
개요
상관관계와 회귀분석
📌 상관관계
- 두 변수 간의 선형적인 관계
📌 상관계수
두 변수 간의 선형 관계의 강도와 방향 (-1 ≤ r ≤ 1)
-
r = 1: 강한 양의 선형관계 -
r = 0: 선형 관계 없음 -
r = - 1: 강한 음의 선형관계 -
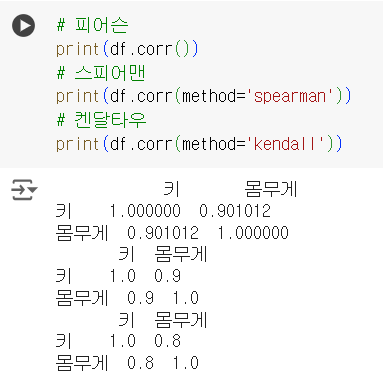
df.corr(): 피어슨 (기본값) -
df.corr(method='spearman'): 스피어맨 -
df.corr(method='kendall'): 켄달타우
# 데이터 import pandas as pd df = pd.DataFrame({ '키': [150, 160, 170, 175, 165], '몸무게': [42, 52, 75, 67, 56] })

# 상관계수 df.corr()
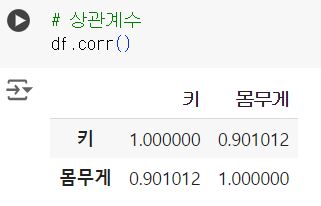
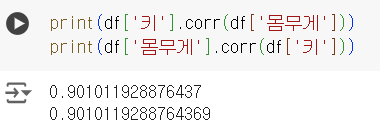
print(df['키'].corr(df['몸무게'])) print(df['몸무게'].corr(df['키']))
# 피어슨 print(df.corr()) # 스피어맨 print(df.corr(method='spearman')) # 켄달타우 print(df.corr(method='kendall'))
📌 상관계수에 대한 t검정
귀무가설: 두 변수 간에 상관관계가 없다.
대립가설: 두 변수 간에 상관관계가 있다.
- stats.pearsonr(x, y) #피어슨
- stats.spearmanr(x, y) # 스피어맨
- stats.kendalltau(x, y) # 켄달타우
# t검정 from scipy import stats # 피어슨 print(stats.pearsonr(df['몸무게'], df['키'])) # 스피어맨 print(stats.spearmanr(df['몸무게'], df['키'])) # 켄달타우 print(stats.kendalltau(df['몸무게'], df['키']))

📌 단순 선형 회귀 분석
-
OLS : 최소제곱법(Ordinary Least Squares)
-
ols(’종속변수 ~ 독립변수’, data=df).fit() -
model.summary(): 회귀 모델 통계적 요약 -
model.predict(): 예측값 -
model.get_prediction(): 예측값과 예측값에 대한 신뢰구간, 예측구간 -
df['잔차'] = df['종속변수'] - model.predict(df)
실습
주어진 키와 몸무게 데이터로 회귀모델을 구축하고 각 소문제의 값을 구하시오.
- 키: 종속변수
- 몸무게: 독립변수
import pandas as pd df = pd.DataFrame({ '키': [150, 160, 170, 175, 165, 155, 172, 168, 174, 158, 162, 173, 156, 159, 167, 163, 171, 169, 176, 161], '몸무게': [74, 50, 70, 64, 56, 48, 68, 60, 65, 52, 54, 67, 49, 51, 58, 55, 69, 61, 66, 53] })

# 모델 학습 summary 출력 from statsmodels.formula.api import ols model = ols('키 ~ 몸무게', data=df).fit() print(model.summary())
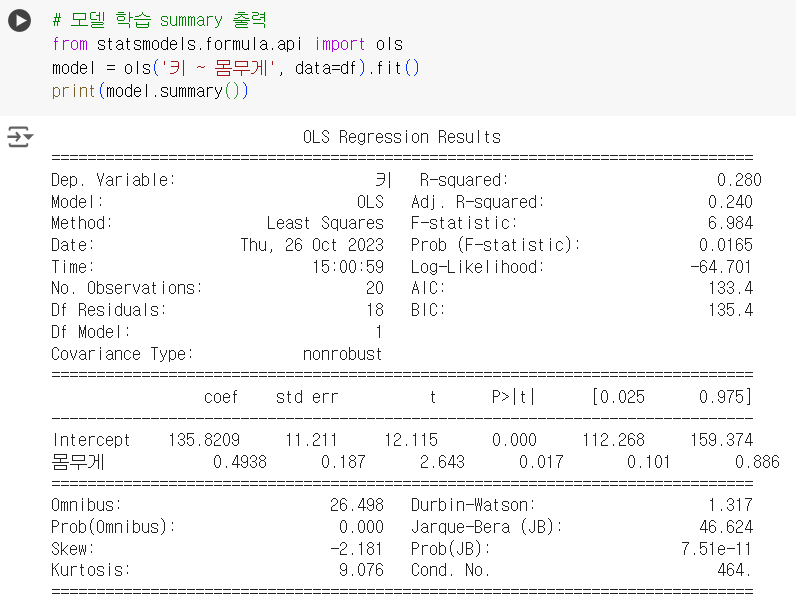
# 결정계수 # 0.28 model.rsquared

# 기울기(회귀계수) # 0.4938 model.params['몸무게']

# 절편(회귀계수) # 135.8209 model.params['Intercept']

# 몸무게의 회귀계수가 통계적으로 유의한지 pvalue # 0.017 model.pvalues['몸무게']

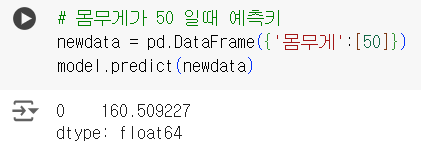
# 몸무게가 50 일때 예측키 newdata = pd.DataFrame({'몸무게':[50]}) model.predict(newdata)
# 잔차 제곱합 # 잔차 = 관측(실제)값 - 예측값 df['잔차'] = df['키'] - model.predict(df['몸무게']) sum(df['잔차'] ** 2)

# MSE (df['잔차'] ** 2).mean()

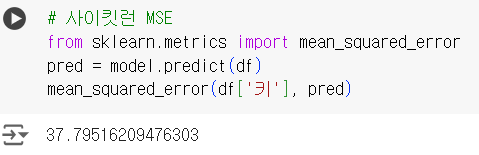
# 사이킷런 MSE from sklearn.metrics import mean_squared_error pred = model.predict(df) mean_squared_error(df['키'], pred)
# 신뢰구간 # 0.101 0.886

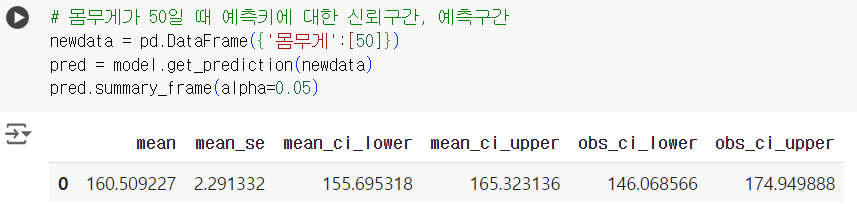
# 몸무게가 50일 때 예측키에 대한 신뢰구간, 예측구간 newdata = pd.DataFrame({'몸무게':[50]}) pred = model.get_prediction(newdata) pred.summary_frame(alpha=0.05) # 신뢰구간: 155.695318 165.323136 # 예측구간: 146.068566 174.949888
📌 다중 선형 회귀 분석
ols(’종속변수 ~ 독립변수1 + 독립변수2’, data=df).fit()
실습
주어진 매출액, 광고비, 플랫폼 데이터로 회귀모델을 구축하고 각 소문제의 값을 구하시오.
- 매출액: 종속변수
- 광고비, 플랫폼(유통 플랫폼 수), 투자: 독립변수
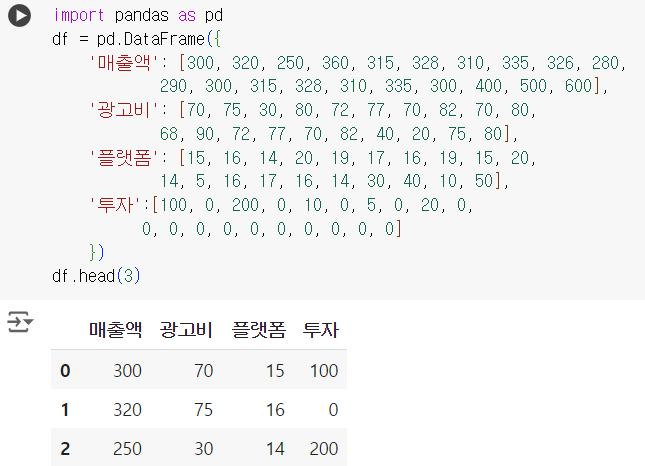
import pandas as pd df = pd.DataFrame({ '매출액': [300, 320, 250, 360, 315, 328, 310, 335, 326, 280, 290, 300, 315, 328, 310, 335, 300, 400, 500, 600], '광고비': [70, 75, 30, 80, 72, 77, 70, 82, 70, 80, 68, 90, 72, 77, 70, 82, 40, 20, 75, 80], '플랫폼': [15, 16, 14, 20, 19, 17, 16, 19, 15, 20, 14, 5, 16, 17, 16, 14, 30, 40, 10, 50], '투자':[100, 0, 200, 0, 10, 0, 5, 0, 20, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] }) df.head(3)
# 모델 학습 summary 출력 (종속변수: 매출액, 독립변수: 광고비, 플랫폼) from statsmodels.formula.api import ols model = ols('매출액 ~ 광고비 + 플랫폼', data=df).fit() print(model.summary())
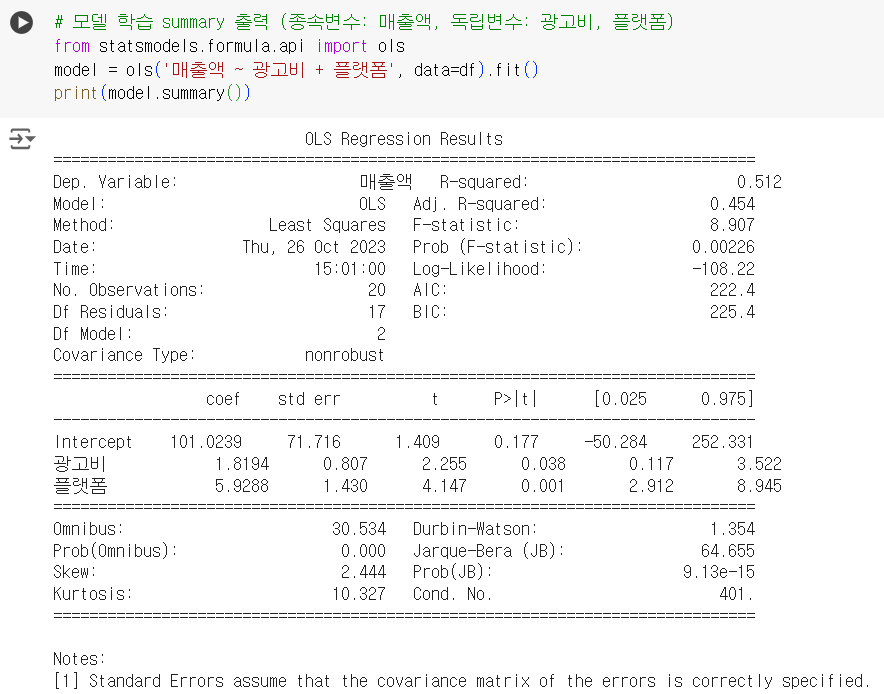
# 결정계수(R-squared) # 0.512 model.rsquared

# 회귀계수(광고비) # 1.8194 model.params['광고비']

# 회귀계수(플랫폼) # 5.9288 model.params['플랫폼']

# 회귀계수(절편) # 101.0239 model.params['Intercept']

# 광고비의 회귀계수가 통계적으로 유의한지 pvalue # 0.038 model.pvalues['광고비']

# 플랫폼의 회귀계수가 통계적으로 유의한지 pvalue # 0.001 model.pvalues['플랫폼']

# 광고비 50, 플랫폼 20일 때 매출액 예측 newdata = pd.DataFrame({ '광고비':[50], '플랫폼':[20] }) model.predict(newdata)

# 잔차 제곱합 (model.resid ** 2).sum()

# MSE (model.resid ** 2).mean()

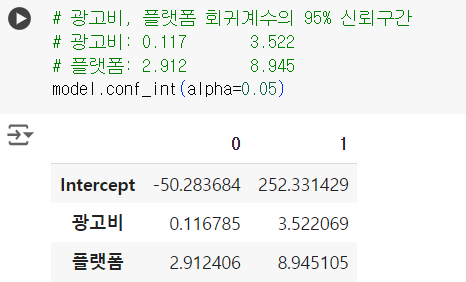
# 광고비, 플랫폼 회귀계수의 95% 신뢰구간 # 광고비: 0.117 3.522 # 플랫폼: 2.912 8.945 model.conf_int(alpha=0.05)
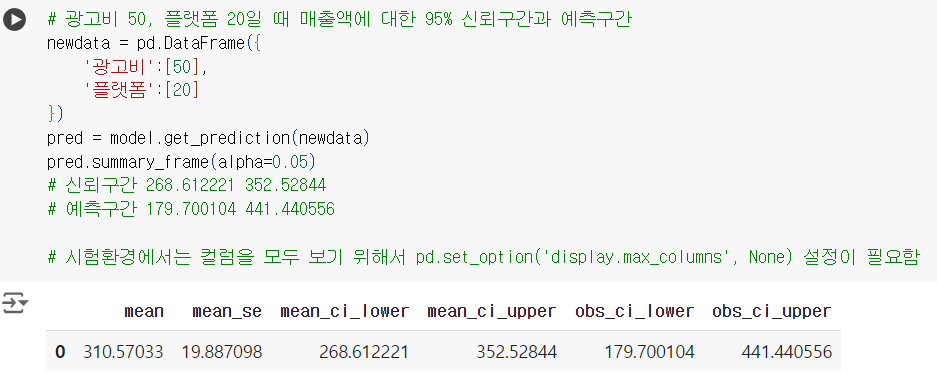
# 광고비 50, 플랫폼 20일 때 매출액에 대한 95% 신뢰구간과 예측구간 newdata = pd.DataFrame({ '광고비':[50], '플랫폼':[20] }) pred = model.get_prediction(newdata) pred.summary_frame(alpha=0.05) # 신뢰구간 268.612221 352.52844 # 예측구간 179.700104 441.440556 # 시험환경에서는 컬럼을 모두 보기 위해서 pd.set_option('display.max_columns', None) 설정이 필요함
📌 범주형 변수
- 판다스의
pd.get_dummies(drop_first=True)로 원-핫인코딩 처리
다중공선성 문제를 해결하기 위해 drop_first = True
원-핫 drop_first
col → A B C → B C
A 1 0 0 0 0
B 0 1 0 1 0
C 0 0 1 0 1
A 1 0 0 0 0
import pandas as pd df = pd.DataFrame({ '매출액': [300, 320, 250, 360, 315, 328, 310, 335, 326, 280, 290, 300, 315, 328, 310, 335, 300, 400, 500, 600], '광고비': [70, 75, 30, 80, 72, 77, 70, 82, 70, 80, 68, 90, 72, 77, 70, 82, 40, 20, 75, 80], '플랫폼': [15, 16, 14, 20, 19, 17, 16, 19, 15, 20, 14, 5, 16, 17, 16, 14, 30, 40, 10, 50], '투자':[100, 0, 200, 0, 10, 0, 5, 0, 20, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], '유형':['B','B','C','A','B','B','B','B','B','B' ,'C','B','B','B','B','B','B','A','A','A'] }) df.head(3)

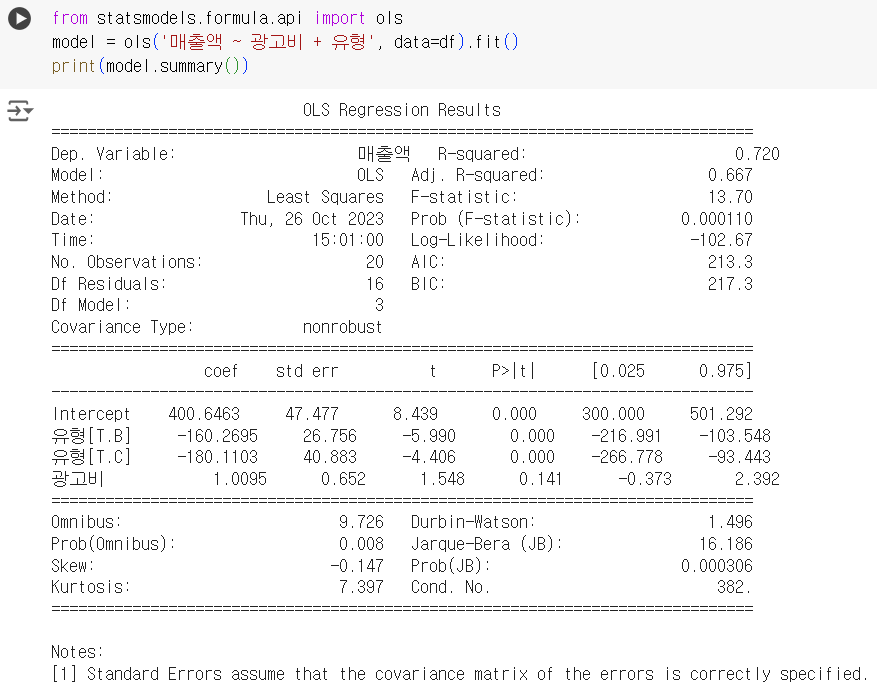
from statsmodels.formula.api import ols model = ols('매출액 ~ 광고비 + 유형', data=df).fit() print(model.summary())
# 원핫인코딩 df2 = pd.get_dummies(df) df2.head()
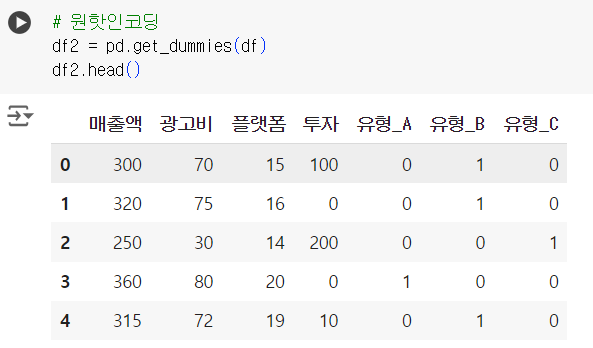
# drop_first=True df = pd.get_dummies(df, drop_first=True) df.head()
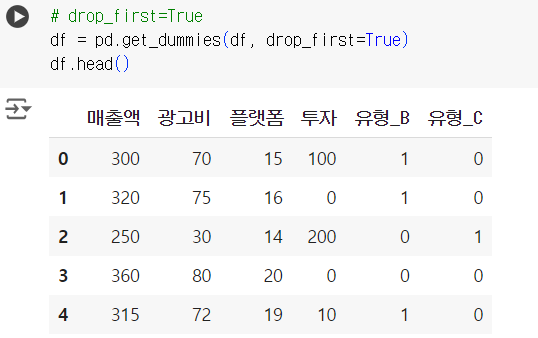
# 회귀 모델 학습 & summary (독립변수로 광고비와 유형만 활용) from statsmodels.formula.api import ols model = ols('매출액 ~ 광고비 + 유형_B + 유형_C', data=df).fit() print(model.summary())
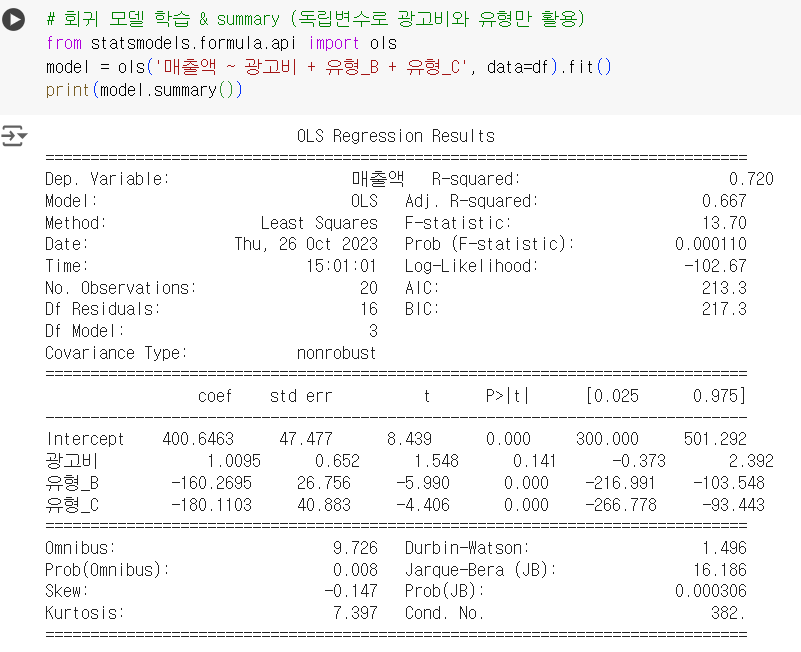

커피 좋아하는 데이터 꿈나무