
#개요
- 데이터 핸들링을 위한 판다스 기초 1
📌 CSV 파일
- CSV 파일? Comma-Separated Values
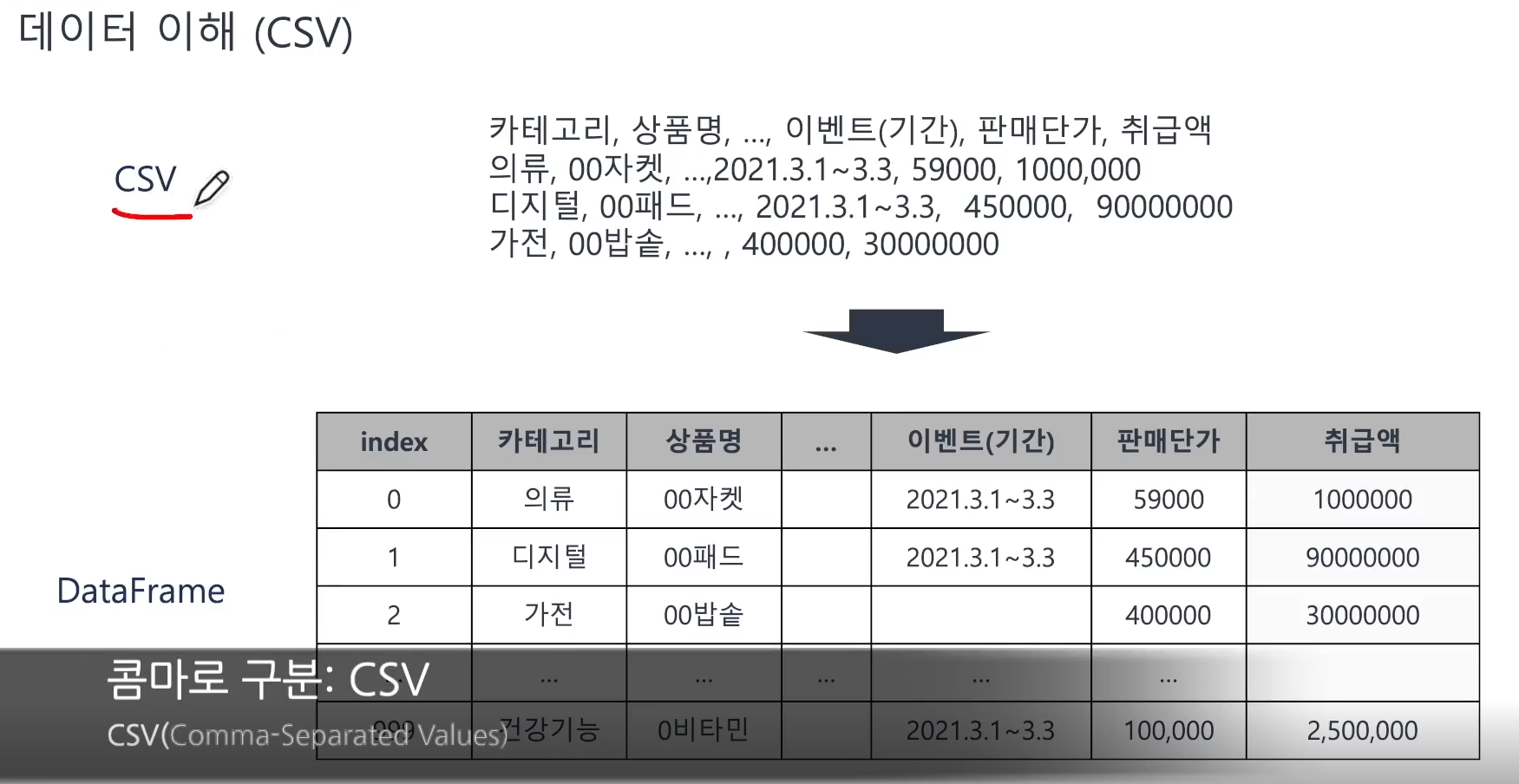
📌 CSV 파일 생성

# csv파일 (data.csv) 생성
import pandas as pd
data = {
"메뉴":['아메리카노','카페라떼','카페모카', '바닐라라떼', '녹차', '초코라떼', '바닐라콜드브루'],
"가격":[4100, 4600, 4600, 5100, 4100, 5000, 5100],
"할인율":[0.5, 0.1, 0.2, 0.3, 0, 0, 0],
"칼로리":[10, 180, 420, 320, 20, 500, 400],
}
data = pd.DataFrame(data)
data.to_csv('data.csv', index=False)📌 라이브러리 불러오기

# 판다스 라이브러리
import pandas as pd📌 데이터 불러오기
- pd.read_파일형식('파일명.확장자')
# 데이터 불러오기 pd.read_csv('data.csv')
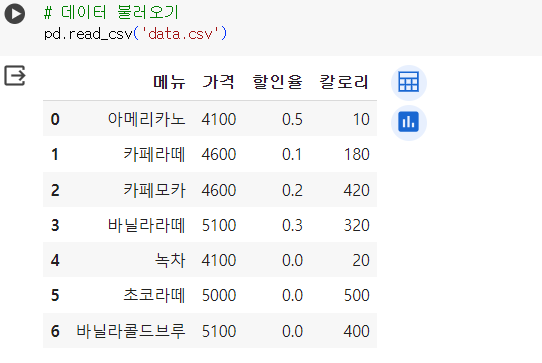
# 데이터 불러와서 변수에 담기 df = pd.read_csv('data.csv')

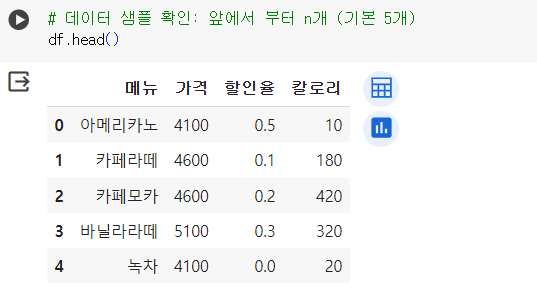
# 데이터 샘플 확인: 앞에서 부터 n개 (기본 5개) df.head()
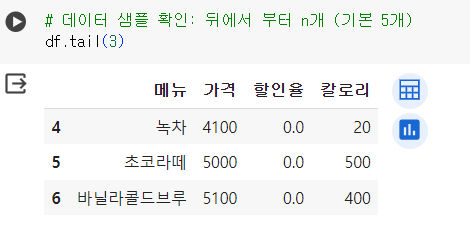
# 데이터 샘플 확인: 뒤에서 부터 n개 (기본 5개) df.tail(3) < () 안 숫자 넣을 시 해당 개수 확인
📌 데이터 프레임과 시리즈
# 시리즈 만들기 (문자열) menu = pd.Series(['아아','아라','바콜']) menu

# 시리즈 만들기(정수형) price = pd.Series([2000, 3000, 4000]) price

# 데이터 프레임 만들기 pd.DataFrame({"컬럼명":데이터}) pd.DataFrame({ "menu" : menu, "price" : price })
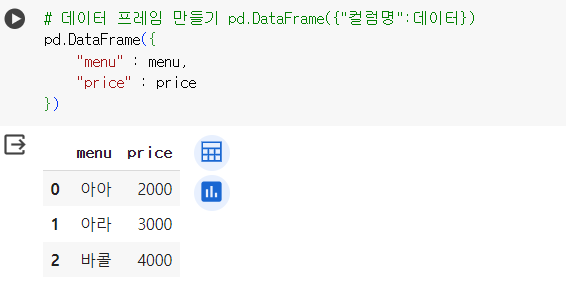
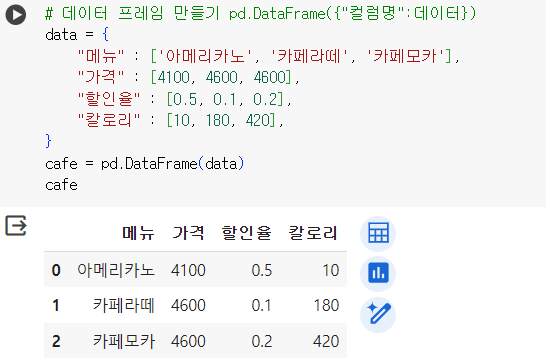
# 데이터 프레임 만들기 pd.DataFrame({"컬럼명":데이터}) data = { "메뉴" : ['아메리카노', '카페라떼', '카페모카'], "가격" : [4100, 4600, 4600], "할인율" : [0.5, 0.1, 0.2], "칼로리" : [10, 180, 420], } cafe = pd.DataFrame(data) cafe
# 시리즈 선택 (가격) df['메뉴']

# 데이터프레임 선택 (가격) df[['가격','할인율']]

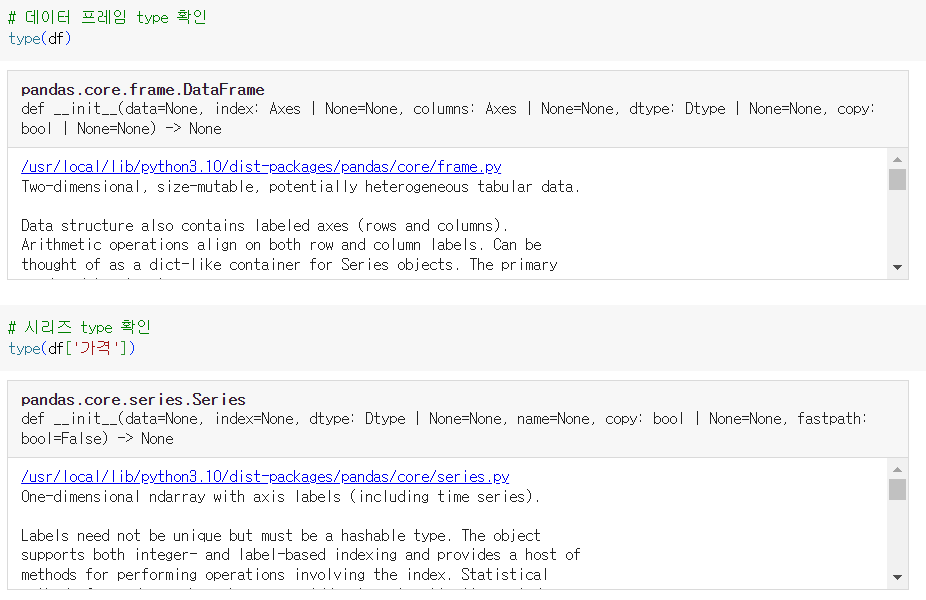
# 데이터 프레임 type 확인 type(df) # 시리즈 type 확인 type(df['가격'])
📌 EDA (탐색적 데이터 분석)
# 데이터 불러오기 (에러가 뜬다면 가장 첫번째 셀, csv 파일을 생성하는 코드 실행) df = pd.read_csv('data.csv')

# 데이터 프레임 크기 (행, 컬럼) df.shape

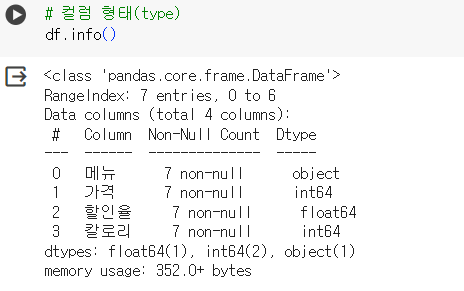
# 컬럼 형태(type) df.info()
# 기초 통계 df.describe()
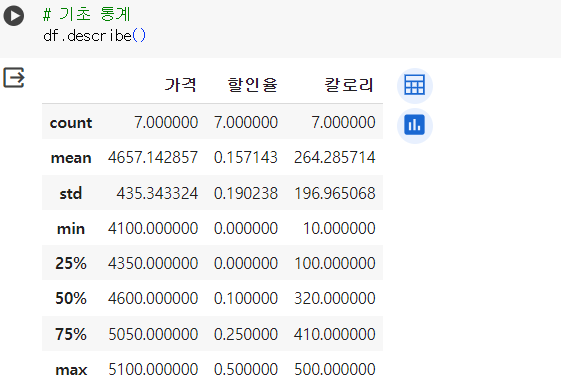
# 기초 통계 (object) df.describe(include='O') < 대문자 O (Object)
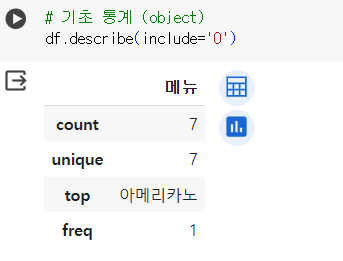
# 상관관계 # 코랩에서 판다스 버전이 업데이트되어 일부 함수에 `numeric_only=True` 를 설정해야 합니다. # 이 설정은 데이터프레임에서 숫자 형태의 데이터만 선택하도록 지정합니다. (단, 시험환경 버전은 설정 필요 없음) df.corr(numeric_only=True)
# 중복 값이 있는 데이터 생성 car = { "car":['Sedan','SUV','Sedan','SUV','SUV','SUV','Sedan','Sedan','Sedan','Sedan','Sedan'], "size":['S','M','S','S','M','M','L','S','S', 'M','S'] } car = pd.DataFrame(car) car.head(3)

# 항목 종류 수 car.nunique()

# 항목 종류 car['car'].unique()

car['size'].unique()

# 항목별 개수 (car) car['car'].value_counts()

# 항목별 개수 (size) car['size'].value_counts()

📌 자료형 변환
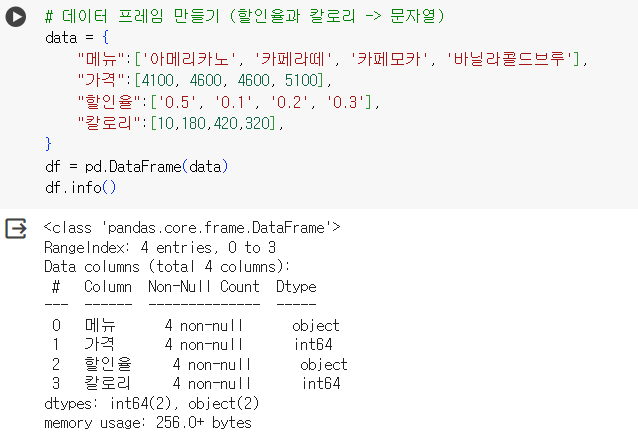
# 데이터 프레임 만들기 (할인율과 칼로리 -> 문자열) data = { "메뉴":['아메리카노', '카페라떼', '카페모카', '바닐라콜드브루'], "가격":[4100, 4600, 4600, 5100], "할인율":['0.5', '0.1', '0.2', '0.3'], "칼로리":[10,180,420,320], } df = pd.DataFrame(data) df.info()
# 자료형 변환 / astype / object -> float df['할인율'] = df['할인율'].astype('float')

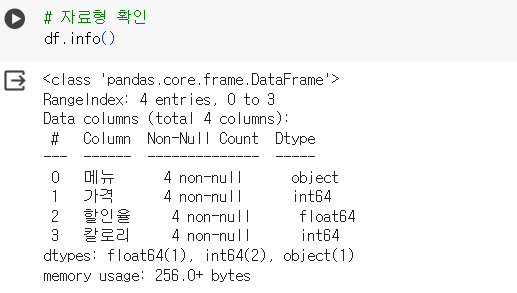
# 자료형 확인 df.info()
📌 새로운 컬럼 추가
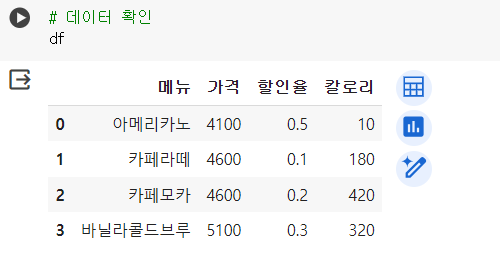
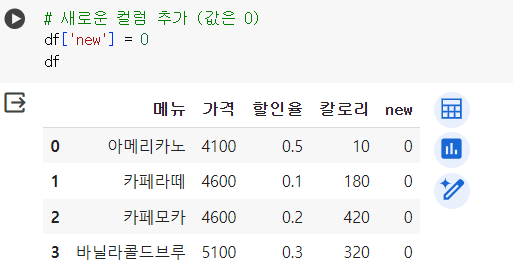
# 새로운 컬럼 추가 (값은 0) df['new'] = 0 df
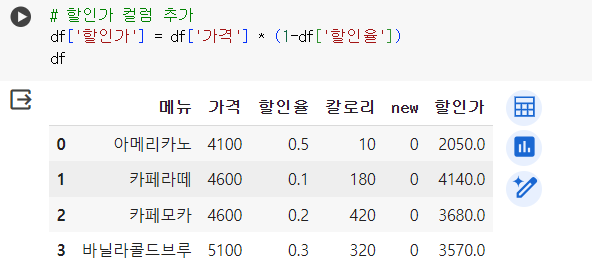
# 할인가 컬럼 추가 df['할인가'] = df['가격'] * (1-df['할인율']) df
# 결측값으로 추가, 원두 컬럼을 만들고 결측값(NaN)으로 대입 import numpy as np df['원두'] = np.nan df
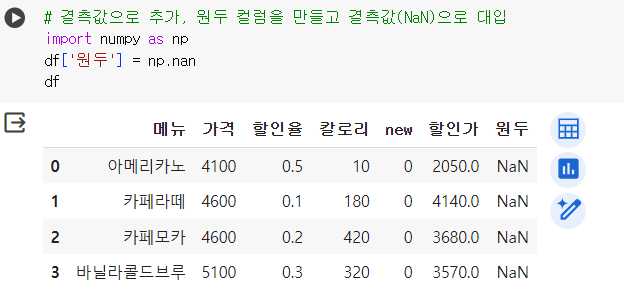
📌 데이터 삭제
-
컬럼 삭제 (axis = 1 : 컬럼 방향)

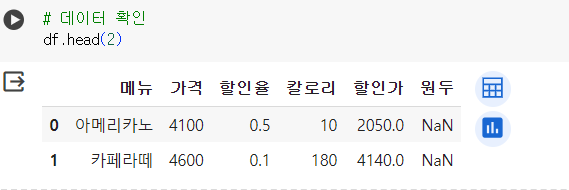
-
행 삭제 (axis = 0 : 행 방향)
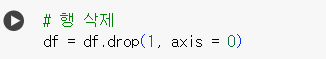

# 데이터 삭제
# axis=1:열방향(컬럼) / axis=0:행방향
# 열 삭제
df = df.drop('new', axis=1)
# 행 삭제
df = df.drop(1, axis = 0)📌 CSV 저장하기
- df.to_파일형식('파일명.확장자') 인덱스 옵션 신경쓰기!
데이터 불러오기랑 헷갈려서 df가 아닌 pd로 쓰는 경우가 많다고 하니 주의하기!
저장할 때는 데이터프레임을 csv로 !# csv로 저장하기 df.to_csv('data2.csv', index = False) # df.to_csv('data2.csv') #인덱스 값 없이 저장하려면 False 옵션 넣어야 함!


📌 QUIZ
# 주어진 데이터
data = {
"메뉴":['아메리카노', '카페라떼', '카페모카', '바닐라콜드브루'],
"가격":[4100, 4600, 4600, 5100],
"할인율":['0.5', '0.1', '0.2', '0.3'],
"칼로리":[10,180,420,320],
}
df = pd.DataFrame(data)
df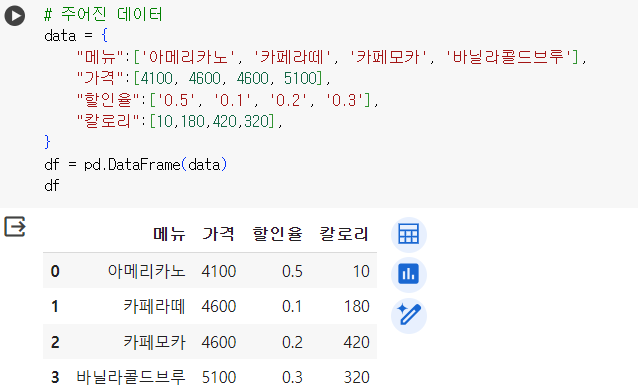
- 이벤트가격 컬럼 만들기
- 원 가격의 50% 할인을 적용한 이벤트가격 컬럼 생성
df['이벤트가격'] = df['가격'] * 0.5
df
- 할인가 컬럼 만들기
- 할인을 적용한 할인가격 컬럼 생성
#data 형식에서 할인율 칼럼의 형식이 object(문자)로 되어있어 계산이 안되는 오류 발생,
astype 메서드를 활용해 할인율 컬럼의 형식을 float로 변경 후 연산 컬럼 생성
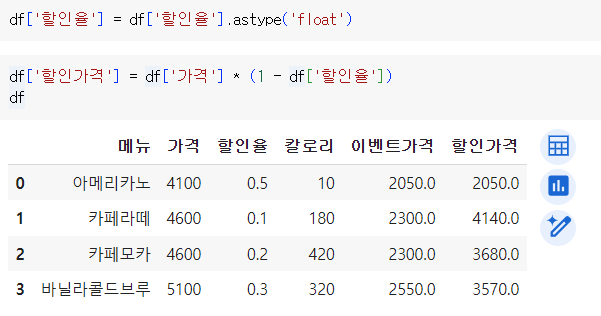
df['할인율'] = df['할인율'].astype('float')
df['할인가격'] = df['가격'] * (1 - df['할인율'])
df

커피 좋아하는 데이터 꿈나무