
개요
머신러닝(
분류) 실행!
📌 머신러닝 프로세스 정리
- 문제정의, 라이브러리/데이터 불러오기
- 탐색적 데이터 분석 (EDA)
- 데이터 전처리
- 피처엔지니어링
- (Train/Validation 나누기)
- 모델 선택/훈련/평가/최적화
- 예측
- (csv 생성)
📌 문제 #1
1. 베이스라인
- 문제정의, 라이브러리 및 데이터 불러오기
- 데이터 전처리 (단순 일괄 처리)
- 모델 선택, 훈련
- 평가
문제 1
- "<= 50K -> 0"
- "> 50K -> 1"
- 평가: 정확도
📌 데이터 불러오기 & EDA
문제1
- "<= 50K -> 0"
- "> 50K -> 1"
- 평가: 정확도
# 라이브러리 및 데이터 불러오기 # from google.colab import drive # drive.mount('/content/drive') # 데이터 불러오기 import pandas as pd X_train = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/edadata/data_atype/X_train.csv") y_train = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/edadata/data_atype/y_train.csv") X_test = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/edadata/data_atype/X_test.csv")

# 데이터 크기 X_train.shape, X_test.shape, y_train.shape

# 데이터 샘플 X_train.head(3)

# 타겟 수 확인 # 타겟이 무엇인지 모를 때는 먼저 y_train 데이터를 불러와 탐색해야 함! y_train['income'].value_counts()

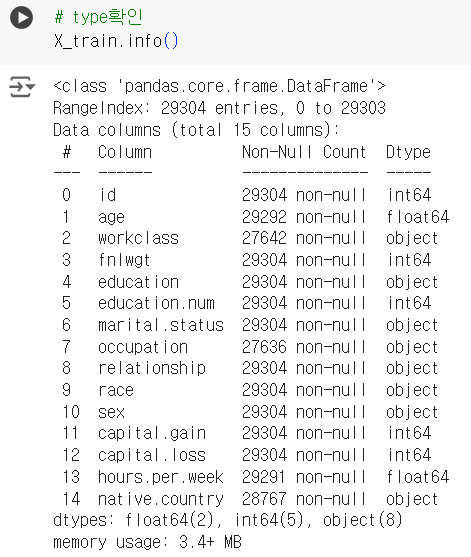
# type확인 X_train.info()
📌 컬럼 선택 (수치형 데이터)
# 수치형 데이터 cols = ['age','fnlwgt','education.num','capital.gain','capital.loss','hours.per.week']
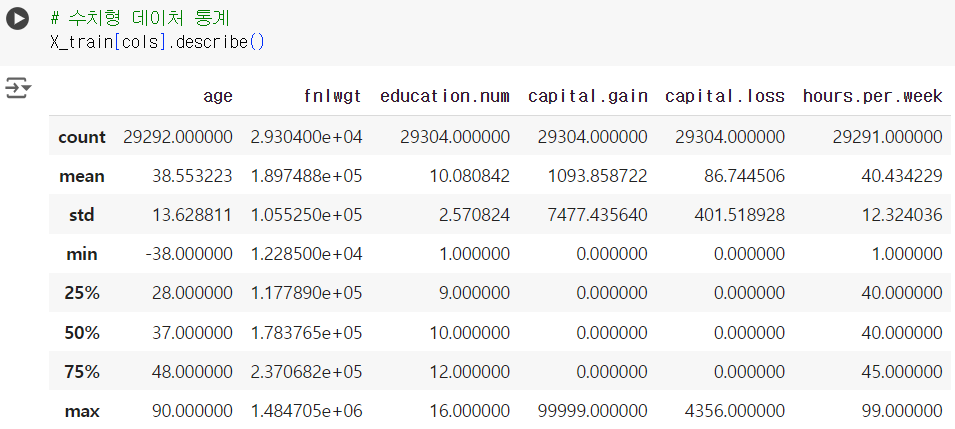
# 수치형 데이처 통계 X_train[cols].describe()
📌 결측치 간단 처리
# 결측값 X_train[cols].isnull().sum()

# 간단한 결측치 처리 # 결측치 처리 시 train, test를 함께 해줘야 오류 최소화! X_train = X_train.fillna(0) X_test = X_test.fillna(0)

# 결측치 확인 X_train[cols].isnull().sum()

# 데이터 확인 X_train[cols]
📌 타겟 값 변경 (문자 -> 숫자)
# target값 변경 # <=50K -> 0 # >50K -> 1 # y = (y_train['income'] != '<=50K').astype(int) y = (y_train['income'] == '>50K').astype(int) y[:3]

📌 머신러닝 (지도학습 - 분류)
# 머신러닝 순서 기억하기 : 모델 불러오기 - 변수 부여 - 모델 fit - 모델 predict # 랜덤포레스트 from sklearn.ensemble import RandomForestClassifier rf = RandomForestClassifier() rf.fit(X_train[cols], y) # fit(x, y) : 훈련 데이터 (x = 훈련, y = 예측) pred = rf.predict(X_test[cols]) # predict : 평가 데이터 # pred[:10] : 평가데이터로 예측한 결과를 담은 변수 확인하기

📌 csv 파일 생성
# 예측 및 csv 파일 생성 / 문제에 따라 index = False 신경 쓸 것! # pd.DataFrame로 딕셔너리 형태의 원하는 컬럼과 해당하는 값(데이터) 넣어 변수 생성 submit = pd.DataFrame ( { 'id' : X_test['id'], 'income' : pred } ) submit.to_csv('00001.csv', index = False) # csv 파일로 저장; 파일 제목은 수험번호

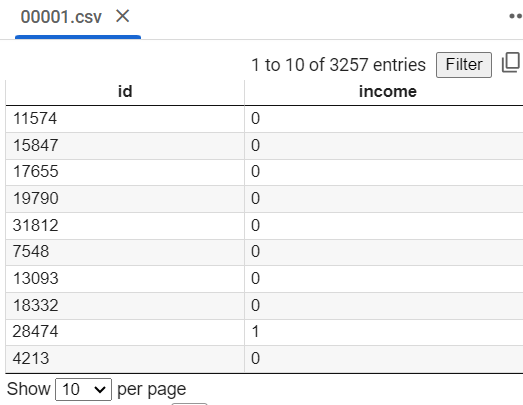
📌 평가(test 데이터, 정확도)
# 평가 (수험자는 알 수 없는 부분임) accuracy from sklearn.metrics import accuracy_score y_test = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/edadata/data_atype/y_test.csv") ans = (y_test['income'] == '>50K').astype(int) accuracy_score(ans, pred) # 두 변수 간 정확도 평가 (기준값(정답), 비교값(예측))

📌 문제 #2
2. 베이스라인
- 훈련/검증용 데이터 분리
- 모델 선택, 훈련
- 의사결정나무
- 랜덤포레스트
- XGBoost
- 평가
.
문제2
- "<= 50K -> 0"
- "> 50K -> 1"
- 평가: roc_auc
- 예측 해야할 값 : 확률
📌 검증 데이터 분리
# 학습용 데이터와 검증용 데이터로 구분 from sklearn.model_selection import train_test_split y = (y_train['income'] == '>50K').astype(int) X_tr, X_val, y_tr, y_val = train_test_split(X_train, y, test_size = 0.1, random_state = 1214)

# 데이터 크기 X_tr.shape, X_val.shape, y_tr.shape, y_val.shape

📌 머신러닝 모델(의사결정나무, 랜덤포레스트, XGboost)
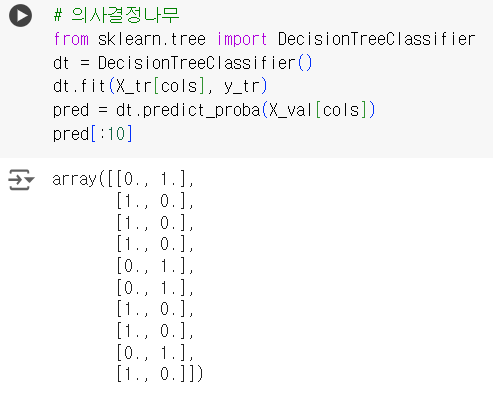
# 의사결정나무 from sklearn.tree import DecisionTreeClassifier dt = DecisionTreeClassifier() dt.fit(X_tr[cols], y_tr) pred = dt.predict_proba(X_val[cols]) pred[:10]
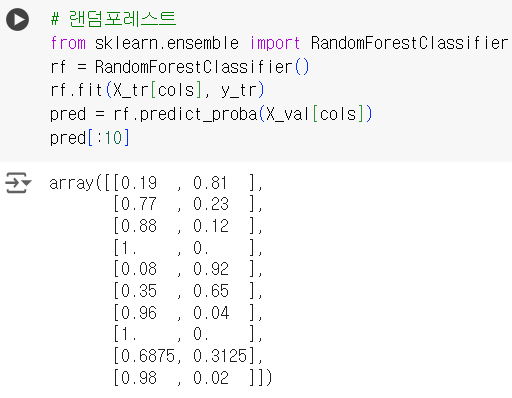
# 랜덤포레스트 from sklearn.ensemble import RandomForestClassifier rf = RandomForestClassifier() rf.fit(X_tr[cols], y_tr) pred = rf.predict_proba(X_val[cols]) pred[:10]
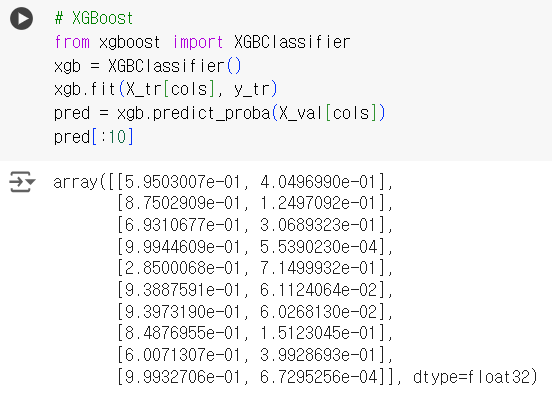
# XGBoost from xgboost import XGBClassifier xgb = XGBClassifier() xgb.fit(X_tr[cols], y_tr) pred = xgb.predict_proba(X_val[cols]) pred[:10]
📌 평가(검증 데이터, roc-auc)
# 평가 데이터로 예측 # 문제에서 예측값이 0일 확률을 구하는 것인지 1일 확률을 구하는 것인지 구분 # 지금 문제에서 평가는 1일 확률을 확인 ! from sklearn.metrics import roc_auc_score roc_auc_score(y_val, pred[:,1])

# 의사결정나무 정확도 from sklearn.tree import DecisionTreeClassifier dt = DecisionTreeClassifier() dt.fit(X_tr[cols], y_tr) pred = dt.predict_proba(X_val[cols]) roc_auc_score(y_val, pred[:,1])

# 랜덤포레스트 정확도 from sklearn.ensemble import RandomForestClassifier rf = RandomForestClassifier() rf.fit(X_tr[cols], y_tr) pred = rf.predict_proba(X_val[cols]) roc_auc_score(y_val, pred[:,1])

# XGBoost 정확도 from xgboost import XGBClassifier xgb = XGBClassifier() xgb.fit(X_tr[cols], y_tr) pred = xgb.predict_proba(X_val[cols]) roc_auc_score(y_val, pred[:,1])

- 여러 모델 중 정확도가 제일 높게 나타나는 모델 결과로 선택
📌 csv 파일 생성
# 평가 데이터로 예측한 csv 파일 생성 from sklearn.metrics import roc_auc_score roc_auc_score(y_val, pred[:,1]) pred = xgb.predict_proba(X_test[cols]) submit = pd.DataFrame( { 'id' : X_test['id'], 'income' : pred[:,1] } ) submit.to_csv('00002.csv', index = False)

📌 평가(test데이터, roc-auc)
from sklearn.metrics import roc_auc_score y_test = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/edadata/data_atype/y_test.csv") ans = (y_test['income'] != '<=50K').astype(int) roc_auc_score(ans, pred[:,1])


커피 좋아하는 데이터 꿈나무