
#개요
- 자주 사용되는 판다스
📌 조건필터 개요
- 판다스
df['칼럼']에 조건을 지정하여 원하는 값들을 추출할 수 있다.


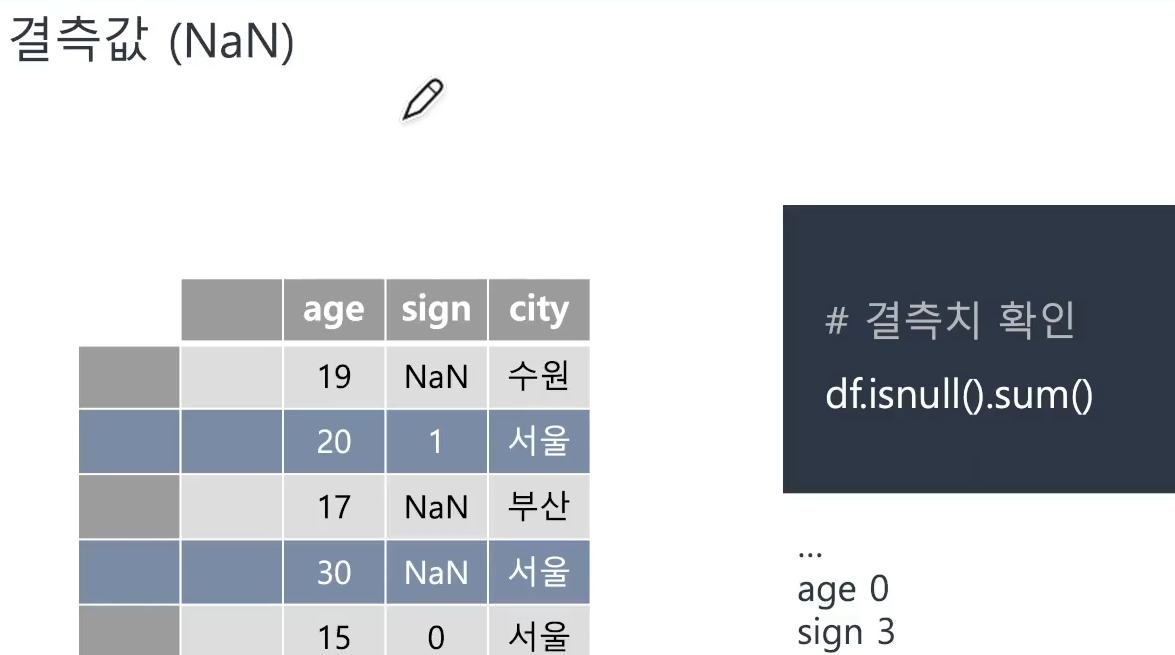
📌 결측치 개요
-
df.isnull()함수를 통해 결측치 유무를 확인하고,

-
.sum()함수로 각 칼럼별 몇 개의 결측치가 있는지 알 수 있다.
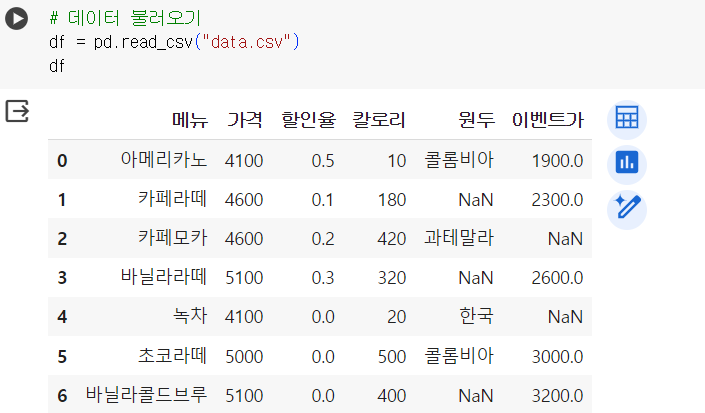
📌 데이터 생성 및 불러오기
# csv파일 (data.csv) 생성 import pandas as pd import numpy as np data = { "메뉴":['아메리카노','카페라떼','카페모카', '바닐라라떼', '녹차', '초코라떼', '바닐라콜드브루'], "가격":[4100, 4600, 4600, 5100, 4100, 5000, 5100], "할인율":[0.5, 0.1, 0.2, 0.3, 0, 0, 0], "칼로리":[10, 180, 420, 320, 20, 500, 400], "원두":['콜롬비아', np.NaN, '과테말라', np.NaN, '한국', '콜롬비아', np.NaN], "이벤트가":[1900, 2300, np.NaN, 2600, np.NaN, 3000, 3200], } data = pd.DataFrame(data) data.to_csv('data.csv', index=False)

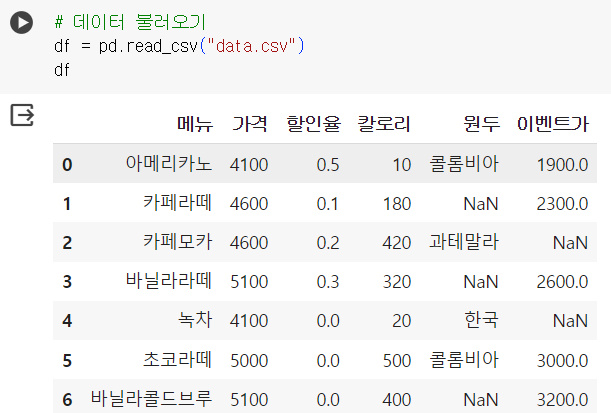
# 데이터 불러오기 df = pd.read_csv("data.csv") df
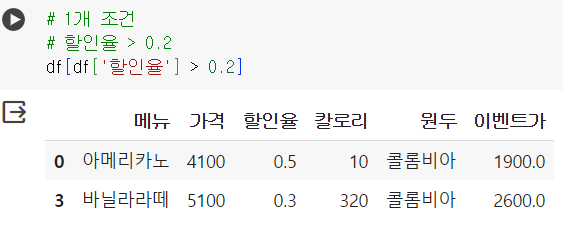
📌 조건필터
# 1개 조건 # 할인율 > 0.2 df[df['할인율'] > 0.2]
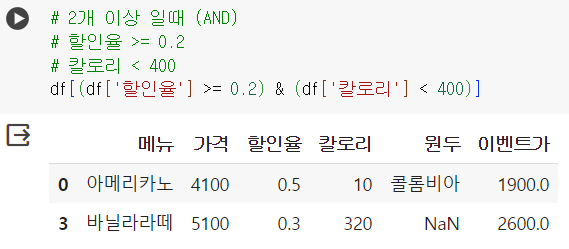
# 2개 이상 일때 (AND = &) # 할인율 >= 0.2 # 칼로리 < 400 df[(df['할인율'] >= 0.2) & (df['칼로리'] < 400)]
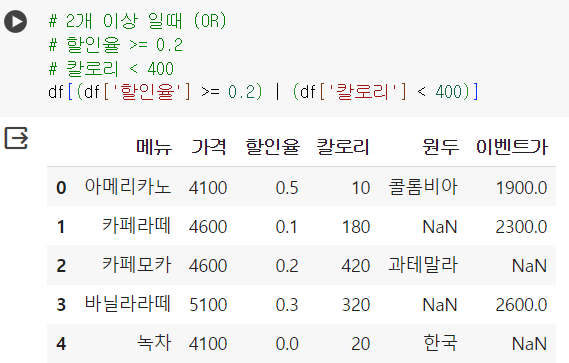
# 2개 이상 일때 (OR = |) # 할인율 >= 0.2 # 칼로리 < 400 df[(df['할인율'] >= 0.2) | (df['칼로리'] < 400)]
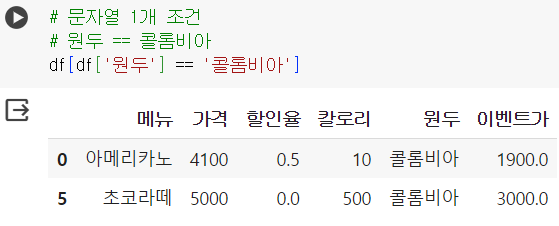
# 문자열 1개 조건 # 원두 == 콜롬비아 df[df['원두'] == '콜롬비아']
# 문자열과 숫자 조건 (AND) # 원두 == 콜롬비아 # 가격 < 4500 df[(df['원두'] == '콜롬비아') & (df['가격'] < 4500)]

📌 결측치
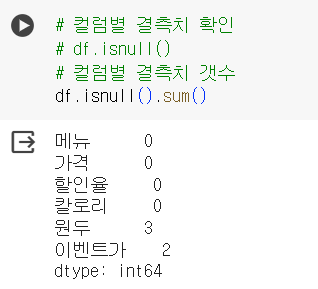
# 컬럼별 결측치 확인 df.isnull() # 컬럼별 결측치 갯수 df.isnull().sum()
# 결측값 채우기 # 원두-> 코스타리카로 채우기 df['원두'] = df['원두'].fillna('코스타리카') df

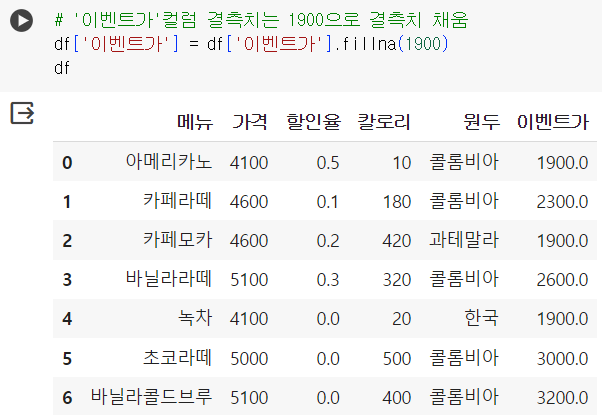
# '이벤트가'컬럼 결측치는 1900으로 결측치 채움 df['이벤트가'] = df['이벤트가'].fillna(1900) df
📌 값 변경
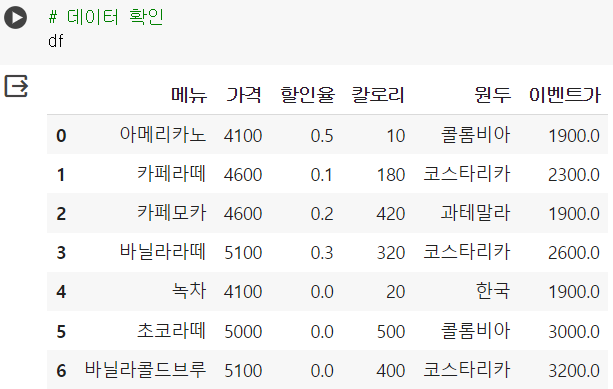
# 문자 변경 : 아메리카노 -> 룽고, 녹차 -> 그린티 # 문자 변경 확인 후 df에 반영하는 것 잊지 말기! df.replace('아메리카노','룽고').replace('녹차','그린티')
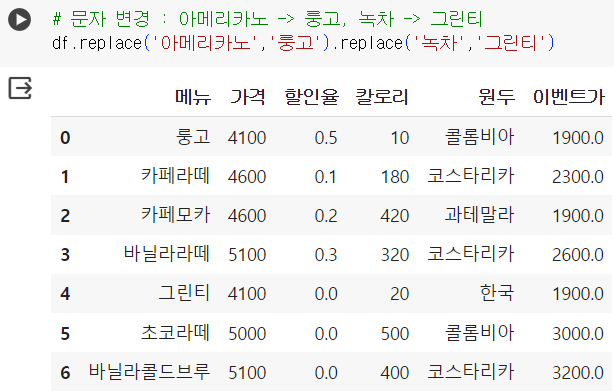
# 문자 변경2 d = {'아메리카노':'룽고', '녹차':'그린티'} df.replace(d)
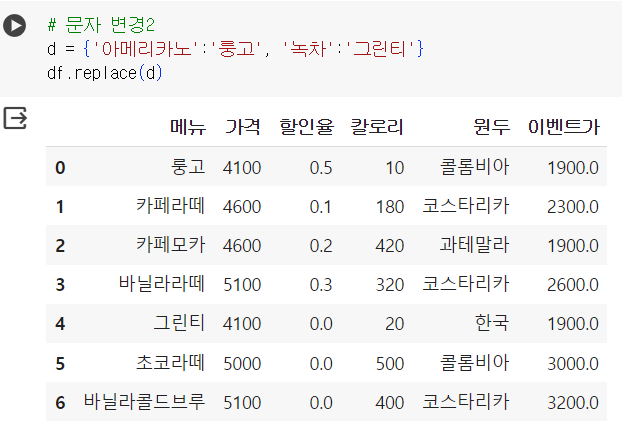
# 숫자 변경 : 1900 -> 1500 df.replace(1900, 1500)
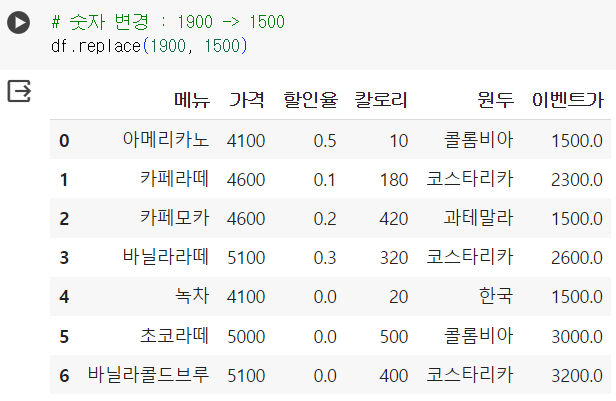
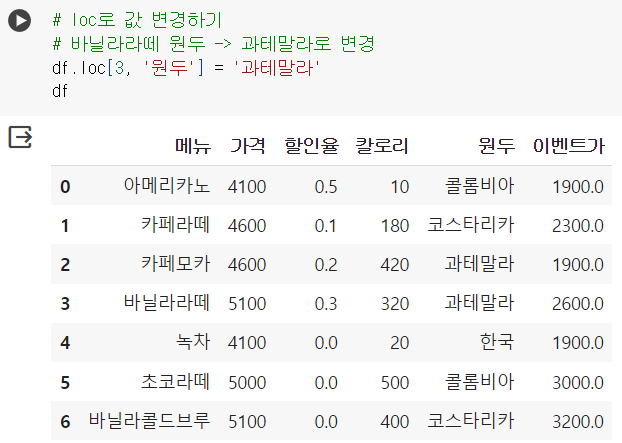
# loc로 값 변경하기 # 바닐라라떼 원두 -> 과테말라로 변경 df.loc[3, '원두'] = '과테말라' - 인덱스 명: 3(바닐라라떼), 컬럼 명: '원두' df
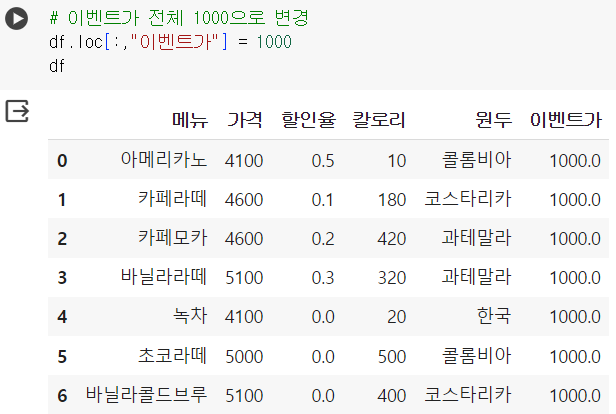
# 이벤트가 전체 1000으로 변경 df.loc[:,"이벤트가"] = 1000 df
📌 내장함수










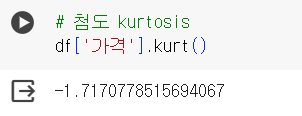
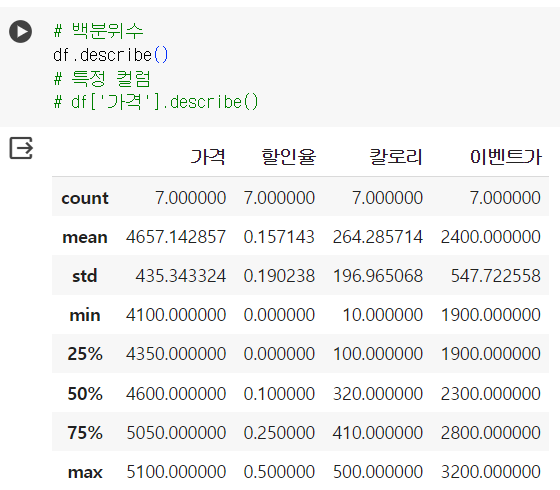
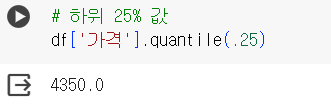
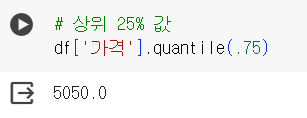
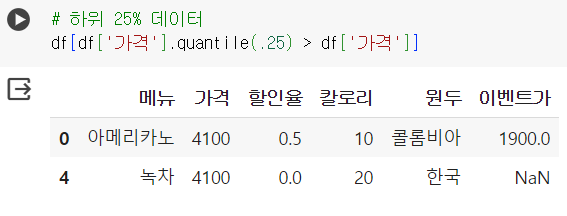
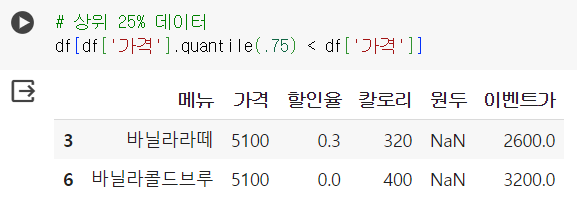

📌 APPLY 함수
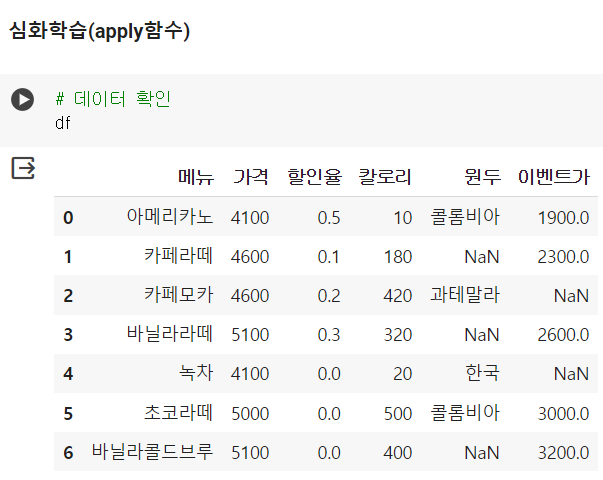

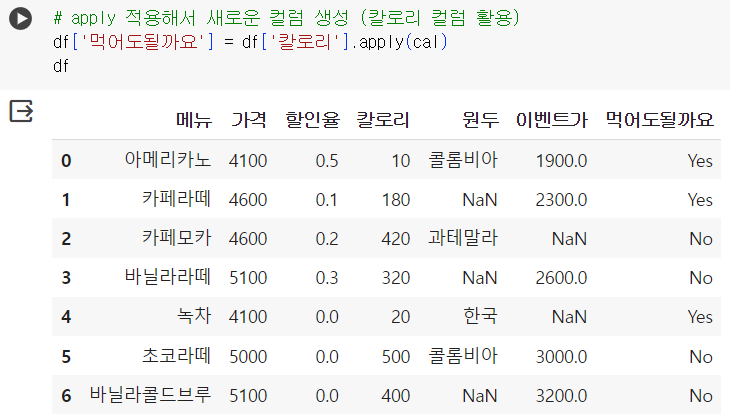
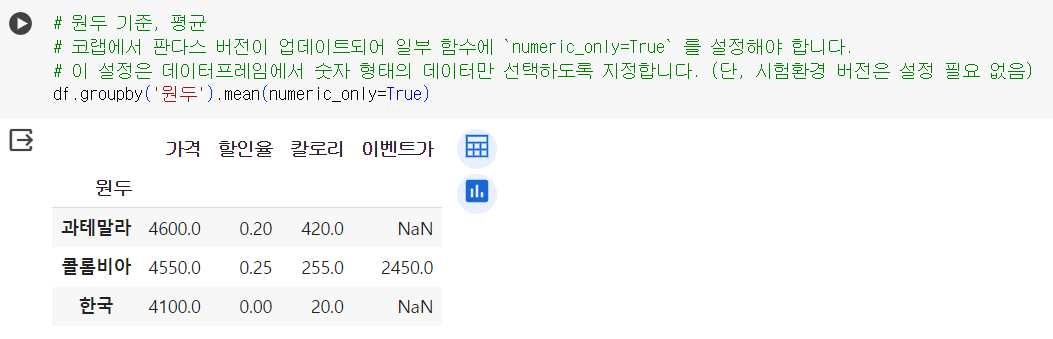
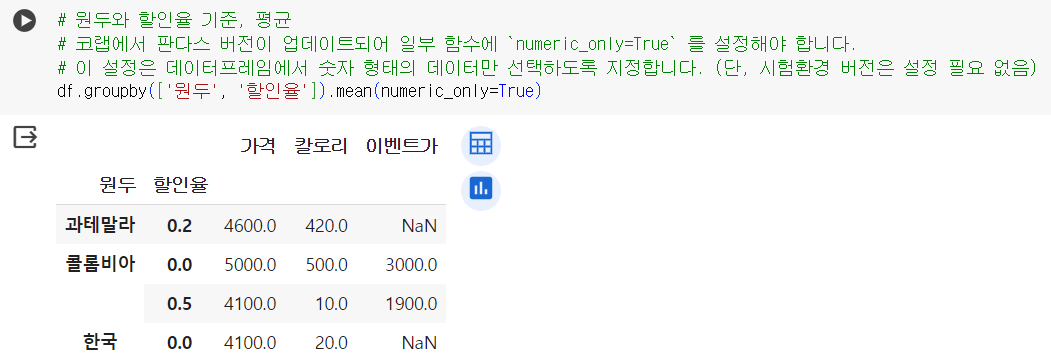
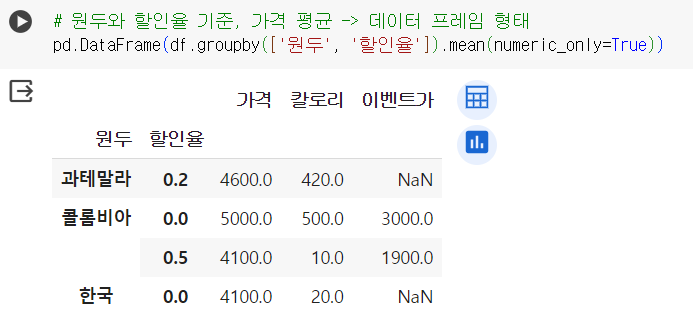
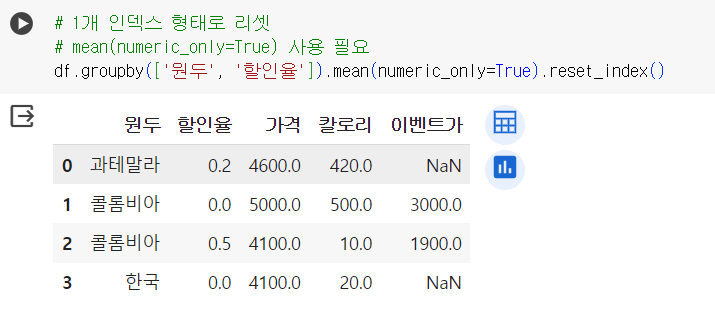
📌 그루핑

📌 QUIZ

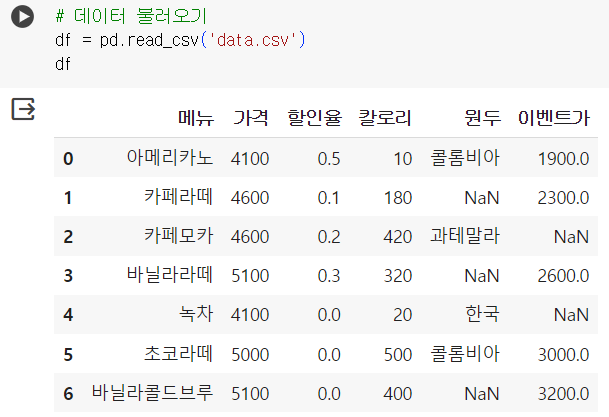
-
'이벤트가' 컬럼 결측치는 이벤트가격 데이터 중 최소값으로 결측치 채움
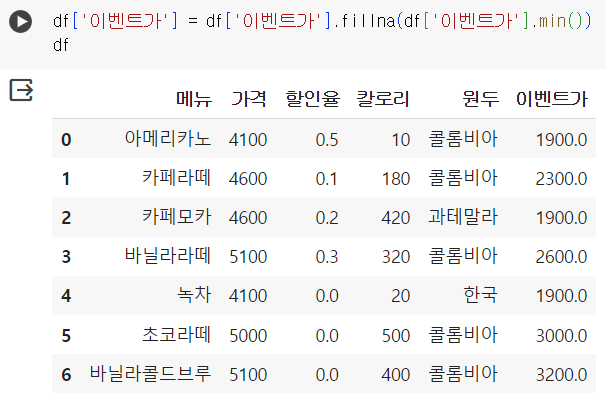
-
'원두' 컬럼 결측치는 원두 데이터 중 최빈값으로 결측치 채움
-
가격이 5000 이상인 데이터의 수를 구하시오


커피 좋아하는 데이터 꿈나무