
개요
작업형 2 예시문제 풀어보기
📌 문제 살펴보기
-
시험환경에서 문제 풀어보기
-
문제
(체험) 제2유형
제공된 데이터는 백화점 고객이 1년간 상품을 구매한 속성 데이터이다.
제공된 학습용 데이터(data/customer_train.csv)를 이용하여
백화점 구매 고객의 성별을 예측하는 모델을 개발하고,
개발한 모델에 기반하여 평가용 데이터(data/customer_test.csv)에 적용하여
얻은 성별 예측 결과를 아래 [제출 형식]에 따라 CSV 파일로 생성하여 제출하시오.
예측 결과는 ROC-AUC 평가지표에 따라 평가함.
성능이 우수한 예측 모델을 구축하기 위해서는
데이터 정제, Feature Engineering, 하이퍼 파라미터(hyper parameter) 최적화,
모델 비교 등이 필요할 수 있음. 다만, 과적합에 유의하여야 함.
[제출 형식]
CSV 파일명: result.csv (파일명에 디렉토리:폴더 지정불가)
예측 성별 칼럼명: pred
제출 칼럼 수: pred 칼럼 1개
평가용 데이터 개수와 예측 결과 데이터 개수 일치: 2,482개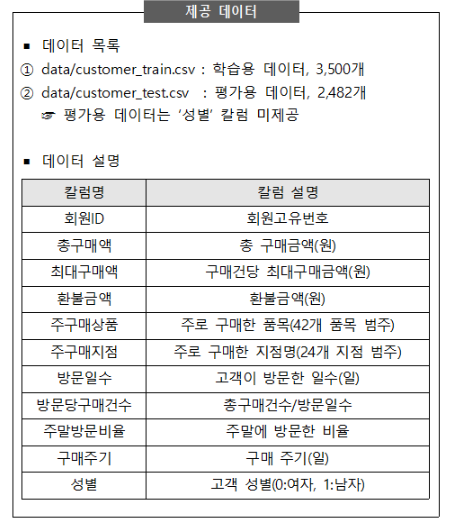

-
문제에서 확인할 사항 :
-
예측 결과 평가 지표 ?
ROC_AUC_SCORE: 양성 클래스 확률값으로 계산되는 평가지표로
예측 결과를 0, 1 로 분류(predict)하는 것이 아닌
확률로 분류(predict_proba)하여 제출하기 -
양성(1, 남자) 클래스 확률값 : predict_proba 결과를 [ : , 1 ] 슬라이싱 하기
-
분류(이진)
-
📌 최대한 간단하게 풀어보기
# 문제정의
# roc-auc -> 확률값을 예측 predict_proba()
# 양성(1, 남자) 클래스 확률값
# 분류(이진)
# 데이터 불러오기
import pandas as pd
train = pd.read_csv("data/customer_train.csv")
test = pd.read_csv("data/customer_test.csv")
# EDA
pd.set_option('display.max_columns', None)
# print(train.shape, test.shape)
# print(train.head())
# print(train.info())
# print(train.isnull().sum())
# print(test.isnull().sum())
# 전처리
train['환불금액'] = train['환불금액'].fillna(0)
test['환불금액'] = test['환불금액'].fillna(0)
cols = ['회원ID', '총구매액', '최대구매액', '환불금액', '방문일수', '방문당구매건수', '주말방문비율', '구매주기']
target = train.pop('성별')
# 모델 학습 및 예측
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(train[cols], target)
pred = model.predict_proba(test[cols])
print(pred)
print(pred[:,1])
# 제출
submit = pd.DataFrame({
'pred': pred[:,1]
})
submit.to_csv('result.csv', index=False)
print(pd.read_csv('result.csv'))📌 모델 성능 높여보기
- 데이터 분리
- 범주형 데이터 활용
# 문제정의
# roc-auc -> 확률값을 예측 predict_proba()
# 양성(1, 남자) 클래스 확률값
# 분류(이진)
# 데이터 불러오기
import pandas as pd
train = pd.read_csv("data/customer_train.csv")
test = pd.read_csv("data/customer_test.csv")
# EDA
pd.set_option('display.max_columns', None)
# print(train.shape, test.shape)
# print(train.head())
# print(train.info())
# print(train.isnull().sum())
# print(test.isnull().sum())
# print(train.describe(include='O'))
# print(test.describe(include='O'))
# print(sorted(list(train['주구매상품'].unique())))
# print(sorted(list(test['주구매상품'].unique())))
a = set(train['주구매상품'].unique())
b = set(test['주구매상품'].unique())
print(a - b)
print(b - a)
# 전처리
train['환불금액'] = train['환불금액'].fillna(0)
test['환불금액'] = test['환불금액'].fillna(0)
from sklearn.preprocessing import LabelEncoder
cols = ['주구매상품', '주구매지점']
for col in cols:
le = LabelEncoder()
train[col] = le.fit_transform(train[col])
test[col] = le.transform(test[col])
target = train.pop('성별')
# 검증용 데이터
from sklearn.model_selection import train_test_split
X_tr, X_val, y_tr, y_val = train_test_split(train, target, test_size=0.2, random_state = 0)
print(X_tr.shape, X_val.shape, y_tr.shape, y_val.shape)
# 모델 학습 및 평가
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(X_tr, y_tr)
# pred = model.predict_proba(X_val[cols])
pred = model.predict_proba(X_val)
from sklearn.metrics import roc_auc_score
print(roc_auc_score(y_val, pred[:,1]))
# 제출
pred = model.predict_proba(test)
submit = pd.DataFrame({
'pred': pred[:,1]
})
submit.to_csv('result.csv', index=False)
print(pd.read_csv('result.csv'))
# 베이스라인 모델(수치형) : 0.57
# predict : 0.55
# 레이블 인코딩 : 0.609
커피 좋아하는 데이터 꿈나무