 아티스트의 특성을 모두 반영하기 어려울 것으로 판단.
3. explicit (음원에 부적절한 내용 여부)
explicit 변수는 0 또는 1의 이진 변수로,
음악의 특성보다는 가사의 내용에 집중된 변수로 판단.
4. id (고유 식별자)
id는 각 음원의 고유 식별자이므로,
군집분석에 의미 있는 정보를 제공하지 않을 것으로 판단.
5. release_date (발매일)
release_date는 year와 유사하게 시간적 흐름을 반영하는 변수로,
음악의 특성보다는 발매 시점에 중점을 둠.
군집분석에서 음원의 내용보다는 시대적 배경에
영향을 미칠 수 있을 것으로 판단.
6. popularity (인기도)
Popularity 는 트랙의 인기도를 나타내는 변수로,
음악의 특성보다는 시간적 흐름을 반영하는 변수
주로 외부 요인에 의해 결정, 특정 시기에 바이럴이 되거나,
유명 아티스트가 새로 발매한 음악이
순간적으로 높은 인기를 얻을 수 있을 것으로 판단.
7. speechiness (말의 비율)
speechiness 는 랩, 스포큰 워드 등의
특정 장르의 중요한 정보가 될 수 는 있지만,
음악의 특성을 반영하는 데 있어서는 제한적일 것으로 판단.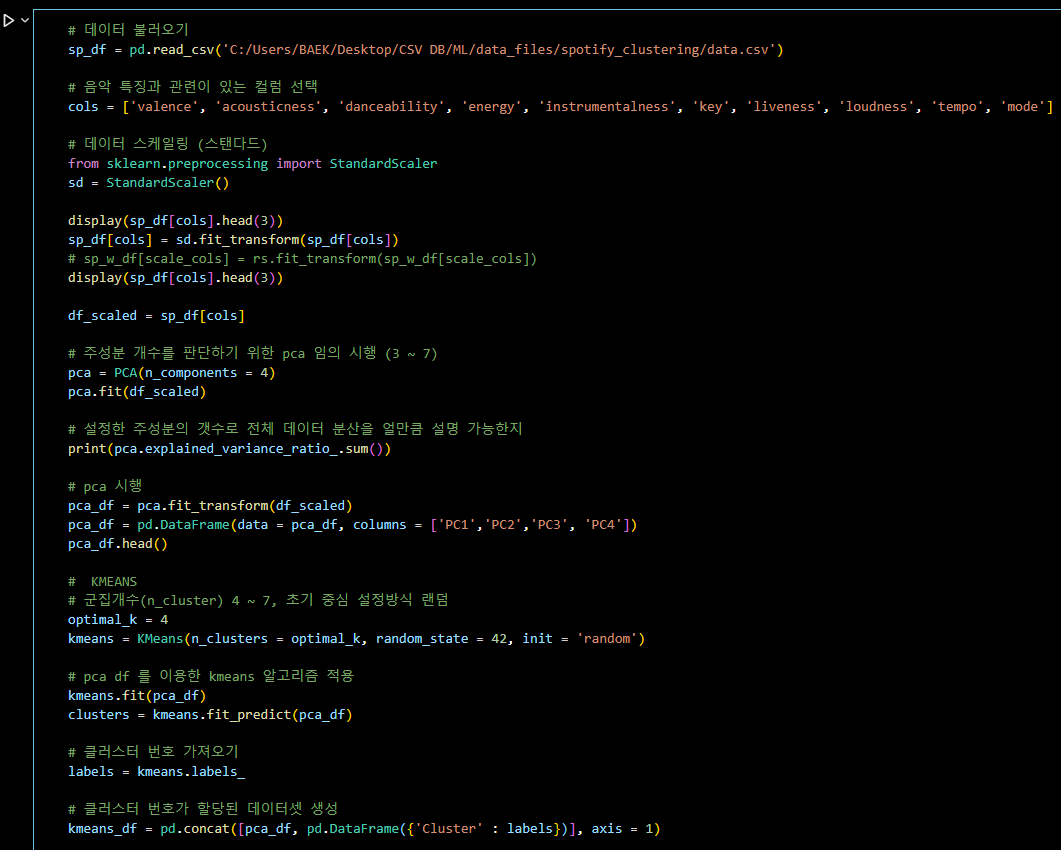
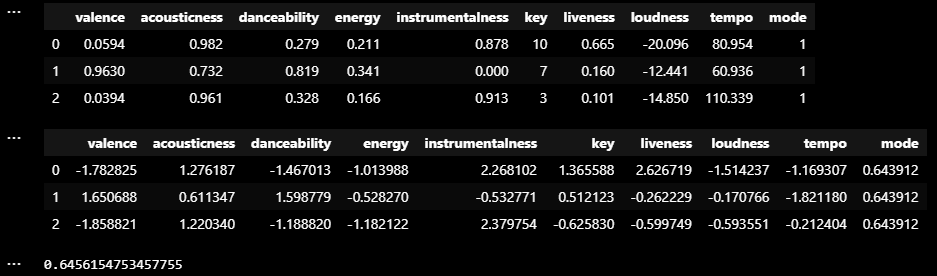
# 데이터 불러오기
sp_df = pd.read_csv('C:/Users/BAEK/Desktop/CSV DB/ML/data_files/spotify_clustering/data.csv')
# 음악 특징과 관련이 있는 컬럼 선택
cols = ['valence', 'acousticness', 'danceability', 'energy', 'instrumentalness', 'key', 'liveness', 'loudness', 'tempo', 'mode']
# 데이터 스케일링 (스탠다드)
from sklearn.preprocessing import StandardScaler
sd = StandardScaler()
display(sp_df[cols].head(3))
sp_df[cols] = sd.fit_transform(sp_df[cols])
# sp_w_df[scale_cols] = rs.fit_transform(sp_w_df[scale_cols])
display(sp_df[cols].head(3))
df_scaled = sp_df[cols]
# 주성분 개수를 판단하기 위한 pca 임의 시행 (3 ~ 7)
pca = PCA(n_components = 4)
pca.fit(df_scaled)
# 설정한 주성분의 갯수로 전체 데이터 분산을 얼만큼 설명 가능한지
print(pca.explained_variance_ratio_.sum())
# pca 시행
pca_df = pca.fit_transform(df_scaled)
pca_df = pd.DataFrame(data = pca_df, columns = ['PC1','PC2','PC3', 'PC4'])
pca_df.head()
# KMEANS
# 군집개수(n_cluster) 4 ~ 7, 초기 중심 설정방식 랜덤
optimal_k = 4
kmeans = KMeans(n_clusters = optimal_k, random_state = 42, init = 'random')
# pca df 를 이용한 kmeans 알고리즘 적용
kmeans.fit(pca_df)
clusters = kmeans.fit_predict(pca_df)
# 클러스터 번호 가져오기
labels = kmeans.labels_
# 클러스터 번호가 할당된 데이터셋 생성
kmeans_df = pd.concat([pca_df, pd.DataFrame({'Cluster' : labels})], axis = 1)
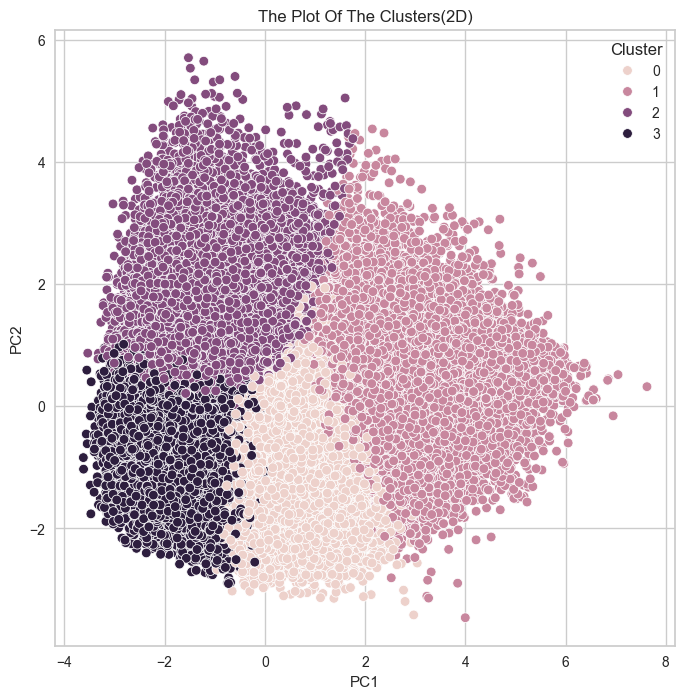
# 2차원으로 시각화
plt.figure(figsize=(8, 8))
sns.scatterplot(data = kmeans_df, x = 'PC1', y='PC2', hue='Cluster')
plt.title('The Plot Of The Clusters(2D)')
plt.show()
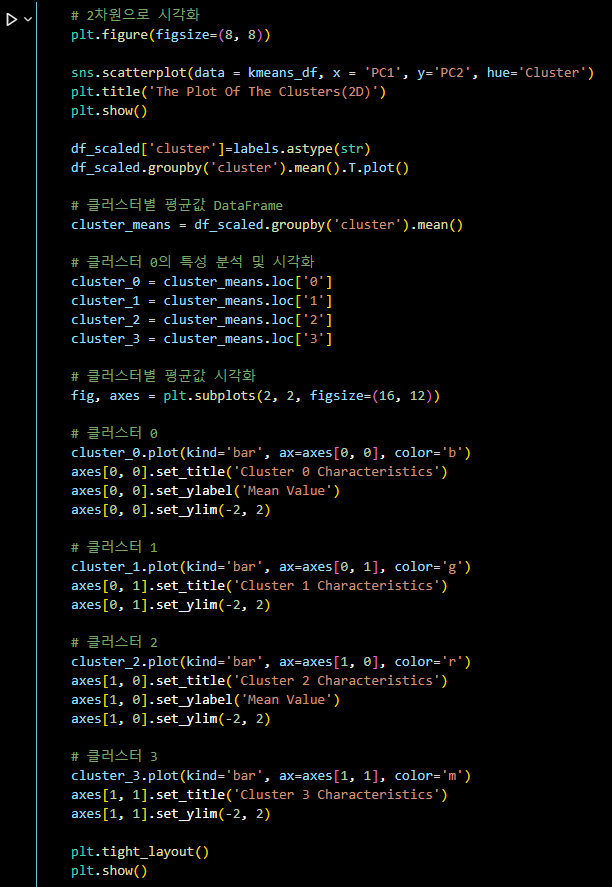
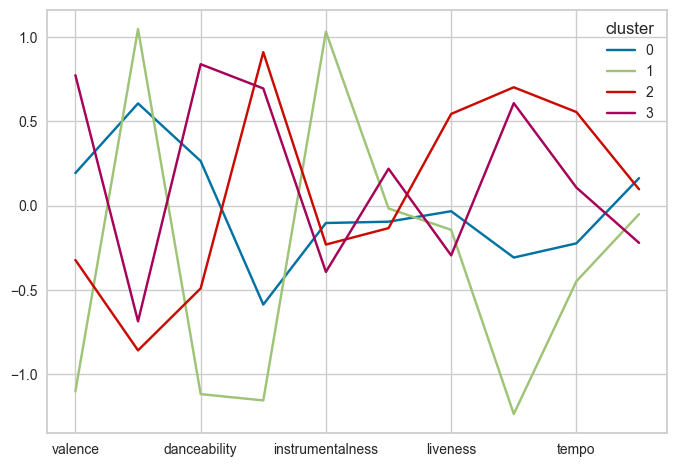
df_scaled['cluster']=labels.astype(str)
df_scaled.groupby('cluster').mean().T.plot()
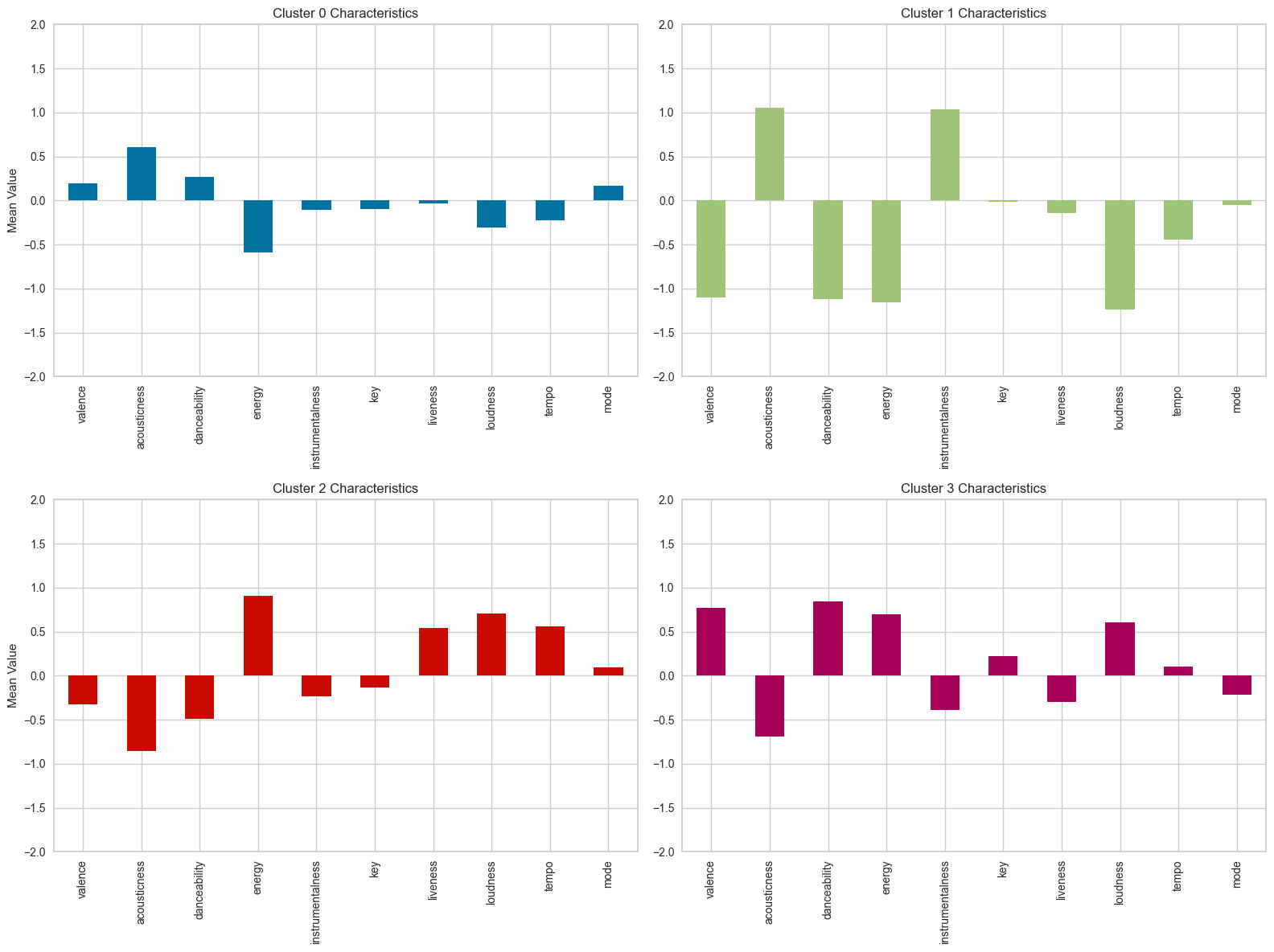
# 클러스터별 평균값 DataFrame
cluster_means = df_scaled.groupby('cluster').mean()
# 클러스터 0의 특성 분석 및 시각화
cluster_0 = cluster_means.loc['0']
cluster_1 = cluster_means.loc['1']
cluster_2 = cluster_means.loc['2']
cluster_3 = cluster_means.loc['3']
# 클러스터별 평균값 시각화
fig, axes = plt.subplots(2, 2, figsize=(16, 12))
# 클러스터 0
cluster_0.plot(kind='bar', ax=axes[0, 0], color='b')
axes[0, 0].set_title('Cluster 0 Characteristics')
axes[0, 0].set_ylabel('Mean Value')
axes[0, 0].set_ylim(-2, 2)
# 클러스터 1
cluster_1.plot(kind='bar', ax=axes[0, 1], color='g')
axes[0, 1].set_title('Cluster 1 Characteristics')
axes[0, 1].set_ylim(-2, 2)
# 클러스터 2
cluster_2.plot(kind='bar', ax=axes[1, 0], color='r')
axes[1, 0].set_title('Cluster 2 Characteristics')
axes[1, 0].set_ylabel('Mean Value')
axes[1, 0].set_ylim(-2, 2)
# 클러스터 3
cluster_3.plot(kind='bar', ax=axes[1, 1], color='m')
axes[1, 1].set_title('Cluster 3 Characteristics')
axes[1, 1].set_ylim(-2, 2)
plt.tight_layout()
plt.show()-
분석 플로우
-
변수 선정
-
전처리(Standard Scaling ; 표준화만 진행)
-
PCA 분석을 통한 차원 축소 (PCA = 4개 ; 설명력 0.65 %)
-
군집 갯수 설정 (4개)
-
결국 군집 결과를 평가해야 한다.
데이터 전처리 과정에서 일부러 배제했던 과정이 이상치 제거였다.
이상치를 어떤 기준으로 판단하고 제거할 지에 대한 논리가 나 스스로 설득이 되지 않아서, 이상치 제거하는 것을 꺼려했던 것인데,
팀원 중 Isolation Forest 기법을 활용한 이상치 제거로 17만 개 데이터 중 4만 개 (약 25%) 의 이상치를 제거 후 군집을 시도한 결과가
군집 실루엣 계수도 높을 뿐더러 군집화가 잘 되어 보였다.
튜터님들께 튜터링을 받은 결과,
이상치 제거에 대한 과정에서 문제가 없다면, (이상치가 좀 많이 제거된 경향은 없지않지만)
이상치가 제거된 후의 군집 성능이 좋은 것이 활용하기에 더 좋을 것이다.
라는 결론을 내렸다.
따라서 우리는 이상치를 제거하고 표준화를 진행한 후,
군집이 잘 된 (실루엣 계수의 분포도 잘 이루어진) 군집을 활용해
군집별 특성을 파악하고 음원 추천 서비스에 적용하는 결론을 내릴 것이다.📌 5일차 스크럼 정리
변수 선택 - 이상치 제거 - 표준화 - 주성분 분석 - 군집화
가장 좋은 군집 시각화와 실루엣 계수, 분포를 보여주는 군집을 활용해
군집별 특성을 분석하고 음원 추천 서비스에 적용하는 방안 탐색하기 !
이제 보고서에 잘 녹이는 일만 남았다.
화이팅!
📌 6일차
📌 자료 제작 및 준비
- 최종 자료 제작 !
완성된 최종 자료는 발표 끝나고 정리 예정 !
짧다면 짧고 길다면 긴 일주일동안
막막한 마음으로 시작했던 프로젝트인데,
어렵고 해결이 안될 것 같던 문제와 고민들도
하나하나 차분하게 풀어가다보면 답이 있었고,
그 과정들이 모여서 어느샌가 성장해있는
나의 모습에 뿌듯함.
이번 프로젝트를 통해서
군집분석의 알고리즘 모델들을 한번씩 경험해볼 수 있었고,
데이터의 전처리와 다양한 군집 분석 기법을 적용하는 과정에서
데이터의 특성과 알고리즘의 선택이 결과에 미치는 영향을
깊이 이해할 수 있었다.📌 7일차
📌 프로젝트 발표
데이터 탐색 - 군집 시도 - 변수 선택 - 군집 시도 - 전처리 - 군집 시도 - 차원 축소 - 군집 시도 - 군집 모델 선택 - 군집 시도 - 실루엣 계수 계산 - 군집 시도 - 군집 시도 - 시도 .....
6일 동안 프로젝트를 진행하면서
코드 한 번 돌리는 데 2시간이 넘게 걸리는 경우도 있었고,
원인을 알 수 없는 에러 코드에 당황하고,
변수를 잘못 넣어 나온 잘못된 결과를 믿고 진행하고,
그걸 발견하면서 처음부터 다시 시도하는 과정..
말이나 글로 표현하지 못할 정도의 막막함, 뿌듯함, 지루함, 재미 등
여러 감정을 느낄 수 있었던 프로젝트였다 ! ㅋㅋㅋ