
개요
머신러닝 개념과 프로세스(전체 흐름)에 대한 숲 그리기
📌지도학습, 비지도학습, 강화학습
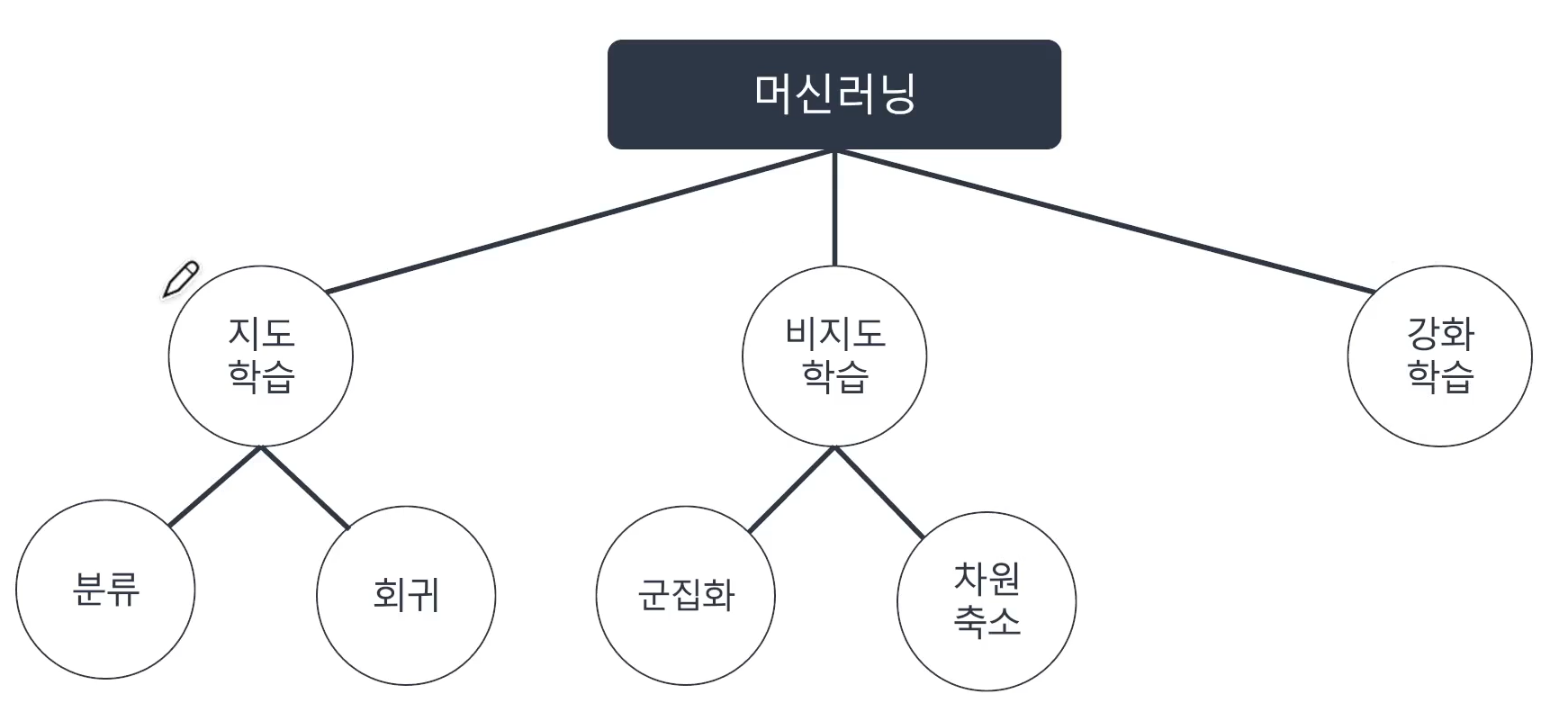
- 빅데이터 분석기사 실기 시험은 "지도학습"으로 진행
📌 전통적인 접근방식과 머신러닝 접근방식
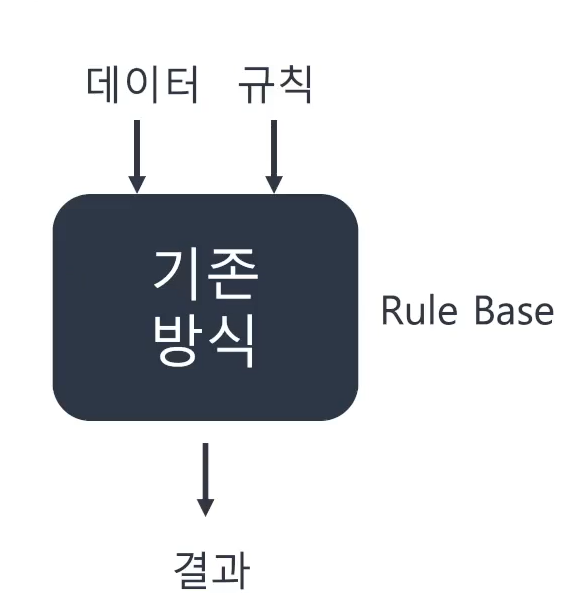
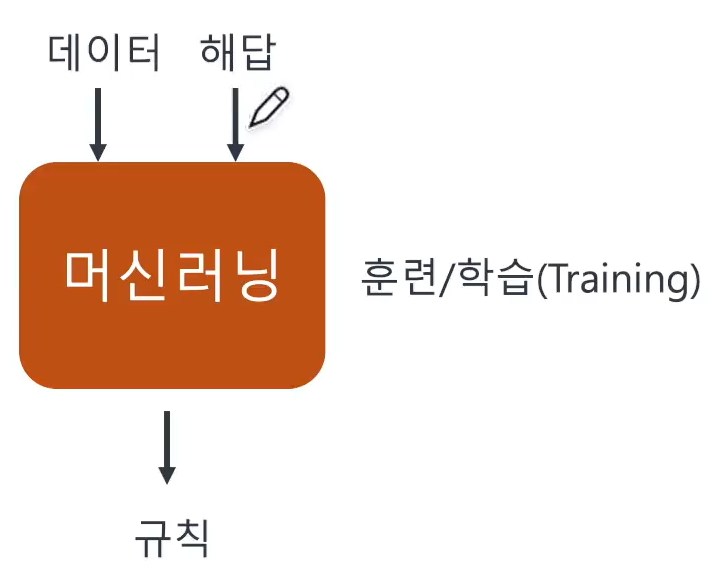
- 규칙을 만드는 것이 사람? 머신러닝? 에 대한 차이
📌 머신러닝 프로세스
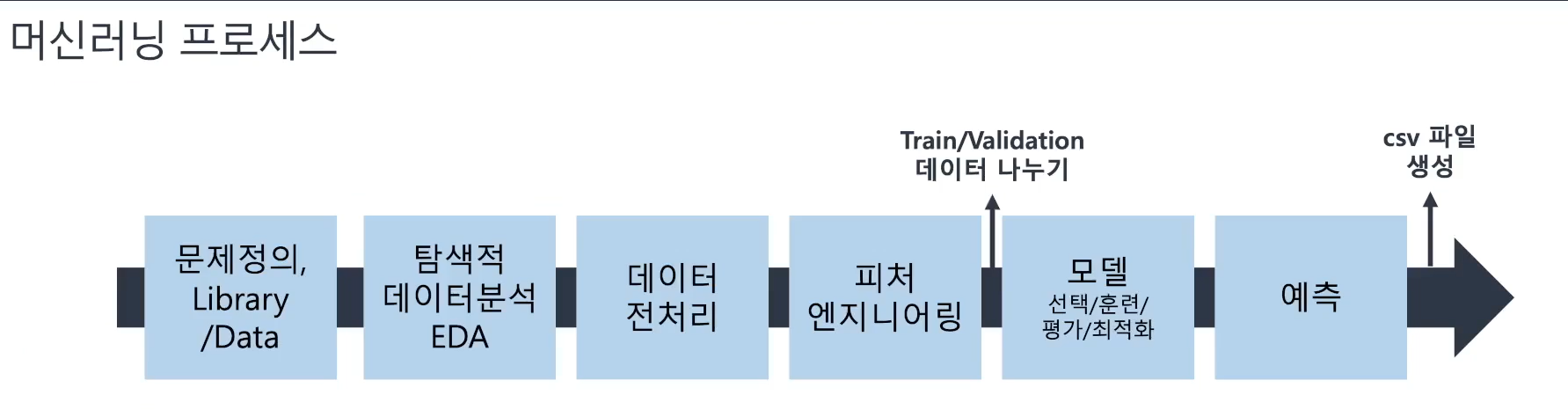
- 머신러닝 프로세스는 문제정의 ~ 예측 순으로 진행 !
📌 문제정의

- 문제가 무엇인지 확인!
- 분류인지 회귀인지
- 예측할 컬럼이 무엇인지
- 확률을 구하는 것인지, 0과 1의 값을 구하는 것인지
- MSE, MAE, RMS 인지? / AUC, ACCURACY, F1 인지?
- 확장자명, 파일명을 무엇으로 해야하는지
📌 라이브러리 및 데이터 불러오기
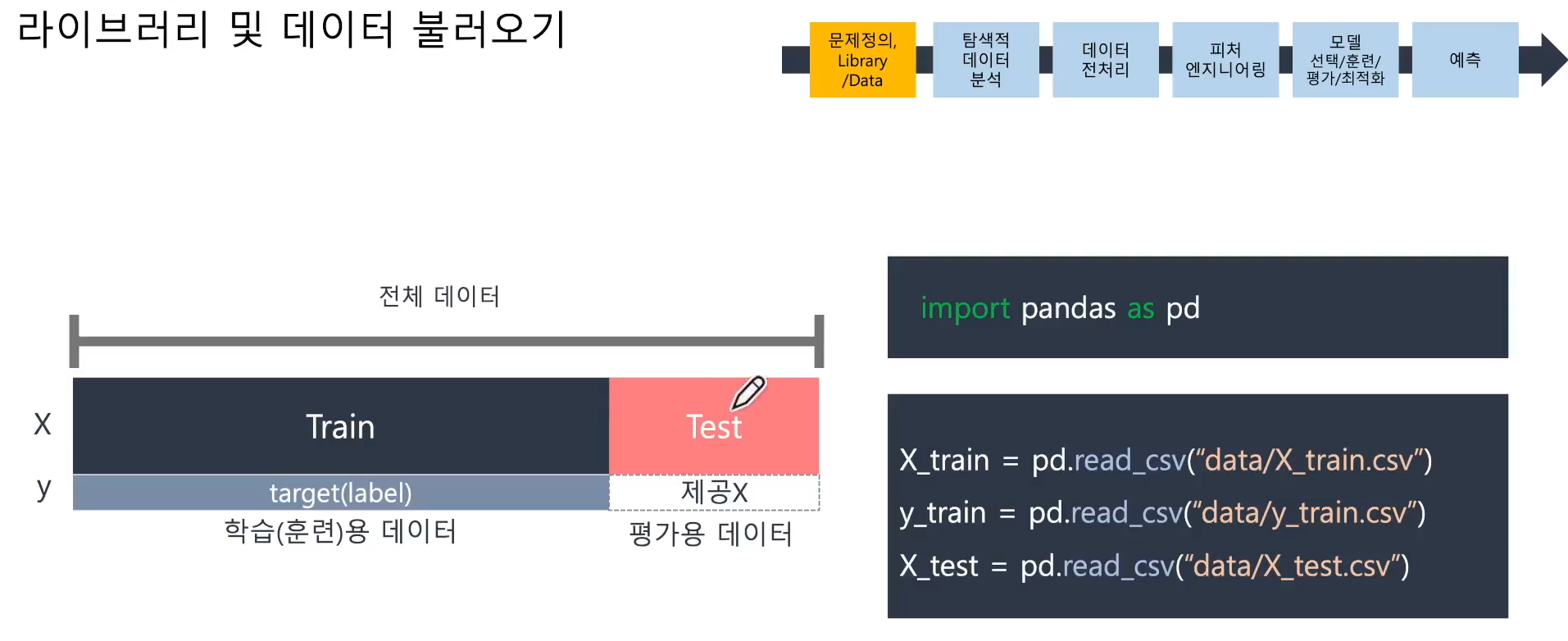
- 판다스 라이브러리를 통해 데이터 불러오기
- 훈련용(학습용)
- 평가용 데이터로 추출한 Y 데이터 - 제출
📌 탐색적 데이터 분석(EDA)
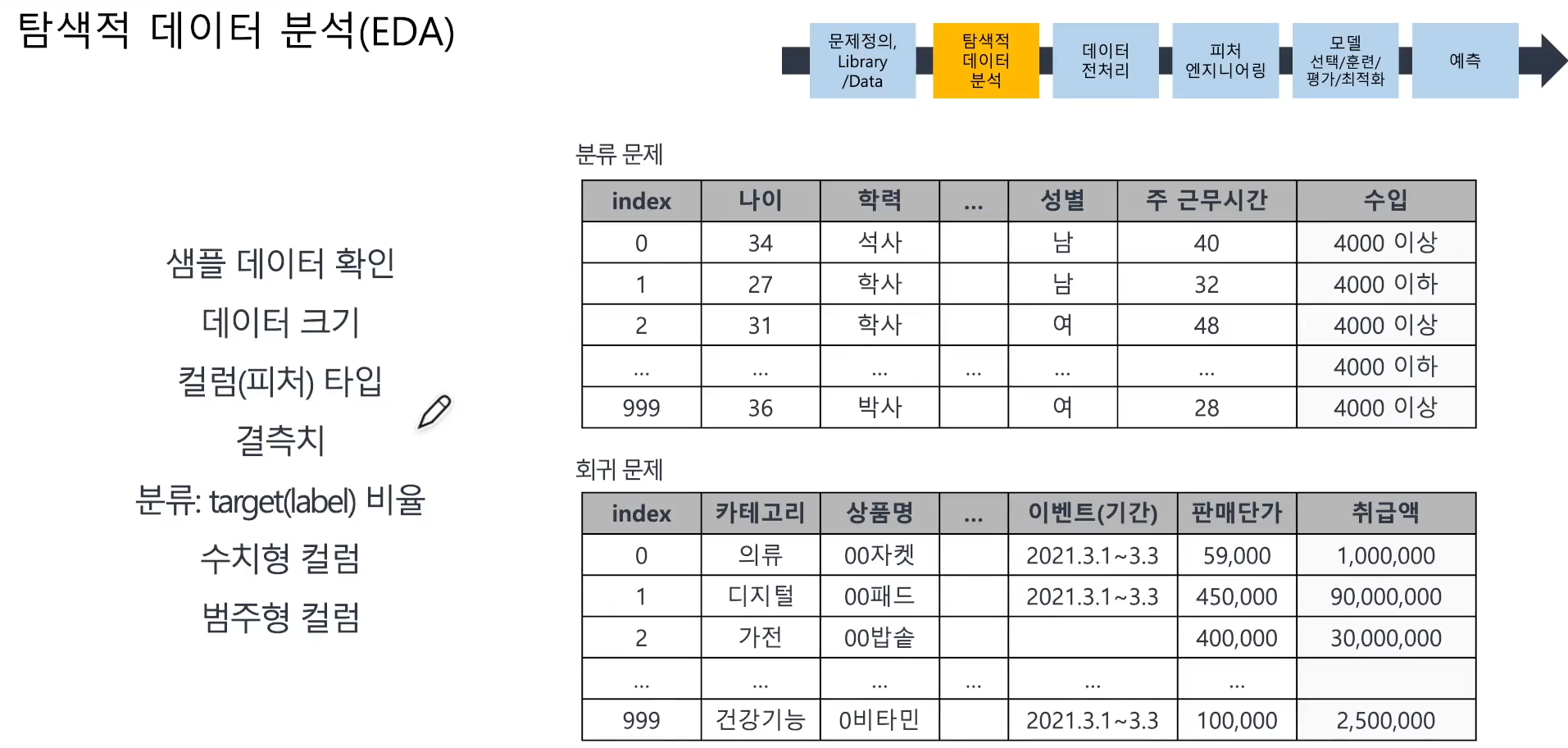
- 데이터 샘플/크기 확인
- 결측/이상 값 등 여부
- 타겟 값. 범주/수치형 컬럼 등 확인
📌 데이터 전처리
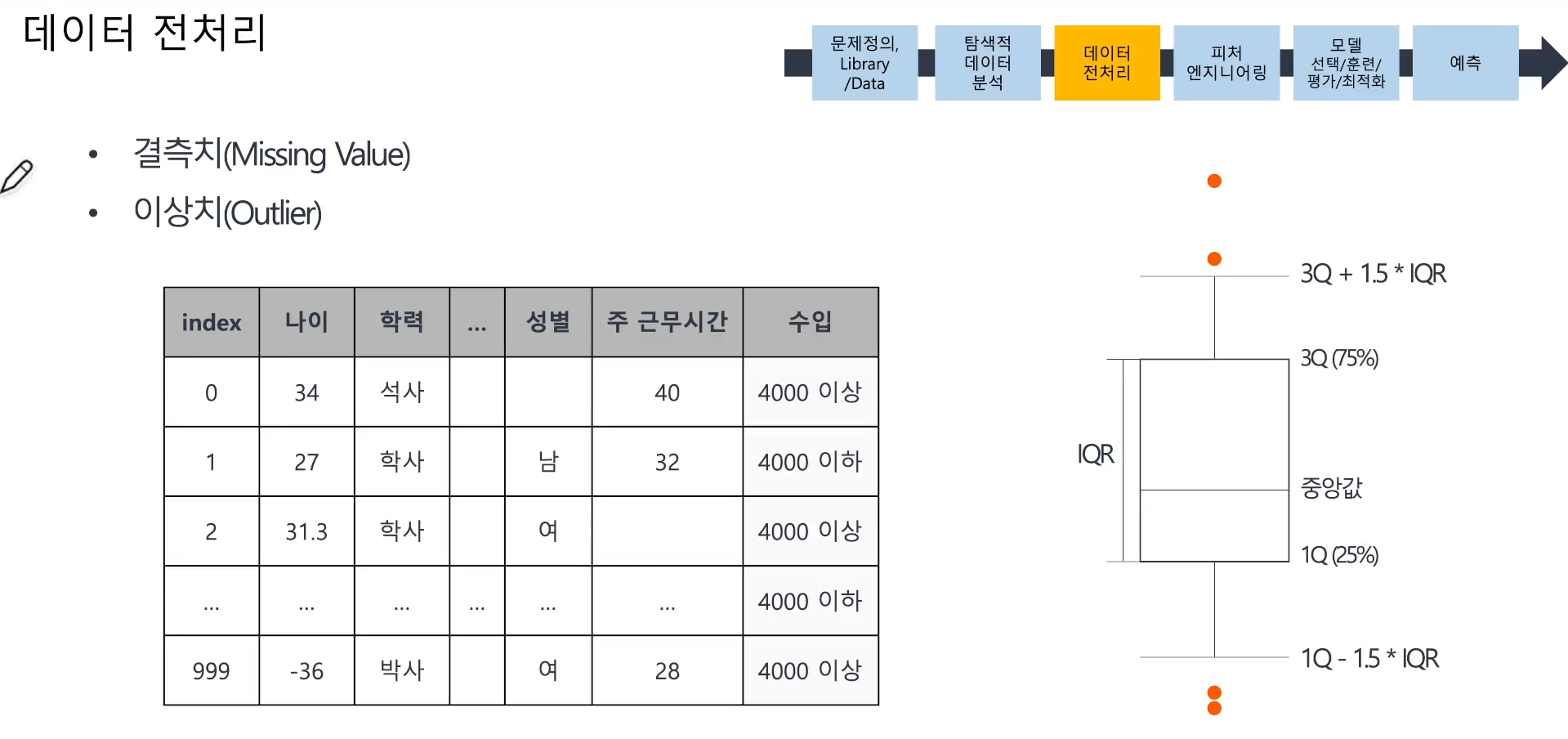
- 결측치 확인 후 제거 또는 대체
- 이상치 확인 후 제거 또는 대체
📌 피처엔지니어링
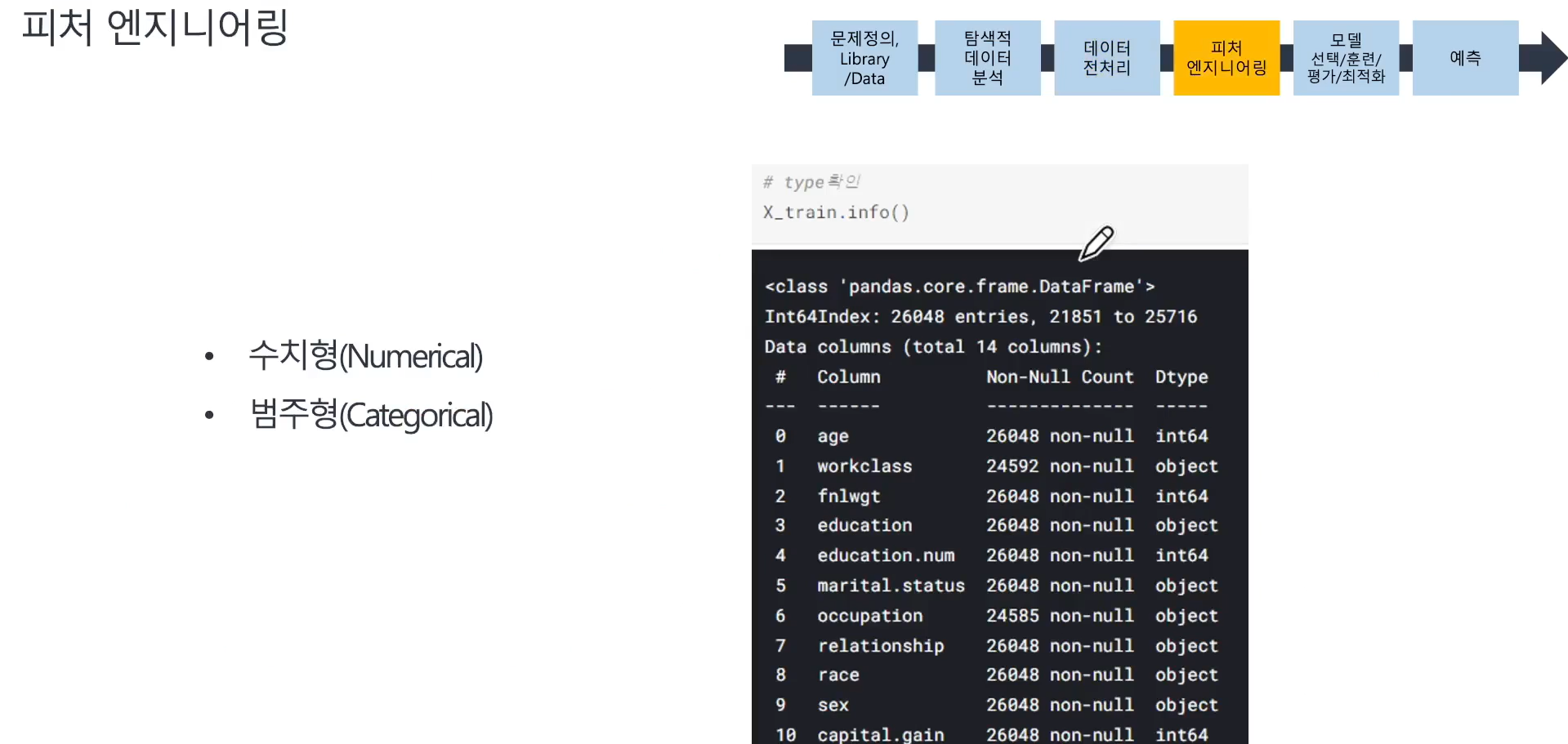
- 수치형 컬럼 (int, float 등)
- 범주형 컬럼 (object 등)
- 컬럼을 확인하고 스케일링과 인코딩 작업 진행 준비
📌 피처엔지니어링 - 수치형 컬럼
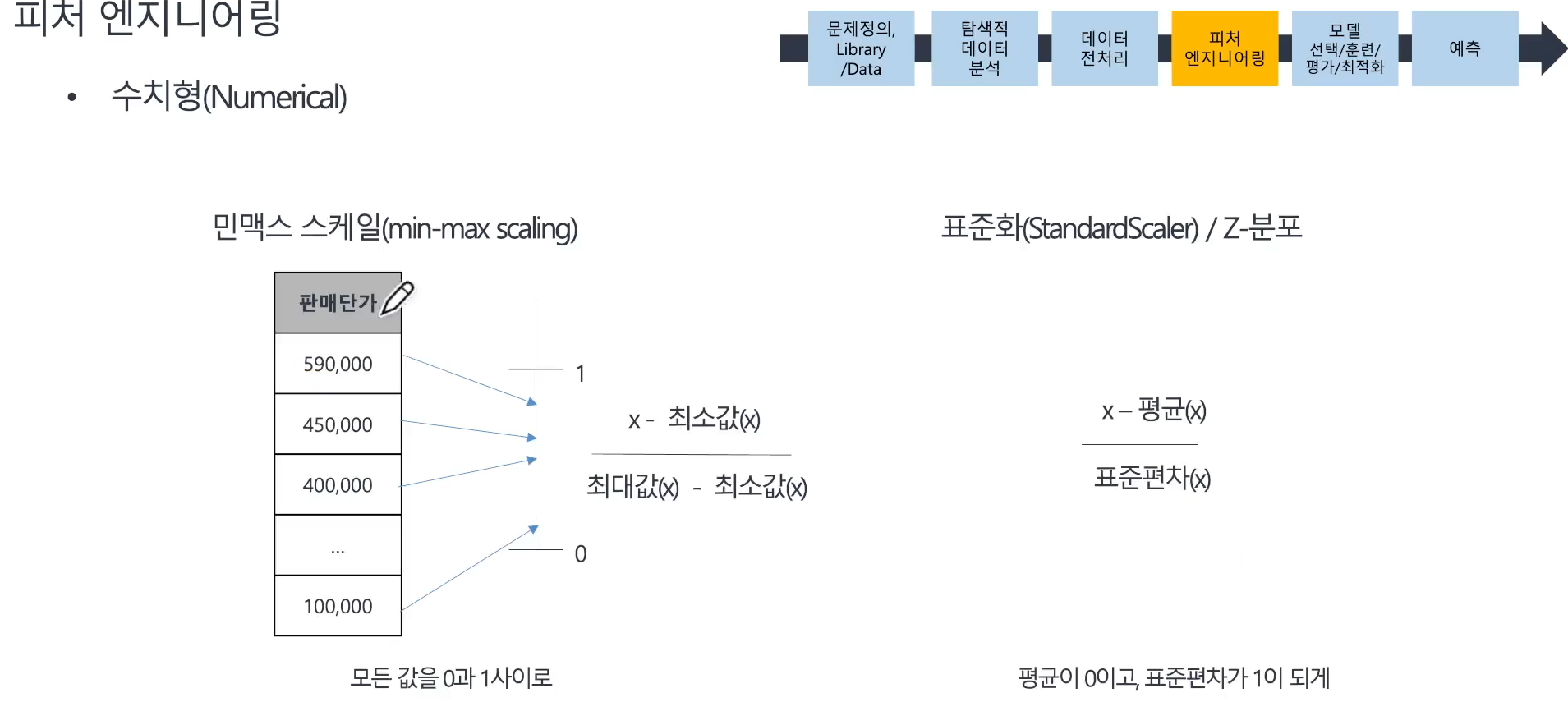
- 수치형 컬럼에 적용할 민맥스 스케일링 또는 표준화
📌 피처엔지니어링 - 범주형 컬럼
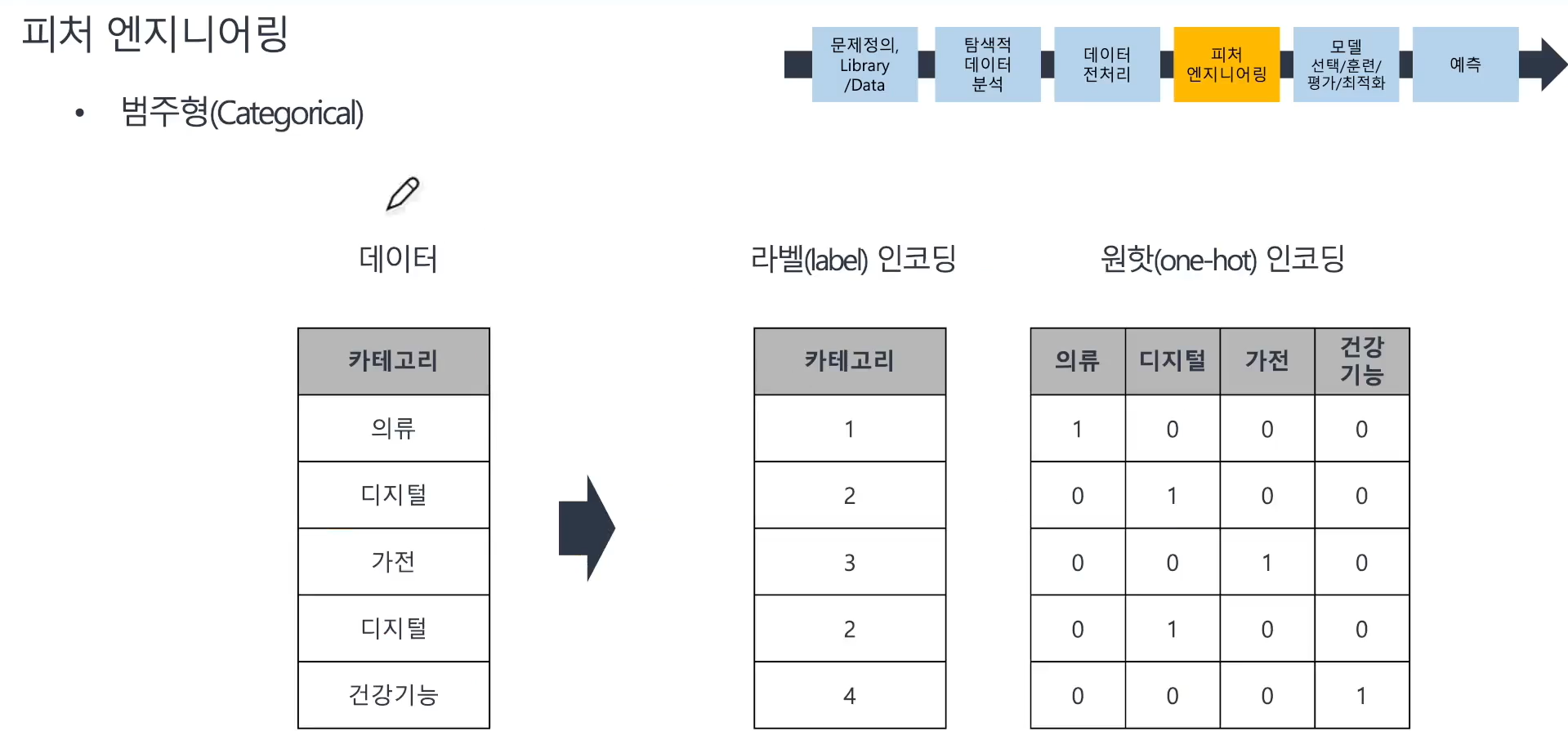
- 라벨 인코딩(데이터가 많을 때) 또는 원핫인코딩(데이터가 많지 않을 때)
- 범주형 컬럼에 적용
📌 Train과 Validation 나누기
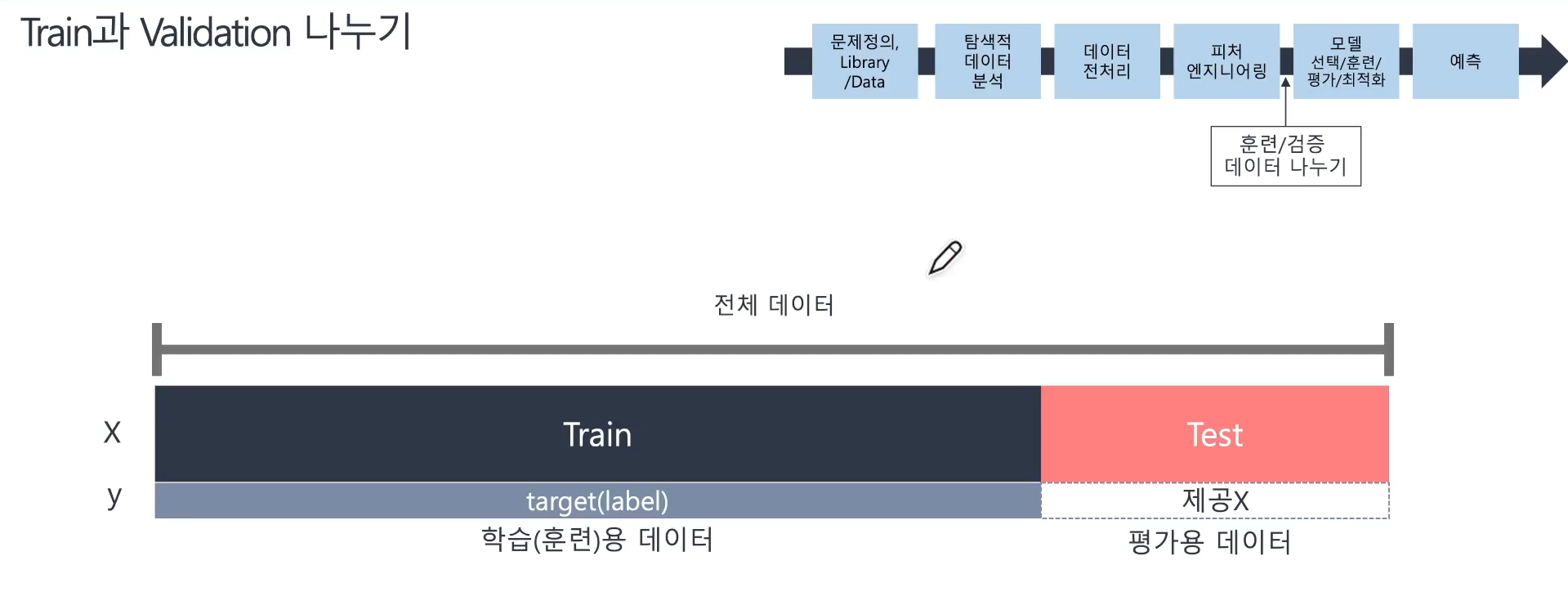
- 자체 평가를 위해 학습용(train)데이터 중 일부를 검증용 데이터로 분리
📌 모델 선택/훈련/평가/최적화
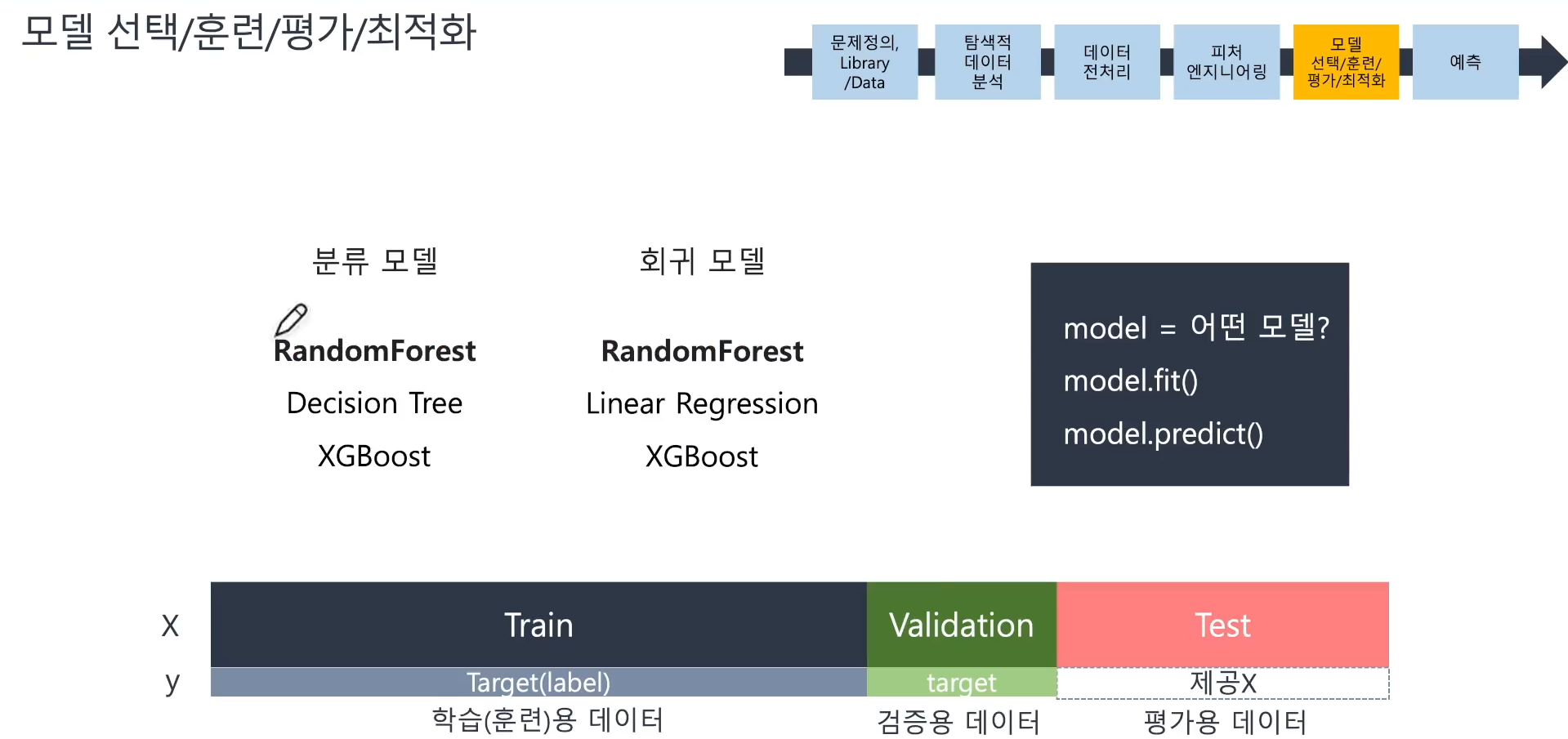
- 문제에 따라 적절한 모델 선택, 머신러닝을 실행하기 위한 3단계
- 분류인지 회귀인지 확인 !
1) 모델 불러오기
2) fit(학습 / 훈련)
3) predict(예측)
📌 예측
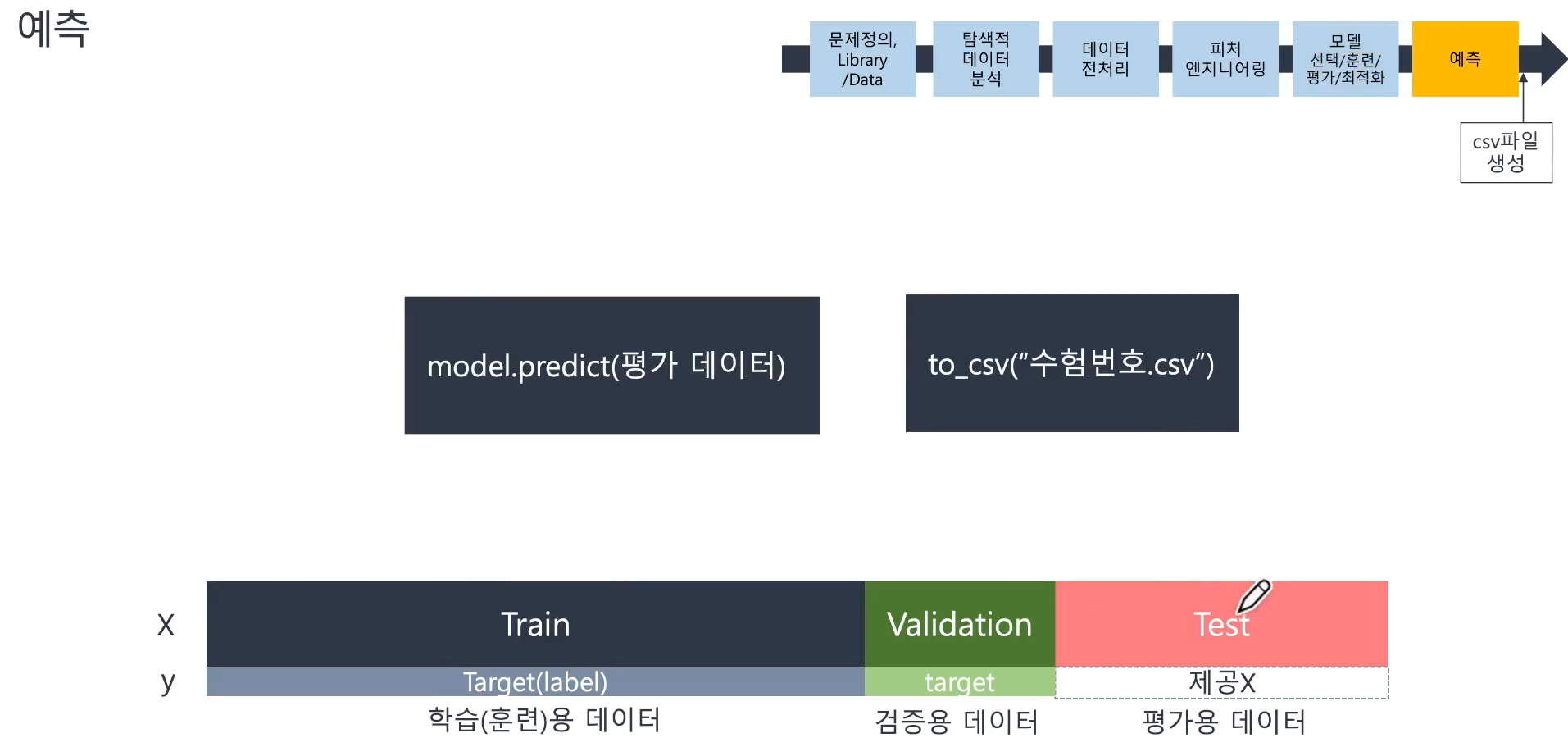
- test데이터를 활용해 예측하고 csv파일을 생성 후 제출

커피 좋아하는 데이터 꿈나무