개요
심화 프로젝트
데이터 탐색 - 군집 시도 - 변수 선택 - 군집 시도 - 전처리 - 군집 시도 - 차원 축소 - 군집 시도 - 군집 모델 선택 - 군집 시도 - 실루엣 계수 계산 - 군집 시도 - 군집 시도 - 시도 .....
5일 동안 군집 분석을 진행하면서
코드 한 번 돌리는 데 2시간이 넘게 걸리는 경우도 있었고,
원인을 알 수 없는 에러 코드,
변수를 잘못 넣어 잘못된 결과를 믿고 진행한 경우,
그걸 발견하면서 처음부터 다시 시도하는 과정..
말이나 글로 표현하지 못할 정도의 막막함, 뿌듯함, 지루함, 재미 등
여러 감정을 느낄 수 있었던 프로젝트였다 ! ㅋㅋㅋ코드는 앞서 언급한 여러 시도들을 전부 정리하지는 않고,
최종적으로 분석에 사용한 코드만 정리했다.
📌 분석 환경 세팅
📌 라이브러리 불러오기
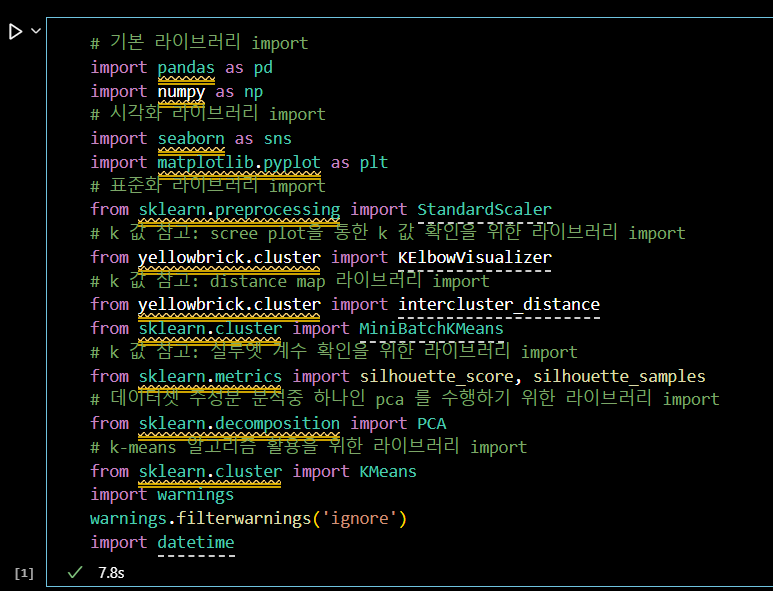
# 기본 라이브러리 import import pandas as pd import numpy as np # 시각화 라이브러리 import import seaborn as sns import matplotlib.pyplot as plt # 표준화 라이브러리 import from sklearn.preprocessing import StandardScaler # k 값 참고: scree plot을 통한 k 값 확인을 위한 라이브러리 import from yellowbrick.cluster import KElbowVisualizer # k 값 참고: distance map 라이브러리 import from yellowbrick.cluster import intercluster_distance from sklearn.cluster import MiniBatchKMeans # k 값 참고: 실루엣 계수 확인을 위한 라이브러리 import from sklearn.metrics import silhouette_score, silhouette_samples # 데이터셋 주성분 분석중 하나인 pca 를 수행하기 위한 라이브러리 import from sklearn.decomposition import PCA # k-means 알고리즘 활용을 위한 라이브러리 import from sklearn.cluster import KMeans import warnings warnings.filterwarnings('ignore') import datetime
-
기본 라이브러리
-
pandas- 데이터 조작 및 분석
- 데이터프레임 사용
- 데이터 읽기, 쓰기, 정리, 통계 분석
-
numpy- 고성능 수치 계산
- 다차원 배열 객체와 수학적 함수 제공
- 데이터 분석과 과학 계산 활용
-
-
시각화 라이브러리
-
seaborn- 통계적 데이터 시각화
- matplotlib 기반
- 데이터프레임과 통합 사용
-
matplotlib.pyplot- 데이터 시각화
- 선 그래프, 막대 그래프, 히스토그램 등 지원
-
-
표준화 라이브러리
sklearn.preprocessing.StandardScaler- 데이터 표준화
- 평균 0, 분산 1로 변환
-
k 값 참고 라이브러리
-
yellowbrick.cluster.KElbowVisualizer- 최적의 k 값 찾기 위한 시각화 도구
- Elbow Method 사용
-
yellowbrick.cluster.intercluster_distance- 클러스터 간 거리 시각화
-
sklearn.metrics.silhouette_score, silhouette_samples- 클러스터의 실루엣 계수 계산
- 군집 품질 평가
-
-
데이터셋 주성분 분석 라이브러리
sklearn.decomposition.PCA- 주성분 분석 수행
- 데이터 차원 축소
-
k-means 알고리즘 라이브러리
sklearn.cluster.KMeans, MiniBatchKMeans- K-means 클러스터링 알고리즘
- 데이터 군집화
-
기타
-
warnings- 경고 메시지 제어
-
datetime- 날짜 및 시간 데이터 처리
-
📌 데이터 불러오기
pd.read_csv('파일 경로')
- 파일 경로의 csv 파일 읽기

# 데이터 불러오기
sp_df = pd.read_csv('C:/Users/BAEK/Desktop/CSV DB/ML/data_files/spotify_clustering/data.csv')📌 EDA
📌 데이터 살펴보기
데이터프레임의 상위 5개 행 출력
- 데이터 구조 및 초기 값 확인
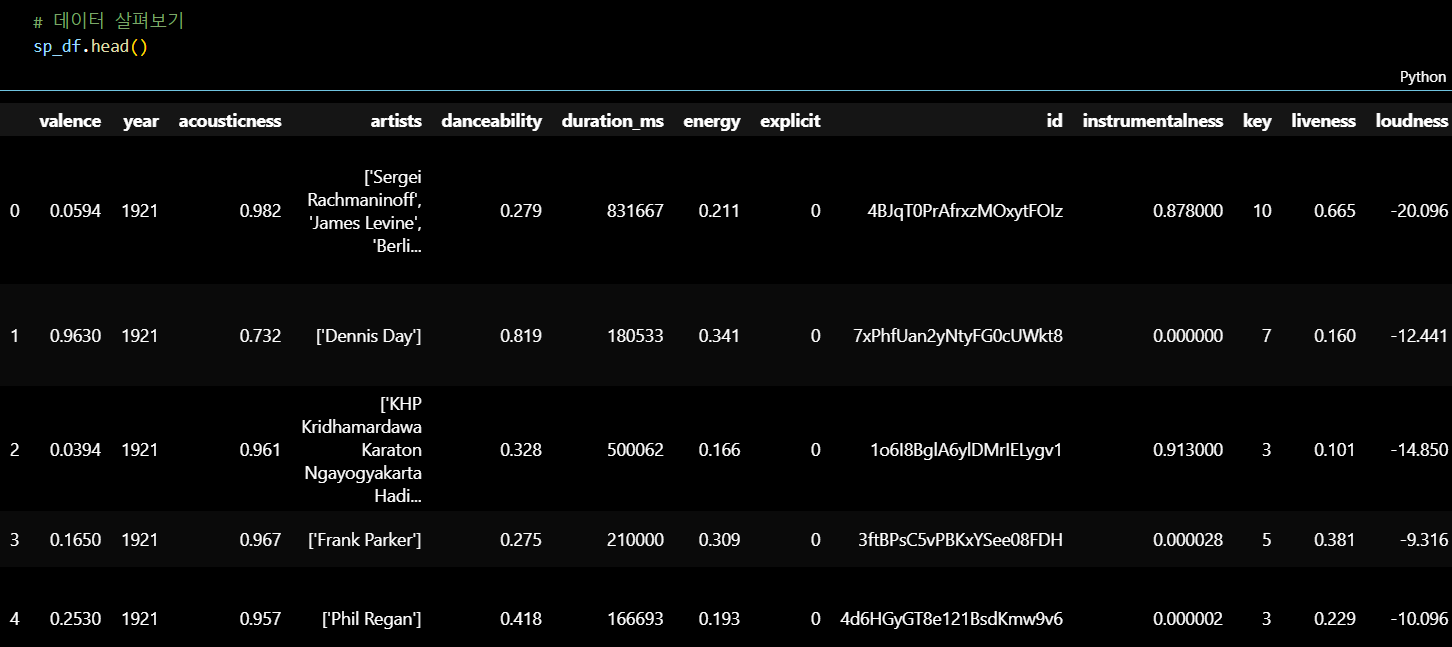
sp_df.head()결측치 확인
- 모든 열의 결측치 개수 출력
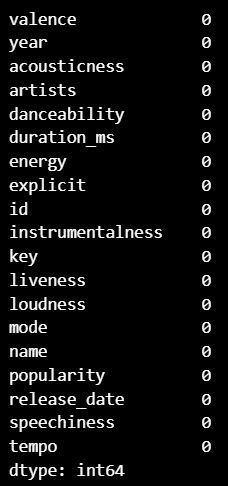
# 모든 데이터에 결측치 없음 !
print(sp_df.isnull().sum())데이터프레임의 정보 출력
- 각 열의 데이터 타입, 비어 있지 않은 값의 개수, 메모리 사용량 확인
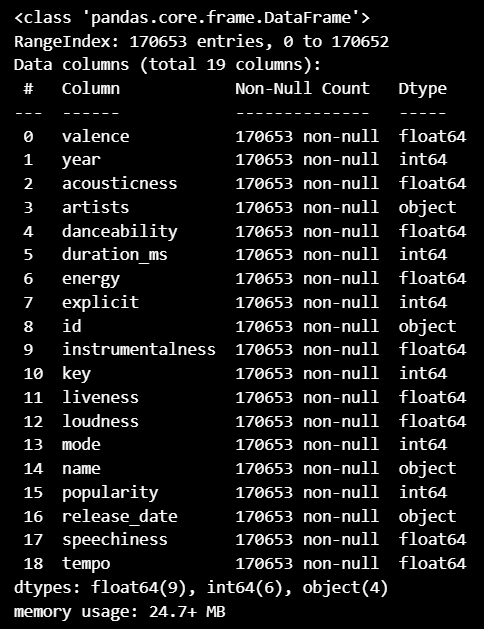
sp_df.info()데이터프레임의 통계 요약 출력
- 각 열의 요약 통계량(평균, 표준편차, 최소값, 최대값 등) 확인
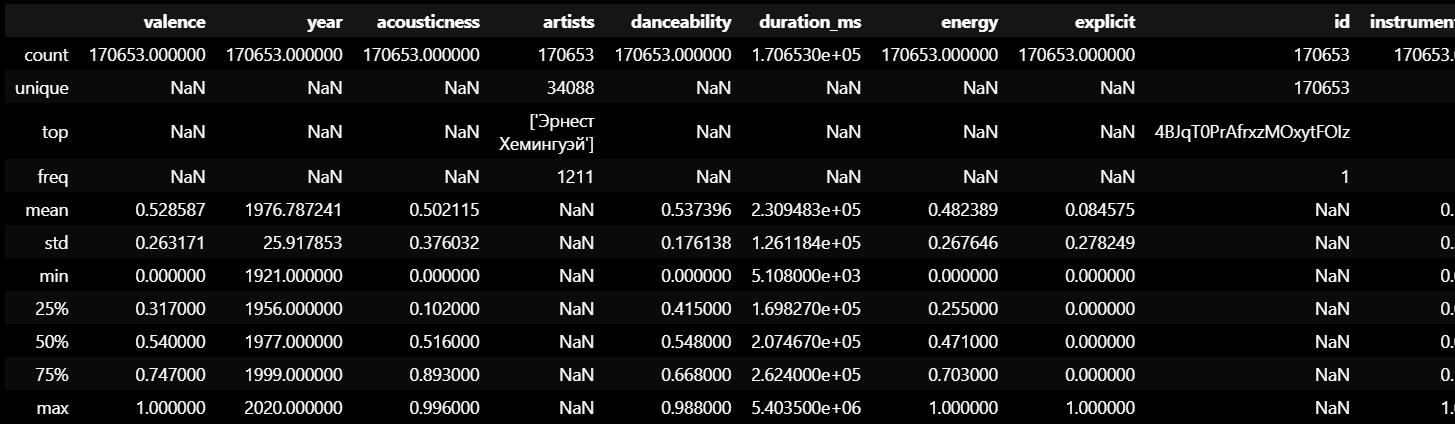
sp_df.describe(include = 'all')각 열의 히스토그램 생성
- 데이터의 분포와 빈도 확인
- 히스토그램의 빈 수 50 설정
- 그래프 크기 20x15 설정
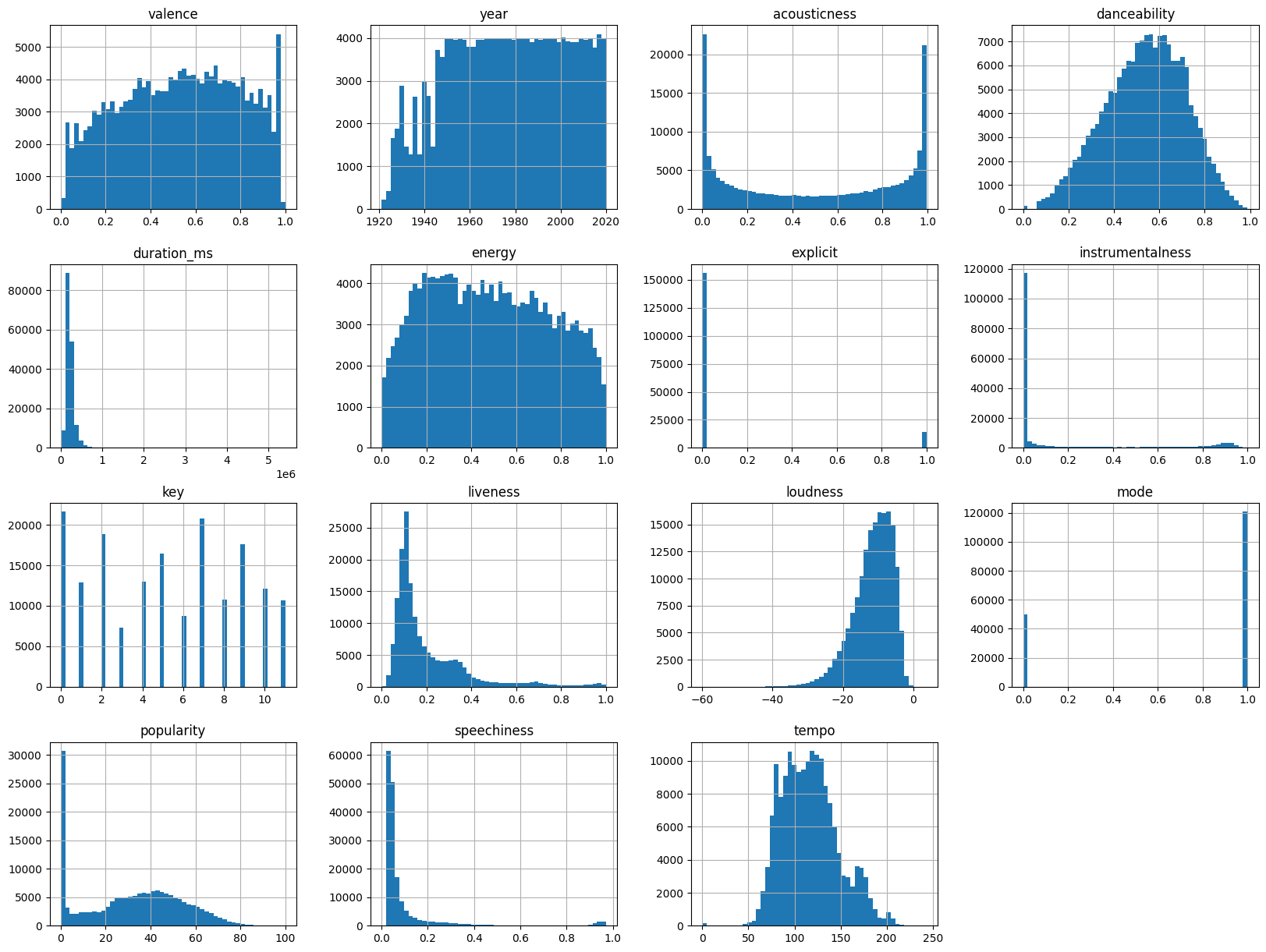
# 각 컬럼의 분포 확인
sp_df.hist(bins=50, figsize=(20, 15))
plt.show()칼럼(변수) 선택을 위해 여러 군집 시도와 평가를 진행..
▼ 최종 선택한 분석 단계
📌 데이터 전처리
📌 변수 선택
음악 특징과 관련된 군집에 활용할 열을 선택하여 리스트에 저장
# 음악 특징과 관련이 있는 컬럼 선택
cols=[
'valence', 'acousticness', 'danceability',
'duration_ms', 'energy', 'instrumentalness',
'liveness', 'loudness', 'speechiness', 'tempo'
]
sp_df_2 = sp_df[cols]
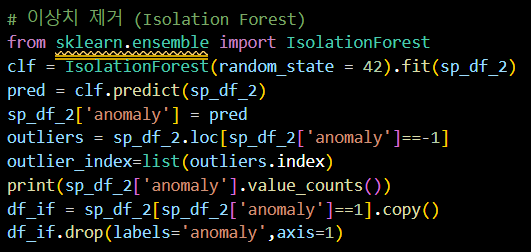
📌 이상치 제거
Isolation Forest를 사용하여 이상치 제거
- IsolationForest 모델을 생성 & 학습
- 예측 결과를 통해 이상치 여부 판단
- anomaly 열에 이상치 여부 저장
- 이상치인 행을 outliers 데이터프레임에 저장
- 이상치 인덱스를 outlier_index 리스트에 저장
- 이상치와 정상치의 개수를 출력
- 이상치가 제거된 데이터프레임 df_if 생성
- anomaly 열 제거
# 이상치 제거 (Isolation Forest)
from sklearn.ensemble import IsolationForest
# Isolation Forest 모델 생성 및 데이터로 학습
clf = IsolationForest(random_state=42).fit(sp_df_2)
# 예측 결과를 통해 이상치 여부 판단
pred = clf.predict(sp_df_2)
# anomaly 열에 이상치 여부 저장
sp_df_2['anomaly'] = pred
# 이상치인 행을 outliers 데이터프레임에 저장
outliers = sp_df_2.loc[sp_df_2['anomaly'] == -1]
# 이상치 인덱스를 outlier_index 리스트에 저장
outlier_index = list(outliers.index)
# 이상치와 정상치의 개수 출력
print(sp_df_2['anomaly'].value_counts())
# 이상치가 제거된 데이터프레임 df_if 생성
df_if = sp_df_2[sp_df_2['anomaly'] == 1].copy()
# anomaly 열 제거
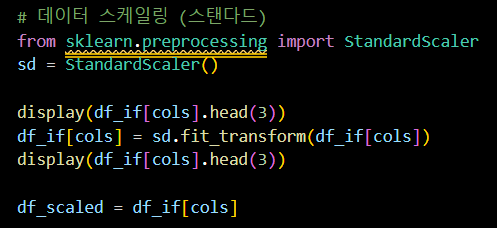
df_if.drop(labels='anomaly', axis=1)📌 데이터 표준화
선택한 컬럼에 대해 스탠다드 스케일링 수행
- StandardScaler를 사용하여 데이터 스케일링
- 스케일링 전 데이터 확인
- 선택한 컬럼을 스케일링하여 변환
- 스케일링 후 데이터 확인
- 스케일링된 데이터를 df_scaled에 저장
# 데이터 스케일링 (스탠다드)
from sklearn.preprocessing import StandardScaler
sd = StandardScaler()
# 스케일링 전 데이터 확인
display(df_if[cols].head(3))
# 선택한 컬럼을 스케일링하여 변환
df_if[cols] = sd.fit_transform(df_if[cols])
# 스케일링 후 데이터 확인
display(df_if[cols].head(3))
# 스케일링된 데이터를 df_scaled에 저장
df_scaled = df_if[cols]
📌 데이터 분석
📌 PCA (주성분 분석)
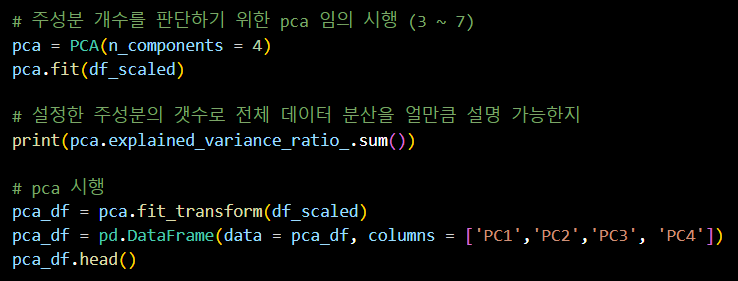
주성분 개수를 판단하기 위한 PCA 임의 시행
- PCA 모델을 생성하고 주성분 개수를 4로 설정
- 모델 학습
- 설정한 주성분의 개수로 전체 데이터 분산에 대한 설명력 확인
- PCA를 수행하여 주성분으로 변환
- 변환된 주성분 데이터를 데이터프레임으로 저장
- 변환된 데이터프레임의 상위 5개 행 출력
# 주성분 개수를 판단하기 위한 pca 임의 시행
pca = PCA(n_components=4)
pca.fit(df_scaled)
# 설정한 주성분의 갯수로 전체 데이터 분산을 얼만큼 설명 가능한지
print(pca.explained_variance_ratio_.sum())
# pca 시행
pca_df = pca.fit_transform(df_scaled)
pca_df = pd.DataFrame(data=pca_df, columns=['PC1', 'PC2', 'PC3', 'PC4'])
pca_df.head()
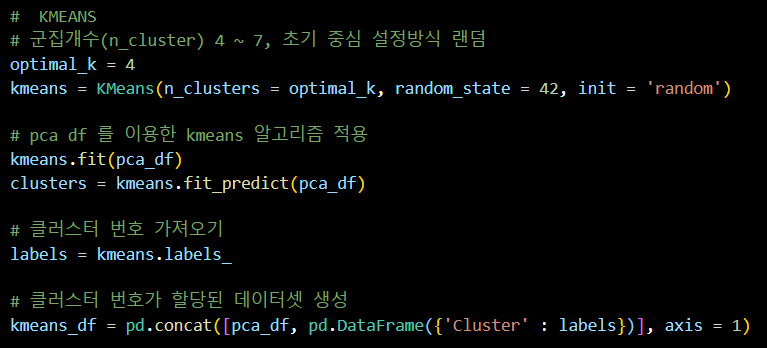
📌 군집 분석 (K-means)
KMeans 클러스터링
- 군집 개수를 4로 설정, 초기 중심 설정 방식을 랜덤으로 설정
- PCA로 변환된 데이터를 이용해 KMeans 알고리즘 적용
- 모델 학습
- 각 데이터 포인트의 클러스터 번호 가져오기
- 클러스터 번호가 할당된 데이터셋 생성
# KMEANS
# 군집개수(n_cluster) 4, 초기 중심 설정방식 랜덤
optimal_k = 4
kmeans = KMeans(n_clusters=optimal_k, random_state=42, init='random')
# pca df 를 이용한 kmeans 알고리즘 적용
kmeans.fit(pca_df)
clusters = kmeans.fit_predict(pca_df)
# 클러스터 번호 가져오기
labels = kmeans.labels_
# 클러스터 번호가 할당된 데이터셋 생성
kmeans_df = pd.concat([pca_df, pd.DataFrame({'Cluster': labels})], axis=1)
📌 군집 시각화
2차원으로 클러스터 시각화
- 그래프 크기를 8x8로 설정
- PC1과 PC2 축을 사용하여 클러스터를 시각화
- 각 클러스터를 다른 색으로 구분
- 그래프 제목 설정
- 그래프 표시
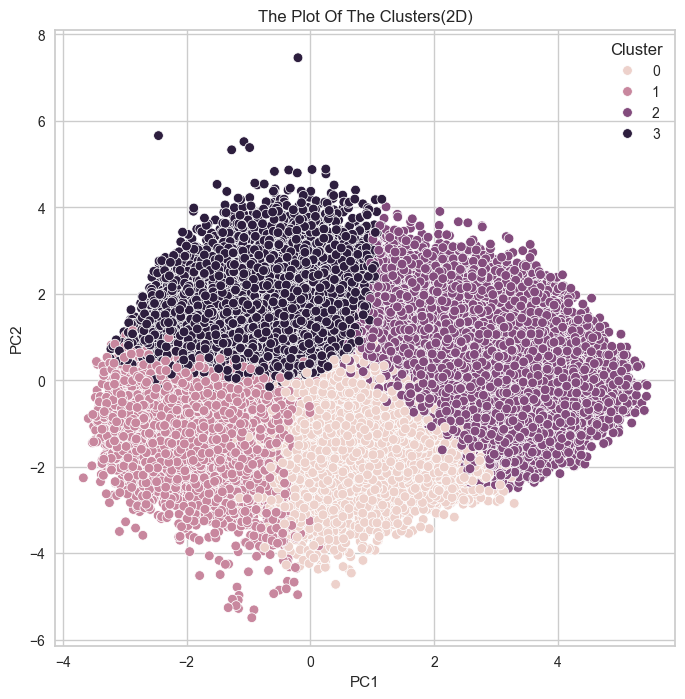
# 2차원으로 시각화
plt.figure(figsize=(8, 8))
sns.scatterplot(data=kmeans_df, x='PC1', y='PC2', hue='Cluster')
plt.title('The Plot Of The Clusters(2D)')
plt.show()
클러스터별 평균값 계산 및 시각화
- 클러스터 번호를 문자열로 변환하여 df_scaled에 추가
- 클러스터별 평균값을 계산하여 전치 후 그래프로 시각화
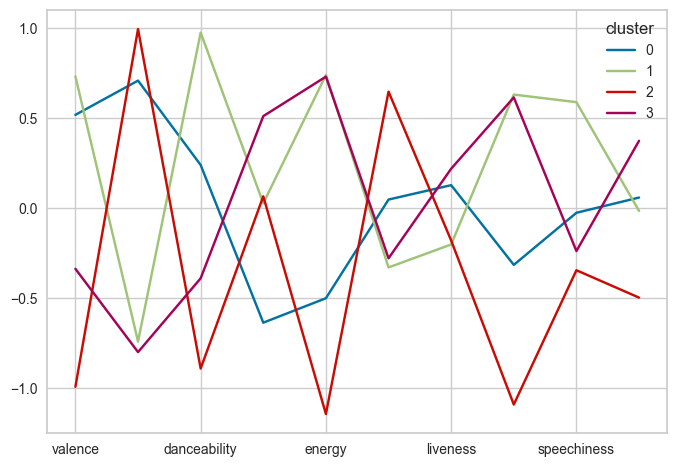
# 클러스터별 평균값 시각화
df_scaled['cluster']=labels.astype(str)
df_scaled.groupby('cluster').mean().T.plot()클러스터별 평균값 DataFrame 생성
- 각 클러스터의 평균값을 계산하여 DataFrame으로 저장
- 각 클러스터의 특성 분석 및 시각화
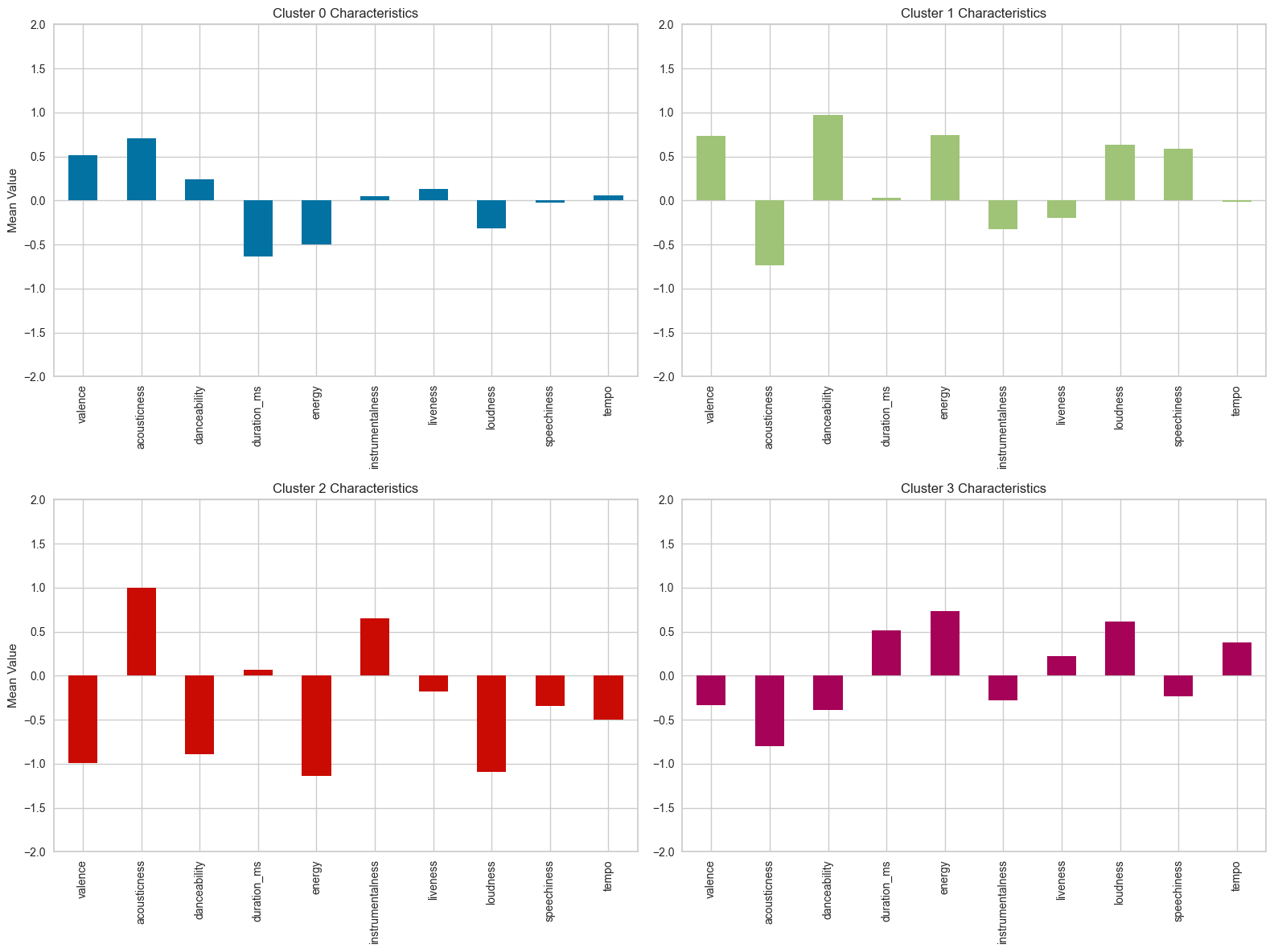
클러스터 0, 1, 2, 3의 평균값을 추출
- 2x2 서브플롯을 생성하여 각 클러스터의 특성을 막대 그래프로 시각화
- 클러스터별 평균값을 막대 그래프로 표시
- 그래프 제목, y축 레이블, y축 범위 설정
- 레이아웃 조정 및 그래프 표시
# 클러스터별 평균값 DataFrame 생성
cluster_means = df_scaled.groupby('cluster').mean()
# 클러스터 0의 특성 분석 및 시각화
cluster_0 = cluster_means.loc['0']
cluster_1 = cluster_means.loc['1']
cluster_2 = cluster_means.loc['2']
cluster_3 = cluster_means.loc['3']
# 클러스터별 평균값 시각화
fig, axes = plt.subplots(2, 2, figsize=(16, 12))
# 클러스터 0
# 클러스터 0의 평균값을 막대 그래프로 시각화
cluster_0.plot(kind='bar', ax=axes[0, 0], color='b')
# 그래프 제목 설정
axes[0, 0].set_title('Cluster 0 Characteristics')
# y축 레이블 설정
axes[0, 0].set_ylabel('Mean Value')
# y축 범위 설정
axes[0, 0].set_ylim(-2, 2)
# 클러스터 1
# 클러스터 1의 평균값을 막대 그래프로 시각화
cluster_1.plot(kind='bar', ax=axes[0, 1], color='g')
# 그래프 제목 설정
axes[0, 1].set_title('Cluster 1 Characteristics')
# y축 범위 설정
axes[0, 1].set_ylim(-2, 2)
# 클러스터 2
# 클러스터 2의 평균값을 막대 그래프로 시각화
cluster_2.plot(kind='bar', ax=axes[1, 0], color='r')
# 그래프 제목 설정
axes[1, 0].set_title('Cluster 2 Characteristics')
# y축 레이블 설정
axes[1, 0].set_ylabel('Mean Value')
# y축 범위 설정
axes[1, 0].set_ylim(-2, 2)
# 클러스터 3
# 클러스터 3의 평균값을 막대 그래프로 시각화
cluster_3.plot(kind='bar', ax=axes[1, 1], color='m')
# 그래프 제목 설정
axes[1, 1].set_title('Cluster 3 Characteristics')
# y축 범위 설정
axes[1, 1].set_ylim(-2, 2)
# 서브플롯 레이아웃 조정
plt.tight_layout()
# 그래프 표시
plt.show()
📌 군집 평가
실루엣 계수 계산
- silhouette_score를 사용하여 각 클러스터의 실루엣 평균값 계산
- silhouette_samples를 사용하여 각 데이터 포인트의 실루엣 값을 계산
- 실루엣 평균값과 각 데이터 포인트의 실루엣 값을 출력
# 실루엣 계수 계산
# 각 클러스터의 실루엣 평균값 계산
silhouette_avg = silhouette_score(pca_df, clusters)
# 각 데이터 포인트의 실루엣 값을 계산
silhouette_values = silhouette_samples(pca_df, clusters)
# 실루엣 평균값 출력
print(silhouette_avg)
# 각 데이터 포인트의 실루엣 값 출력
print(silhouette_values)클러스터별 실루엣 플롯 생성
- 각 클러스터의 실루엣 값을 가져와 정렬
- 클러스터 크기를 계산하여 y 좌표 범위 설정
- 클러스터 색상을 설정하여 실루엣 값을 플롯에 채우기
- 각 클러스터 레이블 추가
- 다음 클러스터를 위한 y 좌표 업데이트
- 플롯 제목, x축 및 y축 레이블 설정
- 실루엣 평균값에 대한 수직선 추가
- 플롯 표시
# 클러스터별 실루엣 플롯 생성
fig, ax = plt.subplots(figsize=(10, 6))
# 초기 y 좌표 설정
y_lower = 10
for i in range(optimal_k):
# 각 클러스터의 실루엣 값을 가져와 정렬
ith_cluster_silhouette_values = silhouette_values[clusters == i]
ith_cluster_silhouette_values.sort()
# 클러스터 크기 계산
size_cluster_i = ith_cluster_silhouette_values.shape[0]
y_upper = y_lower + size_cluster_i
# 클러스터 색상 설정
color = plt.cm.nipy_spectral(float(i) / optimal_k)
ax.fill_betweenx(np.arange(y_lower, y_upper), 0, ith_cluster_silhouette_values,
facecolor=color, edgecolor=color, alpha=0.7)
# 클러스터 레이블 추가
ax.text(-0.05, y_lower + 0.5 * size_cluster_i, str(i))
# 다음 클러스터를 위한 y 좌표 업데이트
y_lower = y_upper + 10
# 플롯 제목 및 레이블 설정
ax.set_title("Silhouette plot for the various clusters")
ax.set_xlabel("Silhouette coefficient values")
ax.set_ylabel("Cluster label")
# 실루엣 평균값에 대한 수직선 추가
ax.axvline(x=silhouette_avg, color="red", linestyle="--")
ax.set_yticks([])
ax.set_xticks(np.arange(-0.1, 1.1, 0.2))
# 플롯 표시
plt.show()
📌 군집 결과
📌 군집 대표 데이터
클러스터 중심 좌표 추출
- KMeans 클러스터링에서 계산된 클러스터 중심 좌표 추출
- 각 데이터 포인트와 해당 클러스터 중심 간의 거리 계산
find_nearest 함수 정의
- 각 클러스터의 데이터 포인트 추출
- 유클리드 거리 계산
- 가장 작은 거리의 인덱스를 찾기
- 가장 가까운 데이터 포인트와 인덱스를 리스트에 추가
- 가장 가까운 데이터 포인트와 인덱스를 데이터프레임으로 반환

# 클러스터 중심 좌표
cluster_centers = kmeans.cluster_centers_
# 각 데이터 포인트와 해당 클러스터 중심 간의 거리 계산
def find_nearest(data, centers, labels):
nearest_points = []
nearest_indices = []
for i, center in enumerate(centers):
# 해당 클러스터의 데이터 포인트 추출
cluster_points = data[labels == i]
# 유클리드 거리 계산
distances = np.linalg.norm(cluster_points.values - center, axis=1)
# 가장 작은 거리의 인덱스 찾기
nearest_point_idx = np.argmin(distances)
# 가장 가까운 데이터 포인트와 인덱스를 리스트에 추가
nearest_points.append(cluster_points.iloc[nearest_point_idx])
nearest_indices.append(cluster_points.index[nearest_point_idx])
return pd.DataFrame(nearest_points), nearest_indices
+) 참고
유클리드 거리 계산
distances = np.linalg.norm(cluster_points.values - center, axis=1): 클러스터 내의 모든 포인트들과 중심점 간의 유클리드 거리를 계산하는 코드
세부 내용 :
cluster_points.values :
.values 메서드는 DataFrame을 numpy 배열로 변환한다.
center는 중심점을 나타내는 numpy 배열로, 클러스터 중심 좌표.
cluster_points.values - center:
각 포인트에서 중심점을 빼는 연산, 중심점과 각 포인트 간의 벡터 차이를 구한다.
np.linalg.norm(..., axis=1) :
이 함수는 벡터의 크기(유클리드 거리)를 계산하는데,
axis=1은 행(row) 단위로 연산을 수행한다는 의미이다.
각 포인트와 중심점 간의 거리를 계산하기 위해 사용
find_nearest 함수 호출
- 각 클러스터의 중심에 가장 가까운 데이터 포인트와 해당 인덱스 반환
- 각 클러스터별 가장 가까운 데이터 포인트와 원본 인덱스 추가
- 가장 가까운 데이터와 원본 데이터의 인덱스를 데이터프레임에 추가
- 클러스터 번호 추가
- 각 클러스터 중심에 가장 가까운 데이터 포인트의 원본 인덱스 추출
- 가장 가까운 데이터 포인트의 원본 인덱스를 추출
- 원본 데이터에서 해당 인덱스에 해당하는 행을 출력
- 원본 데이터프레임에서 해당 인덱스의 행을 출력

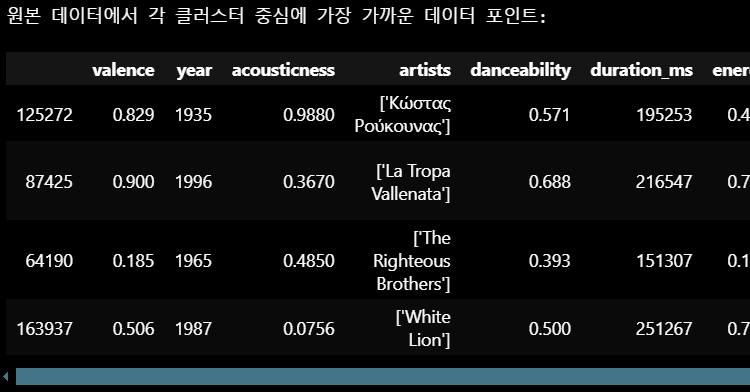
# find_nearest 함수 호출
nearest_points_df, nearest_indices = find_nearest(pca_df, cluster_centers, labels)
# 각 클러스터별 가장 가까운 데이터 포인트와 원본 인덱스 추가
nearest_points_df['Original_Index'] = nearest_indices
nearest_points_df['Cluster'] = range(optimal_k)
# 각 클러스터 중심에 가장 가까운 데이터 포인트의 원본 인덱스 추출
original_indices_nearest = nearest_points_df['Original_Index']
# 원본 데이터에서 해당 인덱스에 해당하는 행을 출력
nearest_original_data = sp_df.loc[original_indices_nearest]
print("원본 데이터에서 각 클러스터 중심에 가장 가까운 데이터 포인트:")
display(nearest_original_data)
클러스터 및 클러스터 중심 시각화
- 그래프 크기를 8x8로 설정
- 각 클러스터를 다른 색으로 시각화
- 클러스터 중심을 빨간색 점으로 표시
- 그래프 제목 및 레전드 설정
- 그래프 표시
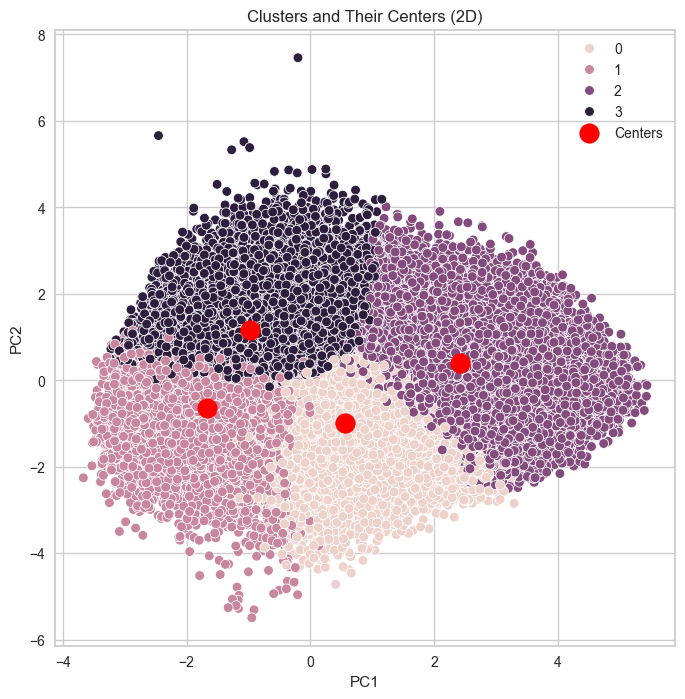
# 시각화
plt.figure(figsize=(8, 8))
# 클러스터 시각화
sns.scatterplot(data=kmeans_df, x='PC1', y='PC2', hue='Cluster')
# 클러스터 중심 시각화
plt.scatter(cluster_centers[:, 0], cluster_centers[:, 1], s=200, c='red', label='Centers')
# 그래프 제목 및 레전드 설정
plt.title('Clusters and Their Centers (2D)')
plt.legend()
# 그래프 표시
plt.show()
📌 군집 활용 1
랜덤 추천 플레이리스트
원본 데이터에 군집 레이블 추가
- 새로운 Cluster 열을 추가하고 군집 레이블을 할당
- -1인 군집이 있는지 확인 및 제거
- -1인 군집을 제거한 깨끗한 데이터프레임 생성
- 원본 데이터에서 랜덤으로 10곡의 음악 리스트 추출
- 랜덤으로 10곡의 음악 리스트를 추출
- 추출된 음악 리스트의 군집 비율 계산
- 추출된 음악 리스트에서 군집 비율을 계산
- 각 군집의 비율에 따라 추천할 곡의 수 계산
- 각 군집의 비율에 따라 추천할 곡의 수를 계산
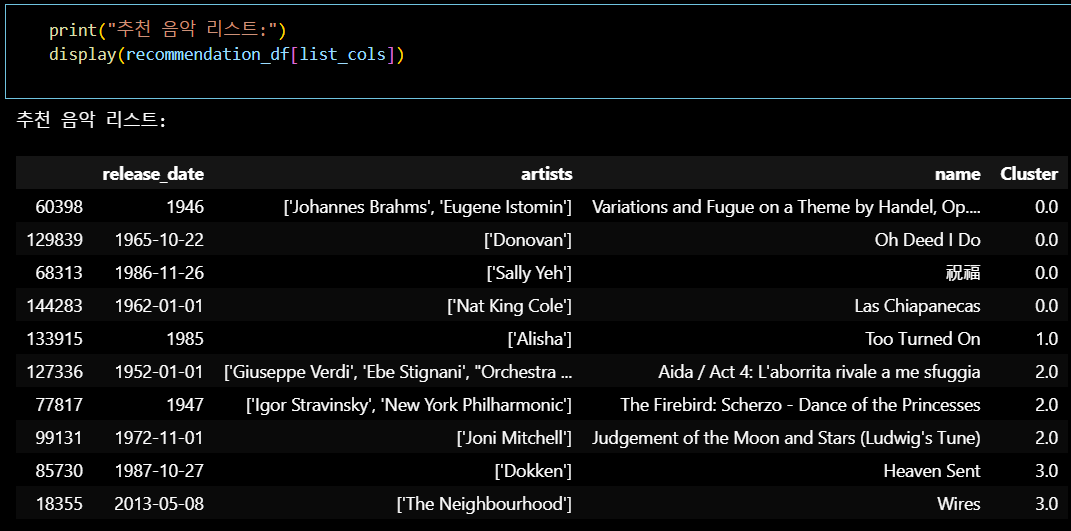
- 추천 음악 리스트 생성
- 각 군집에서 추천할 곡을 샘플링하여 리스트에 추가
- 추천 음악 리스트 결합
- 추천 음악 리스트를 하나의 데이터프레임으로 결합
- 군집별로 정렬
- 추출된 음악 리스트와 추천 음악 리스트를 군집별로 정렬
# 원본 데이터에 군집 레이블 추가
sp_df['Cluster'] = np.nan
sp_df.loc[original_indices, 'Cluster'] = labels
# -1인 군집이 있는지 확인 및 제거
sp_df_clean = sp_df[sp_df['Cluster'] != -1].copy()
# 원본 데이터에서 랜덤으로 10곡의 음악 리스트를 추출
random_sample = sp_df_clean.sample(n=10, random_state=None)
# 추출된 음악 리스트의 군집 비율 계산
cluster_counts = random_sample['Cluster'].value_counts(normalize=True)
# 각 군집의 비율에 따라 추천할 곡의 수 계산
recommendation_counts = (cluster_counts * 10).round().astype(int)
# 추천 음악 리스트 생성
recommendation_list = []
for cluster, count in recommendation_counts.items():
if count > 0:
cluster_songs = sp_df_clean[sp_df_clean['Cluster'] == cluster].sample(n=count, random_state=None)
recommendation_list.append(cluster_songs)
# 추천 음악 리스트 결합
recommendation_df = pd.concat(recommendation_list)
# 군집별로 정렬하기
random_sample = random_sample.sort_values(by='Cluster')
recommendation_df = recommendation_df.sort_values(by='Cluster')
list_cols = ['release_date', 'artists', 'name', 'Cluster']
+) 참고
sp_df['Cluster'] = np.nan
sp_df 데이터프레임에 'Cluster' 열을 추가, 초기값을 NaN으로 설정sp_df.loc[original_indices, 'Cluster'] = labels
클러스터 중심에 가장 가까운 데이터 포인트의
원본 인덱스에 해당하는 행에 클러스터 레이블을 할당
이 과정을 통해 원본 데이터프레임에 클러스터링 결과를 반영한다.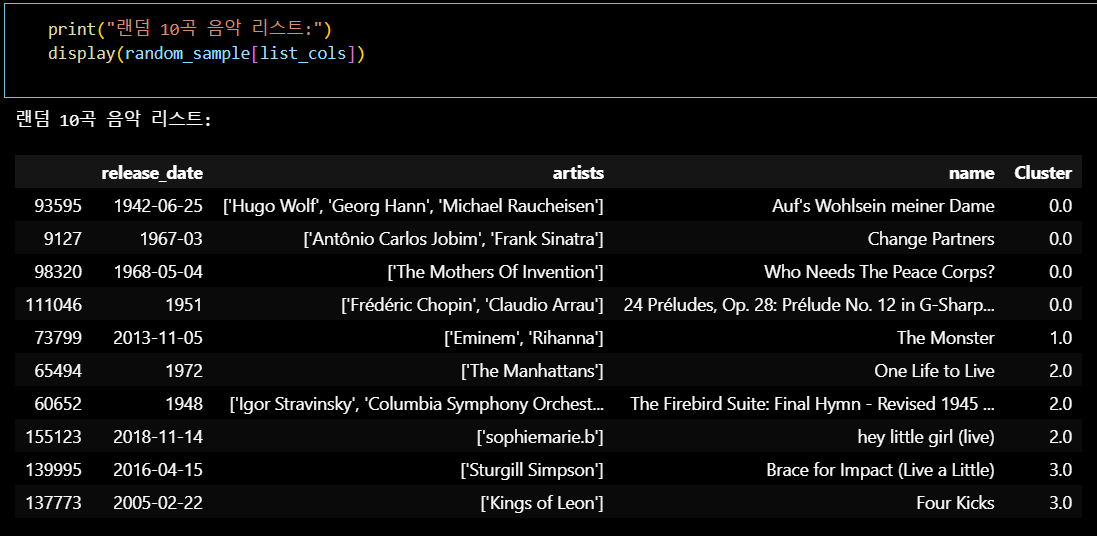
📌 군집 활용 2
검색 기반 추천 플레이리스트
원본 데이터에 군집 레이블 추가
sp_df['Cluster'] = np.nan:
원본 데이터프레임 sp_df에 새로운 'Cluster' 열을 추가하고 초기값을 NaN으로 설정.
sp_df.loc[original_indices, 'Cluster'] = labels:
원본 데이터프레임 sp_df의 특정 인덱스에 해당하는 행에 클러스터 레이블을 할당.
---
-1인 군집이 있는지 확인 및 제거
sp_df_clean = sp_df[sp_df['Cluster'] != -1].copy():
-1인 군집을 제거한 깨끗한 데이터프레임 생성.
---
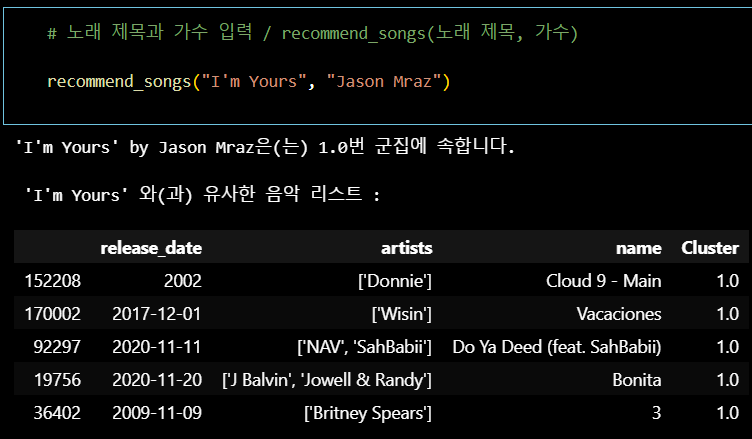
사용자가 입력한 노래 제목과 가수를 통해
해당 노래의 군집을 찾고 비슷한 노래를 추천하기 위한 함수 정의
def recommend_songs(title, artist, n_recommendations=5):
노래 제목과 가수를 입력받아 비슷한 노래를 추천하는 함수 정의.
---
해당 노래가 데이터프레임에 존재하는지 확인
song = sp_df_clean[(sp_df_clean['name'] == title) &
(sp_df_clean['artists'].str.contains(artist))]:
입력된 노래 제목과 가수를 데이터프레임에서 검색
if song.empty:
노래가 데이터프레임에 존재하지 않으면 경고 메시지 출력 후 함수 종료
---
해당 노래의 군집 찾기
cluster = song['Cluster'].values[0]:
해당 노래의 클러스터를 찾고 출력
---
해당 군집에서 비슷한 노래 추천
cluster_songs = sp_df_clean[sp_df_clean['Cluster'] == cluster]:
해당 군집에 속하는 모든 노래를 필터링
recommendations =
cluster_songs.sample(n=n_recommendations, random_state=None):
해당 군집에서 n개의 비슷한 노래를 랜덤으로 샘플링
---
추천 음악 리스트 출력
list_cols = ['release_date', 'artists', 'name', 'Cluster']:
추천 음악 리스트에 포함될 컬럼 설정
display(recommendations[list_cols]):
추천 음악 리스트 출력