
개요
범주형 데이터 분석 검정 (카이제곱 검정)
📌 적합도 검정
-
관찰도수와 기대도수의 차이
-
빈도(count)로 변경 (관찰값, 기대값)
-
scipy.stats.chisquare(observed, expected)- observed : 관찰된 빈도 리스트
- expected : 기대 빈도 리스트
문제
지난 3년간 빅데이터 분석기사 점수 분포 ;
60점 미만 : 50%,
60-70점 : 35%,
80점 이상 : 15%단답형을 제외하고, 작업형 3을 추가하여 300명 대상으로 적용한 결과 ;
60점 미만: 150명,
60-70점: 120명,
80점이상: 30명유의수준 0.05일 때,
새로운 시험문제 유형과 기존 시험문제 유형은 점수에 차이가 없는지 검정하시오.
- 귀무가설(H0): 새로운 시험문제는 기존 시험문제 점수와 동일하다.
- 대립가설(H1): 새로운 시험문제는 기존 시험문제 점수와 다르다.
#관찰 ob = [150, 120, 30] #기대 ex = [0.5*300, 0.35*300, 0.15*300] from scipy import stats stats.chisquare(ob, ex)

📌 독립성 검정
-
두 변수가 서로 독립적인지(연관성이 있는지) 확인
-
교차표 테이블로 만들기
- 문제에서 표로 주어졌을 때
- RAW (원) 데이터가 주어졌을 때
-
scipy.stats.chi2_contingency(table, correction=True)- table : 교차표
- correction : 연속성 보정 (기본값 True)
문제
빅데이터 분석기사 실기 언어 선택에 따라 합격 여부를 조사한 결과 ;
언어와 합격 여부는 독립적인가? 가설검정을 실시하시오. (유의수준 0.05)
- 귀무가설(H0): 언어와 합격 여부는 독립이다.
- 대립가설(H1): 언어과 합격 여부는 독립이지 않다.
교차표 데이터로 주어질 때
- R: 합격 80명, 불합격 20명,
- Python: 합격 90명, 불합격 10명
import pandas as pd df = pd.DataFrame({ '합격':[80, 90], '불합격':[20, 10] },index=['R', 'P'] )
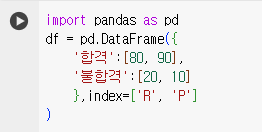
from scipy import stats stats.chi2_contingency(df)

import pandas as pd df = pd.DataFrame({ 'R':[80, 20], 'P':[90, 10] },index=['합격', '불합격'] ) df
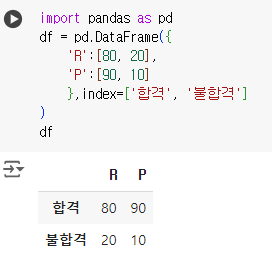
from scipy import stats stats.chi2_contingency(df)

df = [[80, 20], [90, 10]] stats.chi2_contingency(df)

로우 데이터로 주어질 때
# 데이터 생성 import pandas as pd data = { '언어': ['R']*100 + ['Python']*100, '합격여부': ['합격']*80 + ['불합격']*20 + ['합격']*90 + ['불합격']*10 } df = pd.DataFrame(data)

df.sample(1)

df = pd.crosstab(df['언어'], df['합격여부']) df

stats.chi2_contingency(df)

📌 동질성 검정
- 두 개 이상의 집단에서 동질성을 갖는지 확인
- 검정 절차는 독립성 검정과 같음

커피 좋아하는 데이터 꿈나무