
#개요
- 데이터 핸들링을 위한 판다스 기초 2
📌 인덱싱/슬라이싱 설명
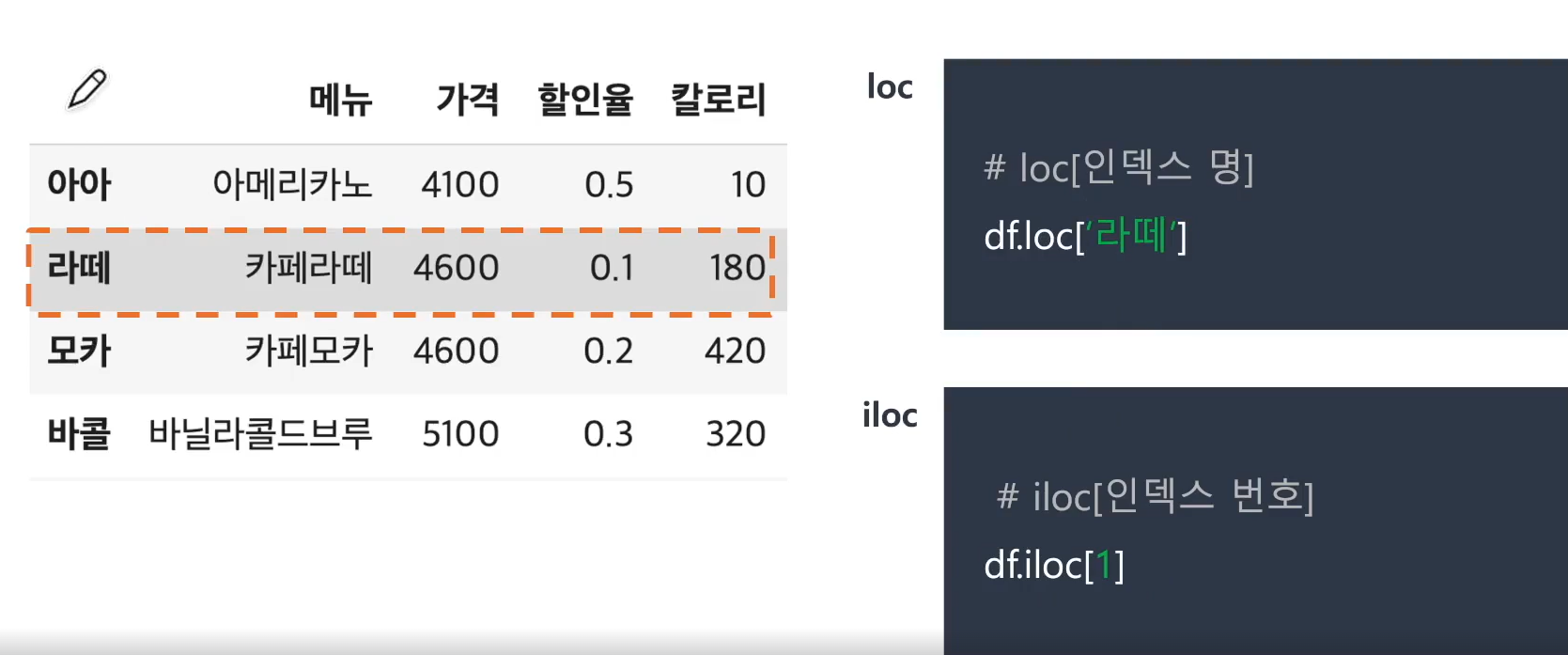
- 인덱싱 (Indexing)
인덱스(index): 연속적인 객체(리스트, 튜플, 문자열 등)에 부여된 번호
인덱싱(indexing): 무언가를 가리킨다는 뜻, 원하는 값을 가리킬 때 사용 - df.loc[인덱스 명]: 인덱스 명은 아아, 라떼 처럼 객체에 부여된 이름
- df.iloc[인덱스 번호]: 인덱스 번호는 0부터 시작해 순서대로 부여
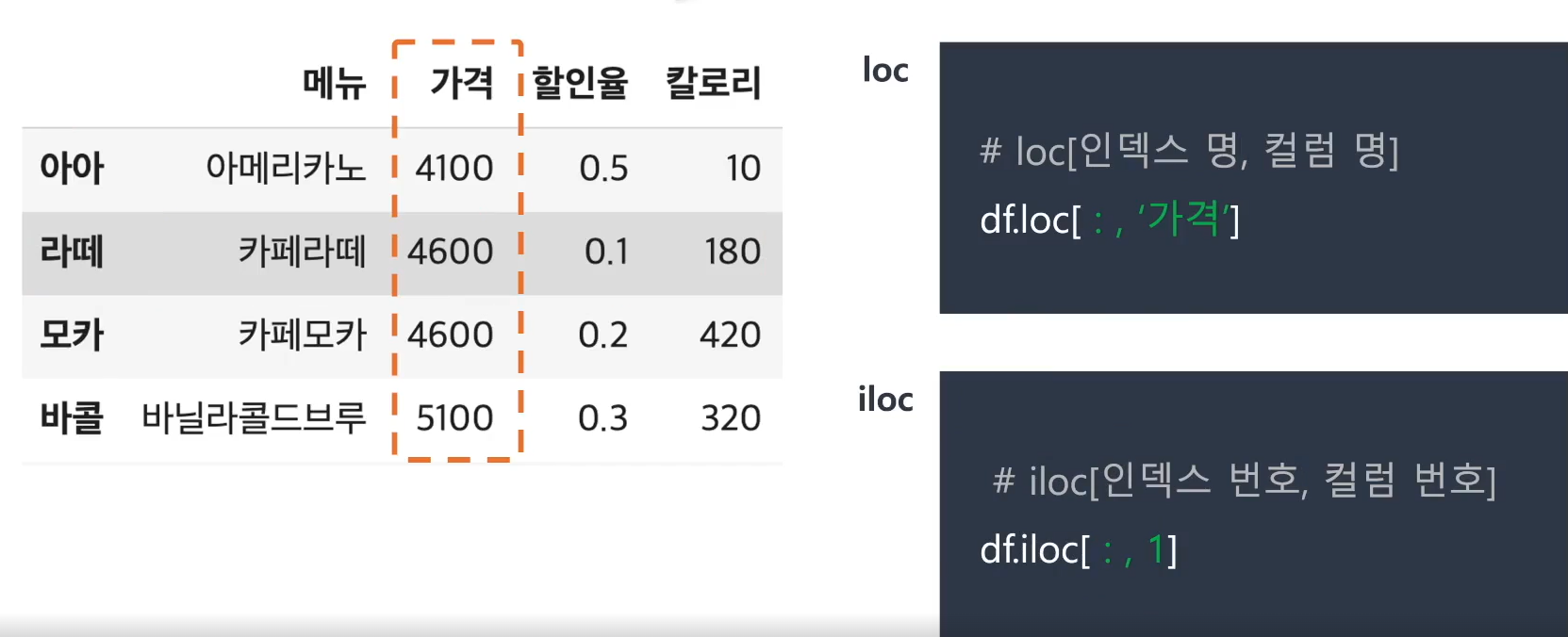
- 슬라이싱 (Slicing)
잘라낸다는 뜻으로 연속적인 객체(리스트, 튜플, 문자열)에
부여된 번호를 이용해 연속된 객체 일부를 추출하는 작업 - df.loc[인덱스 명, 컬럼 명]: 인덱스 명에
:만 작성할 경우전체를 의미 - df.iloc[인덱스 번호, 컬럼 번호]: 컬럼 번호도 0부터 시작!
📌 실습 CSV 생성
# csv파일 (data.csv) 생성 import pandas as pd data = { "메뉴":['아메리카노','카페라떼','카페모카', '바닐라라떼', '녹차', '초코라떼', '바닐라콜드브루'], "가격":[4100, 4600, 4600, 5100, 4100, 5000, 5100], "할인율":[0.5, 0.1, 0.2, 0.3, 0, 0, 0], "칼로리":[10, 180, 420, 320, 20, 500, 400], } data = pd.DataFrame(data) data.to_csv('data.csv', index=False)

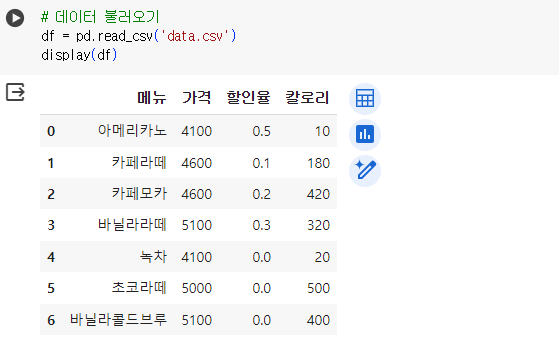
# 데이터 불러오기 df = pd.read_csv('data.csv') display(df)
📌 인덱싱/슬라이싱 : loc

# 인덱싱 (행 전체) # 아메리카노 df.loc[0]

# 슬라이싱 (컬럼 전체) # 가격 df.loc[:, "가격"] - [범위 전체, 가격 칼럼]

# 슬라이싱 # 카페라떼 가격 df.loc[1,"가격"]

# 슬라이싱 # 카페모카 메뉴와 가격 df.loc[2,"메뉴":"가격"]

# 슬라이싱 # 카페모카 메뉴와 칼로리 df.loc[2,["메뉴","칼로리"]]

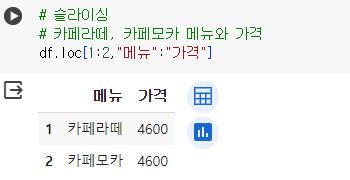
# 슬라이싱 # 카페라떼, 카페모카 메뉴와 가격 df.loc[1:2,"메뉴":"가격"]
📌 인덱싱/슬라이싱 : iloc

# 인덱싱 (행 전체) # 아메리카노 df.iloc[0]

# 슬라이싱 (컬럼 전체) # 가격 df.iloc[:, 1]

# 슬라이싱 # 카페모카 메뉴와 가격 df.iloc[2, 0:2]

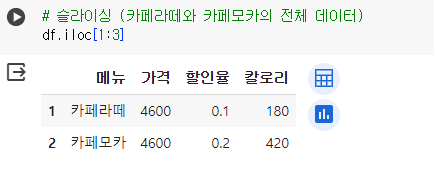
# 슬라이싱 (카페라떼와 카페모카의 전체 데이터) df.iloc[1:3]
📌 데이터 추가
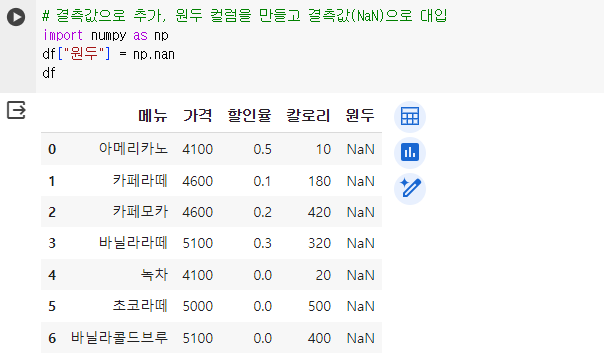
# 결측값으로 추가, 원두 컬럼을 만들고 결측값(NaN)으로 대입 import numpy as np df["원두"] = np.nan df
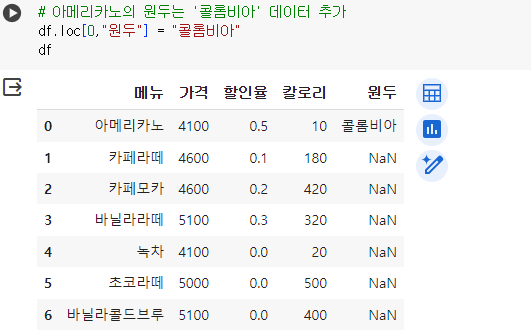
# 아메리카노의 원두는 '콜롬비아' 데이터 추가 df.loc[0,"원두"] = "콜롬비아" df
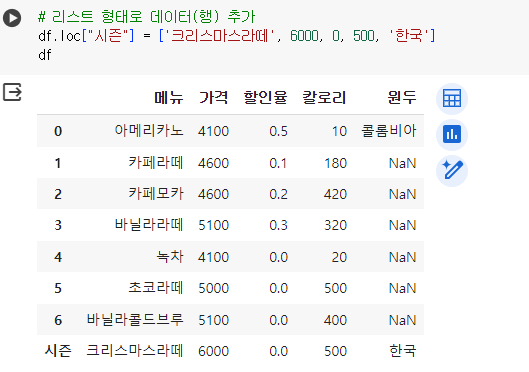
# 리스트 형태로 데이터(행) 추가 df.loc["시즌"] = ['크리스마스라떼', 6000, 0, 500, '한국'] df
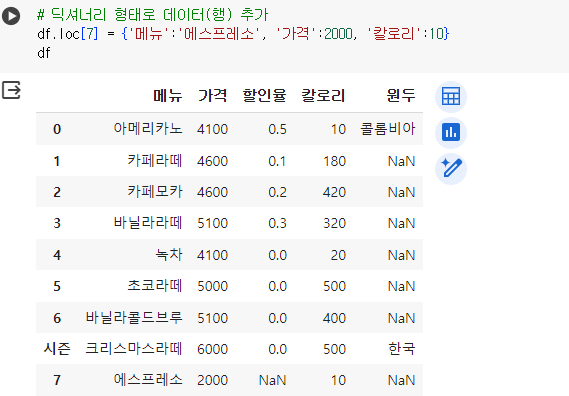
# 딕셔너리 형태로 데이터(행) 추가 df.loc[7] = {'메뉴':'에스프레소', '가격':2000, '칼로리':10} df
📌 소팅
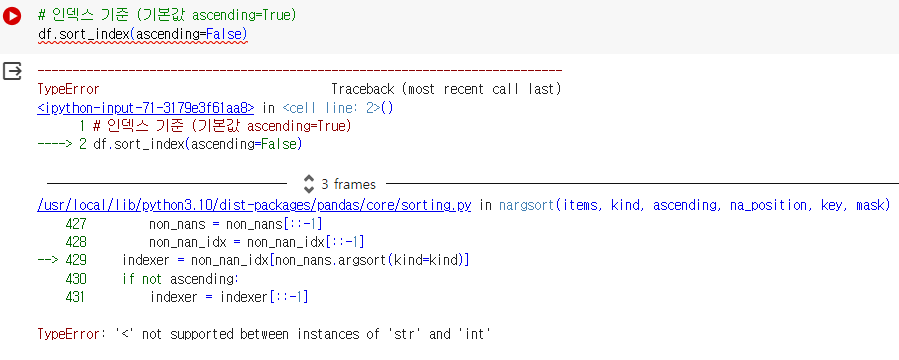
시즌이라는 인덱스명은 문자열, 나머지는 숫자열이기 때문에
인덱스 기준으로 정렬이 불가능하여 오류 발생
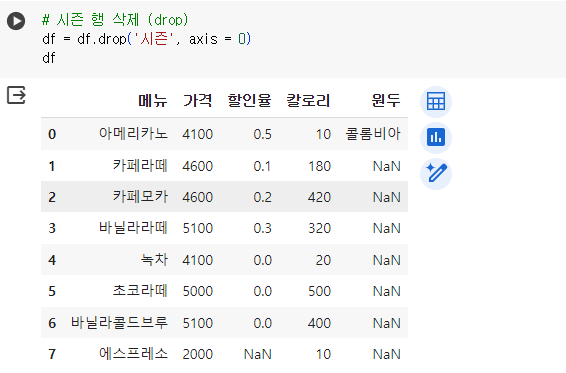
# 시즌 행 삭제 (drop) df = df.drop('시즌', axis = 0) - axis = 1 (수직), 0 (수평) df
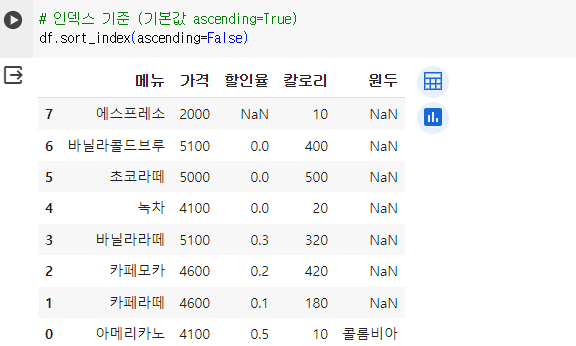
# 인덱스 기준 (기본값 ascending=True) - 기본은 오름차순 df.sort_index(ascending=False) - False 로 설정 시 내림차순
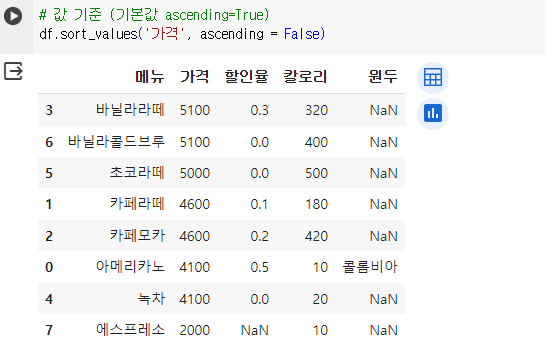
# 값 기준 (기본값 ascending=True) df.sort_values('가격', ascending = False)
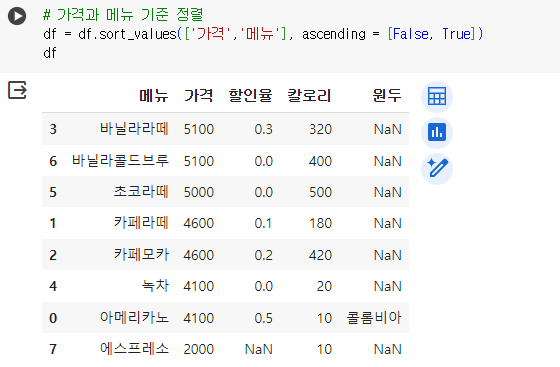
# 가격과 메뉴 기준 정렬 # 두 가지 기준으로 정렬할 때는 기준 칼럼을 대괄호로 묶고, 각각의 정렬 기준(오름, 내림)도 대괄호로 묶어 작성 df = df.sort_values(['가격','메뉴'], ascending = [False, True]) df
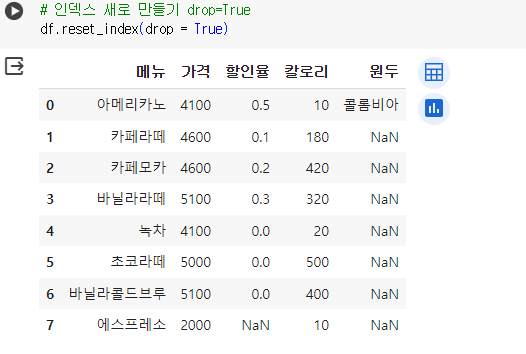
정렬 후 순서로 인덱스를 초기화 기존 인덱스를 삭제하려면 (drop = True) 추가 # 인덱스 새로 만들기 drop=True df.reset_index(drop = True)
📌 QUIZ
- 퀴즈 df 만들기
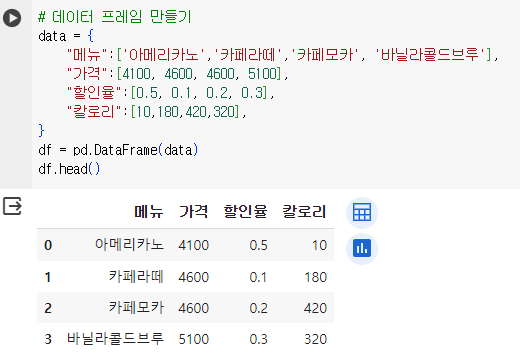
# 데이터 프레임 만들기 data = { "메뉴":['아메리카노','카페라떼','카페모카', '바닐라콜드브루'], "가격":[4100, 4600, 4600, 5100], "할인율":[0.5, 0.1, 0.2, 0.3], "칼로리":[10,180,420,320], } df = pd.DataFrame(data) df.head()
-
앞에서부터 3개의 데이터만 선택하기
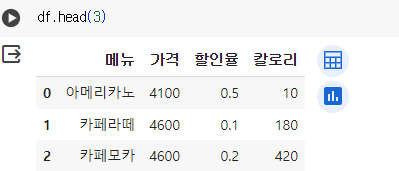
앞에서부터 - head 뒤에서부터 - tail 괄호 안 숫자만큼 선택 -
주어진 데이터(df)에서 아래 값을 loc와 iloc을 활용해
데이터 프레임으로 각각 출력하시오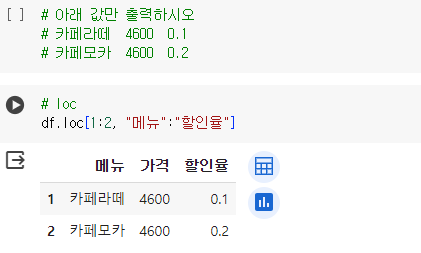
# 아래 값만 출력하시오
# 카페라떼 4600 0.1
# 카페모카 4600 0.2
# loc
df.loc[1:2, "메뉴":"할인율"]
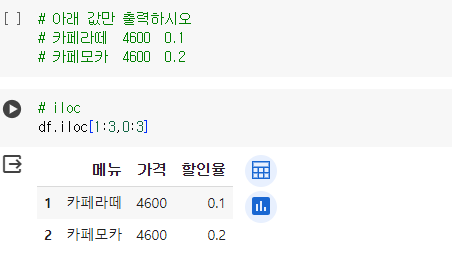
# iloc
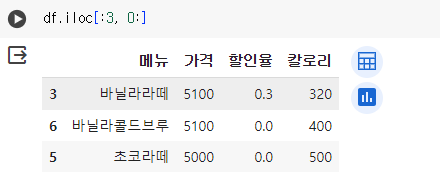
df.iloc[1:3,0:3]- 메뉴 중 가격이 가장 비싼 순으로 정렬해 상위 3개 값을 구하시오.

data = {
"메뉴":['아메리카노','카페라떼','카페모카', '바닐라라떼', '녹차', '초코라떼', '바닐라콜드브루'],
"가격":[4100, 4600, 4600, 5100, 4100, 5000, 5100],
"할인율":[0.5, 0.1, 0.2, 0.3, 0, 0, 0],
"칼로리":[10, 180, 420, 320, 20, 500, 400],
}
df = pd.DataFrame(data)
# 가격 컬럼 기준으로 내림차순 정렬 df = df.sort_values("가격", ascending = False)

# df.iloc 함수를 통해 3번째까지 행 선택 df.iloc[:3, 0:]

커피 좋아하는 데이터 꿈나무