
개요
머신러닝(
회귀) 실행 !
📌 머신러닝 프로세스 정리
- 문제정의, 라이브러리/데이터 불러오기
- 탐색적 데이터 분석 (EDA)
- 데이터 전처리
- 피처엔지니어링
- (Train/Validation 나누기)
- 모델 선택/훈련/평가/최적화
- 예측
- (csv 생성)
📌 문제
문제
- 보험료 예측
- 평가: rmse
- csv: id와 예측 값
📌 데이터 불러오기 & EDA
# 라이브러리 및 데이터 불러오기 import pandas as pd train = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/edadata/insurance/train.csv") test = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/edadata/insurance/test.csv")
# 데이터 크기 확인 # 데이터가 2개가 주어질 때는 train 데이터의 타겟 칼럼으로 인해 # 갯수가 차이나는 것을 확인 할 수 있음! train.shape, test.shape

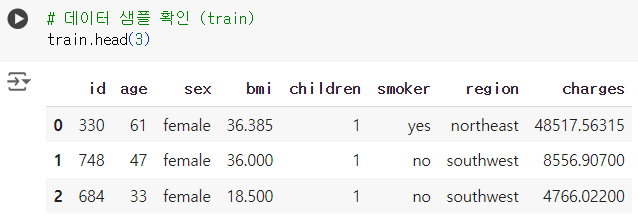
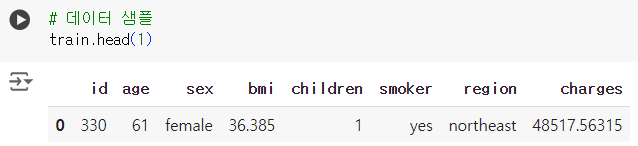
# 데이터 샘플 확인 (train) train.head(3)
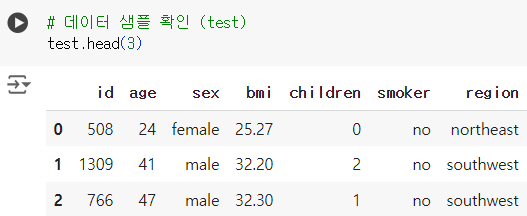
# 데이터 샘플 확인 (test) test.head(3)
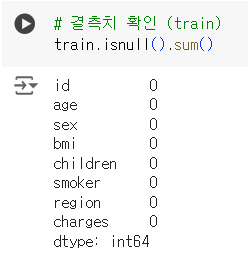
# 결측치 확인 (train) train.isnull().sum()
# 결측치 확인 (test) test.isnull().sum()
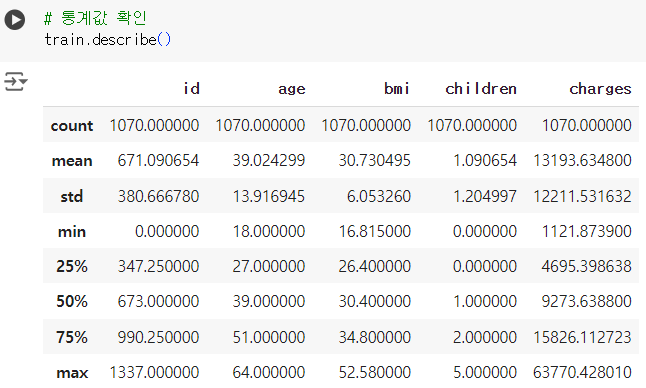
# 통계값 확인 (수치형) train.describe()
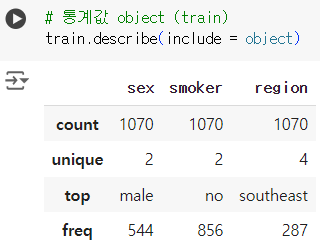
# 통계값 object (train) (범주형) train.describe(include = object)
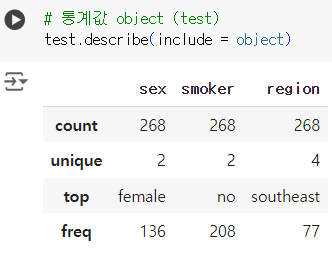
# 통계값 object (test) test.describe(include = object)
📌 데이터 전처리 및 피처 엔지니어링
.select_dtypes(include = " ").columns
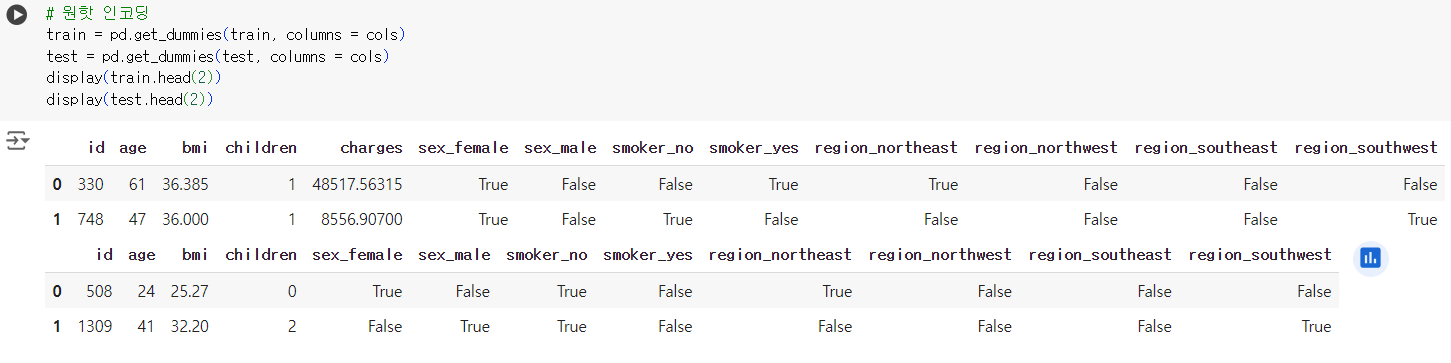
# object 컬럼명 선택 cols = train.select_dtypes(include = "object").columns cols

# 원핫 인코딩 train = pd.get_dummies(train, columns = cols) test = pd.get_dummies(test, columns = cols) display(train.head(2)) display(test.head(2))
# 스탠다드 스케일링 - 이번 문제에서 모델 성능에 큰 효과 없음! # from sklearn.preprocessing import StandardScaler # scaler = StandardScaler() # cols = ['age', 'bmi'] # train[cols] = scaler.fit_transform(train[cols]) # test[cols] = scaler.transform(test[cols]) # train.head(2)

# 민맥스 스케일링 - 이번 문제에서 모델 성능에 큰 효과 없음! # from sklearn.preprocessing import MinMaxScaler # scaler = MinMaxScaler() # cols = ['age', 'bmi'] # train[cols] = scaler.fit_transform(train[cols]) # test[cols] = scaler.transform(test[cols]) # train.head(2)

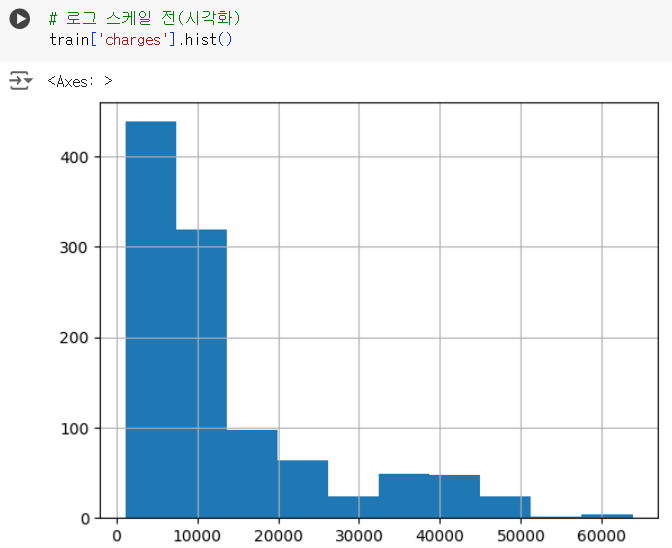
# 로그 스케일 전(시각화) train['charges'].hist()
# 로그 스케일 train['charges'] = np.log1p(train['charges'])

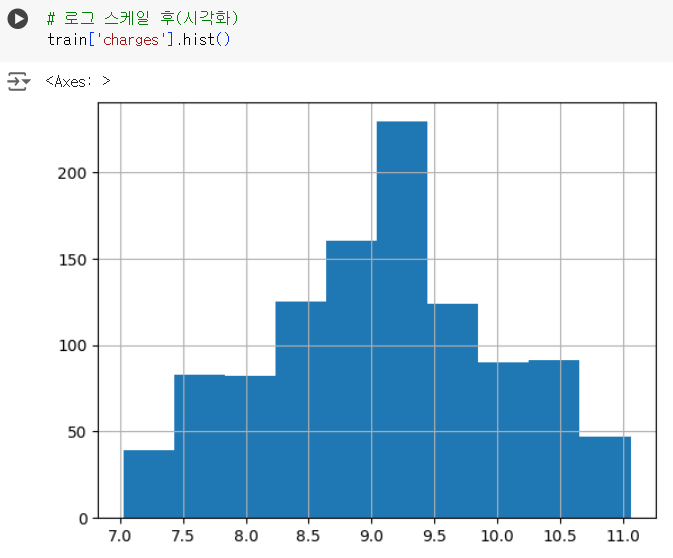
# 로그 스케일 후(시각화) train['charges'].hist()
📌 검증 데이터 분리
# 검증 데이터 분리 from sklearn.model_selection import train_test_split X_tr, X_val, y_tr, y_val = train_test_split(train.drop('charges', axis = 1), train['charges'], test_size = 0.15, random_state = 1214) X_tr.shape, X_val.shape, y_tr.shape, y_val.shape

# X 데이터 확인 X_tr.head(1)

# y 데이터 확인 y_tr.head(1)

📌 평가 수식
# 평가 수식 from sklearn.metrics import mean_squared_error import numpy as np # 참고 : np.sqrt(9) = 제곱근 # 평가 함수 rmse 정의 def rmse(y_test, pred): return np.sqrt(mean_squared_error(y_test, pred))

📌 머신러닝 프로세스 반복 진행
📌 회귀 모델 : 선형 회귀
# LinearRegression from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_tr, y_tr) pred = model.predict(X_val) # rmse(y_val, pred) rmse(np.exp(y_val), np.exp(pred)) # 5881.328211670706 - 베이스라인

📌 회귀 모델 : xgboost
# xgboost Regressor from xgboost import XGBRegressor model = XGBRegressor(objective = 'reg:squarederror') model.fit(X_tr, y_tr) pred = model.predict(X_val) rmse(np.exp(y_val), np.exp(pred))

📌 회귀 모델 : 랜덤포레스트
# RandomForestRegressor from sklearn.ensemble import RandomForestRegressor model = RandomForestRegressor() model.fit(X_tr, y_tr) pred = model.predict(X_val) # rmse(y_val, pred) rmse(np.exp(y_val), np.exp(pred)) # 로그 스케일링 결과 확인 시 단위를 원래대로 돌려야 함 # 성능 비교 (MSE 값이 작을수록 모델 성능이 좋다.) #4353.131898328633 - 베이스라인 #4337.625093161533 - 스탠다드 스케일 #4347.453812296086 - 민맥스 스케일링 #4093.640278328546 - 로그 스케일링 #4413.705922936184 - XGBOOST

- 로그 스케일링한 데이터를 랜덤포레스트 모델에서 예측했을 때
MES값이 제일 작으므로 로그 스케일링 데이터의 랜덤포레스트 예측값을 제출
📌 예측 (test 데이터)
# test 데이터 예측 pred = model.predict(test)

📌 데이터 프레임 만들기
# 제출용 데이터 프레임 submit = pd.DataFrame( { 'id' : test['id'], 'charges' : np.exp(pred) # 로그 스케일링 데이터를 선택했기 때문에 # np.exp() 로 원래 자릿수로 복구 } )

📌 csv파일 생성 및 확인
# csv파일 생성 submit.to_csv("00003.csv", index = False)

📌 평가 (test 데이터)
y_test = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/edadata/insurance/y_test.csv") rmse(y_test['charges'], np.exp(pred))

📌 정리
-
로그 스케일링 후 랜덤포레스트 모델로 train 데이터로 훈련 후
검증 데이터로 예측값을 출력해 성능 확인한 결과 : MSE = 4093.xxxx -
정답 데이터로 제출한 모델 예측값과 성능 확인한 결과 : MSE = 4794.xxxx
-
데이터 전처리와 피처 엔지니어링을 진행하고,
여러 모델들을 이용해 학습시키고 예측값을 출력해 성능을 비교하고,
성능이 가장 좋은 모델의 예측값을 출력해 csv 파일로 생성 후 제출하는
전체 과정에 대한 이해를 할 수 있었다. -
모든 문법과 입력값들을 완벽하게 이해하고 사용할 수 있을 때까지
반복 숙달 해보자!

커피 좋아하는 데이터 꿈나무