
개요
피처 엔지니어링 (Feature Engineering)
- 스케일
- 인코딩
데이터 확인
📌 데이터 불러오기
# 데이터 불러오기 import pandas as pd X_train = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/edadata/data_atype/X_train.csv") y_train = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/edadata/data_atype/y_train.csv") X_test = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/edadata/data_atype/X_test.csv")

# 데이터 샘플 확인 X_train.head()

📌 데이터 전처리
# X_train데이터 X_train['workclass'] = X_train['workclass'].fillna(X_train['workclass'].mode()[0]) X_train['native.country'] = X_train['native.country'].fillna(X_train['native.country'].mode()[0]) X_train['occupation'] = X_train['occupation'].fillna("X") X_train['age'] = X_train['age'].fillna(int(X_train['age'].mean())) X_train['hours.per.week'] = X_train['hours.per.week'].fillna(X_train['hours.per.week'].median())# X_test데이터 X_test['workclass'] = X_test['workclass'].fillna(X_test['workclass'].mode()[0]) X_test['native.country'] = X_test['native.country'].fillna(X_test['native.country'].mode()[0]) X_test['occupation'] = X_test['occupation'].fillna("X") X_test['age'] = X_test['age'].fillna(int(X_train['age'].mean())) X_test['hours.per.week'] = X_test['hours.per.week'].fillna(X_train['hours.per.week'].median())

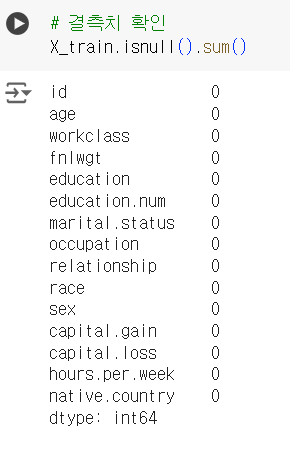
# 결측치 확인 X_train.isnull().sum()
📌 수치형 데이터 범주형 데이터 분리
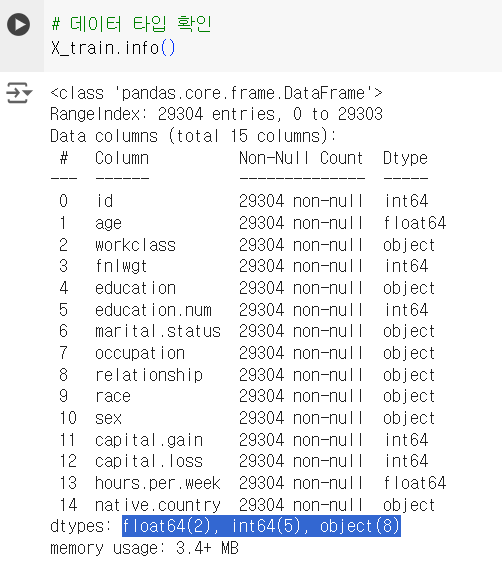
# 데이터 타입 확인 X_train.info()
.copy(): 데이터를 분리할 때 오류를 최소화하기 위해 사본으로 생성 !.select_dtypes(include = '타입'): 해당하는 타입을 포함한 컬럼 선택.select_dtypes(exclude = '타입'): 해당하지 않는 타입을 포함한 컬럼 선택
# 수치형 컬럼과 범주형 컬럼 데이터 나누기 # exclude = 'object' 범주형 데이터 타입을 제외한 컬럼을 선택해서 복사(사) # n_train = X_train.select_dtypes(exclude='object').copy() # n_test = X_test.select_dtypes(exclude='object').copy() # include = 'object' 범주형 데이터 타입만 포함한 컬럼을 선택해서 복사(사본) # c_train = X_train.select_dtypes(include='object').copy() # c_test = X_test.select_dtypes(include='object').copy()# 데이터를 매번 새롭게 불러오기 위해 함수로 제작 def get_nc_data(): X_train = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/edadata/data_atype/X_train.csv") y_train = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/edadata/data_atype/y_train.csv") X_test = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/edadata/data_atype/X_test.csv")n_train = X_train.select_dtypes(exclude='object').copy() n_test = X_test.select_dtypes(exclude='object').copy() c_train = X_train.select_dtypes(include='object').copy() c_test = X_test.select_dtypes(include='object').copy() return n_train, n_test, c_train, c_test n_train, n_test, c_train, c_test = get_nc_data() # 데이터 새로 불러오기

# 데이터 확인(수치형 데이터) n_train.head(3)

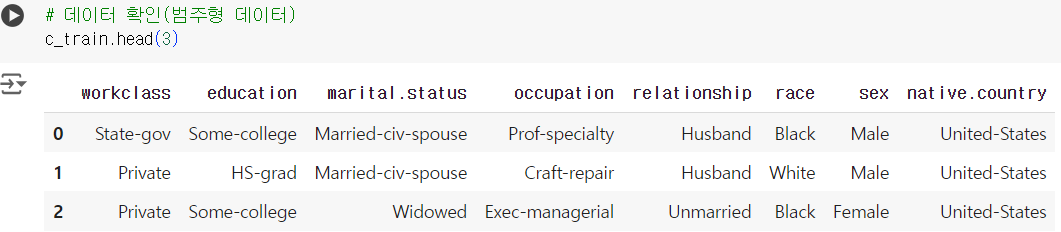
# 데이터 확인(범주형 데이터) c_train.head(3)
스케일링
- 트리기반의 모델은 입력의 스케일을 크게 신경쓰지 않아도 됨
- 선형회귀나 로지스틱 회귀 등과 같은 모델은 입력의 스케일링에 영향을 받음
📌 스케일링
# 스케일링 작업할 컬럼명 (수치형 중 id 칼럼 제외) cols = ['age', 'fnlwgt', 'education.num', 'capital.gain', 'capital.loss', 'hours.per.week']

📌 민-맥스 스케일링
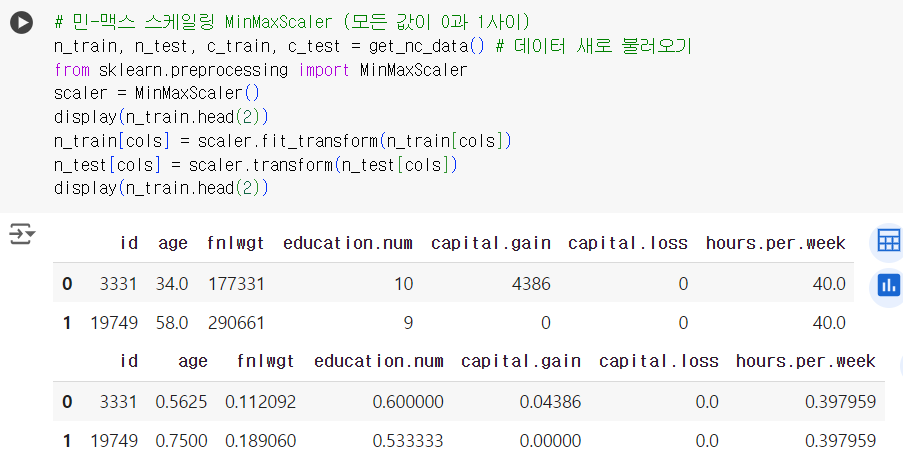
# 민-맥스 스케일링 MinMaxScaler (모든 값이 0과 1사이) n_train, n_test, c_train, c_test = get_nc_data() # 데이터 새로 불러오기 from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() display(n_train.head(2)) n_train[cols] = scaler.fit_transform(n_train[cols]) n_test[cols] = scaler.transform(n_test[cols]) display(n_train.head(2))
📌 표준화
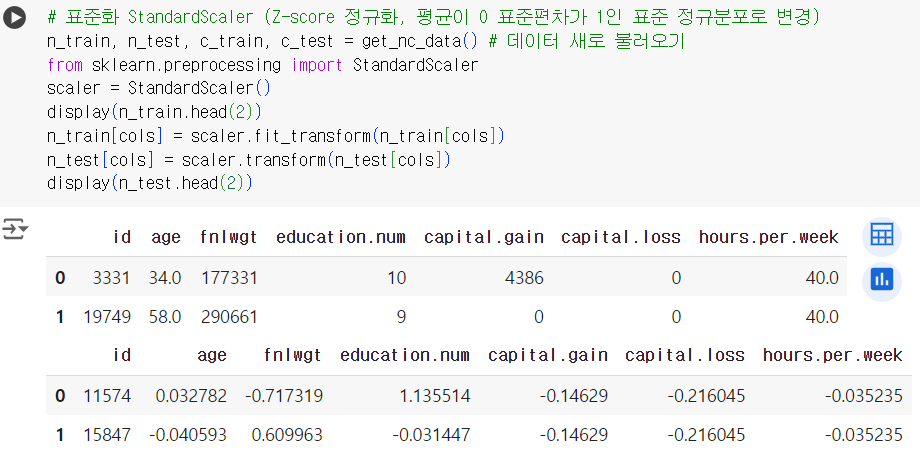
# 표준화 StandardScaler (Z-score 정규화, 평균이 0 표준편차가 1인 표준 정규분포로 변경) n_train, n_test, c_train, c_test = get_nc_data() # 데이터 새로 불러오기 from sklearn.preprocessing import StandardScaler scaler = StandardScaler() display(n_train.head(2)) n_train[cols] = scaler.fit_transform(n_train[cols]) n_test[cols] = scaler.transform(n_test[cols]) display(n_test.head(2))
📌 로버스트 스케일링
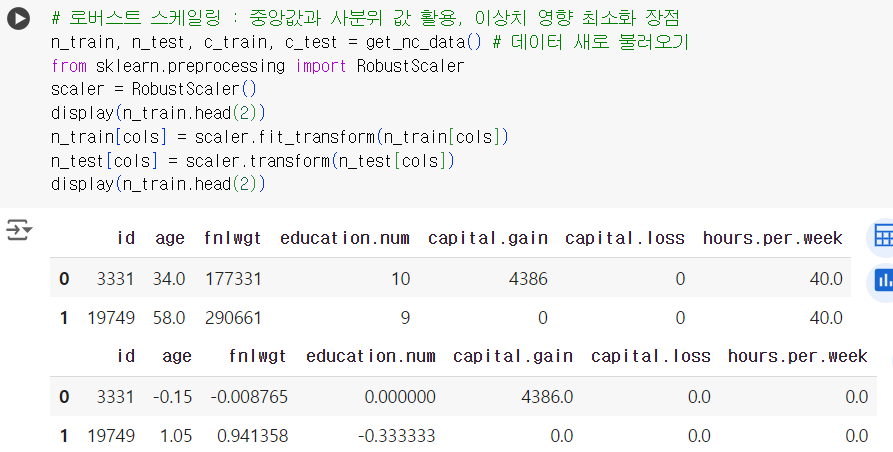
# 로버스트 스케일링 : 중앙값과 사분위 값 활용, 이상치 영향 최소화 장점 n_train, n_test, c_train, c_test = get_nc_data() # 데이터 새로 불러오기 from sklearn.preprocessing import RobustScaler scaler = RobustScaler() display(n_train.head(2)) n_train[cols] = scaler.fit_transform(n_train[cols]) n_test[cols] = scaler.transform(n_test[cols]) display(n_train.head(2))
📌 로그 변환
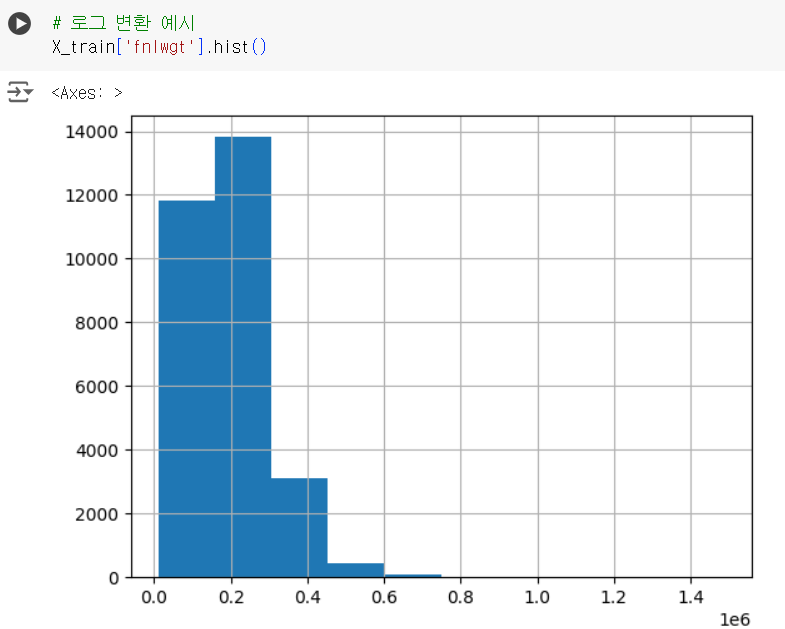
# 로그 변환 예시 X_train['fnlwgt'].hist()
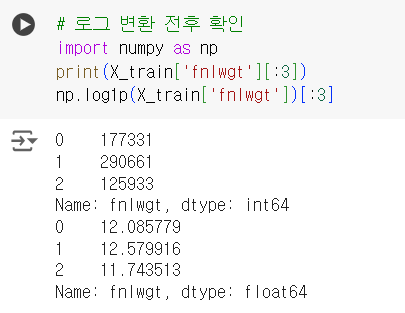
# 로그 변환 전후 확인 import numpy as np print(X_train['fnlwgt'][:3]) np.log1p(X_train['fnlwgt'])[:3]
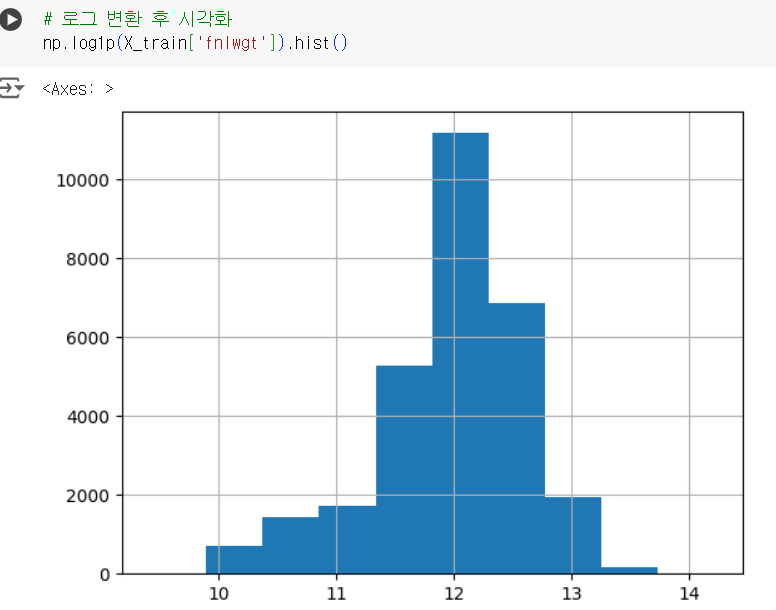
# 로그 변환 후 시각화 np.log1p(X_train['fnlwgt']).hist()
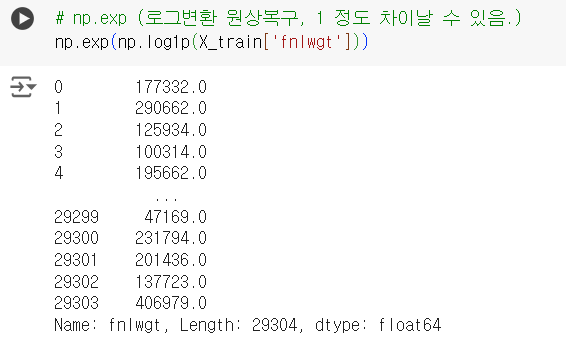
# np.exp (로그변환 원상복구, 1 정도 차이날 수 있음.) np.exp(np.log1p(X_train['fnlwgt']))
인코딩
- 라벨(label) 인코딩
- 원핫(one-hot) 인코딩
📌 인코딩
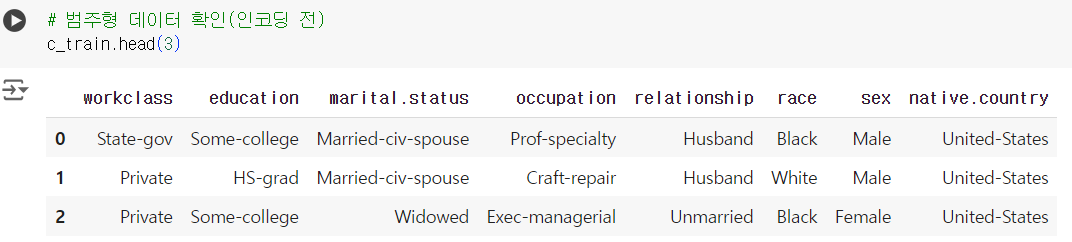
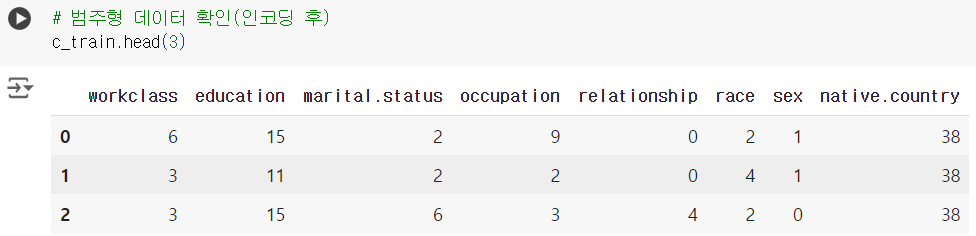
# 범주형 데이터 확인(인코딩 전) c_train.head(3)
# object 컬럼명 cols = list(X_train.columns[X_train.dtypes == object]) # cols = ['workclass','education','marital.status','occupation','relationship','race','sex','native.country']

📌 라벨(label) 인코딩
# 라벨 인코딩 n_train, n_test, c_train, c_test = get_nc_data() # 데이터 새로 불러오기 from sklearn.preprocessing import LabelEncoder for col in cols: le = LabelEncoder() c_train[col] = le.fit_transform(c_train[col]) c_test[col] = le.transform(c_test[col])

📌 원핫(one-hot) 인코딩
# 원핫 인코딩 import pandas as pd n_train, n_test, c_train, c_test = get_nc_data() # 데이터 새로 불러오기 display(c_train.head(3)) c_train = pd.get_dummies(c_train[cols]) c_test = pd.get_dummies(c_test[cols]) display(c_train.head(3))
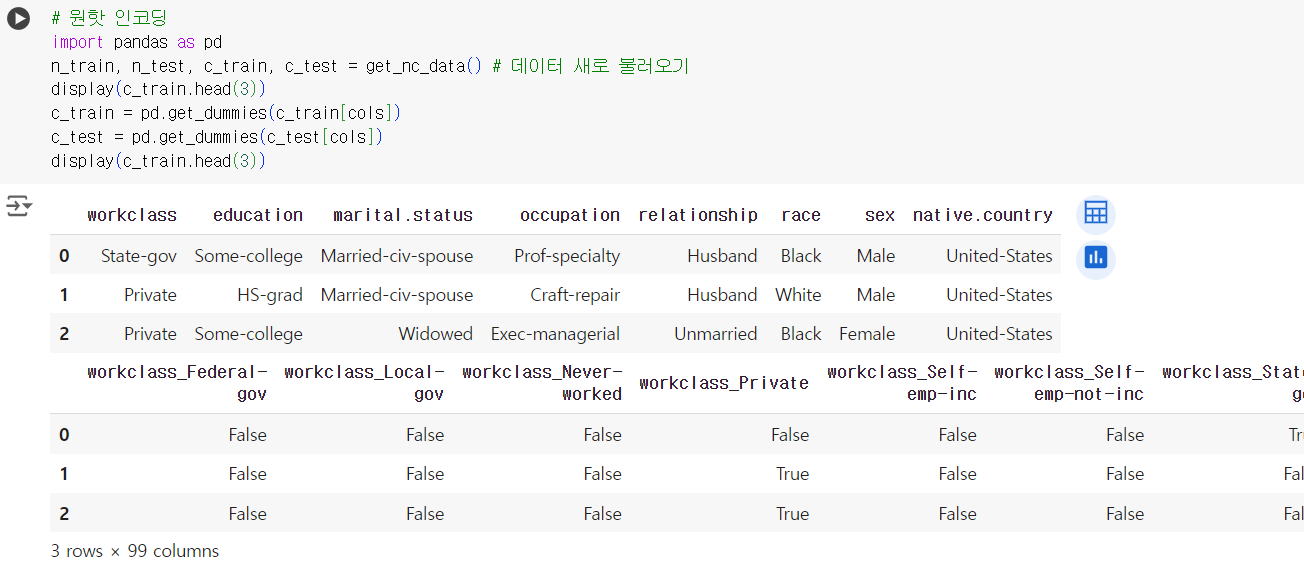
데이터 병합 및 정리
📌 데이터 합치기
# 분리한 데이터 다시 합침 n_train, n_test, c_train, c_test = get_nc_data() # 데이터 새로 불러오기 X_train = pd.concat([n_train, c_train], axis = 1) X_test = pd.concat([n_test, c_test], axis = 1) print(X_train.shape, X_test.shape) X_train.head()

📌 train과 test데이터를 합쳐서 인코딩 후 분리하기
# 데이터 새로 불러오기 import pandas as pd X_train = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/edadata/data_atype/X_train.csv") y_train = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/edadata/data_atype/y_train.csv") X_test = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/edadata/data_atype/X_test.csv")

# train, test 합쳐서 인코딩 cols = list(X_train.columns[X_train.dtypes == object]) print(X_train.shape, X_test.shape) all_df = pd.concat([X_train, X_test]) all_df = pd.get_dummies(all_df[cols])# 후 분리하기 line = int(X_train.shape[0]) X_train = all_df.iloc[:line,:].copy() X_train X_test = all_df.iloc[line:,:].copy() X_test print(X_train.shape, X_test.shape)

📌 정리
- 수치형 데이터와 범주형 데이터로 분리
- 수치형 데이터는 민맥스 스케일링, 범주형 데이터는 라벨 인코딩 진행
- 분리했던 데이터 합치기
- 데이터 확인
# 데이터 분리 n_train, n_test, c_train, c_test = get_nc_data() # 데이터 새로 불러오기
# 수치형 - 민맥스 스케일링 cols = ['age', 'fnlwgt', 'education.num', 'capital.gain', 'capital.loss', 'hours.per.week'] from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() n_train[cols] = scaler.fit_transform(n_train[cols]) n_test[cols] = scaler.transform(n_test[cols])

# 라벨 인코딩 cols = ['workclass', 'education', 'marital.status', 'occupation', 'relationship', 'race', 'sex', 'native.country'] from sklearn.preprocessing import LabelEncoder for col in cols: le = LabelEncoder() c_train[col] = le.fit_transform(c_train[col]) c_test[col] = le.transform(c_test[col])

# 분리한 데이터 다시 합침 X_train = pd.concat([n_train, c_train], axis=1) X_test = pd.concat([n_test, c_test], axis=1) print(X_train.shape, X_test.shape)

# 데이터 확인 display(X_train.head())


커피 좋아하는 데이터 꿈나무