
개요

📌 데이터 전처리
📌 데이터 확인
.head(): 데이터를 n개 행까지 출력data.head() # head()은 기본 5개 행에 대한 데이터를 보여줌 data.head(3) # ()안에 숫자만큼 데이터를 보여줌
.info(): 데이터의 정보 파악 (인덱스, 컬럼명, 데이터 수, 데이터 타입)data.info() # null 값을 확인할때도 활용
.describe(): 데이터 기초통계량 확인 (데이터 수, 평균, 표준편차, 사분위, 중앙값)data.describe() # 숫자값에 대해서만 기초통계량 확인 가능
- 데이터를 불러온 뒤 꼭 확인을 해야 한다!
- 데이터의 결측치(null 또는 NaN) 유무
- 데이터의 타입이 알맞게 들어가 있는지 (날짜, 숫자 등)
- 데이터 통계도 목적에 따라 확인 !
+)
- 데이터 타입 변경
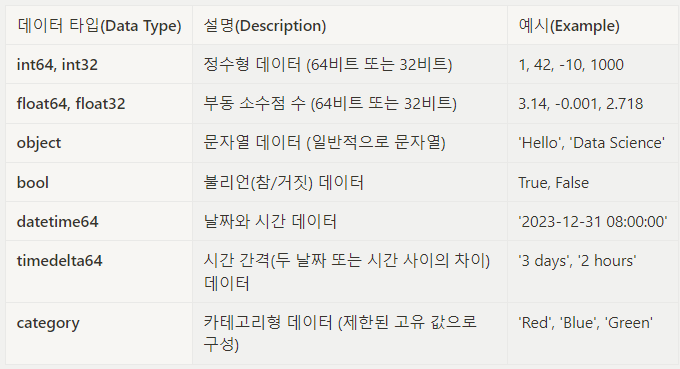
astype(): Pandas 데이터프레임의 열의 데이터 타입을 변경하는 데 사용DataFrame['column_name'] = DataFrame['column_name'].astype(new_dtype)+)
DataFrame['column_name']: 열을 선택하는 방식, 데이터 타입을 변경하고자 하는 열 지정
new_dtype: 변경하고자 하는 새로운 데이터 타입 명시 (예: 'int', 'float', 'str' 등)
- 예시1 : int > float
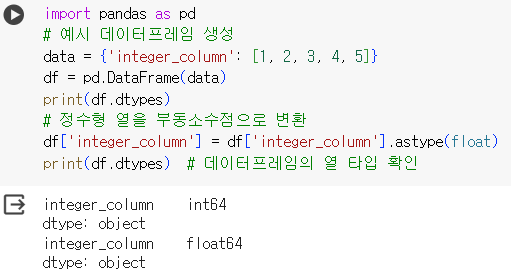
import pandas as pd
# 예시 데이터프레임 생성
data = {'integer_column': [1, 2, 3, 4, 5]}
df = pd.DataFrame(data)
print(df.dtypes)
# 정수형 열을 부동소수점으로 변환
df['integer_column'] = df['integer_column'].astype(float)
print(df.dtypes) # 데이터프레임의 열 타입 확인- 예시2 : int > str
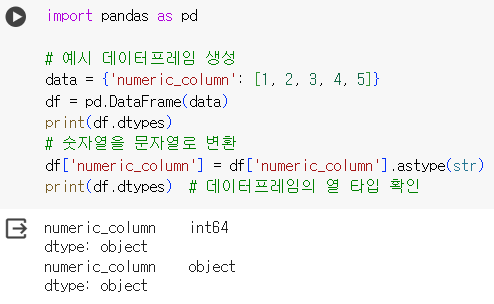
import pandas as pd
# 예시 데이터프레임 생성
data = {'numeric_column': [1, 2, 3, 4, 5]}
df = pd.DataFrame(data)
print(df.dtypes)
# 숫자열을 문자열로 변환
df['numeric_column'] = df['numeric_column'].astype(str)
print(df.dtypes) # 데이터프레임의 열 타입 확인📌 데이터 선택
- 원하는 형태로 데이터를 선택하기
iloc은 정수 기반의 인덱스 사용 /loc은 레이블 기반의 인덱스명 사용
.iloc [로우, 컬럼]: 인덱스 번호로 선택하기
- 행 번호(로우)와 열 번호(컬럼)를 통해 특정 행과 열 데이터를 선택할 수 있다.
data.iloc[0,2] #행과 열 번호를 통해 특정 데이터를 선택할 수 있음
import pandas as pd # 샘플 데이터프레임 생성 data = { 'A': [1, 2, 3, 4, 5], 'B': [10, 20, 30, 40, 50], 'C': [100, 200, 300, 400, 500] } df = pd.DataFrame(data) # iloc을 사용하여 특정 행과 열 선택 selected_data = df.iloc[1:4, 0:2] # 인덱스 1부터 3까지의 행과 0부터 1까지의 열 선택 print(selected_data)

.loc [로우, 컬럼] : 이름으로 선택하기
- 인덱스가 번호가 아니고 특정 문자일 경우
data.loc['행이름' , '컬럼명']
# 행이름과 컬럼명을 통해서도 특정 데이터를 선택할 수 있음
import pandas as pd # 샘플 데이터프레임 생성 data = { 'A': [1, 2, 3, 4, 5], 'B': [10, 20, 30, 40, 50], 'C': [100, 200, 300, 400, 500] } df = pd.DataFrame(data, index=['a', 'b', 'c', 'd', 'e']) # loc을 사용하여 특정 행과 열 선택 selected_data = df.loc['b':'d', 'A':'B'] # 레이블 'b'부터 'd'까지의 행과 'A'부터 'B'까지의 열 선택 print(selected_data)

- 1개의 컬럼 전체를 선택할 경우
- 리스트 슬라이싱을 활용
data.loc[: , '컬럼명']data.loc[: , '컬럼명'] #또는 데이터프레임['컬럼명'] 으로도 동일한 값을 선택할 수 있습니다. data['컬럼명']
- 여러 개의 컬럼 선택의 경우에도 리스트 활용 가능
data[ ['컬럼명1', '컬럼명2', '컬럼명3' ] ]data[ ['컬럼명1', '컬럼명2', '컬럼명3' ] ]
- 여러 개의 컬럼 선택 시 내가 원하는 순서대로 선택 가능
data[ ['컬럼명3', '컬럼명1', '컬럼명2' ] ]data[ ['컬럼명3', '컬럼명1', '컬럼명2' ] ]
- 2개 이상의 셀을 선택할 경우
- 리스트 형태를 활용해 데이터 선택
# 2개 컬럼명을 선택할 경우
data.loc[ '행이름' , ['컬럼명1' , '컬럼명2'] ]
# 2개 행이름을 선택할 경우
data.loc[ ['행이름1', '행이름2'] , '컬럼명1' ]
# 리스트 슬라이싱 : 을 활용해서 특정 범위를 지정하여 선택할 수 있습니다.
data.loc[ '행이름' , '컬럼명1' : ] # '컬럼명1' : ==> 컬럼명1부터 끝까지라는 의미📌 조건에 따라 데이터 선택
- 특정 조건을 만족하는 데이터를 선택할 경우
(Boolean Indexing)- Boolean Indexing이란?
- 조건을 이용하여 데이터프레임에서 특정 조건을 만족하는 행을 선택하는 방법
- 데이터를 필터링하거나 원하는 조건을 만족하는 행을 추출할 수 있음
- 주로 불리언(Boolean) 값을 가지는 조건식을 사용하여 데이터프레임을 인덱싱하는 방법
- 조건식에 따라 각 행이
True또는False로 평가되며 이를 바탕으로 데이터프레임을 필터링
- 조건식에 따라 각 행이
- Boolean Indexing이란?
단일 조건으로 필터링 :
# 'age' 열에서 30세 이상인 행 필터링 df[df['age'] >= 30]
여러 조건으로 필터링 :
# 'age' 열에서 30세 이상이면서 'gender' 열이 'Male'인 행 필터링 df[(df['age'] >= 30) & (df['gender'] == 'Male')]
조건에 따른 특정 컬럼 필터링 :
# 'age' 열에서 30세 이상인 경우의 'name' 열만 선택 df.loc[df['age'] >= 30, 'name']
isin()을 활용한 필터링 :# 'gender' 열에서 'Male' 또는 'Female'인 행 필터링 df[df['gender'].isin(['Male', 'Female'])]
+)
isin(): Series(시리즈)나 DataFrame(데이터프레임)의 값들 중에서
특정 값이나 리스트 안에 포함된 값들을 찾아내는 메소드.
원하는 조건에 해당하는 데이터를 빠르게 필터링하거나 선택할 수 있음# Series나 DataFrame의 특정 열에서 단일 값 포함 여부 확인 import pandas as pd data = {'A': [1, 2, 3, 4, 5], 'B': ['apple', 'banana', 'orange', 'grape', 'melon']} df = pd.DataFrame(data) # 'B' 열에서 'banana' 값이 있는지 확인 result = df['B'].isin(['banana']) print(result)# 여러 값이 포함된 데이터를 찾기 위해 리스트에 여러 값을 넣어 사용합니다. # 'A' 열에서 2 또는 4 값을 포함하는 행 찾기 result = df['A'].isin([2, 4]) print(result)# 데이터프레임 전체에서 여러 열에 대해 isin()을 사용할 수 있습니다. # 데이터프레임 전체에서 여러 조건을 확인하여 필터링 result = df.isin({'A': [1, 3], 'B': ['apple', 'orange']}) print(result)
📌 데이터 추가
df['컬럼명'] = datadf = pd.DataFrame() df['컬럼명'] = data # df라는 데이터프레임에 '컬럼명'이라는 이름의 컬럼이 추가되고,해당 컬럼에 data라는 값이 추가된다. # 이때, data값이 1개의 단일 값인 경우에는 전체 df라는 데이터프레임 행에 data 값이 전체 적용됨 # 즉, # 하나의 값인 경우 => 전체 모두 동일한 값 적용 # (리스트,시리즈)의 형태인 경우 => 각 순서에 맞게 컬럼 값에 적용됨
- 신규 컬럼 추가하기
df = pd.DataFrame() # 컬럼 추가하기 df['EPL'] = 100 df['MLS'] = 60 df['NBA'] = 70 df # 리스트 형태로 컬럼값 추가하기 df['KFC'] = [50, 10, 30] #Tip. 행 수를 맞춰서 입력해줘야함 # 컬럼을 여러 조건 및 계산식을 통해 산출 값으로도 추가가 가능 df['ABC'] = (df['EPL'] + df['NBA']) * df['MLS'] * 2
📌 데이터 병합
-
concat&merge(+) 참고 -
concat()함수는 데이터프레임을 위아래 혹은 좌우로 연결할 수 있다.axis: 연결하고자 하는 축(방향) 지정
기본값은 0으로, 위아래로 연결 / 좌우로 연결하려면axis = 1로 설정ignore_index: 기본값은 False, 연결된 결과 데이터프레임의 인덱스 유지
True로 설정 시 새로운 인덱스 생성(기존 인덱스 무시, 새로운 인덱스 설정)
import pandas as pd # 두 개의 데이터프레임 생성 df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2'], 'B': ['B0', 'B1', 'B2']}) df2 = pd.DataFrame({'A': ['A3', 'A4', 'A5'], 'B': ['B3', 'B4', 'B5']}) # 위아래로 데이터프레임 연결 result_vertical = pd.concat([df1, df2], axis=0) # 좌우로 데이터프레임 연결 result_horizontal = pd.concat([df1, df2], axis=1) print("위아래 연결 결과:\n", result_vertical) print("\n좌우 연결 결과:\n", result_horizontal)

merge()함수는 SQL의 JOIN 연산과 유사한 방식으로 데이터프레임을 합칠 수 있다.
주로 두 개 이상의 데이터프레임에서 공통 열이나 인덱스를 기준으로 병합left&right: 병합할 데이터프레임 중 병합되는 기준이 되는 데이터프레임 지정how병합 방법을 나타내는 매개변수 :
inner, outer, left, right 등의 옵션- 'inner': 공통된 키(열)를 기준으로 교집합
- 'outer': 공통된 키를 기준으로 합집합
- 'left': 왼쪽 df의 모든 행 포함, 오른쪽 df는 공통된 키에 해당하는 행만 포함
- 'right': 오른쪽 df의 모든 행 포함, 왼쪽 df는 공통된 키에 해당하는 행만 포함
on: 병합 기준이 되는 열(열 이름 또는 리스트) 지정left_on&right_on: 왼쪽 df와 오른쪽 df에서 병합할 열 이름이 다른 경우 사용
import pandas as pd # 두 개의 데이터프레임 생성 left_df = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': [1, 2, 3, 4]}) right_df = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'value': [5, 6, 7, 8]}) # 'key' 열을 기준으로 두 데이터프레임 병합 merged_df = pd.merge(left_df, right_df, on='key', how='inner') print(merged_df)

📌 데이터 집계
-
Group by():
데이터프레임을 그룹화하고, 그룹 단위로 데이터를 분할, 적용, 결합하는 기능 제공 -
데이터 프레임을 특정 기준에 따라 그룹으로 나누어 집계, 변환, 필터링 등 가능
- 그룹 생성: 기준열(혹은 열들)을 지정하여 데이터프레임을 그룹으로 분할
- 그룹에 대한 연산 수행: 그룹 단위로 원하는 연산(합, 평균, 개수 등) 수행
- 결과 결합: 각 그룹의 연산 결과를 하나의 df로 결합해 새로운 df 생성
import pandas as pd # 샘플 데이터프레임 생성 data = { 'Category': ['A', 'B', 'A', 'B', 'A', 'B'], 'Value': [1, 2, 3, 4, 5, 6] } df = pd.DataFrame(data) # 'Category' 열을 기준으로 그룹화하여 'Value'의 연산 수행 grouped_mean = df.groupby('Category').mean() grouped_sum = df.groupby('Category').sum() grouped_count = df.groupby('Category').count() grouped_max = df.groupby('Category').max() grouped_min = df.groupby('Category').min() # 수치형 데이터의 경우에 연산이 가능

- 복수의 열을 기준으로 사용
import pandas as pd # 샘플 데이터프레임 생성 data = { 'Category': ['A', 'A', 'B', 'B', 'A', 'B'], 'SubCategory': ['X', 'Y', 'X', 'Y', 'X', 'Y'], 'Value': [1, 2, 3, 4, 5, 6] } df = pd.DataFrame(data) # 'Category'와 'SubCategory' 열을 기준으로 그룹화하여 'Value'의 합 계산 grouped_multiple = df.groupby(['Category', 'SubCategory']).sum() print(grouped_multiple)

- 다양한 집계 함수 적용
import pandas as pd # 샘플 데이터프레임 생성 data = { 'Category': ['A', 'A', 'B', 'B', 'A', 'B'], 'SubCategory': ['X', 'Y', 'X', 'Y', 'X', 'Y'], 'Value1': [1, 2, 3, 4, 5, 6], 'Value2': [10, 20, 30, 40, 50, 60] } df = pd.DataFrame(data) # 'Category'와 'SubCategory' 열을 기준으로 그룹화하여 각 그룹별 'Value1'과 'Value2'의 평균, 합 계산 grouped_multiple = df.groupby(['Category', 'SubCategory']).agg({'Value1': ['mean', 'sum'], 'Value2': 'sum'}) print(grouped_multiple)+)
복수의 열을 기준으로 그룹화하여 데이터프레임을 조작하는 경우,
groupby()함수에 복수의 열을 리스트로 전달하여 원하는 그룹화 기준을 지정하고,
agg()함수를 사용하여 여러 열에 대해 다양한 집계 함수를 적용할 수 있다.

📌 Pivot Table
Pivot_table():
주어진 데이터를 원하는 형태로 재배치하여 요약된 정보를 보기 쉽게 정리
import pandas as pd # 샘플 데이터프레임 생성 data = { 'Date': ['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02', '2023-01-01'], 'Category': ['A', 'B', 'A', 'B', 'A'], 'Value': [10, 20, 30, 40, 50] } df = pd.DataFrame(data) # 피벗 테이블 생성: 날짜를 행 인덱스로, 카테고리를 열 인덱스로, 값은 'Value'의 합으로 집계 pivot = df.pivot_table(index='Date', columns='Category', values='Value', aggfunc='sum') print(pivot)

import pandas as pd # 샘플 데이터프레임 생성 data = { 'Date': ['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02', '2023-01-01'], 'Category': ['A', 'B', 'A', 'B', 'A'], 'SubCategory': ['X', 'Y', 'X', 'Y', 'X'], 'Value': [10, 20, 30, 40, 50] } df = pd.DataFrame(data) # 피벗 테이블 생성: 'Date'를 행 인덱스로, 'Category'와 'SubCategory'를 열 인덱스로, 값은 'Value'의 합으로 집계 pivot = df.pivot_table(index='Date', columns=['Category', 'SubCategory'], values='Value', aggfunc='sum') print(pivot)

import pandas as pd # 샘플 데이터프레임 생성 data = { 'Date': ['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02', '2023-01-01'], 'Category': ['A', 'B', 'A', 'B', 'A'], 'Value1': [10, 20, 30, 40, 50], 'Value2': [100, 200, 300, 400, 500] } df = pd.DataFrame(data) # 피벗 테이블 생성: 'Date'를 행 인덱스로, 'Category'를 열 인덱스로, 값은 'Value1'과 'Value2'의 평균과 합으로 집계 pivot = df.pivot_table(index='Date', columns='Category', values=['Value1', 'Value2'], aggfunc={'Value1': 'mean', 'Value2': 'sum'}) print(pivot)

📌 데이터 정렬하기
sort_values(): 컬럼 기준 정렬
import pandas as pd # 샘플 데이터프레임 생성 data = { 'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eva'], 'Age': [25, 22, 30, 18, 27], 'Score': [85, 90, 75, 80, 95] } df = pd.DataFrame(data) # 정렬 sorted_by_score = df.sort_values('Score') # 'Score' 열을 기준으로 오름차순 정렬 sorted_by_score = df.sort_values('Score',ascending=False) # 'Score' 열을 기준으로 내림차순 정렬 print(sorted_by_score)

sort_index(): 인덱스 기준 정렬
import pandas as pd # 샘플 데이터프레임 생성 data = { 'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eva'], 'Age': [25, 22, 30, 18, 27], 'Score': [85, 90, 75, 80, 95] } df = pd.DataFrame(data) # 정렬 sorted_by_index = df.sort_index() # 인덱스를 기준으로 오름차순 정렬 sorted_by_index = df.sort_index(ascending=False) # 인덱스를 기준으로 내림차순 정렬 print(sorted_by_index)

📌 기타
pickle?- pickle 활용하기
- python 의 변수, 함수, 객체를 파일로 저장하고 불러올 수 있는 라이브러리
- list, dictionary등을 파일 그대로 저장하면 용량이 매우 커지는데 pickle을 사용하면 binary형태로 저장되기 때문에 용량이 매우 작아진다.
- 추가적으로 gzip을 이용하여 pickle로 저장된 데이터를 압축할 수 있음
→ pandas에서는to_pickle()및read_pickle()메서드를 통해pickle을 사용할 수 있음 - 머신러닝 모델 등을 저장하고 불러올때도 활용함
pickle 저장
import pandas as pd # 샘플 데이터프레임 생성 data = { 'Column1': [1, 2, 3, 4, 5], 'Column2': ['A', 'B', 'C', 'D', 'E'] } df = pd.DataFrame(data) # 데이터프레임을 pickle 파일로 저장 df.to_pickle('dataframe.pkl') # 데이터프레임을 'dataframe.pkl' 파일로 저장

pickle 불러오기
import pandas as pd # pickle 파일에서 데이터프레임 불러오기 loaded_df = pd.read_pickle('dataframe.pkl') # 'dataframe.pkl' 파일에서 데이터프레임 불러오기 print(loaded_df)

- 참고
