
개요
작업형 1 예시문제 다양하게 풀어보기
📌 문제 살펴보기
- 작업형 1 예시문제
자동차 데이터 셋에서
qsec 컬럼을 Min-Max Scale로 변환 후,
0.5보다 큰 값을 가지는 레코드(row) 수를 제출하시오.
-
문제 분석
-
문제는
qsec 컬럼만 묻고 있다. (다른 컬럼 신경 쓸 필요 없음) -
MinMax Scale변환 -
조건 :
0.5보다 큰 값
-
📌 데이터 불러오기
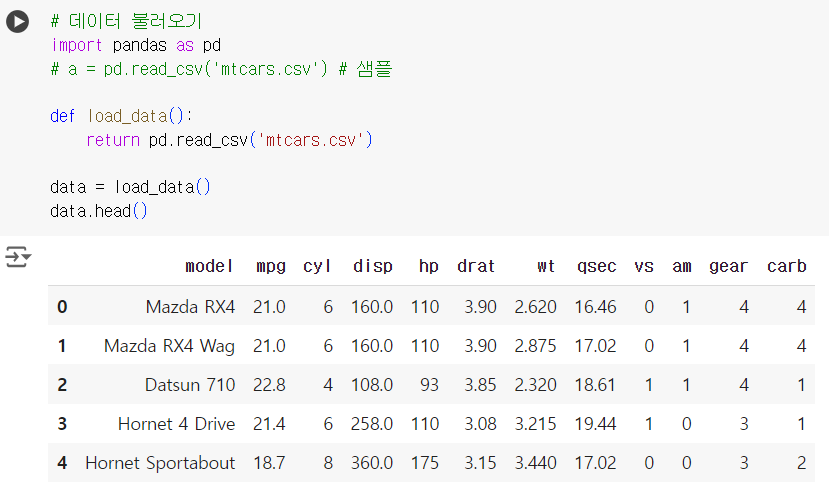
# 데이터 불러오기 import pandas as pd # a = pd.read_csv('mtcars.csv') # 샘플 def load_data(): return pd.read_csv('mtcars.csv') data = load_data() data.head()
📌 스케일링
📌 스케일링 방법1: MinmaxScaler
# MinMaxScaler 활용 from sklearn.preprocessing import MinMaxScaler data = load_data() scaler = MinMaxScaler() print('MinMax Scale 변환 전: \n',data['qsec'].head()) data['qsec'] = scaler.fit_transform(data[['qsec']]) print('MinMax Scale 변환 후: \n',data['qsec'].head())

📌 스케일링 방법2: minmax_scale
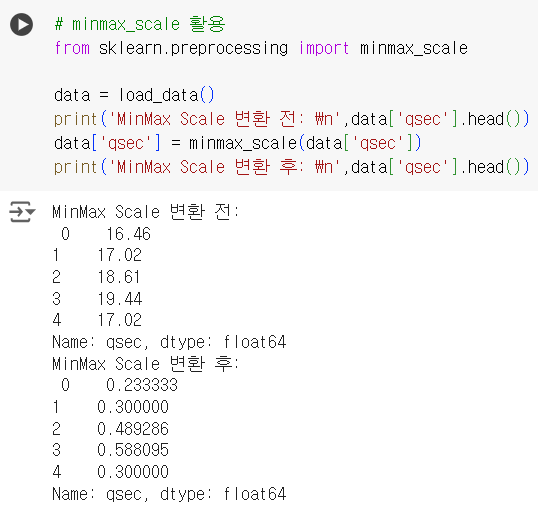
# minmax_scale 활용 from sklearn.preprocessing import minmax_scale data = load_data() print('MinMax Scale 변환 전: \n',data['qsec'].head()) data['qsec'] = minmax_scale(data['qsec']) print('MinMax Scale 변환 후: \n',data['qsec'].head())
📌 스케일링 방법3: minmax_scale
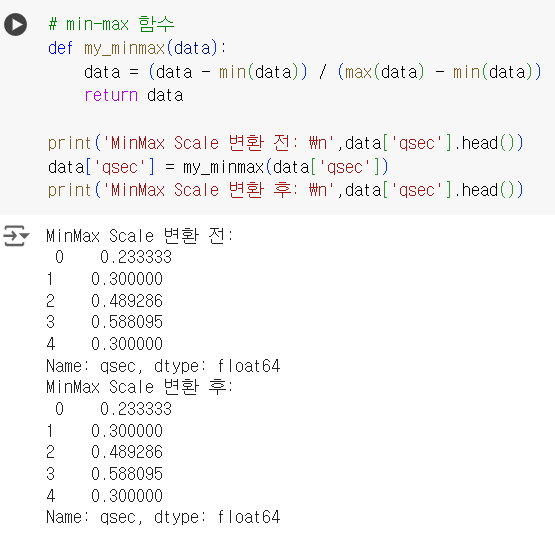
# min-max 함수 def my_minmax(data): data = (data - min(data)) / (max(data) - min(data)) return data print('MinMax Scale 변환 전: \n',data['qsec'].head()) data['qsec'] = my_minmax(data['qsec']) print('MinMax Scale 변환 후: \n',data['qsec'].head())
📌 조건
📌 조건에 맞는 수 1 : sum
# True(1)를 더 함 cond = data['qsec'] > 0.5 print(sum(cond))

📌 조건에 맞는 수 2 : len
# 데이터 수를 구함 cond = data['qsec'] > 0.5 print(len(data[cond]))

📌 조건에 맞는 수 3 : count
# 데이터 수를 구함 cond = data['qsec'] > 0.5 print(data[cond]['qsec'].count())

📌 심화
- 결측치가 있을 때 sum, len, count
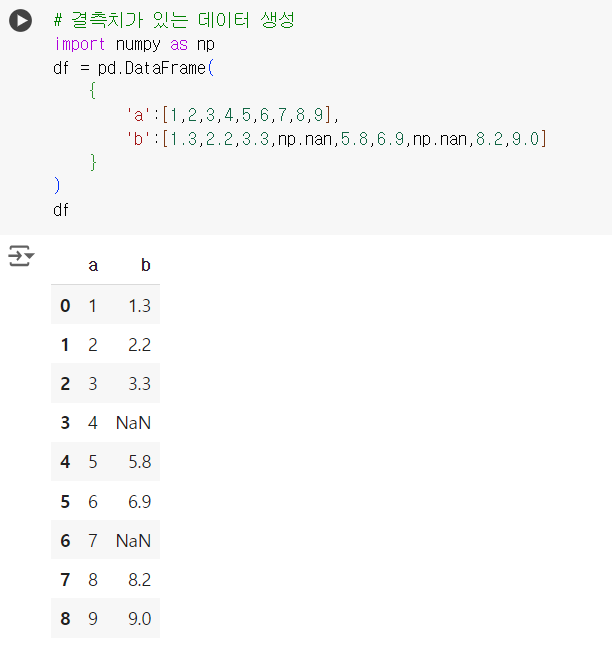
# 결측치가 있는 데이터 생성 import numpy as np df = pd.DataFrame( { 'a':[1,2,3,4,5,6,7,8,9], 'b':[1.3,2.2,3.3,np.nan,5.8,6.9,np.nan,8.2,9.0] } ) df
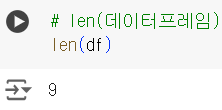
# len(데이터프레임) len(df)
# len(시리즈) len(df['b'])

# 데이터프레임.count() df.count()

# 시리즈.count() df['b'].count()

- len: 행의 수
- count: NaN이 아닌 (컬럼별) 행의 수
- sum: True(1)값을 더했기 때문에 조건문에 따라 달라짐
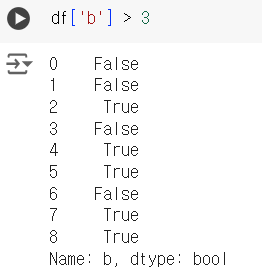
df['b'] > 3
cond = df['b'] > 3 print(sum(cond))


커피 좋아하는 데이터 꿈나무