
개요
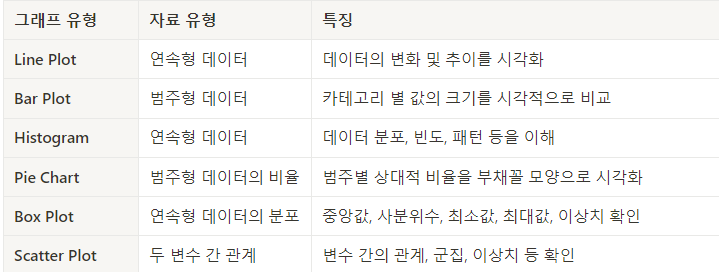
📌 데이터 시각화
📌 그래프 그리기 (차트)
- 차트 시각화 참고자료
📌 Line Plot
Line Plot (선 그래프)
- 선 그래프는 데이터 간
연속적인 관계시각화에 적합
주로 시간의 흐름에 따른 데이터의 변화 시각화
- 자료 유형: 연속적인 데이터의 추이를 보여줄 때 사용
- 활용: 시간에 따른 데이터의 변화, 추세를 보여줄 때 효과적
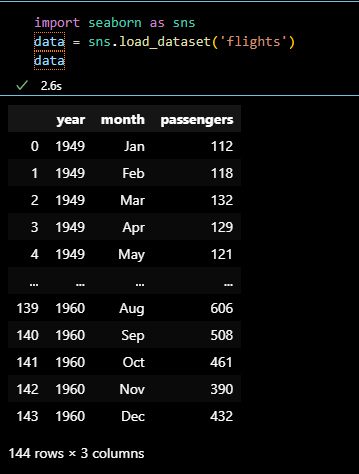
- 데이터 불러오기
import seaborn as sns data = sns.load_dataset('flights') data
- 데이터 전처리
# 연도 기준으로 그룹화 후 승객 컬럼을 sum()하여 연도별 승객 수 데이터 추출 data_gr = data[['year', 'passengers']].groupby('year').sum().reset_index() data_gr
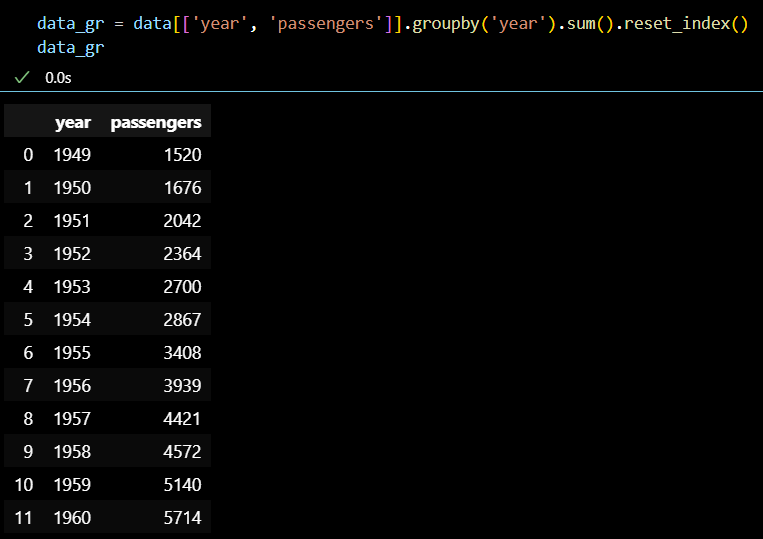
- 선 그래프 시각화
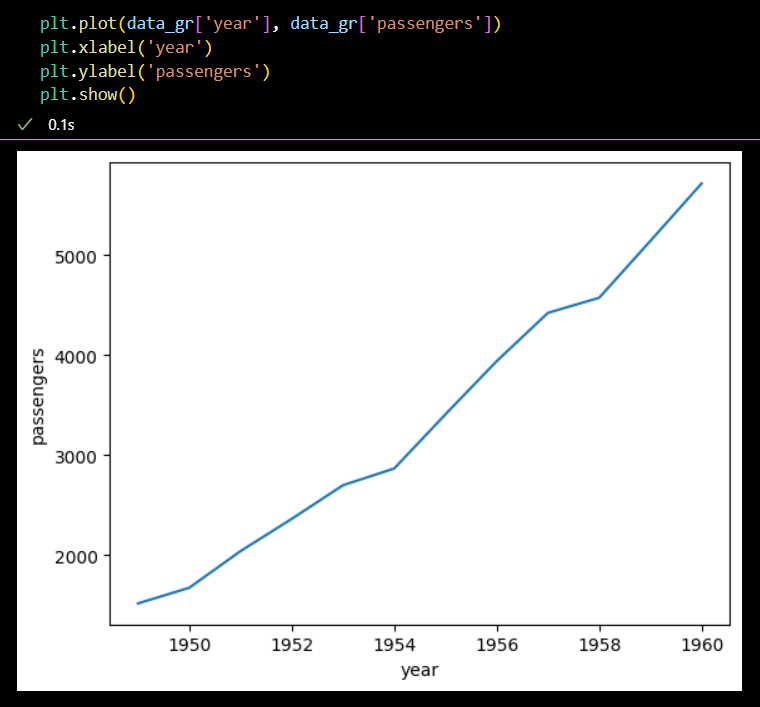
plt.plot(data_gr['year'], data_gr['passengers']) plt.xlabel('year') plt.ylabel('passengers') plt.show()
📌 Bar Plot
Bar Plot (막대 그래프)
- 막대 그래프는 범주형 데이터를 나타내며, 각 막대로 값의 크기를 비교하는 데 사용
- 자료 유형: 범주형 데이터 간의 비교를 나타낼 때 주로 사용
- 활용: 카테고리 별로 값의 크기나 빈도를 시각적으로 비교할 때 유용
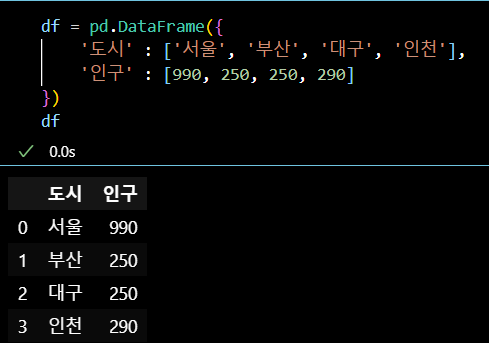
- 데이터 생성
df = pd.DataFrame({ '도시' : ['서울', '부산', '대구', '인천'], '인구' : [990, 250, 250, 290] }) df
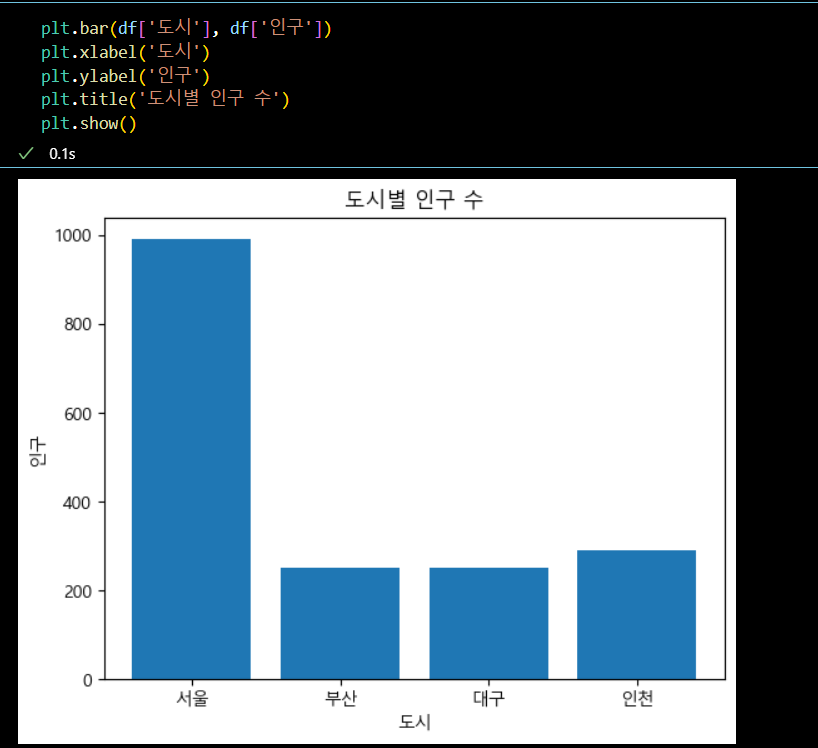
- 막대 그래프 시각화
plt.bar(df['도시'], df['인구']) plt.xlabel('도시') plt.ylabel('인구') plt.title('도시별 인구 수') plt.show()
📌 Histogram
Histogram (히스토그램)
- 히스토그램은 연속된 데이터의 분포 시각화
주로 데이터의 빈도를 시각화하여 해당 데이터의 분포를 이해하는 데 사용
- 자료 유형: 연속형 데이터의 분포를 보여줄 때 사용
- 활용: 데이터의 빈도나 분포, 패턴을 이해하고자 할 때 유용
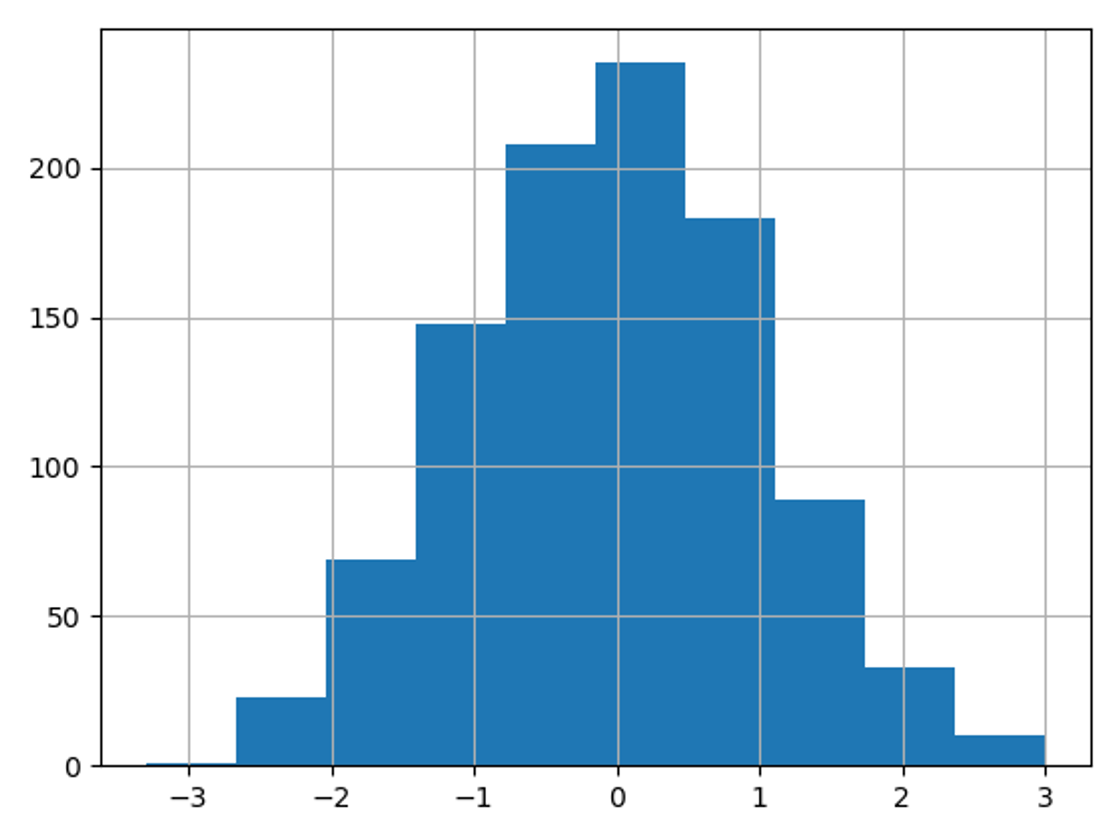
- 연속형 랜덤 데이터 생성 (feat.
numpy)
import numpy as np
data = np.random.randn(1000)
data.shape- 히스토그램 시각화
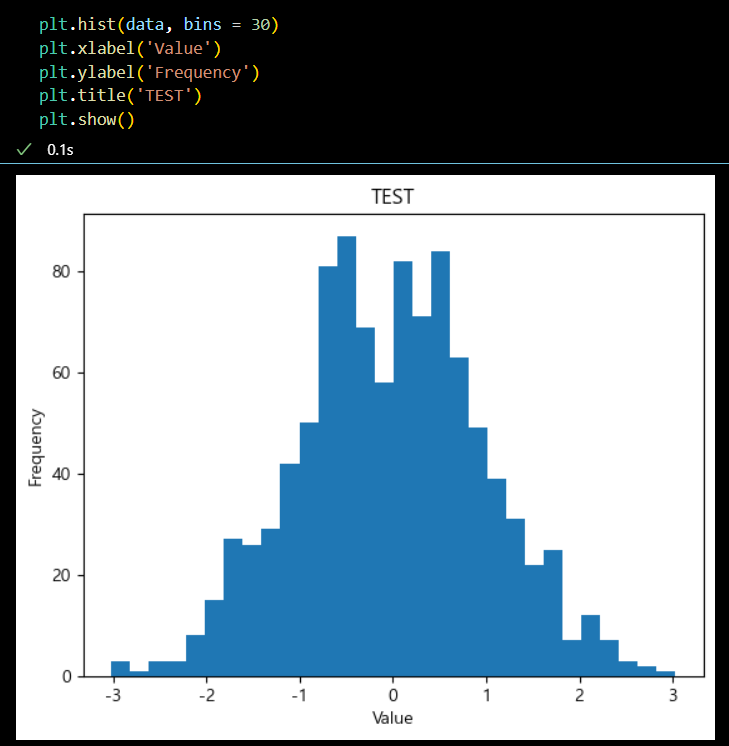
plt.hist(data, bins = 30) #bins 값 조절로 가로축 구간의 갯수 조절 / 기본값 : 30 plt.xlabel('Value') plt.ylabel('Frequency') plt.title('TEST') plt.show()
+) Bar vs Histogram 의 차이
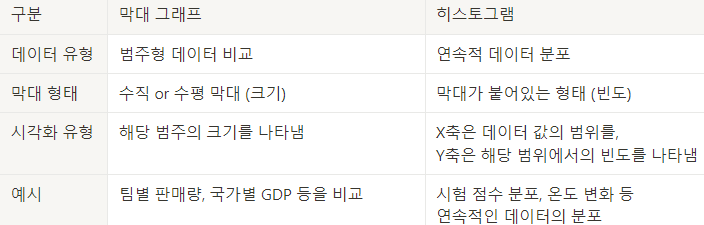
- 데이터 시각화의 목적이 다르다.
- 막대는 주로 범주형 데이터의 값을 비교
- 히스토그램은 연속적인 데이터의 분포를 시각화하는데 사용
📌 Pie Chart
Pie Chart (원 그래프)
- 원 그래프는 전체에서 각 부분의 비율을 시각화.
주로 카테고리별 비율을 비교할 때 사용
- 자료 유형: 범주형 데이터의 상대적 비율을 시각화하는 데 사용
- 활용: 전체에 대한 각 범주의 비율을 보여줄 때 유용
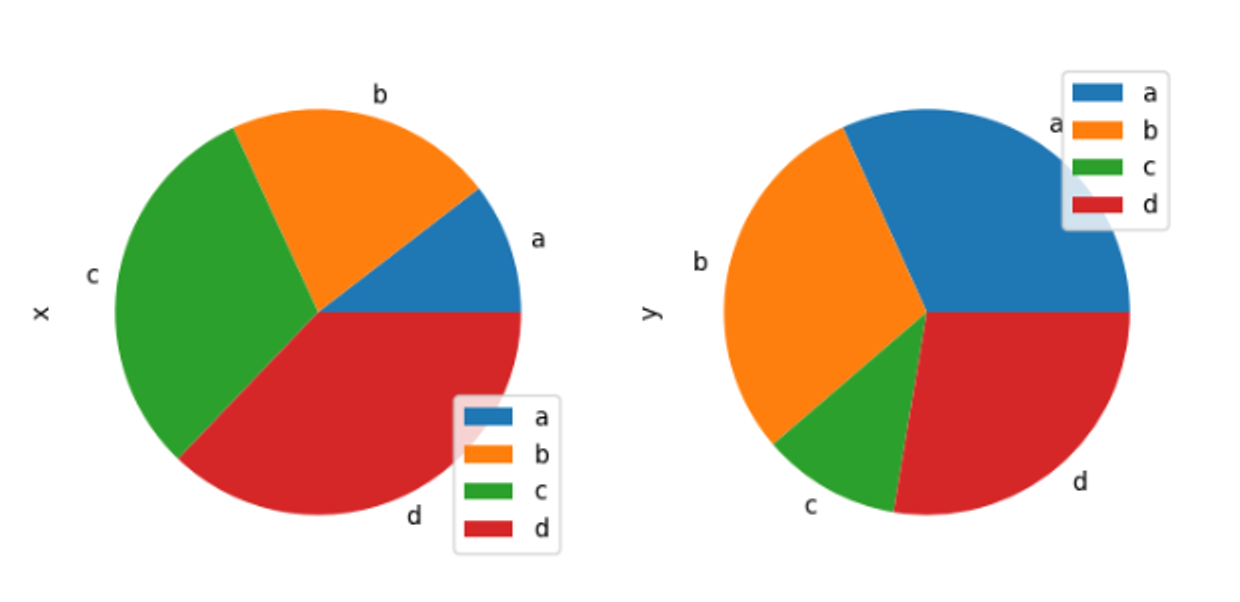
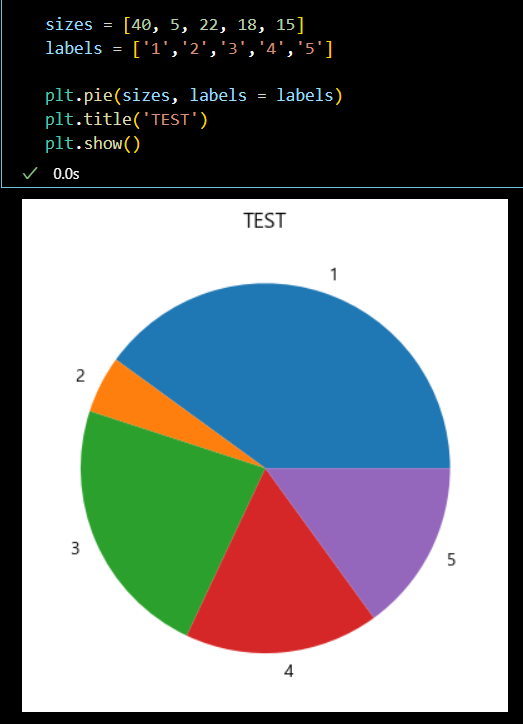
- 파이차트 시각화
sizes = [40, 5, 22, 18, 15] labels = ['1','2','3','4','5'] plt.pie(sizes, labels = labels) plt.title('TEST') plt.show()
📌 Box Plot
Box Plot (박스 플롯)
- 박스 플롯은 데이터의 분포와 이상치를 시각화
중앙값, 사분위수, 최솟값, 최댓값 등의 정보를 제공, 데이터의 통계적 특성 파악에 사용
- 자료 유형: 연속형 데이터의 분포와 이상치를 시각화하는 데 주로 사용
- 활용: 데이터의 중앙값, 사분위수, 최소값, 최대값, 이상치를 한 눈에 파악 가능
- 데이터 생성
iris = sns.load_dataset('iris') species = iris['species'].unique() sepal_lengths_list = [iris[iris['species'] == s]['sepal_length'].tolist() for s in species] sepal_lengths_list
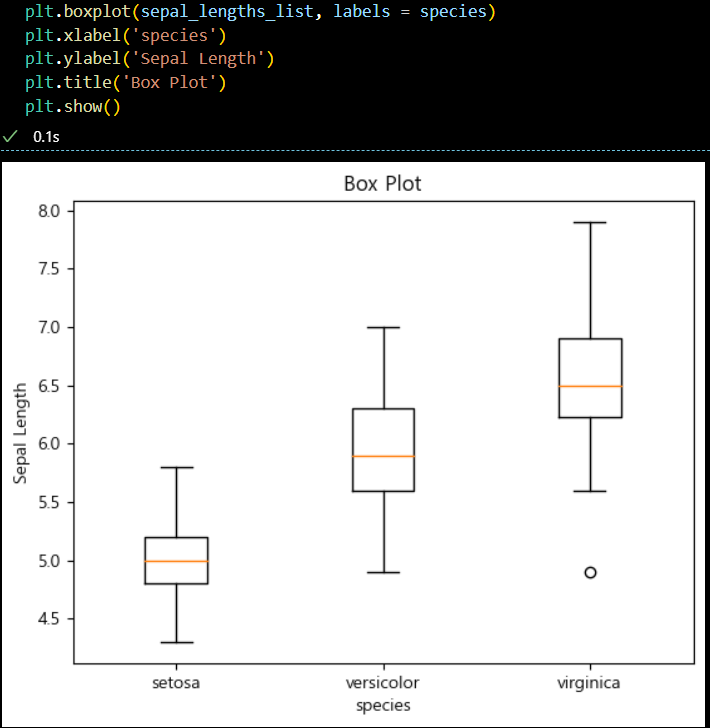
- 박스 플롯 시각화
# plt.figure(figsize = (5,3)) < 크기 조절 가능 plt.boxplot(sepal_lengths_list, labels = species) plt.xlabel('species') plt.ylabel('Sepal Length') plt.title('Box Plot') plt.show()
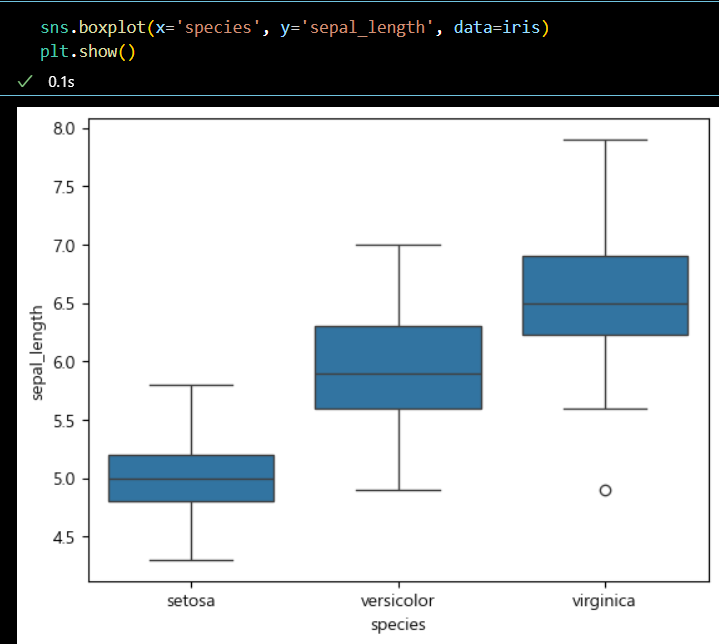
+)
seaborn라이브러리에서도 박스플롯 시각화 가능
sns.boxplot(x='species', y='sepal_length', data=iris) plt.show()
📌 Scatter Plot
Scatter Plot (산점도)
- 산점도는 두 변수 간의 관계를 점으로 표시하여 보여주는 그래프
- 두 변수 간의 상관 관계를 보여주고,
각 점이 데이터 포인트를 나타내며, 그 점들이 어떻게 분포되어 있는지 시각적으로 확인
- 자료 유형: 두 변수 간의 관계 및 상관관계를 보여줄 때 사용
- 활용: 변수 간의 관계, 군집, 이상치를 확인하고자 할 때 유용
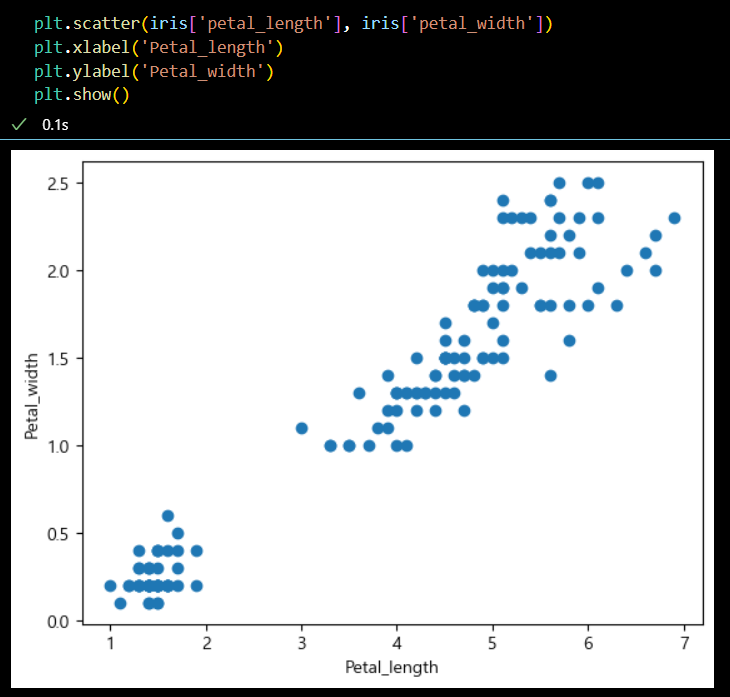
- 산점도 그리기
plt.scatter(iris['petal_length'], iris['petal_width']) plt.xlabel('Petal_length') plt.ylabel('Petal_width') plt.show()
plt.scatter(iris['sepal_length'], iris['sepal_width']) plt.xlabel('sepal_length') plt.ylabel('sepal_width') plt.show()
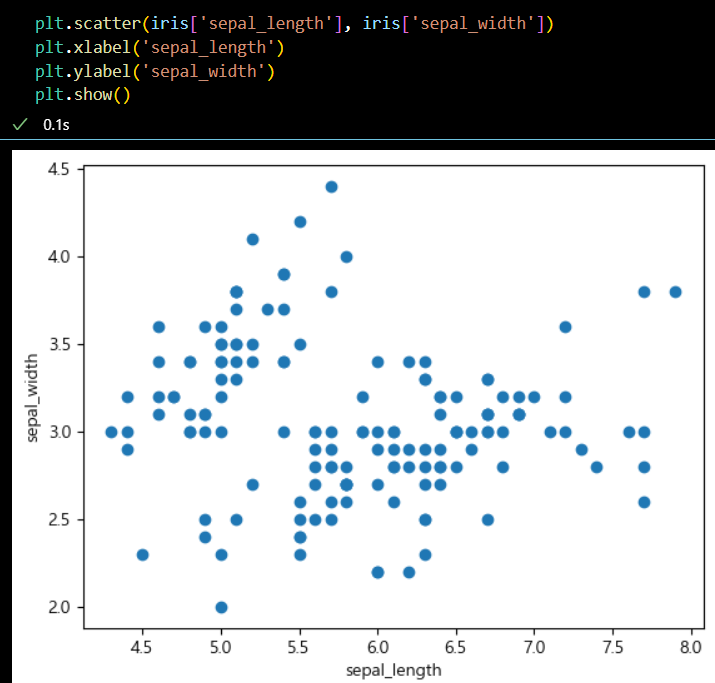
+)
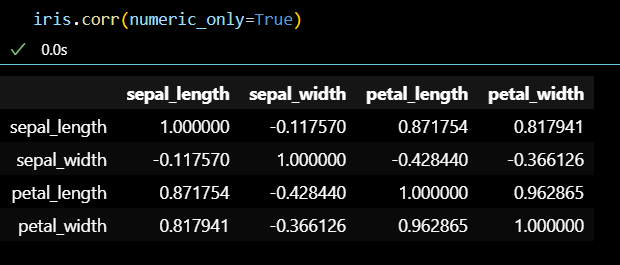
- 상관계수 구하기
# numeric_only = True 를 하게 되면, # iris 데이터셋 내 계산이 가능한 숫자 데이터들만 불러와 상관계수를 구할 수 있다. iris.corr(numeric_only=True)

커피 좋아하는 데이터 꿈나무