
개요
데이터 전처리
- 결측치 처리
- 이상치 처리
데이터 확인
📌 데이터 불러오기
import pandas as pd X_train = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/edadata/data_atype/X_train.csv") y_train = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/edadata/data_atype/y_train.csv") X_test = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/edadata/data_atype/X_test.csv")

📌 데이터 샘플

📌 결측치 컬럼별 확인
# 결측치 컬럼 확인 X_train.isnull().sum()
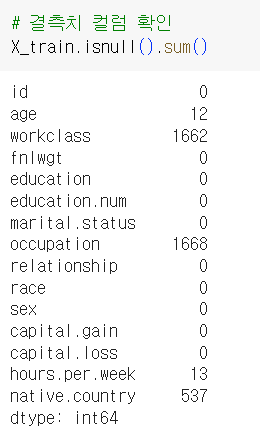
- 결측치가 있는 컬럼 :
age,workclass,occupation,hours.per.week,native.country
📌 데이터 타입
# 데이터 타입 확인 X_train.info()
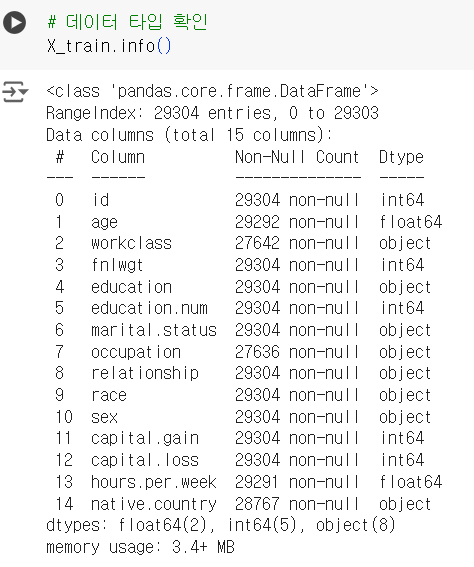
▼ 결측치가 있는 컬럼 분류
-
범주형(
object) 컬럼 :
workclass,occupation,native.country -
수치형(
int,float) 컬럼 :
age,hours.per.week
📌 오브젝트 컬럼 결측치 확인
- 결측치가 있는 오브젝트 컬럼별 고유값 확인
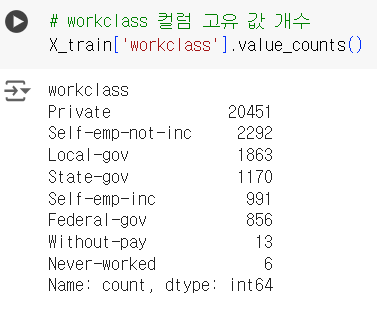
# workclass 컬럼 고유 값 개수 X_train['workclass'].value_counts()
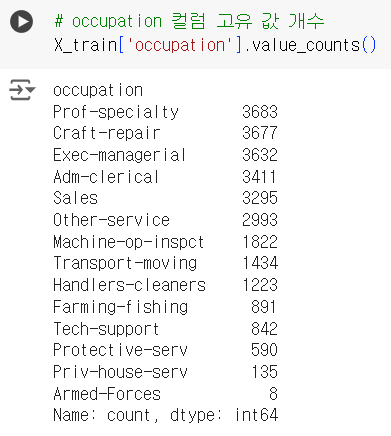
# occupation 컬럼 고유 값 개수 X_train['occupation'].value_counts()
# native.country 컬럼 고유 값 개수 X_train['native.country'].value_counts()

범주형 컬럼 결측치
- 삭제
- 최빈값
- 없는값
📌 범주형 컬럼 결측치
# X_train과 X_test 데이터 크기 확인 X_train.shape, X_test.shape

# 결측치 확인 X_train.isnull().sum()
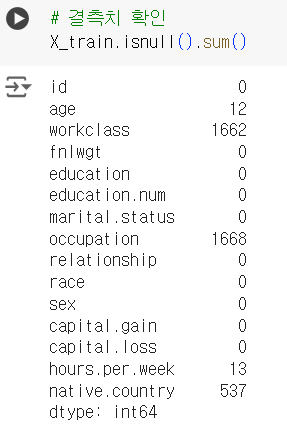
📌 결측치 삭제 : 데이터(행)
dropna()(axis = 0 주의!)
# 결측치가 있는 데이터(행) 전체 삭제 및 확인 dropna() #기본값 axis=0 df = X_train.dropna() print(df.isnull().sum()) print(df.shape)
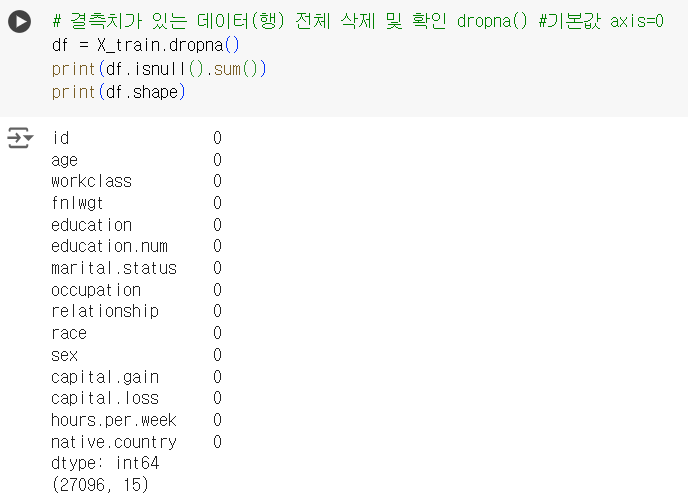
📌 결측치 삭제 : 특정 컬럼에 결측치가 있으면 데이터(행) 삭제
subset = []
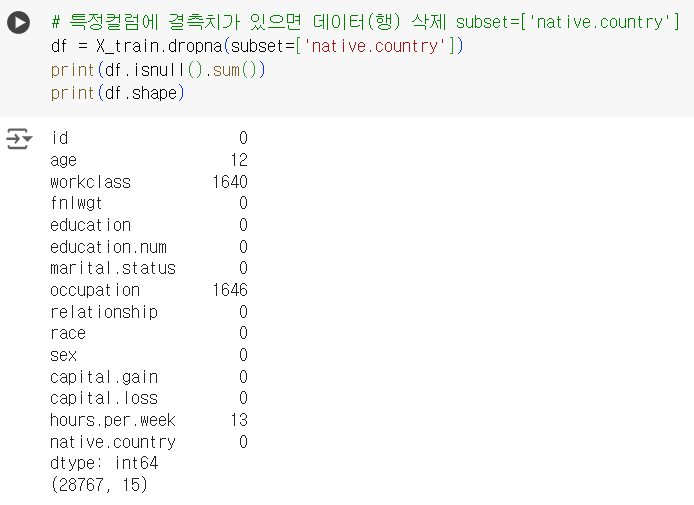
# 특정컬럼에 결측치가 있으면 데이터(행) 삭제 subset=['native.country']
df = X_train.dropna(subset=['native.country'])
print(df.isnull().sum())
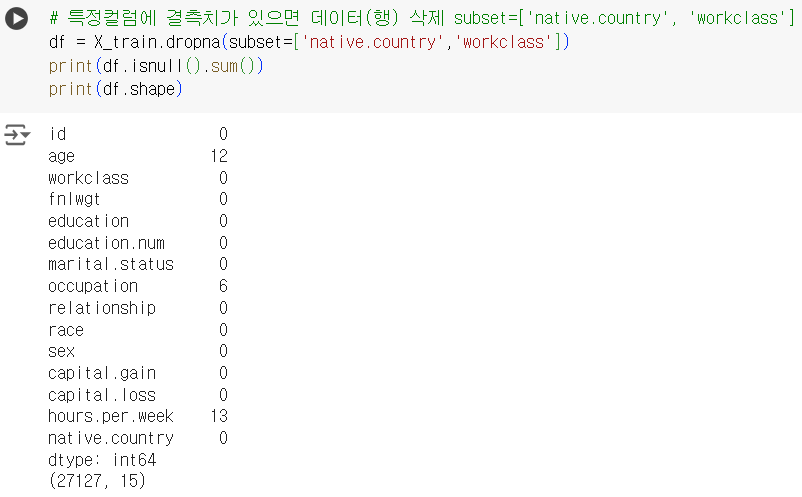
print(df.shape)📌 결측치 삭제 : 특정 컬럼(n개) 에 결측치가 있으면 데이터(행) 삭제
# 특정컬럼에 결측치가 있으면 데이터(행) 삭제 subset=['native.country', 'workclass'] df = X_train.dropna(subset=['native.country','workclass']) print(df.isnull().sum()) print(df.shape)
📌 결측치 삭제 : 결측치 있는 컬럼 모두 삭제
# 결측치가 있는 컬럼 삭제 dropna(axis=1) df = X_train.dropna(axis=1) df.isnull().sum()
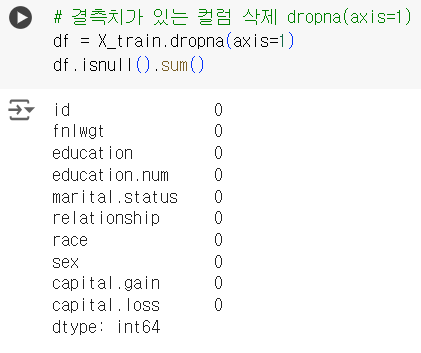
📌 결측치 삭제 : 결측치가 많은 특정 컬럼 삭제
# 결측치가 많은 특정 컬럼 삭제 drop(['workclass'], axis=1) df = X_train.drop(['workclass'], axis = 1) df.isnull().sum()
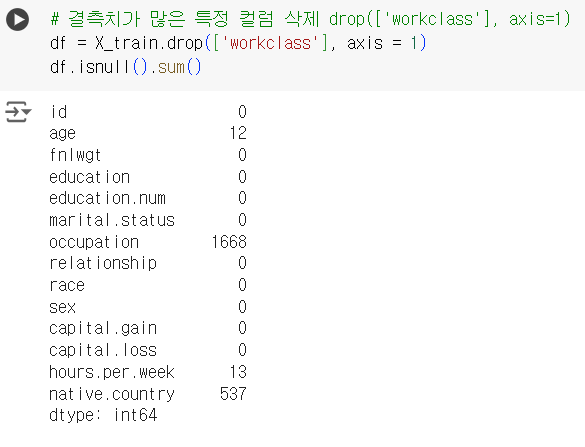
📌 중복 데이터 삭제
# 중복값 제거 drop_duplicates() print(X_train.shape) df = X_train.drop_duplicates() print(df.shape) # df.drop_duplicates(subset = ['A']) # df.drop_duplicates(subset = ['A', 'B'], keep = 'last') # 기본적으로 앞의 값을 살리지만 last 설정 시 뒤의 값을 살린다.

📌 결측치 채우기 - 최빈값
fillna()
# 최빈값 m = X_train['workclass'].mode()[0] print(m) X_train['workclass'] = X_train['workclass'].fillna(m) X_train.isnull().sum()
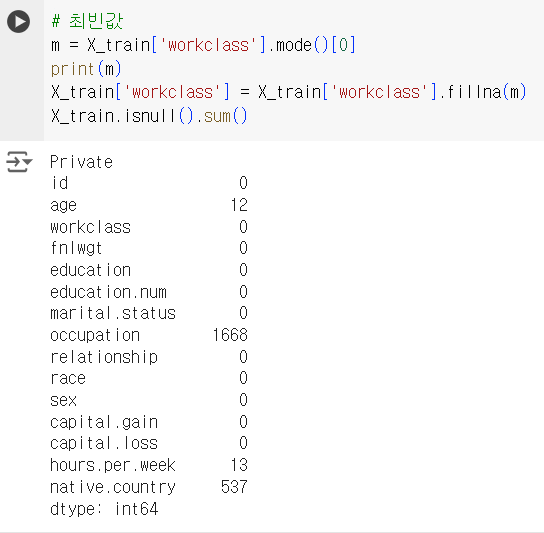
📌 결측치 채우기 - 새로운 카테고리 생성
# 결측값을 새로운 카테고리로 생성 X_train['occupation'] X_train['occupation'] = X_train['occupation'].fillna('nothing') X_train.isnull().sum()
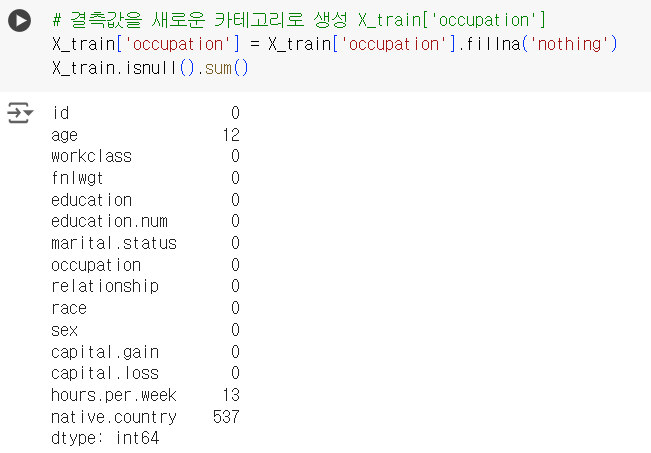
📌 결측치 처리 적용
-
결측치가 있는 범주형 컬럼들에 결측치 처리 적용

-
데이터 불러오기

# 데이터 불러오기
X_train = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/edadata/data_atype/X_train.csv")
y_train = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/edadata/data_atype/y_train.csv")
X_test = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/edadata/data_atype/X_test.csv")- 결측치를 정리할 때는
train데이터와test데이터를 함께 해주는 습관 들이기! - 결측치 채우기 적용

# X_train데이터
X_train['workclass'] = X_train['workclass'].fillna(X_train['workclass'].mode()[0])
X_train['native.country'] = X_train['native.country'].fillna(X_train['native.country'].mode()[0])
X_train['occupation'] = X_train['occupation'].fillna('nothing')
# X_test데이터 X_test['workclass'] = X_test['workclass'].fillna(X_test['workclass'].mode()[0]) X_test['native.country'] = X_test['native.country'].fillna(X_test['native.country'].mode()[0]) X_test['occupation'] = X_test['occupation'].fillna('nothing')

- 결측치 확인
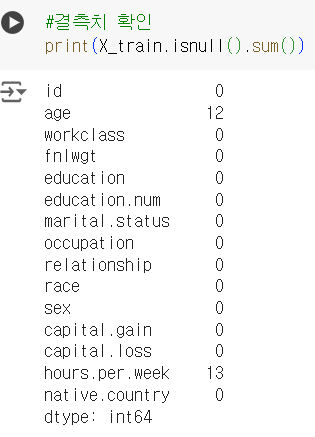
#결측치 확인
print(X_train.isnull().sum())수치형 컬럼 결측치
- 평균값
- 중앙값
- 최대값
- 최소값
- 그룹별 00 값
📌 수치형 컬럼 결측치
-
age 컬럼과 hours.per.week 컬럼의(수치형 컬럼) 결측치만 남아있는 것을 확인.
-
결측치 확인
#결측치 확인
print(X_train.isnull().sum())📌 평균, 중앙, 최대, 최소 값 확인
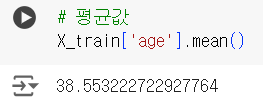
- 평균값
# 평균값 X_train['age'].mean()
- 중앙값
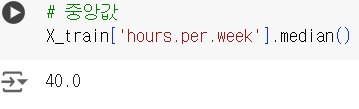
# 중앙값
X_train['hours.per.week'].median()- 최대값
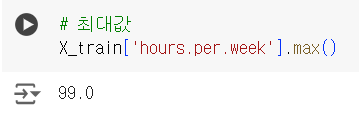
# 최대값
X_train['hours.per.week'].max()- 최소값
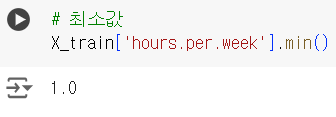
# 최소값
X_train['hours.per.week'].min()📌 결측치 채우기 : 평균
# age 컬럼 평균값으로 채우기 avgage = int(X_train['age'].mean()) print("채우는 값:", avgage) X_train['age'] = X_train['age'].fillna(avgage) X_test['age'] = X_test['age'].fillna(avgage)

📌 결측치 채우기 : 중앙
# 주당 근무시간 중앙값으로 채우기 medwork = int(X_train['hours.per.week'].median()) print("채우는 값:", medwork) X_train['hours.per.week'] = X_train['hours.per.week'].fillna(medwork) X_test['hours.per.week'] = X_test['hours.per.week'].fillna(medwork)

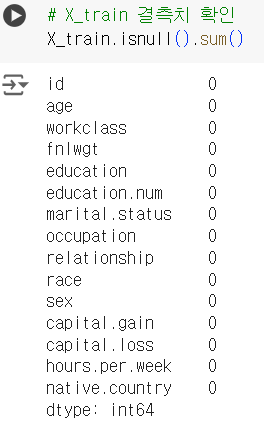
📌 결측치 채우기 결과
# X_train 결측치 확인 X_train.isnull().sum()
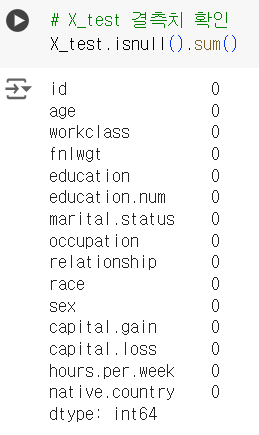
# X_test 결측치 확인 X_test.isnull().sum()
이상치
이상한 값 삭제
📌 이상치 처리
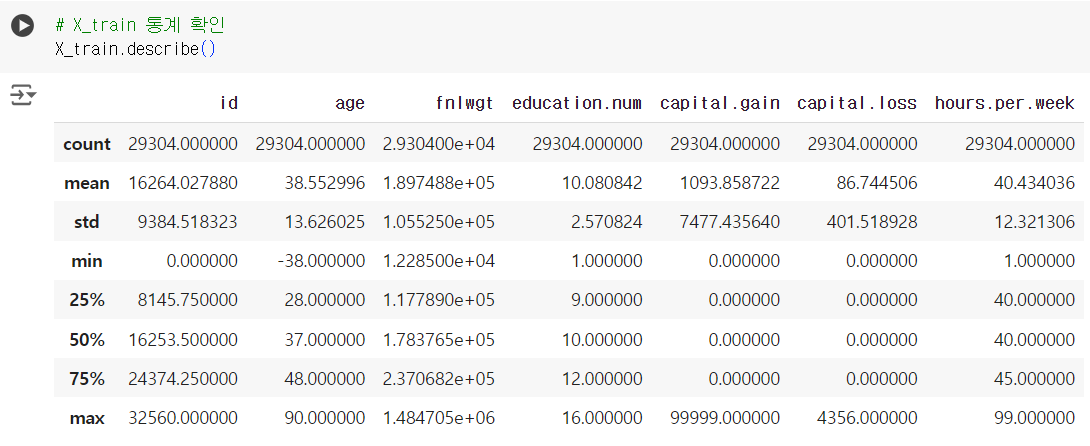
- 데이터 확인
# X_train 통계 확인 X_train.describe()
📌 음수인 데이터 삭제
- 'age' 칼럼의 데이터가 0보다 작거나 클때
# age가 음수인 데이터 X_train[X_train['age']<=0]

- 'age' 칼럼의 데이터가 1보다 클때
# age가 1이상인 데이터만 살림 print(X_train.shape) X_train = X_train[X_train['age']>0] print(X_train.shape)

📌 IQR로 이상치 확인
- IQR의 1.5배보다 크거나 작은 이상치를 확인
# IQR로 확인 cols = ['age','fnlwgt','education.num', 'capital.gain', 'capital.loss', 'hours.per.week'] for col in cols: Q1 = X_train[col].quantile(.25) Q3 = X_train[col].quantile(.75) IQR = Q3 - Q1 min_iqr = Q1-1.5*IQR max_iqr = Q3+1.5*IQR cnt=sum((X_train[col] < min_iqr) | (X_train[col] > max_iqr)) print(f'{col}의 이상치:{cnt}개 입니다.')

📌 전처리 주의 사항

이상치, 결측치에 대해 test 데이터(행) 삭제 불가
예) test 데이터 100개가 주어지고 100개로 평가를 하는데 임의로 10개를 삭제해버리면 채점을 할 수가 없음
train 데이터는 학습/훈련용 데이터임. 데이터가 많을 경우 임의로 소수 데이터(행) 삭제해도 무방함
test, train 컬럼은 삭제/추가 가능. 단, train과 컬럼수와 명이 일치해야 함 (y(target) 제외)

커피 좋아하는 데이터 꿈나무